3.4 虛擬內存
直接使?物理內存會產??些問題
1. 內存空間利?率的問題:各個進程對內存的使?會導致內存碎?化,當要? malloc 分配?塊很?的內存空間時,可能會出現雖然有?夠多的空閑物理內存,卻沒有?夠?的連續空閑內存這種情況
2. 讀寫內存的安全性問題:物理內存本身是不限制訪問的,任何地址都可以讀寫
3. 進程間的安全問題:各個進程之間沒有獨?的地址空間,?個進程由于執?錯誤指令或是惡意代碼都可以直接修改其它進程的數據,甚?修改內核地址空間的數據,這是操作系統所不愿看到的
4. 內存讀寫的效率問題:當多個進程同時運?,需要分配給進程的內存總和?于實際可?的物理內存時,需要將其他程序暫時拷?到硬盤當中,然后將新的程序裝?內存運?。由于?量的數據頻繁裝?裝出,內存的使?效率會?常低虛擬內存 虛擬內存是計算機系統內存管理的?種技術。它使得應?程序認為它擁有連續可?的內存,?實際上,它通常是被分隔成多個物理內存碎?,還有部分暫時存儲在外部磁盤存儲器上,在需要時進?數據交換。 [1] 虛擬內存有什么作??
● 解決了多進程之間地址沖突的問題。由于每個進程都有??的?表,進程也沒有辦法訪問其他進程的?表,所以每個進程的虛擬內存空間就是相互獨?的。
● 在內存訪問??,操作系統提供了更好的安全性。?表?的?表項中除了物理地址之外,還有?些標記屬性,?如控制?個?的讀寫權限,標記該?是否存在等。
????????虛擬地址空間
? 對于?個單?進程的概念,這個進程看到的將是地址從0開始的整個內存空間。虛擬存儲器是?個抽象概念,它為每?個進程提供了?個假象,好像每個進程都在獨占主存,每個進程看到的存儲器是?致的,稱為虛擬地址空間。在 Linux 操作系統中,虛擬地址空間的內部?被分為內核空間和?戶空間兩部分,不同位數的系統,地址空間的范圍也不同。?如最常?的 32 位和 64 位系統,如下所示。雖然每個進程都各?有獨?的虛擬內存,但是每個虛擬內存中的內核地址,其實關聯的都是相同的物理內存。這樣,進程切換到內核態后,就可以很?便地訪問內核空間內存。
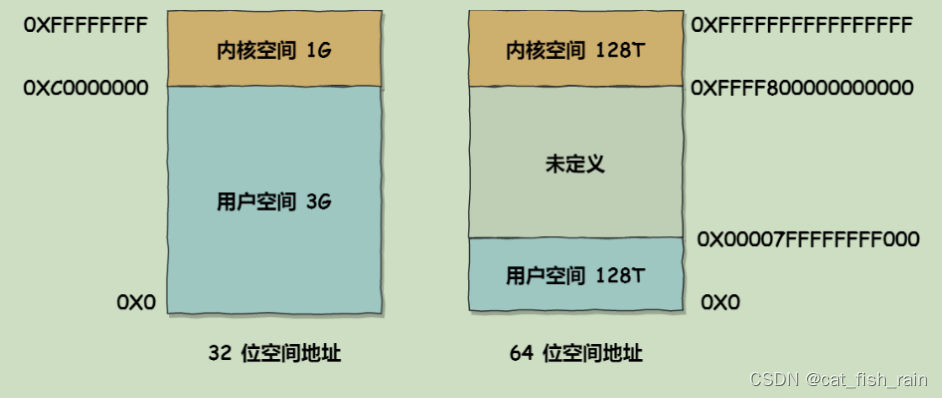
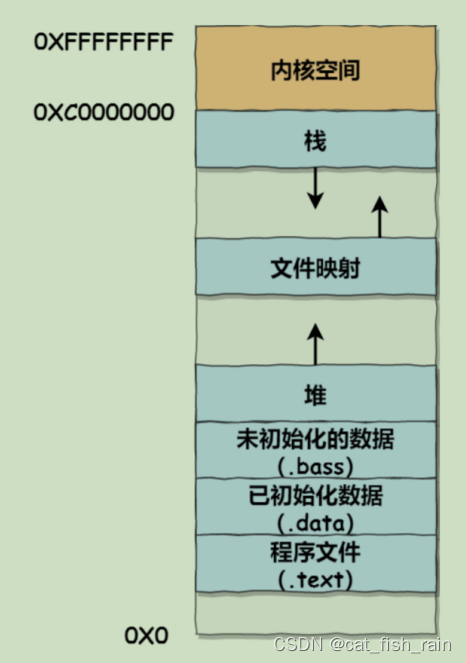
?戶空間內存,從低到?分別是 6 種不同的內存段:
● 程序?件段(.text),包括?進制可執?代碼;
● 已初始化數據段(.data),包括靜態常量;
● 未初始化數據段(.bss),包括未初始化的靜態變量;
● 堆段,包括動態分配的內存,從低地址開始向上增?;
● ?件映射段,包括動態庫、共享內存等,從低地址開始向上增?;
