談到智能制造、智慧工廠,愿景是美好的,借助計算機視覺技術和 AI 算法,為自動化生產線賦予環境感知的能力,從而改善工藝流程,提高生產效率。但是,隨著柔性化生產的需求增長,產線的布局調整和功能擴展在所難免,這就要求設備供應商或使用者能夠對 AI 算法進行持續性的維護、優化或移植,而現實是維護成本高、團隊能力缺乏。
MATLAB 就像一位全能的搭檔,提供了完備的文檔和友好的交互式應用程序,即使是沒有數據科學背景的領域工程師,也可以在一步步引導,快速完成“數據準備-AI?算法開發-系統部署”整個工作流程。

紙上得來終覺淺,讓我們來具體看看,以上工作流在一個典型的工業應用場景——零件表面缺陷檢測——中是如何實現的。

◆??◆??◆??◆
數據準備
攝像頭采集的原始圖像數據中,往往含有大量冗余信息。前處理的第一步,通常是將被檢測的目標對象和背景(其他無關物體)分離開來,即提取感興趣區域(Region Of Interest, ROI)。在這里,可以運用一個小技巧:選擇一個與目標顏色對比差異足夠大的背景,采用簡單的圖像處理方法,例如顏色空間變換、二值化處理等,就可以快速提取出目標,而不需要使用計算更復雜的 YOLO 等目標檢測深度神經網絡。
具體步驟如下:
1.將采集的單幀彩色 RGB 圖像轉換為更有利于進行圖像分割的 HSV 顏色模型;
img1 = snapshot(webcam);
hsv1 = rgb2hsv(img1);
2.通過大津算法確定閾值,對圖像進行二值化分割;
th = otsuthresh(imhist(hsv1(:,:,2)));
bw = hsv1(:,:,2) > th;
bw = bwareaopen(~bw,50);
3.分析區域特性,可確定邊界框,再對原圖進行相應的裁剪;
stats = regionprops('table',bw,'BoundingBox');
bbox = int16(stats.BoundingBox);
img2 = imcrop(img1,bbox);
4.最后進行灰度化處理。
img3 = rgb2gray(img2);
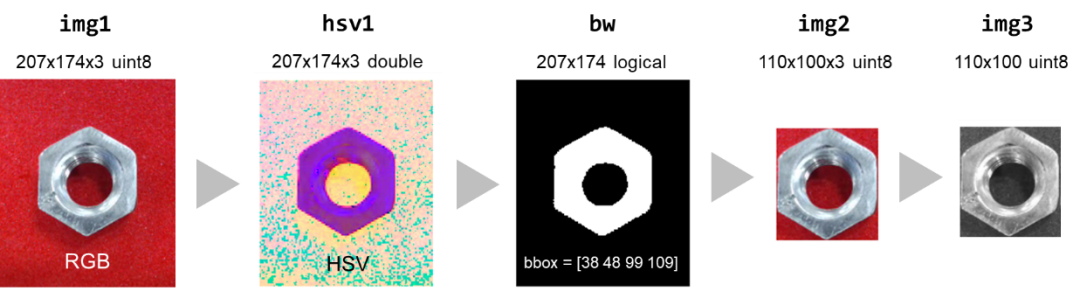
經過以上步驟,單幀圖像的數據量從 207x174x3 降低至 110x100,數據維度的降低,可減輕后續分類算法的需要完成的計算量,從而提高推斷速度。
如果您的實際應用場景較為復雜,可考慮加強對外部環境的控制,例如光照條件、攝像頭角度等,此外,在前處理的過程中,結合更多圖像處理和計算機視覺技術,例如相機校準、圖像增強和降噪等方法,以獲得更高質量的樣本數據。
采集足夠多的樣本后,通過對帶有真值標注的數據進行監督式機器學習,是常用的構建預測模型進行分類的方法。使用 MATLAB 中的數據存儲對象 imageDatastore,可以方便快速地對硬盤中的數據進行索引,并定義數據標簽來源:
categ = {'good', 'defective'};
imds =imageDatastore(fullfile(pwd,?'images', categ), ...
??? 'IncludeSubfolders',1,'LabelSource',?'foldernames')
我們準備了一個樣本大小為 784 的數據集,標簽為缺陷檢測結果,其中 509 個“有缺陷”(Defective)樣本,273 個“無缺陷”(Good)樣本,隨機選取 90% 樣本作為訓練集,剩余 10% 作為驗證集:
[trainingSet,validationSet] = splitEachLabel(imds, 0.9,?'randomize');
在數據不夠多、類別不均衡的情況下,借助數據增強的方法,對圖像進行不同程度的平移、旋轉和縮放等,可一定程度上提高機器學習模型的泛化能力。
