1.Elasticsearch簡介
Elasticsearch是一個基于Lucene的一個開源的分布式、RESTful 風格的搜索和數據分析引擎。Elasticsearch是用Java語言開發的,并作為Apache許可條款下的開放源碼發布,是一種流行的企業級搜索引擎。Elasticsearch用于云計算中,能夠達到實時搜索,穩定,可靠,快速,安裝使用方便。官方客戶端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和許多其他語言中都是可用的。根據DB-Engines的排名顯示,Elasticsearch是最受歡迎的企業搜索引擎,其次是Apache Solr,也是基于Lucene。
2.Lucene 核心庫(紅黑二叉樹)
Lucene 可以說是當下最先進、高性能、全功能的搜索引擎庫——無論是開源還是私有,但它也僅僅只是一個庫。為了充分發揮其功能,你需要使用 Java 并將 Lucene 直接集成到應用程序中。 更糟糕的是,您可能需要獲得信息檢索學位才能了解其工作原理,因為Lucene 非常復雜。
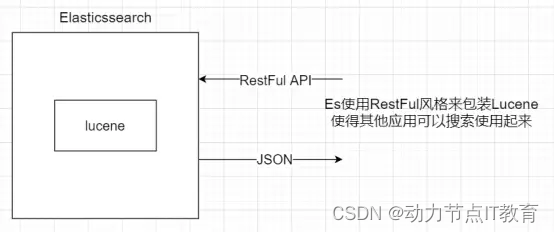
為了解決Lucene使用時的繁復性,于是Elasticsearch便應運而生。它使用 Java 編寫,內部采用 Lucene 做索引與搜索,但是它的目標是使全文檢索變得更簡單,簡單來說,就是對Lucene 做了一層封裝,它提供了一套簡單一致的 RESTful API 來幫助我們實現存儲和檢索。
3.和solr對比
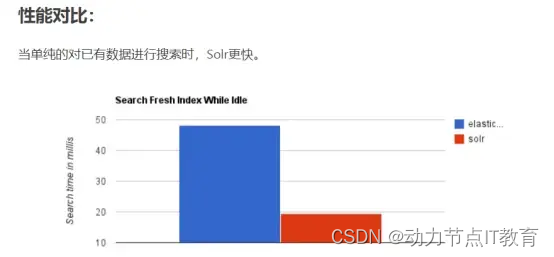
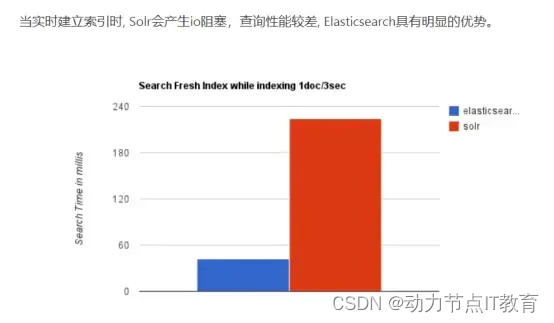
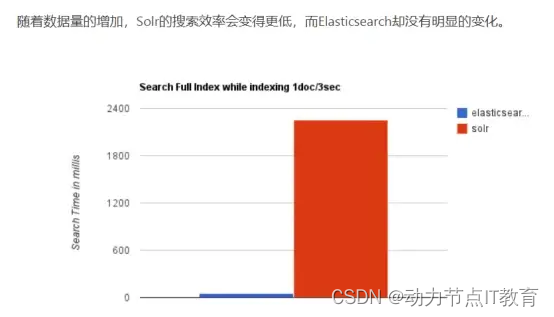
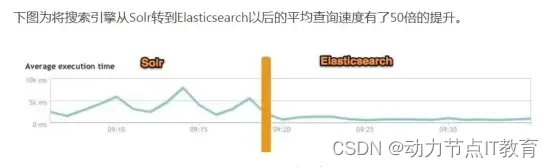
ElasticSearch 對比 Solr 總結
-
es基本是開箱即用,非常簡單。Solr安裝略微復雜一丟丟
-
Solr 利用 Zookeeper 進行分布式管理,而 Elasticsearch 自身帶有分布式協調管理功能。
-
Solr 支持更多格式的數據,比如JSON、XML、CSV,而 Elasticsearch 僅支持json文件格式。
-
Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高級功能多有第三方插件提供,例如圖形化界面需要kibana,head等友好支撐,分詞插件
-
Solr 查詢快,但更新索引時慢(即插入刪除慢),用于電商等查詢多的應用(之前);
ES建立索引快(即查詢慢),即實時性查詢快,用于推特 新浪等搜索。
Solr 是傳統搜索應用的有力解決方案,但 Elasticsearch 更適用于新興的實時搜索應用。
- Solr比較成熟,有一個更大,更成熟的用戶、開發和貢獻者社區,而 Elasticsearch相對開發維護者較少,更新太快,學習使用成本較高。 (現在es也比較火)
4.倒排索引(重點)
正排索引根據id 找到對應的一組數據 (B+tree 聚簇索引)
非聚簇索引:給一個字段建立索引,查詢的時候 根據這個字段查到這行數據對應的id
回表 再根據id 去查 聚簇索引 從而拿到一行數據
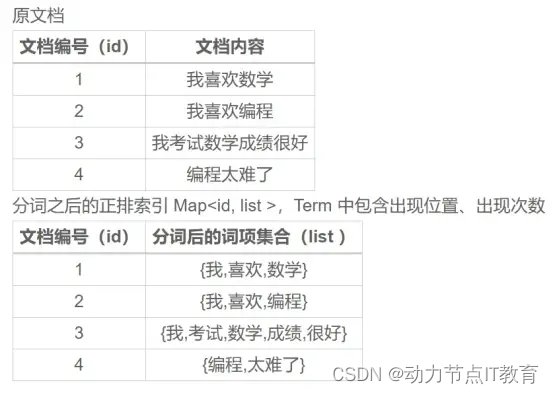
4.1 正排索引
4.2 倒排索引
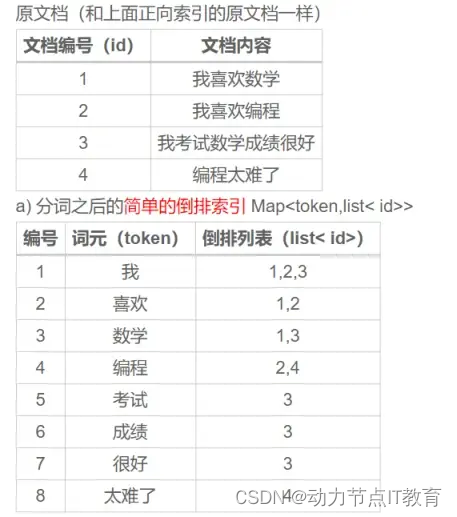
一個倒排索引由文檔中所有不重復詞的列表構成,對于其中每個詞,有一個包含它的 Term 列表。
5.分詞
就是按照一定的規則,將一句話分成組合的單詞,按照國人喜歡來進行的
海上生明月 - 如何分成 ----->海上 | 生 | 明月
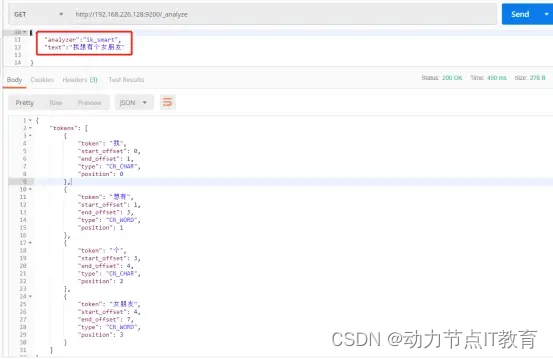
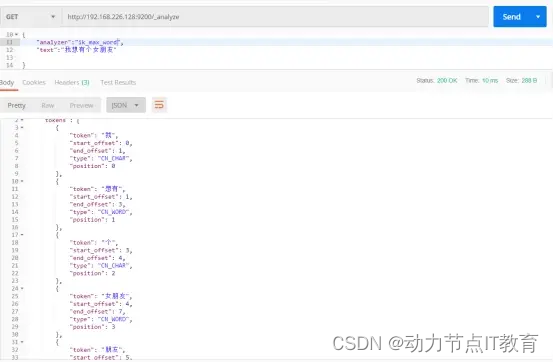
我想要個女朋友 ---- > 我|想要|要個|女朋友|朋友
6.模擬一個倒排索引
原理步驟:
-
將數據存入mysql之前,對其進行分詞
-
講分詞和存入后得到的id,存放在數據結構中Map<String,Set> index
-
查詢時先分詞,然后從index中拿到Set ids
-
再根據ids 查詢mysql,從而得到結果,這樣借助了mysql的B+tree索引,提高性能
6.1 創建boot項目選擇依賴
6.2 引入分詞的依賴
<dependency><groupId>com.huaban</groupId><artifactId>jieba-analysis</artifactId><version>1.0.2</version>
</dependency>
6.3 修改啟動類,注入結巴分詞器
/*** 往IOC容器中入住結巴分詞組件** @return*/
@Bean
public JiebaSegmenter jiebaSegmenter() {return new JiebaSegmenter();
}
6.4 測試分詞
@Autowired
public JiebaSegmenter jiebaSegmenter;@Test
void testJieBa() {String words = "華為 HUAWEI P40 Pro 麒麟990 5G SoC芯片 5000萬超感知徠卡四攝 50倍數字變焦 8GB+256GB零度白全網通5G手機";// 使用結巴分詞,對字符串進行分詞,分詞類型為搜索類型List<SegToken> tokens = jiebaSegmenter.process(words, JiebaSegmenter.SegMode.INDEX);// 遍歷,拿到SegToken對象中的word屬性,打印結果tokens.stream().map(token -> token.word).collect(Collectors.toList()).forEach(System.out::println);
}
6.5 使用商品搜索案例來展示倒排索引結構
6.5.1 新建Goods類
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Goods {/*** 商品的id*/private Integer goodsId;/*** 商品的名稱(主要分詞和檢索字段)*/private String goodsName;/*** 商品的價格*/private Double goodsPrice;}