● 棧段,包括局部變量和函數調?的上下?等。棧的??是固定的,?般是 8 MB。當然系統也提供了參數,以便我們?定義??;
???????? 
虛擬內存實現思路
1. 在系統中為每個程序定義?個虛擬地址空間,虛擬地址空間中的地址都是連續的
2. 虛擬地址空間被分割成多個塊,每塊稱為?個?或者??
3. 物理內存被分成和????相同的多個區域,稱作?框
4. 程序加載時,可將任意?個??放?內存中的任意?個?框
5. CPU 的硬件負責將虛擬地址映射到物理內存中的地址(?? -> ?框)
6. 程序的整個地址空間?需全部載?物理內存,還有部分暫時存儲在外存上,需要時再換?內存
7. 如果程序引?到?部分不在虛擬地址時,會發?缺?中斷,由操作系統負責將缺失的??加載??框中,并重新執?失敗的指令
????????
內存管理單元(MMU):將CPU中 負責地址轉換 的部分統稱為內存管理單元。利?地址轉換,操作系統就可以控制進程的所有內存訪問,確保訪問在地址空間的界限內。這個技術的關鍵是硬件?持,硬件可以快速地將內存訪問操作中的虛擬地址轉換為物理地址。對于?個?式內存地址轉換,有三個步驟:
● 把虛擬內存地址,切分成?號和偏移量;
● 根據?號,從?表??,查詢對應的物理?號;
● 直接拿物理?號,加上前?的偏移量,就得到了物理內存地址。
TLB 的原理
現代操作系統中,?表的個數是很多的,?每次執?語句時都需要先查找?表,將虛擬地址轉換為物理內存地址。這部分切換的時間開銷是很?的。因此,解決?案是為計算機設置?個轉換檢測緩沖區(TLB,translation-lookaside buffer),是 MMU(內存管理單元)的?部分。它提供?個緩沖區, 89 記錄虛擬??號到物理?框號的映射,這樣可以在 O(1) 的時間?直接將虛擬??映射到物理?框,不需要訪問?表,從?節省時間。
?作流程:如果??號在 TLB 中,得到?框號,訪問內存;否則,從內存中的?表中得到?框號,將其存? TLB,訪問內存。
內存管理?法
段式內存管理:按照邏輯意義將程序分成若?個段,每個段獨?載?到內存的不同區間中,通過段表對物理地址進?映射
優點:按照邏輯關系劃分,能產?連續的內存空間。
缺點:每個段必須連續、全部加載到內存中,會產?內存碎?;連續空間不?,與硬盤交互導致內存交換的效率低的問題。
?式內存管理:?式管理把內存空間按?的??劃分成若???,然后把?式虛擬地址與內存地址建? ??對應的?表。?當進程訪問的虛擬地址在?表中查不到時,系統會產??個缺?異常,進?系統內核空間分配物理內存、更新進程?表,最后再返回?戶空間,恢復進程的運?。
優點:不存在外部碎?,只在每個進程的最后?個?中存在內部碎?
