0.對原教程的一些見解
個人認為原教程中兩點知識的引入不夠友好。
首先是只讀數據結構?ByteView?的引入使用是有點迷茫的,可能不能很好理解為什么需要ByteView。
第二是主體結構 Group的引入也疑惑。其實要是熟悉groupcache,那對結構Group的使用是清晰明白的。而看該教程的人可能是沒有了解過groupcache,直接就引入結構Group,可能不好理解。這一章節希望可以講明白這兩點。
1.統一的緩存的value對象
//該類型實現了NodeValue接口
type String stringfunc (d String) Len() int {return len(d)
}在上節講解中, 我們存入的每一個元素(鍵值對)都要計算大小。為了能計算大小,那存入緩存的 value 對象必須實現NodeValue接口的Len()方法。上一節的測試用例中存儲的value對象是String(也即是string)。
那么問題來了, 我們存入的 value 可能是 string, int,?也可能自定義的結構體User等等。如果為每一種類型都實現一個 Len() 方法那確實是繁瑣。因此,我們希望將存入的每個 value 都轉化為統一的類型, 比如:字節數組 []byte。
我們可以抽象了一個只讀數據結構?ByteView?用來表示緩存值。
ByteView 只有一個數據成員,b []byte,b 將會存儲真實的緩存值。
b?是只讀的,使用?ByteSlice()?方法返回一個拷貝,防止緩存值被外部程序修改。
//緩存值的抽象與封裝
type ByteView struct {b []byte
}func (v ByteView) Len() int {return len(v.b)
}func (v ByteView) ByteSlice() []byte {return cloneByte(v.b)
}func cloneByte(b []byte) []byte {c := make([]byte, len(b))copy(c, b)return c
}func (v ByteView) String() string {return string(v.b)
}2.實現緩存并發讀寫
上一節實現的LRU算法是不支持并發讀寫的。Go中map不是線程安全的。要實現并發讀寫map,需要加鎖,可以使用sync.Mutex。
sync.Mutex 是一個互斥鎖,可以由不同的協程加鎖和解鎖。
先回顧下上一節定義的緩存的整體數據結構
type Cache struct {maxBytes int64 //允許的能使用的最大內存nbytes int64 //已使用的內存ll *list.List //雙向鏈表cache map[string]*list.ElementOnEvicted func(key string, value NodeValue)
}要是想的簡單點,我們可以在該結構體Cache內部加上sync.Mutex并修改其方法的部分原有邏輯來實現并發讀寫。但這樣就破壞了對擴展開放,對修改關閉的面向對象原則。這是不好的。
?定義加鎖的緩存對象
我們可以在Cache結構體基礎上再封裝一個可以支持并發讀寫的對象。
type cache struct {mutex sync.Mutexlru *lru.CachecacheBytes int64
}顯然,該新對象中是需要有個互斥鎖變量。而每個緩存對象都有能使用的最大內存量上限,使用cacheBytes?字段來存儲這個值。
該cache對象也基于互斥鎖和lru封裝了?get 和 add 方法。
func (c *cache) add(key string, value ByteView) {c.mutex.Lock()defer c.mutex.Unlock()if c.lru == nil {c.lru = lru.New(c.cacheBytes, nil)}c.lru.Add(key, value)
}func (c *cache) get(key string) (value ByteView, ok bool) {c.mutex.Lock()defer c.mutex.Unlock()if c.lru == nil {return}if v, ok := c.lru.Get(key); ok {return v.(ByteView), ok}return
}3.提升緩存并發讀寫能力
互斥鎖引發的性能問題
引入鎖之后,可能會引起性能問題,思考如下場景:
當有 A個線程訪問庫存的緩存數據時, 我們給?cache?對象加了鎖, 如果此時有 B個線程來訪問商品緩存數據,這 A + B 個線程就需要共同競爭一把鎖。
要是線程數量大的話,對性能是有影響的,那是因為所有的緩存都被一把鎖把持住。那要是我們可以把緩存進行分組,這樣首先就可以不用所有的線程都去搶一把鎖了。
將緩存數據進行分組
為了提高緩存系統的并發讀寫的性能(降低鎖的競爭程度),?我們想想是否可以再細分鎖的范圍,分段鎖的設計。
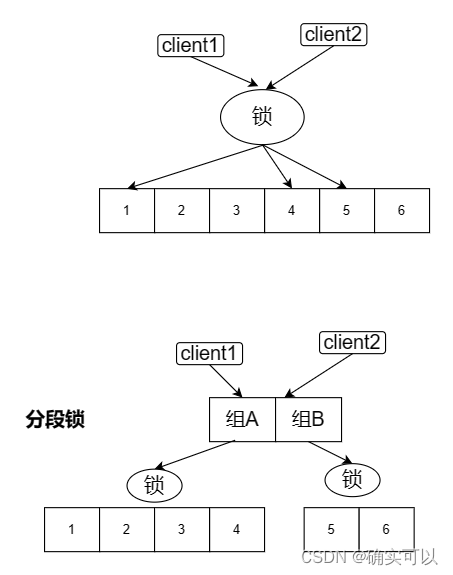