6.5.2 模擬數據庫,新建DBUtil類
public class DBUtil {/*** 模擬數據庫,key=id,value=商品對象* 這里也可以使用List來模擬*/public static Map<Integer, Goods> db = new HashMap<>();/*** 插入數據庫** @param goods*/public static void insert(Goods goods) {db.put(goods.getGoodsId(), goods);}/*** 根據id得到商品** @param id* @return*/public static Goods getGoodsById(Integer id) {return db.get(id);}/*** 根據ids查詢商品集合** @param ids* @return*/public static List<Goods> getGoodsByIds(Set<Integer> ids) {if (CollectionUtils.isEmpty(ids)) {return Collections.emptyList();}List<Goods> goods = new ArrayList<>(ids.size() * 2);// 循環idsids.forEach(id -> {// 從數據庫拿到數據Goods g = db.get(id);if (!ObjectUtils.isEmpty(g)) {goods.add(g);}});return goods;}
}
6.5.3 創建倒排索引的數據結構
public class InvertedIndex {/*** 倒排索引 key = 分詞,value= ids*/public static Map<String, Set<Integer>> index = new HashMap<>();}
6.5.4 創建GoodsService接口
public interface GoodsService {/*** 添加商品的方法** @param goods*/void addGoods(Goods goods);/*** 根據商品名稱查詢** @param name* @return*/List<Goods> findGoodsByName(String name);/*** 根據關鍵字查詢** @param keywords* @return*/List<Goods> findGoodsByKeywords(String keywords);}
6.5.5 創建GoodsServiceImpl實現類
@Service
public class GoodsServiceImpl implements GoodsService {@Autowiredprivate JiebaSegmenter jiebaSegmenter;/*** 添加商品的方法* 1.先對商品名稱進行分詞,拿到了List<String> tokens* 2.將商品插入數據庫 拿到商品id* 3.將tokens和id放入倒排索引中index** @param goods*/@Overridepublic void addGoods(Goods goods) {// 分詞List<String> keywords = fenci(goods.getGoodsName());// 插入數據庫DBUtil.insert(goods);// 保存到倒排索引中saveToInvertedIndex(keywords, goods.getGoodsId());}/*** 保存到倒排索引的方法** @param keywords* @param goodsId*/private void saveToInvertedIndex(List<String> keywords, Integer goodsId) {// 拿到索引Map<String, Set<Integer>> index = InvertedIndex.index;// 循環分詞集合keywords.forEach(keyword -> {Set<Integer> ids = index.get(keyword);if (CollectionUtils.isEmpty(ids)) {// 如果之前沒有這個詞 就添加進去HashSet<Integer> newIds = new HashSet<>(2);newIds.add(goodsId);index.put(keyword, newIds);} else {// 說明之前有這個分詞 我們記錄idids.add(goodsId);}});}/*** 分詞的方法** @param goodsName* @return*/private List<String> fenci(String goodsName) {List<SegToken> tokens = jiebaSegmenter.process(goodsName, JiebaSegmenter.SegMode.SEARCH);return tokens.stream().map(token -> token.word).collect(Collectors.toList());}/*** 根據商品名稱查詢** @param name* @return*/@Overridepublic List<Goods> findGoodsByName(String name) {// 查詢倒排索引中 是否有這個詞Map<String, Set<Integer>> index = InvertedIndex.index;Set<Integer> ids = index.get(name);if (CollectionUtils.isEmpty(ids)) {// 查詢數據庫 模糊匹配去} else {// 說明分詞有 根據ids 查詢數據庫return DBUtil.getGoodsByIds(ids);}return Collections.emptyList();}/*** 根據關鍵字查詢** @param keywords* @return*/@Overridepublic List<Goods> findGoodsByKeywords(String keywords) {// 進來先把關鍵字分詞一下List<String> tokens = fenci(keywords);// 拿到倒排索引Map<String, Set<Integer>> index = InvertedIndex.index;Set<Integer> realIds = new HashSet<>();// 循環分詞集合 查詢倒排索引tokens.forEach(token -> {Set<Integer> ids = index.get(token);if (!CollectionUtils.isEmpty(ids)) {// 如果局部的ids不為空,就添加到總的ids里面去realIds.addAll(ids);}});// 查詢數據庫return DBUtil.getGoodsByIds(realIds);}