缺點:程序全部裝?內存,要求有相應的硬件?持。例如地址轉換模塊缺?中斷的產?和選擇淘汰??等都要求有相應的硬件?持。這增加了機器成本和系統開銷。
段?式內存管理:把分段和分?兩種?式結合,先把程序按照邏輯意義分成段,然后每個段再分成固定??的?。這樣,地址結構就由段號、段內?號和?內位移三部分組成。Linux 系統主要采?了分?管理,但是由于 Intel 處理器的發展史,Linux 系統?法避免分段管理。于是 Linux 就把所有段的基地址設為 0,也就意味著所有程序的地址空間都是線性地址空間(虛擬地址),相當于屏蔽了 CPU 邏輯地址的概念,所以段只被?于訪問控制和內存保護。
??放置算法
????????空閑鏈表與內存池:https://zhuanlan.zhihu.com/p/73468738
1. 最佳適應算法:檢查所有空閑分區,選擇和新進程申請內存??最接近的空閑分區
優點:該算法保留?的空閑區
缺點:檢查所有空閑分區需要時間。外部碎?多:會留下許多難以利?的,很?的空閑分區,稱為外部碎?。可以采?內存緊湊的?法,將被使?的分區都移動到?起,減少外部碎?。但是移動內存中的代碼和數據也需要很多時間
2. 最差適應算法:每次為進程分配分區時,都選擇最?的空閑分區分配。最差適應算法使鏈表中的結點??趨于均勻,適?于請求分配的內存??范圍較窄的系統
優點:該算法保留?的空閑區,盡量減少外部碎?的產?
缺點:檢查?較所有的空閑區間需要時間;系統中不會存在?積很?的空閑區間,難滿??進程的要求
3. ?次適應法:只要發現能?的分區就分配。這種?法?的在于減少查找時間。為適應這種算法,空閑分區表(空閑區鏈)中的空閑分區要按地址由低到?進?排序。該算法優先使?低址部分空閑
區,在低址空間造成許多?的空閑區,在?地址空間保留?的空閑區
優點:可以剩下?的分區
缺點:外部碎?多,集中在低址部分;并且每次查找都是從低址部分開始的,這?疑?會增加查找可?空閑分區時的開銷
4. 下次適應法:操作系統記住接下來該檢查的空閑分區的位置,給進程分配分區時,系統從記錄的分區開始依次向后查找直到碰到能?的分區為?,如果到鏈表尾還沒有找到,就再從頭開始
缺點:很難剩下?積很?的區間,會使剩余分區的???較平均。
??置換算法
當出現缺?異常需調?新???內存已滿時,選擇被置換的物理??,也就是說選擇?個物理??換出到磁盤,然后把需要訪問的??換?到物理?。
1. 最佳??置換算法:置換在「未來」最?時間不訪問的??。最佳??置換算法作?是為了衡量你的算法的效率,你的算法效率越接近該算法的效率,那么說明你的算法是?效的。
2. 先進先出置換算法(FIFO):直接換出最早裝?的??。
優點:簡單
缺點:性能不是很好,因為它淘汰的可能是常?的??
適?場景:數據只??次,將來不太可能使?;
3. 時鐘置換法(Clock):將??保存在環形鏈表中,只需要后移隊頭指針。如果該位為 0,淘汰該?;如果該位為 1,將該位設為 0
優點:避免了移動鏈表節點的開銷
4. 最近最少使?法(LRU:Least Recently Used):優先淘汰最久未被訪問的??。根據局部性原理,?個進程在?段時間內要訪問的指令和數據都集中在?起。如果?個??很久沒有被訪問,那么將來被訪問的可能性也?較?。
優點:實驗證明 LRU 的性能較好,能夠降低置換頻率
缺點:存在緩存污染問題,即由于偶發性或周期性的冷數據批量查詢,熱點數據被擠出去,導致緩存命中率下降
適?場景:訪問分布未知的情況
5. 最少頻率使?法(LFU:Least Frequently Used):優先淘汰最近訪問頻率最少的數據。
優點:能夠避免緩存污染問題對 LRU 的命中影響
缺點:存在訪問模式問題,即如果訪問內容發?較?變化,LFU 需要?更?的時間來適應,導致緩存命中率下降;維護相關數據結構的開銷?