可以理解成是先分段再鎖,將原本的所有緩存分成了若干段,分別將這若干段放在了不同的組中,每個組有各自的鎖,以此提高效率。
如此設計之后,?不同組的存緩數據就隔離了起來, 訪問同一組數據的線程才會互相競爭。
這就引出了Group這個結構。
4.Group結構
定義一個分組結構,從上圖也可知道,要去訪問緩存,就需去找到該組,那如何辨別是這個組呢,這里就是通過組的名字去辨別的,每個組都有個名字。
// 緊接著我們定義一個 分組 類型
type Group struct {name string // 分組名稱mainCache cache // 單個緩存對象
}
這時有多個組后,那如何通過組名字快速找到該組了?還是要用map。那肯定又涉及到多個線程并發讀寫?groups?。這里是找到對應組名字的組而加鎖的。我們可以考慮用?讀寫鎖?來解決這個問題。
這里使用讀寫鎖應該比使用互斥鎖可以提高并發度。
來看看創建組和通過名字獲取組的函數
var (rwMu sync.RWMutexgroups = make(map[string]*Group)
)func NewGroup(name string, cacheBytes int64) *Group {rwMu.Lock()defer rwMu.Unlock()g := &Group{name: name,mainCache: cache{cacheBytes: cacheBytes},}groups[name] = greturn g
}// 獲取 Group 對象的方法
func GetGroup(name string) *Group {rwMu.RLock()defer rwMu.RUnlock()g := groups[name]return g
}緩存查詢回調方法
我們要考慮一種情況:如果緩存不存在,應從數據源(文件,數據庫等)獲取數據并添加到緩存中。
該Cache 是否應該支持多種數據源的配置呢?不應該,一是數據源的種類太多,沒辦法都實現;二是擴展性不好。如何從源頭獲取數據,應該是用戶決定的事情,我們就把這件事交給用戶好了。因此,我們設計了一個回調函數(callback),在緩存不存在時,就可以調用該函數,得到源數據。
這個回調方法我們可以直接定義在上面的 Get 方法的入參中,也可以放在 Group 對象中,為了方便,我們放在Group內。
type Group struct {name string // 組名mainCache cache // 單個緩存對象// 新增回調函數getter Getter}type Getter interface {Get(key string) ([]byte, error)
}type GetterFunc func(key string) ([]byte, error)func (f GetterFunc) Get(key string) ([]byte, error) {return f(key)
}?函數類型實現某一個接口,稱之為接口型函數,那么該函數也是接口。
其好處:當一個函數的參數類型是接口,那使用者在調用時既能夠傳入函數作為參數,也能夠傳入實現了該接口的結構體作為參數。
接口型函數不太理解的話,可以看Go接口型函數。
接口型函數在這章節的最后測試中也會進行講解的,測試中有例子。
?Group 的 Get 方法
首先從本地緩存中查找,若是有則直接返回該緩存數據即可。
若是緩存不存在(即是沒擊中),則調用 load?方法,調用用戶回調函數?g.getter.Get()?獲取源數據,并且將源數據添加到緩存 mainCache 中。
func (g *Group) Get(key string) (ByteView, error) {if v, ok := g.mainCache.get(key); ok {return v, nil}return g.load(key)
}func (g *Group) load(key string) (ByteView, error) {bytes, err := g.getter.Get(key)if err != nil {return ByteView{}, err}value := ByteView{b: cloneByte(bytes)}g.mainCache.add(key, value) //將源數據添加到緩存mainCachereturn value, nil
}至此,這一章節的單機并發緩存就已經完成了。
5.測試
// 緩存中沒有的話,就從該db中查找
var db = map[string]string{"tom": "100","jack": "200","sam": "444",
}// 統計某個鍵調用回調函數的次數
var loadCounts = make(map[string]int, len(db))創建 group 實例,并測試?Get?方法。
主要測試了兩種情況
- 1)在緩存為空的情況下,能夠通過回調函數獲取到源數據。
- 2)在緩存已經存在的情況下,是否直接從緩存中獲取,為了實現這一點,使用?