}
6.5.6 編寫測試類
@Autowired
public GoodsService goodsService;/*** 測試我們自己寫的倒排索引** @throws Exception*/
@Test
public void testMyIndex() throws Exception {// 造數據Goods goods = new Goods(1, "蘋果手機", 10.00);Goods goods1 = new Goods(2, "華為手機", 11.00);Goods goods2 = new Goods(3, "紅米手機", 5.00);Goods goods3 = new Goods(4, "聯想手機", 6.00);goodsService.addGoods(goods);goodsService.addGoods(goods1);goodsService.addGoods(goods2);goodsService.addGoods(goods3);// 查詢goodsService.findGoodsByName("蘋果手機").forEach(System.out::println);System.out.println("--------------------------------------------");goodsService.findGoodsByKeywords("蘋果手機").forEach(System.out::println);
}
7.Elasticsearch安裝
下載地址 https://www.elastic.co/cn/downloads/past-releases#elasticsearch
echo 3 > /proc/sys/vm/drop_caches
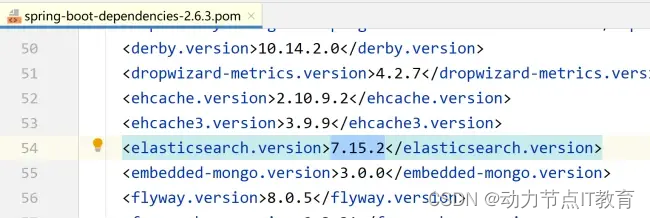
1.Docker拉取鏡像,我們選7.15.2版本,因為springboot的2.6.3版指定的是這個版本
docker pull elasticsearch:7.15.2
- 運行鏡像
docker run -d --name elasticsearch --net=host -p 9200:9200 -p 9300:9300 -e “discovery.type=single-node” -e ES_JAVA_OPTS=“-Xms256m -Xmx256m” elasticsearch:7.15.2
- 試訪問 ip:9200
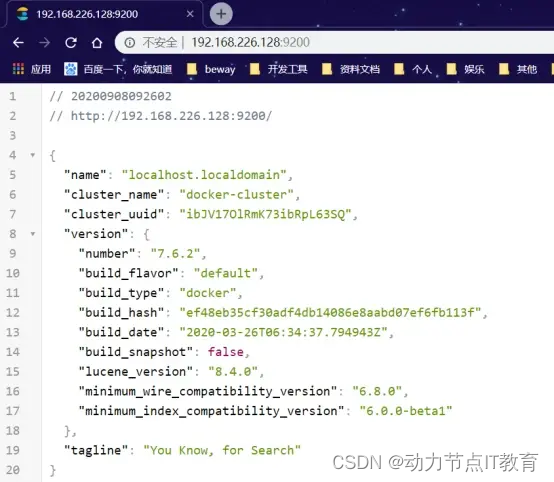
- 意外
錯誤:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144],你最少需要262144的內存
運行:sysctl -w vm.max_map_count=262144
重啟容器就ok 了
8.Elasticsearch目錄學習
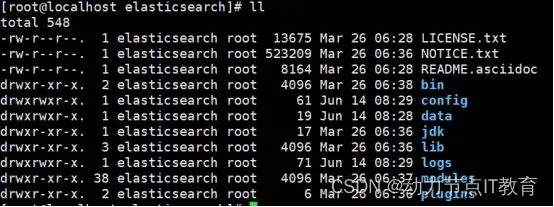
bin:啟動腳本
config:
elasticsearch.yml,ES的集群信息、對外端口、內存鎖定、數據目錄、跨域訪問等屬性的配置
jvm.options,ES使用Java寫的,此文件用于設置JVM相關參數,如最大堆、最小堆
log4j2.properties,ES使用log4j作為其日志框架
data:數據存放目錄(索引數據)
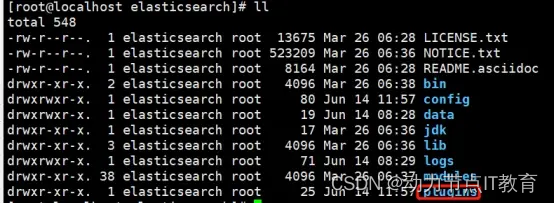
plugins: ES的可擴展插件存放目錄,如可以將ik中文分詞插件放入此目錄,ES啟動時會自動加載
9.Elasticsearch可視化插件的安裝
9.1 谷歌插件方式
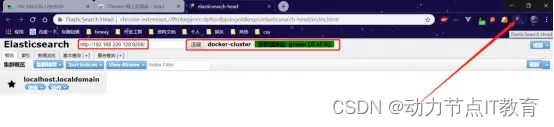
9.2 Docker鏡像方式安裝(和9.1選擇一個玩)
docker run --name eshead -p 9100:9100 -d mobz/elasticsearch-head:5
9.3 解決跨域問題
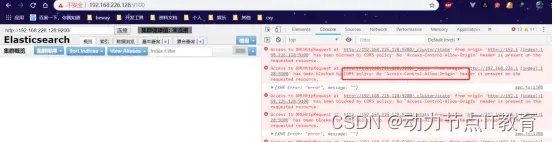
1.進入elasticsearch容器
docker exec -it elasticsearch bash
2.進入配置文件
cd /usr/share/elasticsearch/config
- 修改elasticsearch.yml配置文件,
vi elasticsearch.yml
- 結尾添加
http.cors.enabled: true
http.cors.allow-origin: “*”
- 重啟elasticsearch后訪問即可
docker restart elasticsearch
10.IK分詞的安裝【重點】**
Ik分詞在es 里面也是插件的形式安裝的
10.1 沒有ik分詞的時候

10.2 IK分詞安裝(方式一受網速影響)
- 找對應的ES版本的IK分詞
https://github.com/medcl/elasticsearch-analysis-ik/releases
-
進入容器 docker exec -it elasticsearch bash
-
進入這個目錄 /usr/share/elasticsearch/bin
-
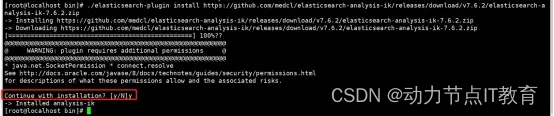
執行命令 install 后面的連接就是從上面找到的對應的版本下載鏈接
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.15.2/elasticsearch-analysis-ik-7.15.2.zip
- 下載完成
10.3 IK分詞安裝(方式二推薦)
-
