Course1-Week2-多輸入變量的回歸問題
文章目錄
- Course1-Week2-多輸入變量的回歸問題
- 1. 向量化和多元線性回歸
- 1.1 多維特征
- 1.2 向量化
- 1.3 用于多元線性回歸的梯度下降法
- 2. 使梯度下降法更快收斂的技巧
- 2.1 特征縮放
- 2.2 判斷梯度下降是否收斂
- 2.3 如何設置學習率
- 3. 特征工程
- 3.1 選擇合適的特征
- 3.2 多項式回歸
- 筆記主要參考B站視頻“(強推|雙字)2022吳恩達機器學習Deeplearning.ai課程”。
好文:
- 2023吳恩達機器學習: 上班族35 天學完~學習筆記 (1.1 監督學習)——系列文章
- 入門機器學習/深度學習要多長時間?
本篇筆記對應課程 Course1-Week2(下圖中深紫色)。

1. 向量化和多元線性回歸
??在上一周“單變量線性回歸”的基礎上,本周將繼續拓展到“多元線性回歸”(第1節)、“多項式回歸”(第3節),并介紹加速梯度下降法收斂的技巧(第2節)。
1.1 多維特征
首先將單個特征擴展到多個特征,下面是機器學習術語:
- m m m:訓練樣本的總數。
- n n n:輸入特征的總數。
- X ? \vec{X} X:全部的輸入特征值,是一個二維向量,每一行表示一個樣本,每一列表示所有樣本的單個特征。
- x ? j \vec{x}_j xj?:表示第 j j j個特征概念(一維向量), j j j的取值范圍為 j = 1 , . . . , n j=1,...,n j=1,...,n。
- x ? ( i ) \vec{x}^{(i)} x(i):第 i i i個訓練樣本的輸入特征(一維向量), i i i的取值范圍為 i = 1 , . . . , m i=1,...,m i=1,...,m。
- x ? j ( i ) \vec{x}^{(i)}_{j} xj(i)?:第 i i i個訓練樣本的第 j j j個特征,是單個值。如下圖中, x ? 4 ( 3 ) = 30 \vec{x}^{(3)}_4 = 30 x4(3)?=30。
- y ? ( i ) \vec{y}^{(i)} y?(i):第 i i i個訓練樣本的目標值,是單個值。
- Y ? \vec{Y} Y:全部的訓練樣本的特征值,是一維向量。
注:若無特殊說明,所有的一維向量都默認為列向量。
概念區分:
- 單變量線性回歸(univariate linear regression):只有單個特征的線性回歸模型。
- 多元線性回歸(multiple linear regression):具有多維特征的線性回歸模型。
- multivariate regression:不是上述“多元回歸”!另有別的意思,后面介紹。

??如上圖所示,將“房價預測”中的輸入特征數量增加為4個:輸入特征:房屋面積、臥室數量、房屋層數、房屋年齡。于是顯然其線性回歸模型也將從 f w , b ( x ) = w x + b f_{w,b}(x) = wx+b fw,b?(x)=wx+b 擴展為下面的向量形式:
f w ? , b ( x ? ) = w 1 x 1 + w 2 x 2 + . . . + w 4 x 4 + b = ∑ j = 1 n w j x j + b = w ? ? x ? + b \begin{aligned} f_{\vec{w},b}(\vec{x}) &= w_1x_1 + w_2x_2 + ... + w_4x_4 + b\\ &= \sum_{j=1}^{n}w_jx_j + b\\ &= \vec{w}·\vec{x} + b \end{aligned} fw,b?(x)?=w1?x1?+w2?x2?+...+w4?x4?+b=j=1∑n?wj?xj?+b=w?x+b?
- w ? = [ w 1 , w 2 , . . . , w n ] T \vec{w}=[w_1,w_2,...,w_n]^T w=[w1?,w2?,...,wn?]T:表示參數(列)向量。 w i w_i wi?表示當前特征對房屋價格影響。
- b b b:常數項參數。可以理解為房屋的基價(base price)。
- x ? = [ x 1 , x 2 , . . . , x n ] T \vec{x}=[x_1,x_2,...,x_n]^T x=[x1?,x2?,...,xn?]T:表示單個樣本的特征(列)向量。
- w ? ? x ? \vec{w}·\vec{x} w?x:表示兩個向量的點積。
1.2 向量化
??簡單來說,所謂“向量化”就是將分散的數字綁在一起進行處理。雖然概念很簡單,但是“向量化”對于機器學習來說非常重要,因為它可以使模型更簡潔、代碼更簡潔,并且也可以加速代碼運行速度。比如下圖給出了三種書寫求和公式的方法。可以發現,使用向量形式的模型表達式最簡潔、代碼最少(一行):