6. 隨機淘汰法(Random):實現簡單,不需要保留有關訪問歷史記錄的任何信息
適?場景:如果應?對于緩存的訪問概率相等,則可以使?這個算法。
磁盤調度算法
為了提?磁盤的訪問性能,?般是通過優化磁盤的訪問請求順序來做到的。尋道的時間是磁盤訪問最 耗時的部分,如果請求順序優化得當,必然可以節省?些不必要的尋道時間,從?提?磁盤的訪問性能。
1. 先來先服務
2. 最短尋道時間優先(Shortest Seek First,SSF)算法:優先選擇從當前磁頭位置所需尋道時間最短的請求。但這個算法可能存在某些請求的饑餓
3. 掃描算法:為了防?上述饑餓問題,可以規定:磁頭在?個?向上移動,訪問所有未完成的請求,直到磁頭到達該?向上的最后的磁道,才調換?向,這就是掃描(Scan)算法。
4. 循環掃描(Circular Scan, CSCAN ):只有磁頭朝某個特定?向移動時,才處理磁道訪問請求,?返回時直接快速移動?最靠邊緣的磁道,也就是復位磁頭,這個過程是很快的,并且返回中途不處理任何請求,該算法的特點,就是磁道只響應?個?向上的請求。
5. LOOK 與 C-LOOK算法:掃描算法和循環掃描算法,都是磁頭移動到磁盤「最始端或最末端」才開始調換?向。優化的思路就是磁頭在移動到「最遠的請求」位置,然后?即反向移動。
內存不?會發?什么
????????
主要有兩類內存可以被回收,?且它們的回收?式也不同。?件?和匿名?的回收都是基于 LRU 算法,也就是優先回收不常訪問的內存。
● ?件?:內核緩存的磁盤數據(Buffer)和內核緩存的?件數據(Cache)都叫作?件?。?部分?件?,都可以直接釋放內存,以后有需要時,再從磁盤重新讀取就可以了。?那些被應?程序修改過,并且暫時還沒寫?磁盤的數據(也就是臟?),就得先寫?磁盤,然后才能進?內存釋放。所以,回收?凈?的?式是直接釋放內存,回收臟?的?式是先寫回磁盤后再釋放內存。
● 匿名?:這部分內存沒有實際載體,不像?件緩存有硬盤?件這樣?個載體,?如堆、棧數據等。這部分內存很可能還要再次被訪問,所以不能直接釋放內存,它們回收的?式是通過 Linux 的
Swap 機制,Swap 會把不常訪問的內存先寫到磁盤中,然后釋放這些內存。再次訪問這些內存 時,重新從磁盤讀?內存就可以了。
在 4GB 物理內存的機器上,申請 8G 內存會怎么樣?