找對應的ES版本的IK分詞 https://github.com/medcl/elasticsearch-analysis-ik/releases
-
下載到windows上
-
將zip文件拷貝到linux上
-
docker cp linux的路徑 elasticsearch:/usr/share/elasticsearch/plugins
-
進容器后解壓,注意名字unzip elasticsearch-analysis-ik-7.15.2.zip -d ./ik/
-
刪掉zip文件 elasticsearch-analysis-ik-7.15.2.zip
10.4 重啟ES測試
docker restart elasticsearch
Ik分詞的兩種方式:
ik_smart:分詞的粒度較小,也叫智能分詞
ik_max_word:分詞的粒度較大,也叫最大力度分詞
10.5 自定義分詞【了解】
進入容器
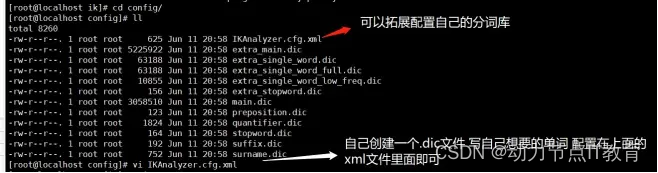
11.Elasticsearch核心概念【重點】
一個json串 叫文檔 es又被叫文檔性數據庫
11.1 結構說明
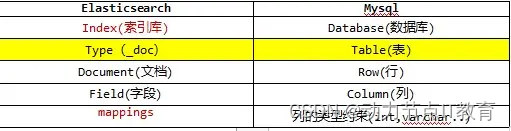
11.2 索引庫(indices)
把數據寫入elasticsearch 時,會在里面建立索引,索引庫里面存儲索引,一個index 對應一個database
11.3 文檔(document)
就是一條數據,一般使用json 表示,和數據庫對比,就是一行數據,在java 里面就是一個一個對象
11.4 字段(field)
一個對象的屬性,對應數據庫就是一列
11.5 節點
一臺運行elasticsearch的服務器,被稱為一個節點
11.6 集群
多個節點組成一個集群
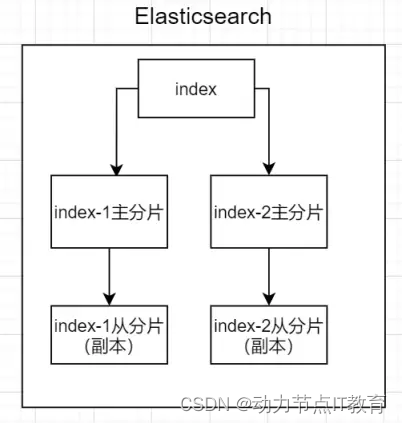
11.7 分片
一個索引可以存儲在多個主分片上,有負載均衡的作用,還有從分片是主分片的一個副本
11.8 副本
一份數據可以有多個副本,做數據冗余(安全),一般放在從分片里面
12.Elasticsearch基本使用(重點)
Elasticsearch 是基于restful風格的http應用
Restful風格就是使用http動詞形式對url資源進行操作(GET,POST,PUT,DELETE…)
操作格式為:
請求類型 ip:port/索引名/_doc/文檔id
{請求體}
12.1 對索引和mappings的操作(建庫建表約束)
12.1.1 新增索引
PUT http://192.168.226.128:9200/student 新建一個student索引,給定幾個字段約束
索引只能增刪,不能修改
{"mappings": {"properties": {"name":{"type": "text"},"age":{"type": "integer"},"birthDay":{"type": "date"},"price":{"type": "double"}}}}
查詢索引信息
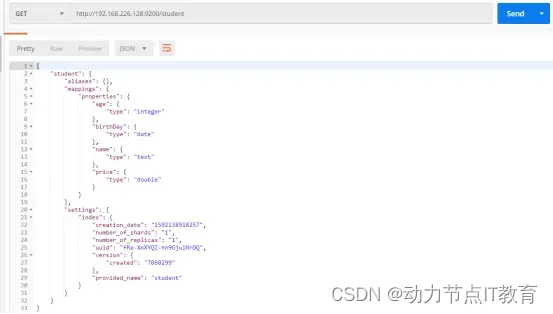
查詢索引的mappings信息
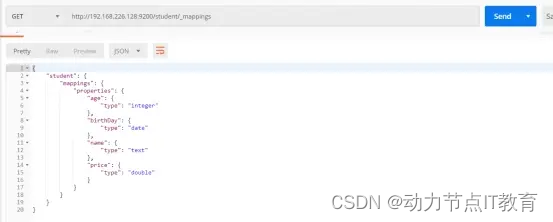
12.1.2 刪除索引
DELETE http://192.168.226.128:9200/student
12.2 對Document的操作
12.2.1 新增數據(方便后面演示,自己多新增幾條)
使用put請求新增時需要自己指定id,使用post請求新增時系統會自動生成一個id
PUT http://192.168.226.128:9200/user/_doc/1 請求解釋
user: 索引名稱
_doc:類型(即將剔除,官方建議全部使用_doc)
1: 文檔id
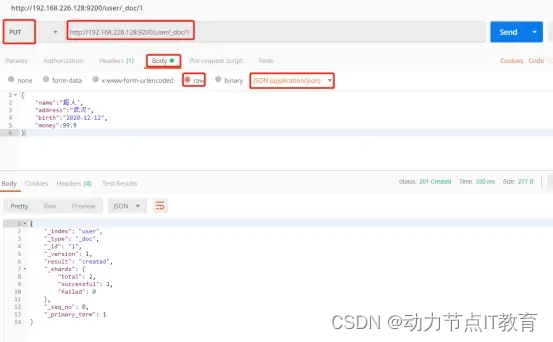
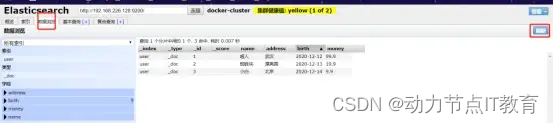
從head插件里面查看數據
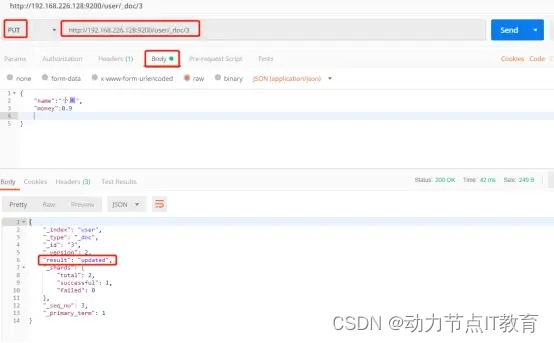
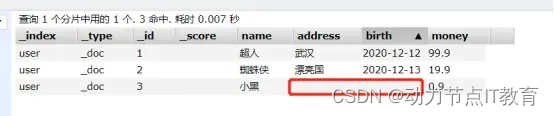
12.2.2 修改一個數據
- 危險的修改,把其他的字段值都刪了
PUT http://192.168.226.128:9200/user/_doc/2
- 安全的修改,其他的字段值會保留
POST http://192.168.226.128:9200/user/_doc/2/_update
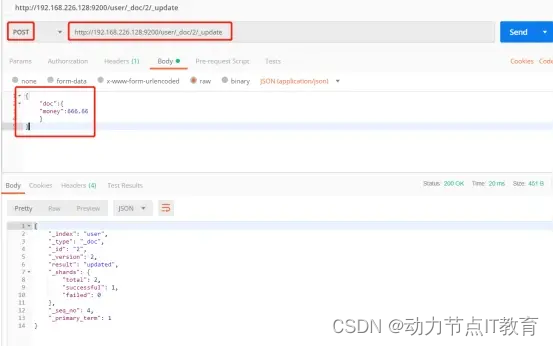
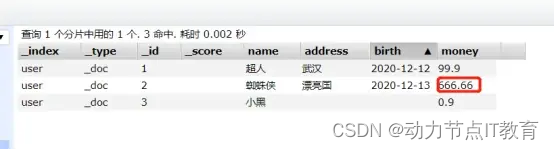
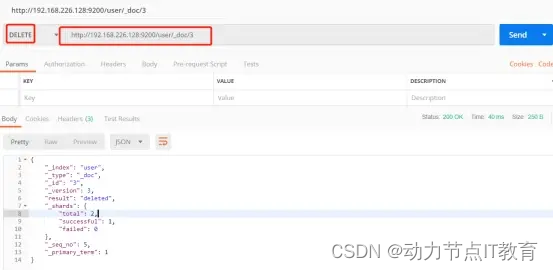
12.2.3 刪除一個數據
DELETE http://192.168.226.128:9200/user/_doc/3
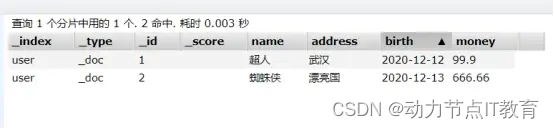
12.2.4 查詢一個數據
GET http://192.168.226.128:9200/user/_doc/1
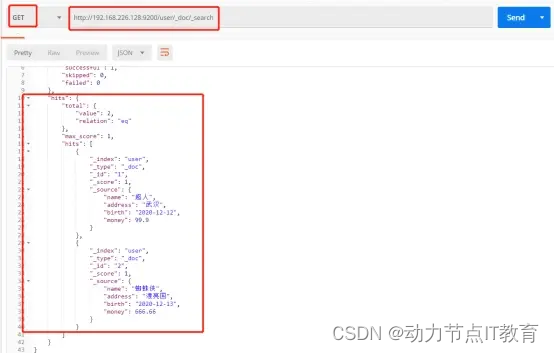
12.2.5 查詢全部數據
GET http://192.168.226.128:9200/user/_doc/_search
13.SpringBoot使用ES【重點】
13.1 新建項目選擇依賴
13.2 修改配置文件
spring:
elasticsearch:
uris: http://192.168.226.129:9200
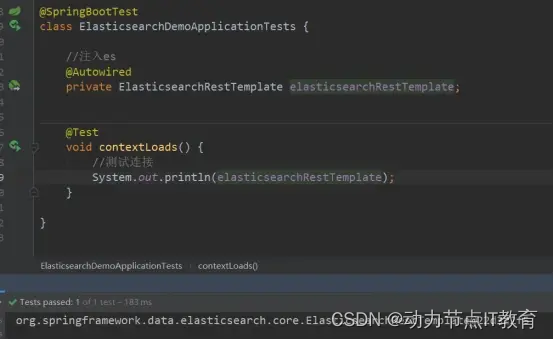
13.3 測試連接ES
說明我們連接成功,下面開始操作
13.4 對索引的操作,我們直接使用實體類操作
13.4.1 新建Goods實體類
/*** @Document是ES提供的注解 indexName:索引名稱* createIndex:啟動時是否創建* shards:分片個數* replicas:副本個數* refreshInterval:數據導入到索引里面,最多幾秒搜索到*/@Data
@AllArgsConstructor
@NoArgsConstructor
@Setting(shards = 2,replicas = 1,refreshInterval = "1s")
@Document(indexName = "goods_index")