augmenter =imageDataAugmenter('RandXReflection',true, ...
????'RandYReflection',true,'RandRotation', [-180180]);
trainingSet =augmentedImageSource([227 227],trainingSet, ...
????'DataAugmentation',augmenter);
◆??◆??◆??◆
AI 算法開發
AI 應用領域目前主流的方法有兩大分支:一是基于統計的傳統機器學習方法,例如支持向量機、隨機森林等,其中需要人為定義數據的特征作為輸入;二是基于人工神經網絡的深度學習方法,可以直接從數據中學習特征后進行推斷。接下來,我們將探討兩種方式各自的可行性和優缺點:1. 基于特征工程和支持向量機的缺陷檢測;2. 基于深度神經網絡的缺陷檢測。
方案 1. 基于特征工程和支持向量機的缺陷檢測
特征工程,是機器學習中一個非常重要的環節,對模型推斷的準確度影響很大。我們嘗試使用 Bag of Features 方法,從圖像數據中提取特征,并轉換為機器學習算法可以處理的形式——特征向量。
bag =bagOfFeatures(trainingSet);
在 Bag of Features 中,將對每張圖片,先用 SURF(加速穩健特征)算法提取局部特征,再通過 K-均值聚類將相似特征合并,聚類中心構成大小為 500 的視覺詞匯字典。
每張圖片可以對應表示為各個視覺詞匯的組合,即特征向量,用于描述各個視覺詞匯出現的頻率。如以下直方圖所示,不同樣本的特征向量有所差別。
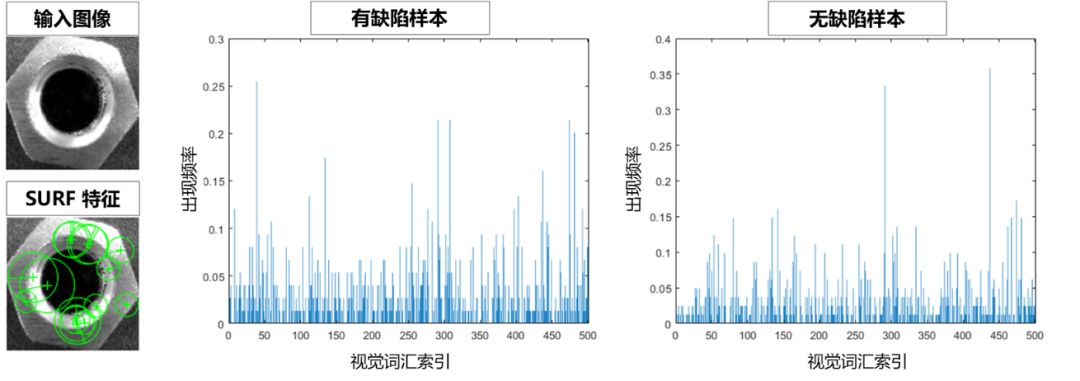
您可以通過 encode 函數,將每張圖片對應轉換為對應的特征向量后,作為機器學習模型的輸入進行訓練:
featureVector =encode(bag, img);
也可以通過 trainImageCategoryClassifier 函數,直接接收訓練集和 bag 對象,快速訓練一個支持向量機(SVM)分類器:
categoryClassifier= trainImageCategoryClassifier(trainingSet,bag);
分類器對訓練集的預測準確度為 82%,測試集為 75%,通常進行超參數調優,可在一定程度上提高推斷準確度,然而受限于人為的特征選擇,傳統機器學習方法的優化空間比較有限。如何能夠降低難度并進一步提高分類準確度呢?我們來看下一個方案。
方案 2. 基于深度神經網絡的缺陷檢測
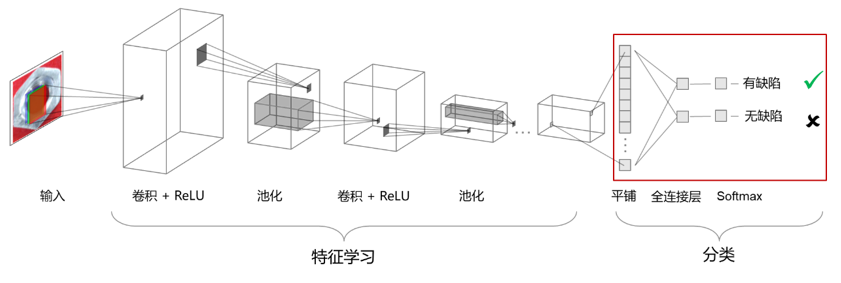
相較于方案1,深度神經網絡訓練和推斷對計算資源的要求更高,但是往往準確度也更高。卷積神經網絡(CNN)是一種適用于視覺任務的深度神經網絡架構,如下圖所示,從左到右,依次是輸入層、特征學習相關層(卷積層,ReLU 激活層和池化層)和分類輸出層。
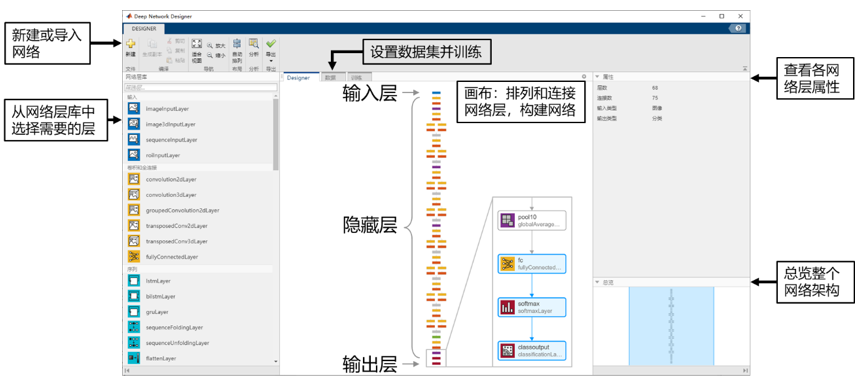
MATLAB 深度學習工具箱提供了基礎網絡層庫,您可以使用交互式應用程序 Deep Network Designer 從零起步創建網絡,并進行圖像分類網絡的訓練。目前有大量優秀的預訓練網絡,可供開發者直接使用,您只需要按照實際的任務對網絡的輸出進行微調后再訓練,就能以較低的數據和計算成本,得到一個功能強大的深度學習模型,這種方法稱為“遷移學習”。
我們選用 SqueezeNet 進行遷移學習,保留其中特征學習的部分,加入輸出大小為 2 的全連接層,并替換最后的 Softmax 和分類層,使其適用于當前的二分類缺陷檢測任務。
接下來,選擇數據源為之前設定的訓練集 trainingSet 和驗證集 validationSet,可加入數據增強方法,然后,設置學習率、優化器等訓練參數:

啟動訓練,并查看以下圖窗中的曲線了解訓練進度和效果:
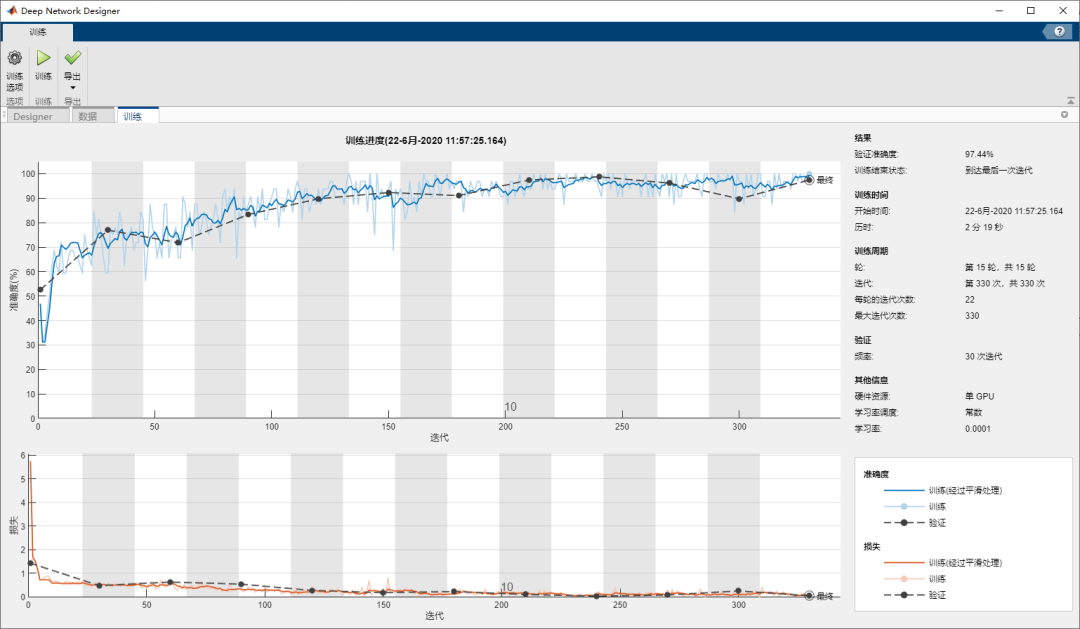
訓練完成后,可以看到驗證準確度達到 97.44%,效果相對于方案1大幅提升,您可以在此基礎上,嘗試繼續迭代優化,或直接導出至工作空間用于推斷。以上操作流程可直接導出為 MATLAB 代碼,當需要擴展數據集或更換數據時,用于自動化訓練過程和模型更新。
后處理與神經網絡驗證
深度神經網絡是一個黑盒模型,使用訓練好的模型對新圖像進行分類,可直接輸出對應的標簽,但是怎樣解釋預測結果,神經網絡的推斷是否有合理依據,卻難以評估,此外,簡單分類也無法反映缺陷的位置和形狀。為了解答這些疑問,我們可以使用類激活映射(Class Activation Mapping, CAM)的方法,提供一些用于評估網絡的可視化依據。
之前提到,卷積核會對特定的特征產生不同程度的激活,下圖中,每一個黑白相間的像素組代表一個卷積核對輸入圖像產生的激活,白色像素表示強正激活,黑色表示負激活。預測結果(類別)和最后一個卷積層的激活程度,存在一定的映射關系,全連接層的權重值?[w1?w2?… w1000]T?代表各個激活對預測結果的貢獻大小,加權計算以后得到的值稱為類激活映射,將其以熱圖(heatmap)的形式,疊加在原圖像上,如下:
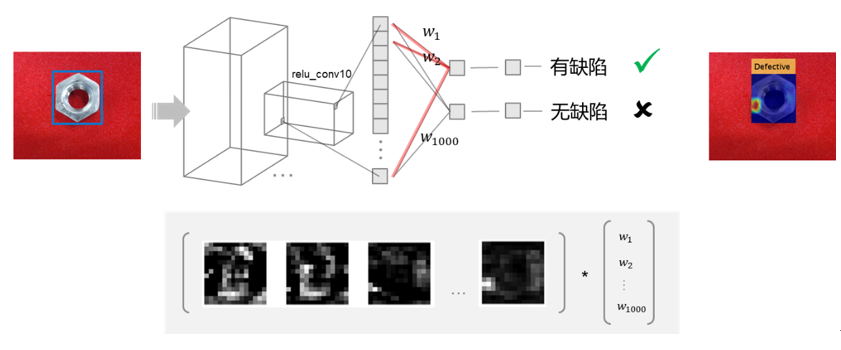
上圖中,高亮處代表神經網絡將樣本判定為“有缺陷“類別的主要特征,這與實際的缺陷位置基本吻合,我們可以判斷神經網絡預測依據合理。
◆??◆??◆??◆
系統部署?
算法開發完成后,最終需要部署到生產環境才能發揮作用。MATLAB 提供了完整的工具鏈,支持一次開發,多平臺部署,您可以將深度神經網絡,連同前后處理函數和其他應用邏輯,自動生成產品級代碼,運行在嵌入式設備中,或者作為應用程序,運行在桌面、網頁或者云端。
在代碼生成方面,MATLAB Coder 支持基于 MKL-DNN 和 ARM Compute Library 的神經網絡 C/C++ 代碼生成,而 GPU Coder 則支持基于 NVIDIA GPU 的 CUDA 代碼生成。
接下來,讓我們來看看如何在真實場景下測試以上算法。