這個問題要考慮三個前置條件:
● 操作系統是 32 位的,還是 64 位的?因為 32 位操作系統,進程最多只能申請 3 GB ??的虛擬
內存空間,所以進程申請 8GB 內存的話,在申請虛擬內存階段就會失敗
● 申請完 8G 內存后會不會被使??程序申請的是虛擬內存,如果沒有被使?,它是不會占?物理空間的。當訪問這塊虛擬內存后,操作系統才會進?物理內存分配。
● 操作系統有沒有使? Swap 機制?如果沒有開啟 Swap 機制,程序就會直接 OOM(內存溢出簡稱OOM,是指應?系統中存在?法回收的內存或使?的內存過多,最終使得程序運?要?到的內存?于能提供的最?內存);如果有開啟 Swap 機制,程序可以正常運?。
3.5 緩存區
緩存區溢出
C 語?使?運?時棧來存儲過程信息。每個函數的信息存儲在?個棧幀中,包括寄存器、局部變量、參數、返回地址等。C 對于數組引?不進?任何邊界檢查,因此對越界的數組元素的寫操作會破壞存儲在棧中的狀態信息,這種現象稱為緩沖區溢出。緩沖區溢出會破壞程序運?,也可以被?來進?攻擊計算機,如使??個指向攻擊代碼的指針覆蓋返回地址。
防范緩沖區溢出攻擊的機制:隨機化、棧保護和限制可執?代碼區域。
隨機化
使?緩沖區溢出進?攻擊,需要知道攻擊代碼的地址。因此常?的防范?法有:
1. 棧隨機化:程序開始時在棧上分配?段隨機??的空間
2. 地址空間布局隨機化(Address-Space Layout Randomization,ASLR):每次運?時程序的不
同部分,包括代碼段、數據段、棧、堆等都會被加載到內存空間的不同區域
但是攻擊者依然可以使?蠻?克服隨機化,這種?式稱為“空操作雪橇(nop sled)”,即在實際的攻擊代碼前插?很?的?段 nop 指令序列,執?這條指令只會移動到下?條指令。因此只要攻擊者能夠猜中這段序列的某個地址,程序就會最終經過這段序列,到達攻擊代碼。因此棧隨機化和 ASLR 只能增加攻擊?個系統的難度,但不能完全保證安全。
? ? ??
棧保護
在發?緩沖區溢出、造成任何有害結果之前,嘗試檢測到它。即在每個函數的棧幀的局部變量和棧狀態之間存儲?個隨機產?的特殊的值,稱為?絲雀值(canary)。在恢復寄存器狀態和函數返回之前,程序檢測這個?絲雀值是否被改變了,如果是,那么程序異常終?。
限制可執?代碼區域
內存?的訪問形式有三種:可讀、可寫、可執?。只有編譯器產?的那部分代碼所處的內存才是可執?的,其他?應當限制為只允許讀和寫。
3.6 I/O 模型
為什么 Redis 單線程模型依然效率很?:多線程技術是為了充分利? CPU 的計算資源,適?于下層存儲慢速的場景。? redis 是純內存操作,讀寫速度?常快。所有的操作都會在內存中完成,不涉及任何I/O 操作,因此多線程頻繁的上下?切換反?是?種負優化。Redis 選擇基于?阻塞 I/O 的 I/O 多路復?機制,在單線程?并發處理客戶端的多個連接,減少多線程帶來的系統開銷,同時也有更好的可維護性,?便開發和調試。
I/O 模型類型
I/O 同步和異步的區別在于:將數據從內核復制到?戶空間時,?戶進程是否會阻塞
I/O 阻塞和?阻塞的區別在于:進程發起系統調?后,是會被掛起直到收到數據后再返回、還是?即返 回成功或失敗
I/O 模型類別:阻塞IO、?阻塞IO、IO復?模型、信號驅動IO模型、異步IO
?平觸發(LT,Level Trigger):當?件描述符就緒時,會觸發通知,如果?戶程序沒有?次性把數據讀/寫完,下次還會發出通知。select 只?持?平觸發。
邊緣觸發(ET,Edge Trigger):僅當描述符從未就緒變為就緒時,通知?次,之后不會再通知。
epoll ?持?平觸發和邊緣觸發。當循環讀取 recv 到沒有數據時會出現 eagain 現象(LT 是多線程時可能會出現),默認跳過處理。
針對?絡IO的操作,可以分成兩個階段:
● 準備階段(阻塞):等待數據是否可?,是在內核進程中完成的;
● 操作階段(同步):執?實際的IO調?,數據從內核緩沖區拷?到?戶進程緩沖區。
阻塞IO:應?進程調?I/O操作時阻塞,只有等待要操作的數據準備好,并復制到應?進程的緩沖區中才返回;
?阻塞IO:應?進程調?I/O操作導致該進程進?阻塞狀態時,該I/O調?返回?個錯誤。?般情況下,應?進程需要利?輪詢的?式來檢測某個操作是否就緒。數據就緒后,會等待數據復制到應?進程的緩沖區中以后才返回;