public class Goods {/*** 商品ID*/@Id //默認使用keyword關鍵字模式,不進行分詞@Fieldprivate Integer goodsId;/*** 商品名稱* analyzer:導入時使用的分詞* searchAnalyzer:搜索時使用的分詞*/@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")private String goodsName;/*** 商品描述*/@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")private String goodsDesc;/*** 商品價格*/@Field(type = FieldType.Double)private Double goodsPrice;/*** 商品的銷量*/@Field(type = FieldType.Long)private Long goodsSaleNum;/*** 商品的賣點*/@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")private String goodsBrief;/*** 商品的狀態*/@Field(type = FieldType.Integer)private Integer goodsStatus;/*** 商品的庫存*/@Field(type = FieldType.Integer)private Integer goodsStock;/*** 商品的標簽*/@Field(type = FieldType.Text)private List<String> goodsTags;/*** 上架的時間* 指定時間格式化*/private Date goodsUpTime;}13.5 對文檔的操作,我們熟悉的CRUD
13.5.1 創建goodsDao
@Repository
public interface GoodsDao extends ElasticsearchRepository<Goods, Integer> {}
13.5.2 新增數據
@Autowired
private GoodsDao goodsDao;/*** 描述: 對document的curd** @param :* @return void*/
@Test
public void testDocumentCurd() throws Exception {//新增商品數據100條ArrayList<Goods> goods = new ArrayList<>(200);for (int i = 1; i <= 100; i++) {goods.add(new Goods(i,i % 2 == 0 ? "華為電腦" + i : "聯想電腦" + i,i % 2 == 0 ? "輕薄筆記本" + i : "游戲筆記本" + i,4999.9 + i,999L,i % 2 == 0 ? "華為續航強" : "聯想性能強",i % 2 == 0 ? 1 : 0,666 + i,i % 2 == 0 ? Arrays.asList("小巧", "輕薄", "續航") : Arrays.asList("炫酷", "暢玩", "游戲"),new Date()));}goodsDao.saveAll(goods);
}
13.5.3 修改數據(注意是危險修改)
@Test
public void testUpdate() throws Exception {goodsDao.save(new Goods(1, "小米筆記本", null, null, null, null, null, null, null, null));
}
13.5.4 刪除數據
@Test
public void testDelete() throws Exception{goodsDao.deleteById(1);
}13.5.5 根據id查詢數據
@Test
public void testSearchById() throws Exception {Optional<Goods> byId = goodsDao.findById(502);System.out.println(byId.get());
}13.5.6 查詢所有數據
@Test
public void testSearchAll() throws Exception {Iterable<Goods> all = goodsDao.findAll();all.forEach(System.out::println);
}
14.復雜的查詢操作【重點】
14.1 查詢注意點
match:會通過分詞器去模糊匹配 例如:華為電腦,會把包含‘華為’,‘電腦’,都查出來
matchPhrase:不分詞查詢,彌補了match和term
term:精確查找你的關鍵字,一般使用keywords的約束,使用term
rang:范圍查詢
match 和 rang 如果同時出現,需要組合bool查詢
分頁,排序是通用的查詢,不需要通過bool組合使用,直接nativeSearchQueryBuilder使用
14.2 查詢常用類
QueryBuilders:構造條件對象,例如matchQuery,rangeQuery,boolQuery等
NativeSearchQueryBuilder:組合條件對象,組合后使用build構建查詢對象
HighlightBuilder:高亮的查詢類,注意使用它的Field靜態內部類
FunctionScoreQueryBuilder:權重類,注意它的FilterFunctionBuilder靜態內部類
14.3 關鍵字,范圍,分頁,排序
@Test