loadCounts?統計某個鍵調用回調函數的次數,如果次數大于1,則表示調用了多次回調函數,沒有緩存。
func main() {//傳函數入參 cache.GetterFunc(funcCbGet)是進行類型轉換,不是執行函數cache := cache.NewGroup("scores", 2<<10, cache.GetterFunc(funcCbGet))//傳結構體入參,也可以// cbGet := &search{}// cache := cache.NewGroup("scores", 2<<10, cbGet)for k, v := range db {if view, err := cache.Get(k); err != nil || view.String() != v {fmt.Println("failed to get value of ",k)}if _, err := cache.Get(k); err != nil || loadCounts[k] > 1 {fmt.Printf("cache %s miss", k)}}if view, err := cache.Get("unknown"); err == nil {fmt.Printf("the value of unknow should be empty, but %s got", view)}else {fmt.Println(err)}
}// 函數的
func funcCbGet(key string) ([]byte, error) {fmt.Println("callback search key: ", key)if v, ok := db[key]; ok {if _, ok := loadCounts[key]; !ok {loadCounts[key] = 0}loadCounts[key] += 1return []byte(v), nil}return nil, fmt.Errorf("%s not exit", key)
}// 結構體,實現了Getter接口的Get方法,
type search struct {
}func (s *search) Get(key string) ([]byte, error) {fmt.Println("struct callback search key: ", key)if v, ok := db[key]; ok {if _, ok := loadCounts[key]; !ok {loadCounts[key] = 0}loadCounts[key] += 1return []byte(v), nil}return nil, fmt.Errorf("%s not exit", key)
}討論接口型函數
NewGroup中的最后一個參數類型是接口類型。
這里既可以傳入函數,也可以傳入結構體變量。
而按照這個例子,傳入函數是很方便的。只寫一個函數就行,而做成結構體的話,還需要新建一個結構體類型,再實現Get方法,這就是很麻煩的。
這里可能就有疑惑了,大家通過這個例子明白,這樣做是既可以傳入函數,也可以傳入結構體變量。但從這例子來看,沒必要這樣做,就只是傳函數就行啦,沒必要把NewGroup的最后那個參數類型做成接口類型,只弄成函數類型就行啦。
這是這個例子的,要是在其他更加復雜的情況呢。比如:如果對數據庫的操作需要很多信息,地址、用戶名、密碼,還有很多中間狀態需要保持,比如超時、重連、加鎖等等。這種情況下,更適合將其封裝為一個結構體,再把該結構體傳入更好。
既能夠將普通的函數類型(需類型轉換)作為參數,也可以將結構體作為參數,使用更為靈活,可讀性也更好,這就是接口型函數的價值。
這樣就不用等我們想要用結構體傳參時候,發現類型不符合,傳參失敗就需要修改代碼,這時候就麻煩了。
完整代碼:https://github.com/liwook/Go-projects/tree/main/go-cache/2-single-node


















)