IO復?:多路IO共?同?個同步阻塞接?,此時阻塞發?在 select/poll 的系統調?上,?不是阻塞在實際的I/O系統調?上。IO多路復?的?級之處在于,它能同時等待多個?件描述符,?這些?件描述符其中的任意?個進?讀就緒狀態,select等函數就可以返回。
信號驅動IO:注冊?個IO信號事件,在數據可操作時通過信號通知線程。
異步IO: 應?進程通知內核開始?個異步I/O操作,并讓內核在整個操作(包含將數據從內核復制到應?進程的緩沖區)完成后通知應?進程。
I/O 復?模型
select 缺點:
1. 性能開銷?:調? select 時會陷?內核,這時需要將參數中的 fd_set 從?戶空間拷?到內核空
間。內核需要遍歷傳遞進來的 fd_set 的每?位,不管它們是否就緒
2. 能夠監聽的?件描述符數量太少:受限于 sizeof(fd_set) 的??,在編譯內核時就確定了且?法更改,?般是 1024。?poll 和 select ?乎沒有區別。poll 在?戶態通過數組?式傳遞?件描述符,在內核會轉為鏈表?式存 儲,沒有最?數量的限制
epoll ,select、poll 模型都只使??個函數,? epoll 模型使?三個函數:epoll_create、epoll_ctl(監聽事件) 和 epoll_wait(相當于select,返回就緒數量)。
特點:
1. 使?紅?樹存儲?件描述符集合
2. 使?隊列存儲就緒的?件描述符
3. 每個?件描述符只需在添加時傳??次,之后調? epoll_wait 不需要再次傳遞,提?了效率。
4. 通過事件更改?件描述符狀態。epoll_ctl 中為每個?件描述符指定了回調函數,并在就緒時將其加?到就緒列表,因此只需要判斷就緒列表是否為空即可。
三者區別:
1. select、poll 都是在?戶態維護?件描述符集合,因此每次需要將完整集合傳給內核;epoll 由操作系統在內核中維護?件描述符集合,因此只需要在創建的時候傳??件描述符。
2. 當連接數較多并且有很多的不活躍連接時,epoll 的效率?很多;當連接數較少并且都?分活躍的情況下,由于 epoll 需要很多回調,因此性能可能低于其它兩者。
3. epoll 不?持跨平臺,僅在 linux 上使?,? select 可以在windows 和 linux 同時使?。
Reactor 與 Proactor 模式
Reactor 是 ?阻塞 同步 ?絡模式,感知的是 就緒可讀寫 事件。在每次感知到有IO事件發?(?如可讀就緒事件)后,就需要應?進程主動調? read ?法來完成數據的讀取,也就是要應?進程主動將socket 接收緩存中的數據讀到應?進程內存中,這個過程是同步的,讀取完數據后應?進程才能處理數據。
Proactor 是 異步 ?絡模式, 感知的是 已完成的讀寫 事件。在發起異步讀寫請求時,需要傳?數據緩 沖區的地址(?來存放結果數據)等信息,這樣系統內核才可以?動幫我們把數據的讀寫?作完成,這?的讀寫?作全程由操作系統來做,并不需要像 Reactor 那樣還需要應?進程主動發起 read/write 來讀寫數據,操作系統完成讀寫?作后,就會通知應?進程直接處理數據。因此,Reactor 可以理解為「來了事件操作系統通知應?進程,讓應?進程來處理」,? Proactor 可以理解為「來了事件操作系統來處理,處理完再通知應?進程」。這?的「事件」就是有新連接、有數據可讀、有數據可寫的 I/O 事件;這?的「處理」包含從驅動讀取到內核以及從內核讀取到?戶空間。?論是 Reactor,還是 Proactor,都是?種基于「事件分發」的?絡編程模式,區別在于 Reactor 模式是基于「待完成」的 I/O 事件,? Proactor 模式則是基于「已完成」的 I/O 事件。
3.7 Copy on Write
寫時復制(Copy-on-write,COW),有時也稱為隱式共享(implicit sharing)。COW 將復制操作推遲到第?次寫?時進?:在創建?個新副本(只復制其?表)時,不會?即復制資源,?是共享原始副本的資源;當修改時再執?復制操作。通過這種?式共享資源,可以顯著減少創建副本時的開銷,節省資源。
實現原理:
● fork() 之后,內核會把?進程的所有內存?都標記為只讀
● ?旦其中?個進程嘗試寫?某個內存?,就會觸發?個保護故障(缺?異常),此時會陷?內核
● 內核將寫?操作攔截,并為嘗試寫?的進程創建這個??的?個新副本,恢復這個??的可寫權
限,然后重新執?這個寫操作,這時就可以正常執?了
● 內核會保留每個內存??的引?數。每次復制某個??后,該??的引?數減?;如果該??只有?個引?,就可以跳過分配,直接修改
?