public void testFuZaSearch() throws Exception {//關鍵字,“華為” ,范圍,分頁,排序MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("goodsName", "華為");RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("goodsStock").from(700).to(750);//使用bool組合這兩個查詢BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery().must(matchQueryBuilder).must(rangeQueryBuilder);//創建組合器NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();//去build()構建查詢對象NativeSearchQuery nativeSearchQuery = nativeSearchQueryBuilder.withQuery(boolQueryBuilder).withPageable(PageRequest.of(0, 20)) //注意范圍和分頁有關系,可能查出來了,但是當前分頁沒有.withSort(SortBuilders.fieldSort("goodsPrice").order(SortOrder.ASC)).build();//使用es查詢 得到結果集SearchHits<Goods> searchHits = elasticsearchRestTemplate.search(nativeSearchQuery, Goods.class);searchHits.forEach(goodsSearchHit -> {//循環結果集,答應結果System.out.println(goodsSearchHit.getContent());});
}
14.4 高亮查詢
@Testpublic void testHighlight() throws Exception {//華為,模糊匹配MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("goodsName", "華為");HighlightBuilder.Field goodsName = new HighlightBuilder.Field("goodsName").preTags("<span style='color:red'>").postTags("</span>");NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();NativeSearchQuery nativeSearchQuery = nativeSearchQueryBuilder.withQuery(matchQueryBuilder).withHighlightFields(goodsName).build();//得到結果集 我們需要手動組裝高亮字段SearchHits<Goods> searchHits = elasticsearchRestTemplate.search(nativeSearchQuery, Goods.class);List<Goods> goodsArrayList = new ArrayList<>();searchHits.forEach(goodsSearchHit -> {//得到goods對象,但是這里面額goodsName屬性不是高亮的,所以要改Goods goods = goodsSearchHit.getContent();List<String> highlightField = goodsSearchHit.getHighlightField("goodsName");String highlight = highlightField.get(0);goods.setGoodsName(highlight);goodsArrayList.add(goods);});System.out.println(JSON.toJSONString(goodsArrayList));}
}
14.5 權重查詢
@Test
public void testWeight() throws Exception {//手機名稱 和賣點 都有的情況下,設置權重查詢String keyWords = "華為";//創建權重數組FunctionScoreQueryBuilder.FilterFunctionBuilder[] functionBuilders = new FunctionScoreQueryBuilder.FilterFunctionBuilder[2];//設置權重functionBuilders[0] = (new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.matchQuery("goodsName", keyWords),ScoreFunctionBuilders.weightFactorFunction(10)//給名稱設置10的權重大小));functionBuilders[1] = (new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.matchQuery("goodsBrief", keyWords),ScoreFunctionBuilders.weightFactorFunction(4)//給賣點設置4的權重));FunctionScoreQueryBuilder functionScoreQueryBuilder = new FunctionScoreQueryBuilder(functionBuilders);functionScoreQueryBuilder.setMinScore(2) //設置最小分數.scoreMode(FunctionScoreQuery.ScoreMode.FIRST);//設置計分方式NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder().withQuery(functionScoreQueryBuilder).build();SearchHits<Goods> searchHits = elasticsearchRestTemplate.search(nativeSearchQuery, Goods.class);searchHits.forEach(goodsSearchHit -> {//循環結果集,答應結果System.out.println(goodsSearchHit.getContent());});
}
15.ES集群(了解)
這里使用windows方式演示集群
Linux上的集群道理一樣,修改配置文件即可
可以參考https://my.oschina.net/u/4353003/blog/4333773
15.1 創建三個es節點
解壓出三個來

15.2 修改配置文件
15.2.1 Node1修改配置文件