借助硬件支持包 GPU Coder Support Package for NVIDIA GPUs,可以快速將方案 2 部署在 Jetson Nano 的開發板中,步驟如下:
1. 連接硬件:
hwobj = jetson('hostname','username','password');
2. 設置代碼生成相關參數,例如生成可執行文件,使用 cuDNN 庫等:
cfg =coder.gpuConfig('exe');
cfg.DeepLearningConfig= coder.DeepLearningConfig('cudnn');
cfg.DeepLearningConfig.DataType=?'fp32';
cfg.Hardware =coder.hardware('NVIDIA Jetson');
cfg.Hardware.BuildDir=?'~/';
3. 自動生成代碼:
codegen?-config cfg targetFunction -args {ones(240, 320, 3,'uint8'), coder.Constant(Weights),coder.Constant(true)} -report
下圖為在 NVIDIA Jetson Nano 開發板上,調用 Webcam,對測試樣本進行缺陷檢測的效果示意,在使用 cuDNN 庫,采用 32 位浮點計算的情況下,同時處理兩個樣本幀率大約為 4.3 FPS,單樣本約為 8 FPS。

在以上模型的基礎上,通過生成基于 TensorRT 的 fp16 代碼,或采用 Xavier 等處理能力更強的硬件,可進一步加快推斷速度。此外,您也可考慮使用其他神經網絡架構。在 MATLAB 附加功能資源管理器中搜索”Deep Learning for Defect Detection on Raspberry Pi”,可以獲取基于樹莓派的代碼部署版本。
◆??◆??◆??◆
總結
概括來說,在 MATLAB 中,您可以:
-
通過圖像處理技術減少原始圖像數據中的冗余信息
-
利用深度學習直接學習特征,實現端到端的缺陷檢測
-
借助應用程序和自動代碼生成工具提高 AI 算法開發和部署效率



malloc,calloc,realloc函數的介紹使用及柔性數組的介紹)

)




———HTTPS:保護網絡通信安全的關鍵)








-1. 兩數之和)