3.8 Linux
啟動過程
BIOS開機?檢:當打開電源后,?先是BIOS開機?檢,按照BIOS中設置的啟動設備(通常是硬盤)來啟動。操作系統接管硬件以后,?先讀? /boot ?錄下的內核?件。
運? init:init 進程是系統所有進程的起點,沒有這個進程,系統中任何進程都不會啟動。init 程序?先是需要讀取配置?件 /etc/inittab。許多程序需要開機啟動。它們在Windows叫做"服務"(service),在Linux就叫做"守護進程"(daemon)。init進程的??任務,就是去運?這些開機啟動的程序。Linux啟動時根據"運?級別",確定要運?哪些程序。Linux系統有7個運?級別(runlevel):
● 運?級別0:系統停機狀態,系統默認運?級別不能設為0,否則不能正常啟動
● 運?級別1:單?戶?作狀態,root權限,?于系統維護,禁?遠程登陸
● 運?級別2:多?戶狀態(沒有NFS)
● 運?級別3:完全的多?戶狀態(有NFS),登陸后進?控制臺命令?模式
● 運?級別4:系統未使?,保留
● 運?級別5:X11控制臺,登陸后進?圖形GUI模式
● 運?級別6:系統正常關閉并重啟,默認運?級別不能設為6,否則不能正常啟動
系統初始化:執? rc.sysinit 腳本,它主要是完成?些系統初始化的?作,rc.sysinit是每?個運?級別都要?先運?的重要腳本。它主要完成的?作有:激活交換分區,檢查磁盤,加載硬件模塊以及其它?些需要優先執?的任務。
建?終端并登錄:這時系統環境基本已經設置好了,各種守護進程也已經啟動了。init接下來會打開6個終端,以便?戶登錄系統。
常?命令
?件管理:
● ls: 顯示當前?錄下?件。
● pwd:顯示當前?作?錄的絕對路徑
● cd + 路徑:切換當前?作?錄。(路徑可以為相對路徑也可以為絕對路徑)
● touch:創建普通?件。
● rm:刪除普通?件 rm -r:刪除?錄?件 -r(遞歸的意思)
● mkdir:創建?錄?件
● rmdir:刪除空?錄
● mv:剪切、重命名
● cp:拷? cp -r
● chmod:修改?件權限
● tar 壓縮?件
進程管理:
● ps :顯示進程信息快照(-e 顯示所有進程。 -f 全格式)
● kill pid :結束進程
● kill -9 pid :強制結束pid進程
● kill -stop pid :掛起進程
● &:在后臺運?進程
系統管理:
● uptime:查詢系統負載
● top:實時顯示系統中各個進程的資源占?狀況,類似 于Windows 的任務管理器
● free:可以顯示當前系統未使?的和已使?的內存數?,還可以顯示被內核使?的內存緩沖區
?絡通訊命令:
● ping
ifconfig
● tcpdump:抓包?具
● netstat:打印本地?卡接?上的全部連接、路由表信息、?卡接?信息。常?:顯示tcp連接