進入elasticsearch-7.15.2-node1\config下,修改elasticsearch.yml
# 設置集群名稱,集群內所有節點的名稱必須一致。cluster.name: my-esCluster# 設置節點名稱,集群內節點名稱必須唯一。node.name: node1# 表示該節點會不會作為主節點,true表示會;false表示不會node.master: true# 當前節點是否用于存儲數據,是:true、否:falsenode.data: true# 索引數據存放的位置#path.data: /opt/elasticsearch/data# 日志文件存放的位置#path.logs: /opt/elasticsearch/logs# 需求鎖住物理內存,是:true、否:false#bootstrap.memory_lock: true# 監聽地址,用于訪問該esnetwork.host: 0.0.0.0# es對外提供的http端口,默認 9200http.port: 9200# TCP的默認監聽端口,默認 9300transport.tcp.port: 9300# 設置這個參數來保證集群中的節點可以知道其它N個有master資格的節點。默認為1,對于大的集群來說,可以設置大一點的值(2-4)discovery.zen.minimum_master_nodes: 2# es7.x 之后新增的配置,寫入候選主節點的設備地址,在開啟服務后可以被選為主節點discovery.seed_hosts: ["192.168.186.1:9300", "192.168.186.1:9301", "192.168.186.1:9302"]discovery.zen.fd.ping_timeout: 1mdiscovery.zen.fd.ping_retries: 5# es7.x 之后新增的配置,初始化一個新的集群時需要此配置來選舉mastercluster.initial_master_nodes: ["node1", "node2", "node3"]# 是否支持跨域,是:true,在使用head插件時需要此配置http.cors.enabled: true# “*” 表示支持所有域名http.cors.allow-origin: "*"action.destructive_requires_name: trueaction.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*xpack.security.enabled: falsexpack.monitoring.enabled: truexpack.graph.enabled: falsexpack.watcher.enabled: falsexpack.ml.enabled: false
15.2.2 Node2修改配置文件
# 設置集群名稱,集群內所有節點的名稱必須一致。cluster.name: my-esCluster# 設置節點名稱,集群內節點名稱必須唯一。node.name: node2# 表示該節點會不會作為主節點,true表示會;false表示不會node.master: true# 當前節點是否用于存儲數據,是:true、否:falsenode.data: true# 索引數據存放的位置#path.data: /opt/elasticsearch/data# 日志文件存放的位置#path.logs: /opt/elasticsearch/logs# 需求鎖住物理內存,是:true、否:false#bootstrap.memory_lock: true# 監聽地址,用于訪問該esnetwork.host: 0.0.0.0# es對外提供的http端口,默認 9200http.port: 9201# TCP的默認監聽端口,默認 9300transport.tcp.port: 9301# 設置這個參數來保證集群中的節點可以知道其它N個有master資格的節點。默認為1,對于大的集群來說,可以設置大一點的值(2-4)discovery.zen.minimum_master_nodes: 2# es7.x 之后新增的配置,寫入候選主節點的設備地址,在開啟服務后可以被選為主節點discovery.seed_hosts: ["192.168.186.1:9300", "192.168.186.1:9301", "192.168.186.1:9302"]discovery.zen.fd.ping_timeout: 1mdiscovery.zen.fd.ping_retries: 5# es7.x 之后新增的配置,初始化一個新的集群時需要此配置來選舉mastercluster.initial_master_nodes: ["node1", "node2", "node3"]# 是否支持跨域,是:true,在使用head插件時需要此配置http.cors.enabled: true# “*” 表示支持所有域名http.cors.allow-origin: "*"action.destructive_requires_name: trueaction.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*xpack.security.enabled: falsexpack.monitoring.enabled: truexpack.graph.enabled: falsexpack.watcher.enabled: falsexpack.ml.enabled: false
15.2.3 Node3修改配置文件
