目錄
- 1 分區
- 2 消費者
- 3 Kafka 如何保證消息的消費順序?
- 3.1 方案一
- 3.2 方案二
- 4 消息積壓
在項目中使用kafka作為消息隊列,核心工作是創建生產者—包裝數據;創建消費者----包裝數據。
欠缺一些思考,特此梳理項目中使用kafka遇到的一些問題和解決方案
1 分區
參考博文:點擊鏈接
分區:主題可以被分為若干個分區(partition),同一個主題中的分區可以不在一個機器上,有可能會部署在多個機器上,由此來實現 kafka 的伸縮性,單一主題中的分區有序,但是無法保證主題中所有的分區有序
示例:假設有一個主題(Topic)A,有三個分區(Partition 0、Partition 1、Partition 2)。如果生產者產生了5條消息,該如何分配?
這就涉及到了kafka的分區機制了
kafka 的分區策略指的就是將生產者發送到哪個分區的算法。Kafka 為我們提供了默認的分區策略,同時它也支持你自定義分區策略。
分區策略有
- 順序輪詢 (下面示例介紹)
- 隨機輪詢
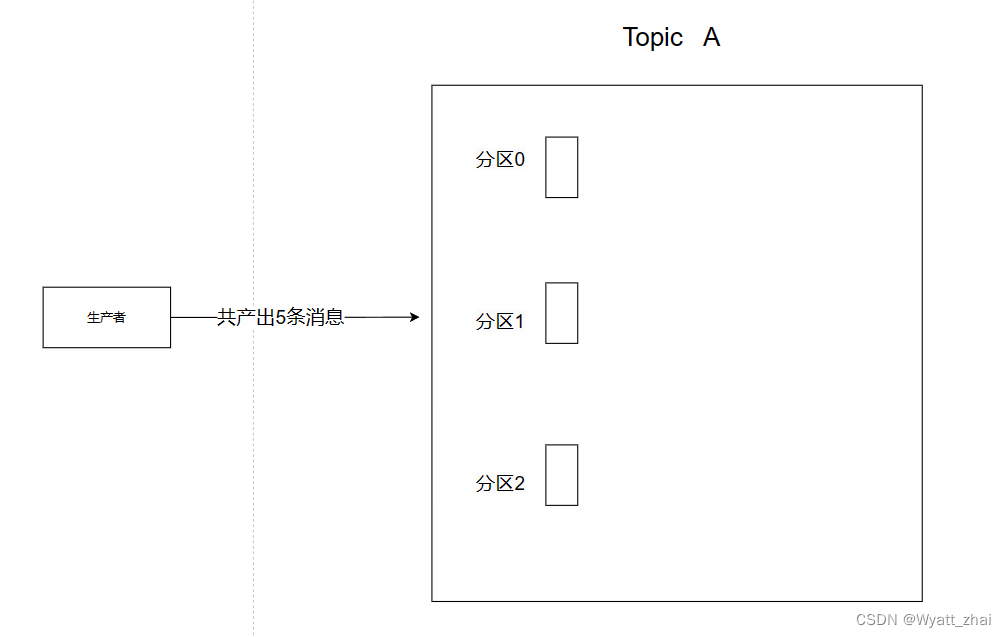
Kafka中消息的分配到分區的過程是由分區器(Partitioner)來負責的。默認情況下,Kafka使用的是輪詢分區策略,也就是說,生產者產生的消息會依次被分配到不同的分區,以此循環。
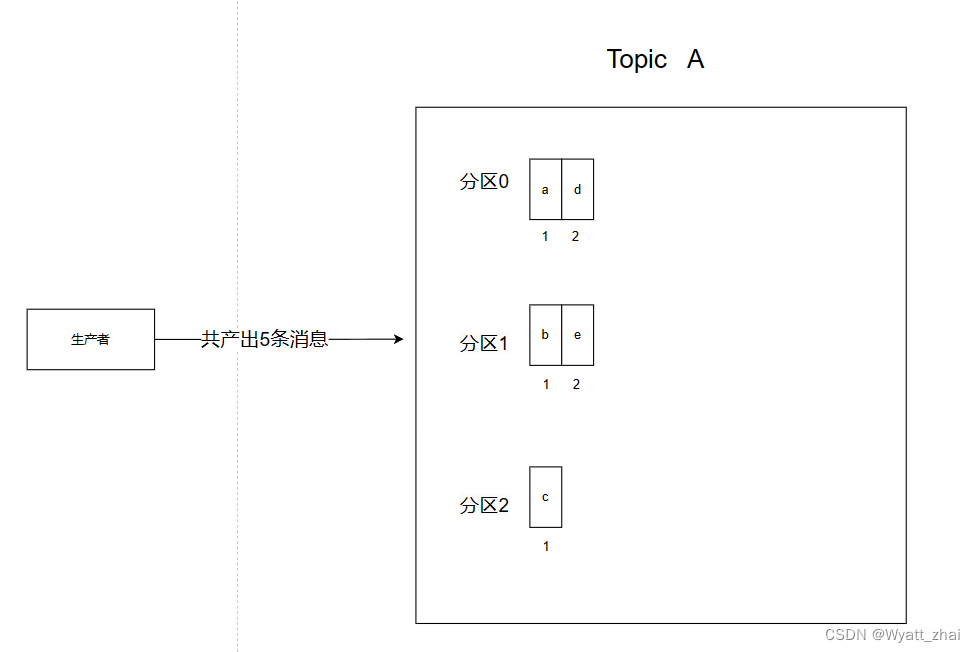
假設有一個主題(Topic)A,有三個分區(Partition 0、Partition 1、Partition 2)。如果生產者產生了5條消息,這些消息會被輪詢地分配到這三個分區中,直到所有消息都被發送。分配的過程如下:
第1條消息分配到 Partition 0
第2條消息分配到 Partition 1