以及狀態。
3.9 硬件結構
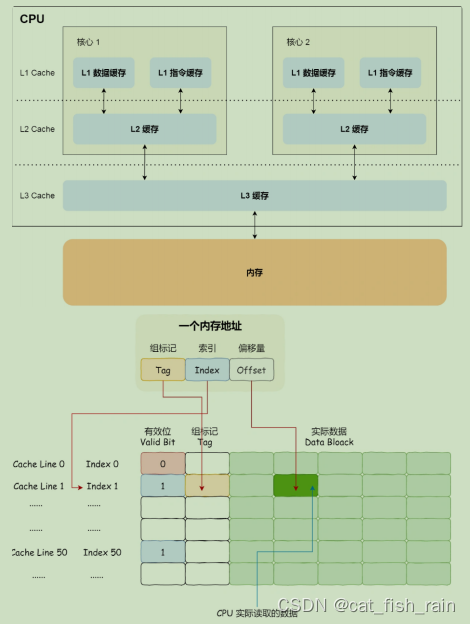
CPU 緩存?致性
解決?法
1. 寫傳播:當某個 CPU 核?發?寫?操作時,需要把該事件?播通知給其他核?;
2. 事務的串?化:只有保證了這個,才能保障數據是真正?致的,程序在各個不同的核?上運?的結 果也是?致的
MESI 協議
基于總線嗅探機制實現了事務串?化,也?狀態機機制降低了總線帶寬壓?,這個協議就是 MESI 協議,這個協議就做到了 CPU 緩存?致性。MESI 協議其實是 4 個狀態單詞的開頭字?縮寫,分別是:
● Modified,已修改
● Exclusive,獨占。「獨占」和「共享」的差別在于,獨占狀態的時候,數據只存儲在?個 CPU 核?的 Cache ?,?其他 CPU 核?的 Cache 沒有該數據。另外,在「獨占」狀態下的數據,如果 有其他核?從內存讀取了相同的數據到各?的 Cache ,那么這個時候,獨占狀態下的數據就會變成共享狀態。
● Shared,共享。「共享」狀態代表著相同的數據在多個 CPU 核?的 Cache ?都有,所以當要更 新 Cache ??的數據的時候,不能直接修改,?是要先向所有的其他 CPU 核??播?個請求,要求先把其他核?的 Cache 中對應的 Cache Line 標記為「?效」狀態,然后再更新當前 Cache ??的數據。
● Invalidated,已失效
這四個狀態來標記 Cache Line 四個不同的狀態。
偽共享
多個線程同時讀寫同?個 Cache Line 的不同變量時,?導致 CPU Cache 失效的現象稱為偽共享
(False Sharing)。解決?法:
● Cache Line ??字節對?:利?宏,以空間換時間的思想,浪費?部分 Cache 空間,從?換來性能的提升。
● 字節填充:如在類中增加占位的字符
?致性哈希
?致性哈希算法解決了分布式系統在擴容或者縮容時,發?過多的數據遷移的問題。
?致性哈希是指將「存儲節點」和「數據」都映射到?個?尾相連的哈希環上,如果增加或者移除?個節點,僅影響該節點在哈希環上順時針相鄰的后繼節點,其它數據也不會受到影響。但是?致性哈希算法不能夠均勻的分布節點,會出現?量請求都集中在?個節點的情況,在這種情況下進?容災與擴容時,容易出現雪崩的連鎖反應。為了解決?致性哈希算法不能夠均勻的分布節點的問題,就需要引?虛擬節點,對?個真實節點做多個副本。不再將真實節點映射到哈希環上,?是將虛擬節點映射到哈希環上,并將虛擬節點映射到實際節點,所以這?有「兩層」映射關系。引?虛擬節點后,可以會提?節點的均衡度,還會提?系統的穩定 性。所以,帶虛擬節點的?致性哈希?法不僅適合硬件配置不同的節點的場景,?且適合節點規模會 ?變化的場景。









)









)