# 設置集群名稱,集群內所有節點的名稱必須一致。cluster.name: my-esCluster# 設置節點名稱,集群內節點名稱必須唯一。node.name: node3# 表示該節點會不會作為主節點,true表示會;false表示不會node.master: true# 當前節點是否用于存儲數據,是:true、否:falsenode.data: true# 索引數據存放的位置#path.data: /opt/elasticsearch/data# 日志文件存放的位置#path.logs: /opt/elasticsearch/logs# 需求鎖住物理內存,是:true、否:false#bootstrap.memory_lock: true# 監聽地址,用于訪問該esnetwork.host: 0.0.0.0# es對外提供的http端口,默認 9200http.port: 9202# TCP的默認監聽端口,默認 9300transport.tcp.port: 9302# 設置這個參數來保證集群中的節點可以知道其它N個有master資格的節點。默認為1,對于大的集群來說,可以設置大一點的值(2-4)discovery.zen.minimum_master_nodes: 2# es7.x 之后新增的配置,寫入候選主節點的設備地址,在開啟服務后可以被選為主節點discovery.seed_hosts: ["192.168.186.1:9300", "192.168.186.1:9301", "192.168.186.1:9302"]discovery.zen.fd.ping_timeout: 1mdiscovery.zen.fd.ping_retries: 5# es7.x 之后新增的配置,初始化一個新的集群時需要此配置來選舉mastercluster.initial_master_nodes: ["node1", "node2", "node3"]# 是否支持跨域,是:true,在使用head插件時需要此配置http.cors.enabled: true# “*” 表示支持所有域名http.cors.allow-origin: "*"action.destructive_requires_name: trueaction.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*xpack.security.enabled: falsexpack.monitoring.enabled: truexpack.graph.enabled: falsexpack.watcher.enabled: falsexpack.ml.enabled: false
15.3 啟動es
進入bin目錄下 逐個啟動,三臺全部雙擊啟動,注意不要關閉黑窗口
15.4 訪問查看集群信息和狀態
訪問查看:http://127.0.0.1:9200/_cat/nodes
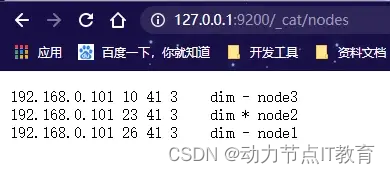
也可以使用head插件查看
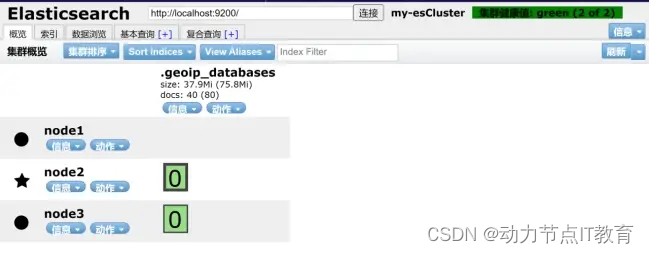
15.5 SpringBoot連接es集群
spring:
elasticsearch:
uris:
- http://127.0.0.1:9200
- http://127.0.0.1:9201
- http://127.0.0.1:9202
16.Es總結面試
16.1 為什么使用es (結合項目業務來說)
商城中的數據,將來會非常多,所以采用以往的模糊查詢,模糊查詢前置配置,會放棄索引,(%name%)導致商品查詢是全表掃描,在百萬級別的數據庫中,效率非常低下,而我們使用ES做一個全文索引,我們將經常查詢的商品的某些字段,比如說商品名,描述、價格還有id這些字段我們放入我們索引庫里,可以提高查詢速度。 (數據量過大,而且用戶經常使用查詢的場景,對用戶體驗很好)
16.2 es用來做什么(場景)重點
-
商品存放 (業務數據的存放) 每個商品都是一個對象
-
日志統計 (整個應用的日志非常多,都要收集起來,方便后期做日志分析,數據回溯)
-
數據分析(大數據)(只要是電商,就要和tb,jd等對比價格,做數據分析等)
你做一個電商項目 你賣鞋子 衣服 你怎么 定價 鞋子 199 599 398
你寫個爬蟲 定期采集tb jd的數據庫 做數據比對分析 做 競品 分析
定期的做數據采集和分析 數據采集系統 定時任務去采集別的大型電商網站的數據,進行價格分析,從而定價,后期還要做競品分析
16.3 什么是倒排索引
通常正排索引是通過id映射到對應的數據
倒排索引是將分詞建立索引,通過分詞映射到id,在通過id找到數據
詳見文檔4.2
16.4 es的存儲數據的過程
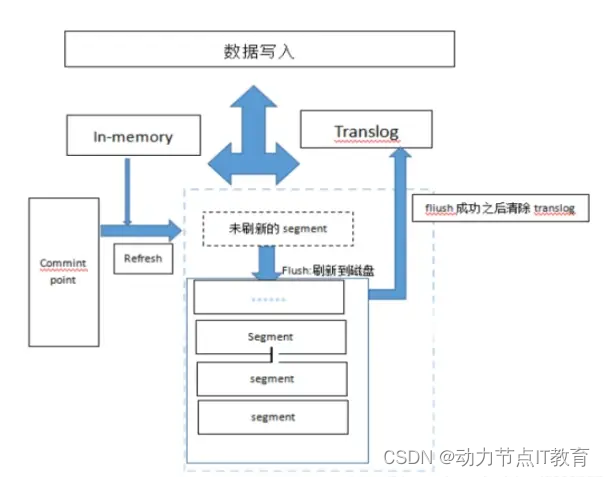
1:寫入請求,分發節點。
2:數據寫入同時寫入內存和translog各一份,tanslog為保證數據不丟失,每 5 秒,或每次請求操作結束前,會強制刷新 translog 日志到磁盤上
3:確定數據給那個分片,refresh 刷新內存中數據到分片的segment,默認1秒刷新一次,為了提高吞吐量可以增大60s。參數refresh_interval(refresh操作使得寫入文檔搜索可見)
4:通過flush操作將segment刷新到磁盤中完成持久化,保存成功清除translog,新版本es的 translog 不會在 segment 落盤就刪,而是會保留,默認是512MB,保留12小時。每個分片。所以分片多的話 ,要考慮 translog 會帶來的額外存儲開銷(flush操作使得filesystem cache寫入磁盤,以達到持久化的目的) (refresh之前搜索不可見)
5:segment過多會進行合并merge為大的segment,消耗大量的磁盤io和網絡io (方便數據整理和磁盤優化)
16.5 es的搜索過程
1、搜索被執行成一個兩階段過程,我們稱之為 Query Then Fetch;
2、在初始查詢階段時,查詢會廣播到索引中每一個分片拷貝(主分片或者副本分
片)。 每個分片在本地執行搜索并構建一個匹配文檔的大小為 from + size 的
優先隊列。
注意:在搜索的時候是會查詢 Filesystem Cache 的,但是有部分數據還在 Memory
Buffer,所以搜索是接近實時的。
3、每個分片返回各自優先隊列中所有文檔的 ID 和排序值給協調節點(主節點),它合并
這些值到自己的優先隊列中來產生一個全局排序后的結果列表。
4、接下來就是 取回階段,協調節點辨別出哪些文檔需要被取回并向相關的分片
提交多個 GET 請求。每個分片加載并 豐富 文檔,如果有需要的話,接著返回
文檔給協調節點。一旦所有的文檔都被取回了,協調節點返回結果給客戶端。
通俗的將就是:
每個分片先拿到id和排序值,然后整合成一個全局列表
然后通過判斷找到相應的節點提交多個get請求,組裝數據返回
https://javajl.yuque.com/docs/share/61000afe-fc17-4bb7-9279-63bfba5fd6cc?# 《Elasticsearch 7.x(入門)》密碼:yk91


】)

)
)
)






![[Makefile] include 關鍵字](http://pic.xiahunao.cn/[Makefile] include 關鍵字)
--安全滲透簡介)