第3條消息分配到 Partition 2
第4條消息再次分配到 Partition 0
第5條消息再次分配到 Partition 1
這樣的分配方式保證了各個分區的負載均衡。總體而言,如果有足夠的消息量,這些消息會在各個分區之間均勻分布,從而實現了平均分配的效果。
需要注意的是,分區策略是可以配置的,你可以自定義分區器來實現不同的分配策略,但默認情況下,輪詢分區是常見的方式。
2 消費者
消費組: 消費數據的時候,都必須指定一個group id,指定一個組的id假定程序A和程序B指定的group id號一樣,那么兩個程序就屬于同一個消費組。
特殊: 比如,有一個主題topicA程序A去消費了這個topicA,那么程序B就不能再去消費topicA(程序A和程序B屬于一個消費組);再比如程序A已經消費了topicA里面的數據,現在還是重新再次消費topicA的數據,是不可以的,但是重新指定一個group id號以后,可以消費。不同消費組之間沒有影響,消費組需自定義,消費者名稱程序自動生成(獨一無二)。
此時有兩個消費者,三個分區,該如何分配呢?
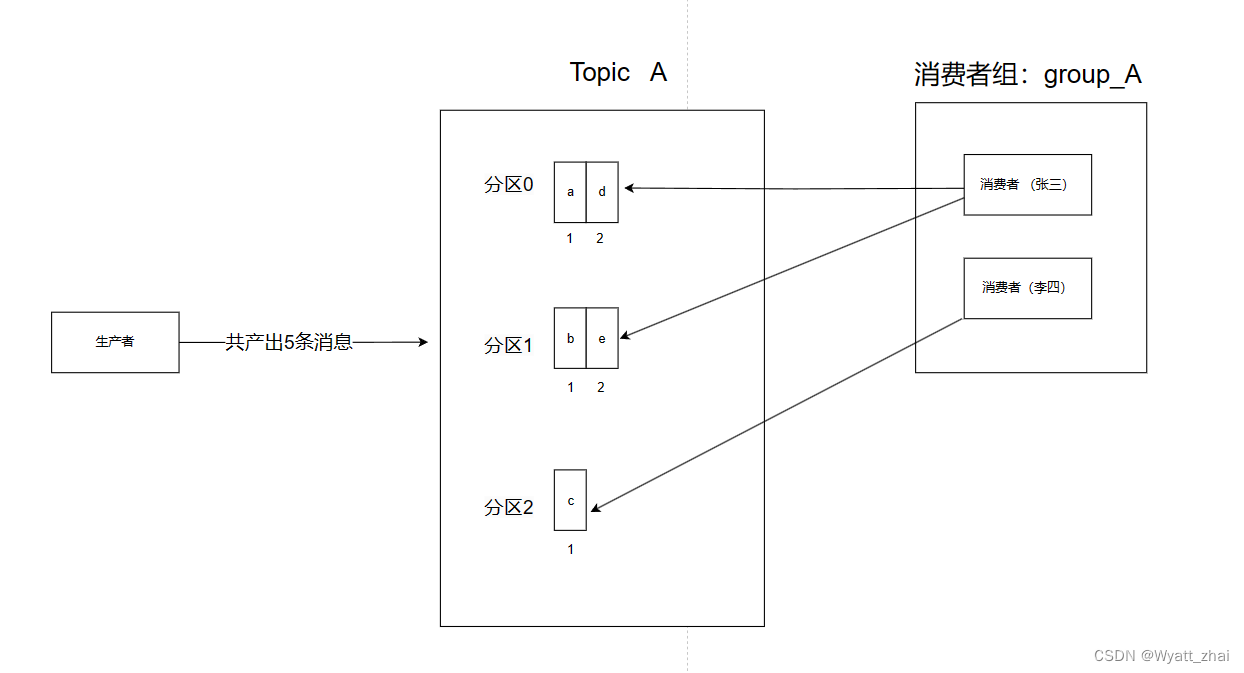
在 Kafka 中,一個消費者組(Consumer Group)可以由多個消費者組成。當消費者組訂閱一個主題(Topic)時,Kafka 會自動將主題的分區分配給消費者組中的消費者。
對于一個消費者組中的多個消費者,它們不需要手動指定分區。Kafka 使用一種分區分配策略來確保每個分區只被一個消費者消費。默認情況下,Kafka 使用的是范圍分配(Range Assignment)策略。
在范圍分配策略下,每個消費者被分配一定范圍的分區。例如,有一個主題有三個分區(Partition 0、Partition 1、Partition 2),消費者組中有兩個消費者(Consumer A 和 Consumer B),分配可能如下:
Consumer A 被分配 Partition 0 和 Partition 1
Consumer B 被分配 Partition 2
這種自動的分區分配機制使得消費者組能夠 并行 地處理消息,提高整體的消費吞吐量。
需要注意的是,如果消費者組中的消費者數量發生變化,分區的分配會動態調整以適應新的消費者數量,而無需手動干預。 Kafka會在有新的消費者加入或者有消費者退出時自動重新平衡分區。這種自動的分區調整機制是 Kafka 提供的一項強大的功能,能夠使得整個系統更加靈活和容錯。
3 Kafka 如何保證消息的消費順序?
消費后會提交偏移量
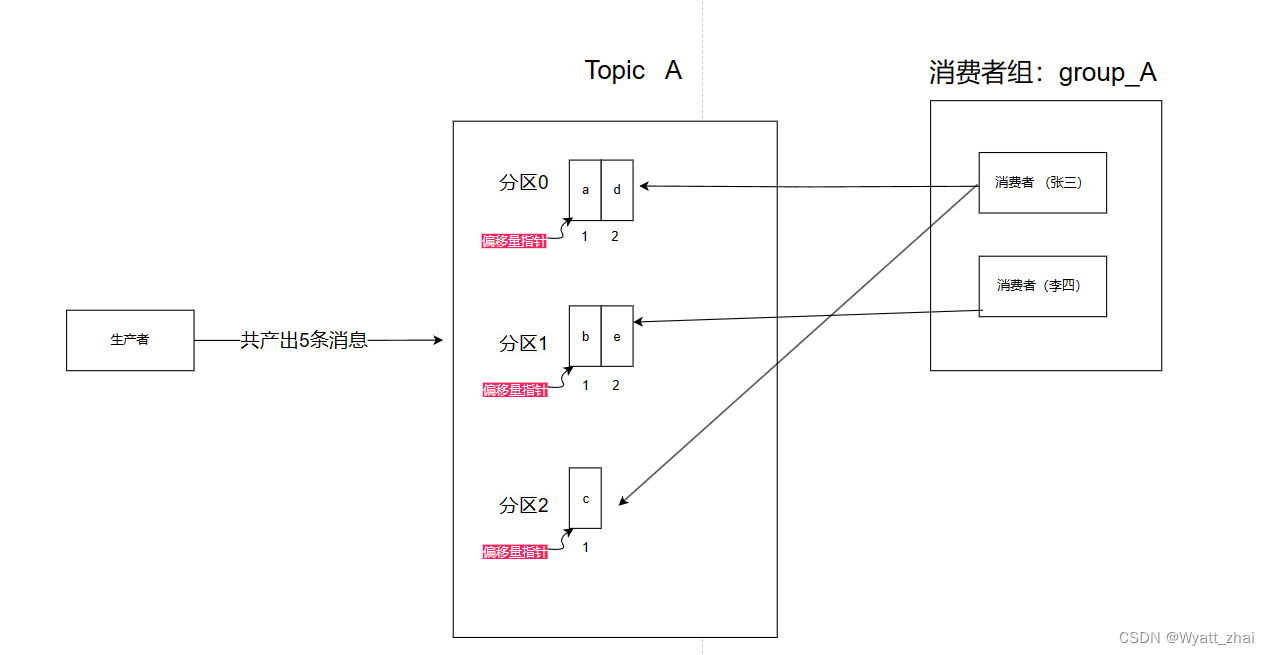
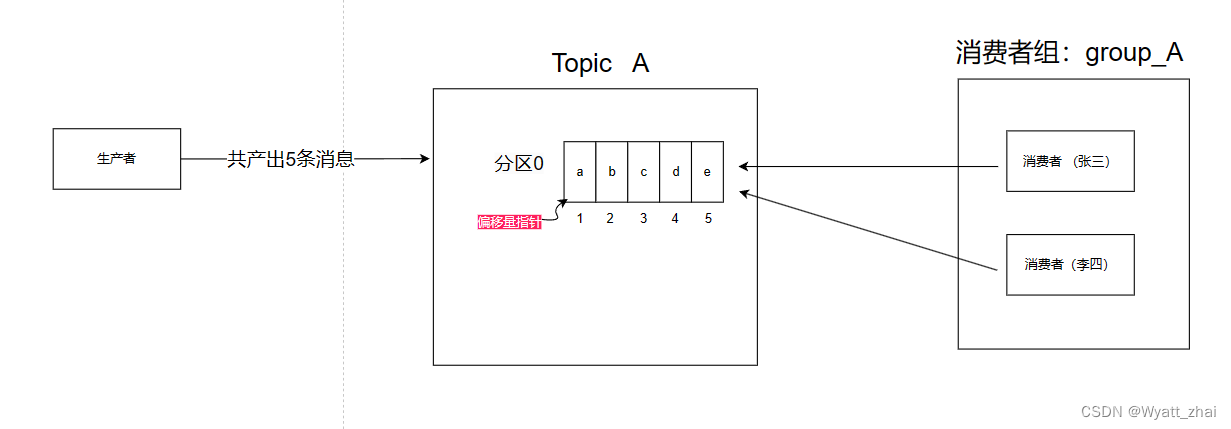
示例:生產者提供了5條消息,暫且按照上述方式分配消息。當消費者組 消費的時候會出現這種情況
0:01時刻 :張三消費c(并提交offset) 李四消費b(并提交offset)
重新動態匹配 消費者和分區,這里暫且忽略
0:02時刻 :張三消費a(并提交offset) 李四消費e(并提交offset)
此時消費的順序是 c,b---->a,e
期待的消費順序是a–>b—>c—>d---->e
因此是亂序的,需要重新設計方案解決
3.1 方案一
若是只有一個分區,這樣就可以保證消費順序了:a–>b—>c—>d---->e
3.2 方案二
指定消息全存在某一個分區
如何指定: Kafka 中發送 1 條消息的時候,可以指定 topic, partition, key,data(數據) 4 個參數。如果你發送消息的時候指定了 Partition 的話,所有消息都會被發送到指定的 Partition。并且,同一個 key 的消息可以保證只發送到同一個 partition,這個我們可以采用表/對象的 id 來作為 key 。
- Topic: 指定消息要發送到的主題。
- Partition: 指定消息要發送到的分區。如果指定了分區,那么所有的消息都會被發送到這個分區。
- Key: 通常用于確定消息應該被發送到哪個分區。如果你使用相同的 key,Kafka 會根據 key 使用分區器(Partitioner)將具有相同 key 的- 消息發送到同一個分區。
- Value: 實際的消息內容。
Key是用于計算消息應該被分配到哪個分區的依據,而Partition是直接指定分區
4 消息積壓
4.1 方案一
場景描述:
- Kafka 主題:orders,2個分區
- 初始狀態:有一個消費者組(Consumer Group)中有一個消費者實例(Consumer Instance)用于處理訂單消息。
- 積壓情況:由于訂單數量激增,導致 orders 主題中的消息積壓。
- 增加消費者
以前消息被分發到2個分區,但是只有一個消費者消費其中一個分區,另外一個暫時擱置,多創建一個消費者,提高使用率。
這里有個細節,項目執行后,唯一的線程:main線程---->消費分區1,無法做到同時控制另外一個消費者去消費分區2。看似消費者多了,實際效率沒變化。只能增加線程
- 增加線程
一個消費者占一個線程,這樣項目啟動,2個線程控制2個消費者,kafka負載均衡自動分配(一個消費者消費一個分區),提高了效率
- 異步消費 (并不能處理消息積壓)
在系統中,主線程調用 某個方法后,這個方法先返回數據給主,主繼續執行自己的邏輯。而這個方法是異步的,所以他可以在后臺創建線程和消費者,不會造成系統阻塞。


安裝及使用教程)



2)
題】)




正態分布)

——軟件安裝與使用(3))