- 一個一個寫:很麻煩,耗時耗力,也不會加快代碼計算。
- for循環:每次只能計算單個乘法并相加,n很大時非常耗時。
- 向量相乘:形式簡潔、運行更快。這是因為
numpy.dot()可以并行計算所有乘法,再進行相加。甚至某些內置算法還會使用GPU加速運算。注:Optional Lab介紹了一些NumPy的語法。
并且梯度下降法的迭代計算中,使用向量更新參數也會非常簡潔。所以機器學習中盡量使用向量化代碼。
1.3 用于多元線性回歸的梯度下降法
??有了“向量化”的鋪墊,本節將前面的單變量線性回歸問題擴展到多元線性回歸。首先使用“向量”重寫模型,然后也就可以寫出梯度下降法的“向量”形式,進而迭代計算出模型參數:
Model : f w ? , b ( x ? ) = w ? ? x ? + b Cost?function : min ? w ? , b J ( w ? , b ) = 1 2 m ∑ i = 1 m ( f w ? , b ( x ? ( i ) ) ? y ( i ) ) 2 Gradient?descent repeat?until?convergence : { w j = w j ? α ? ? w j J ( w ? , b ) = w j ? α m ∑ i = 1 m [ ( f w ? , b ( x ? ( i ) ) ? y ( i ) ) ? x ? j ( i ) ] , j = 1 , 2 , . . . , n . b = b ? α ? ? b J ( w ? , b ) = b ? α m ∑ i = 1 m ( f w ? , b ( x ? ( i ) ) ? y ( i ) ) \begin{aligned} \text{Model} &: \quad f_{\vec{w},b}(\vec{x}) = \vec{w}·\vec{x} + b\\ \text{Cost function} &: \quad \min_{\vec{w},b} J(\vec{w},b) = \frac{1}{2m} \sum_{i=1}^{m}(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})^2\\ \begin{aligned} \text{Gradient descent} \\ \text{repeat until convergence} \end{aligned} &: \left\{\begin{aligned} w_j &= w_j - \alpha \frac{\partial }{\partial w_j} J(\vec{w},b) = w_j - \frac{\alpha}{m} \sum_{i=1}^{m}[(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})·\vec{x}^{(i)}_j],\; j=1,2,...,n. \\ b &= b - \alpha \frac{\partial }{\partial b} J(\vec{w},b) = b - \frac{\alpha}{m} \sum_{i=1}^{m}(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)}) \end{aligned}\right. \end{aligned} ModelCost?functionGradient?descentrepeat?until?convergence??:fw,b?(x)=w?x+b:w,bmin?J(w,b)=2m1?i=1∑m?(fw,b?(x(i))?y(i))2:? ? ??wj?b?=wj??α?wj???J(w,b)=wj??mα?i=1∑m?[(fw,b?(x(i))?y(i))?xj(i)?],j=1,2,...,n.=b?α?b??J(w,b)=b?mα?i=1∑m?(fw,b?(x(i))?y(i))??
- 模型中 x ? \vec{x} x 表示單個樣本的所有特征,是一維向量。
- f w ? , b ( x ? ( i ) ) f_{\vec{w},b}(\vec{x}^{(i)}) fw,b?(x(i))是一個值, y ( i ) y^{(i)} y(i)是一個值。
??除了梯度下降法,還有一類求解模型參數的方法——正規方程法(Normal rquation method)。此方法利用線性代數的知識,直接令代價函數的梯度 ? ? w ? J ( w ? , b ) = 0 ? \frac{\partial }{\partial \vec{w}} J(\vec{w},b) = \vec{0} ?w??J(w,b)=0,便可以一步求解出代價函數極小點所對應的參數值: w ? = ( X ? T X ? ) ? 1 X ? T Y ? \vec{w}=(\vec{X}^T\vec{X})^{-1}\vec{X}^T\vec{Y} w=(XTX)?1XTY,見“詳解正規方程”。但是這種方法有兩個缺點:
- 適用面小:僅適用于線性擬合,無法應用于其他方法,比如下周要學的“邏輯回歸算法(logistic regression algorithm)”或者神經網絡(Course2)。
- 計算規模不能太大:如何特征值數量很大,矩陣的逆等求解非常慢。
正規方程法通常會包含在機器學習函數庫中,我們無需關心具體的計算過程。對于大多數機器學習算法來說,梯度下降法仍然是推薦的方法。
本節Quiz:
In the training set below, what is x 4 ( 3 ) x_4^{(3)} x4(3)?? Please type in the number below (this is an integer such as 123, no decimal points).
Answer: 30
Which of the following are potential benefits of vectorization? Please choose the best option.
√ It can make your code shorter.
√ It allows your code to run more easily on parallel compute hardware.
√ It makes your code run faster.
√ All of the above.To make gradient descent converge about twice as fast, a technique that almost always works is to double the learning rate α \alpha α.
× True
√ FalseWith polynomial regression, the predicted values f w , b ( x ) f_{w,b}(x) fw,b?(x) does not necessarily have to be a straight line (or linear) function of the input feature x x x.
× False
√ True
2. 使梯度下降法更快收斂的技巧
2.1 特征縮放
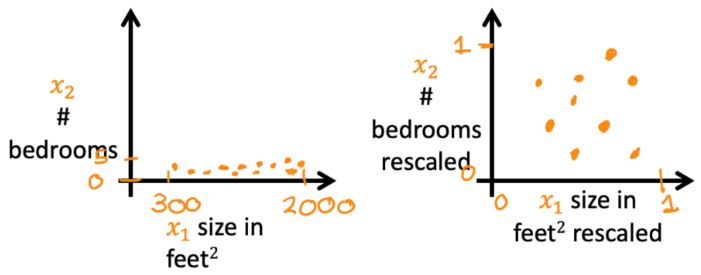
??特征縮放(feature scaling)可以使梯度下降法更快收斂。這主要是因為不同特征的取值范圍有很大不同,但所有特征所對應的參數的學習率是一致的。這就導致取值范圍較小的特征的參數,會“跟不上”取值范圍較大的特征的參數變化。比如我們來看看“特征值大小”和其關聯的“參數大小”的關系,首先將“房價預測”的問題簡化成兩個特征:

- x 1 x_1 x1?:房屋面積,范圍是300~2000平方英尺。
- x 2 x_2 x2?:臥室數量,范圍是0~5。
參數選擇:顯然取值范圍更大的 x 1 x_1 x1? 影響更大。
- w 1 = 50 , w 2 = 0.1 , b = 50 w_1=50,w_2=0.1,b=50 w1?=50,w2?=0.1,b=50:計算出來的房屋價格是 $ 100050.5 k 100050.5k 100050.5k,顯然與實際的 $ 500 k 500k 500k 完全不符。
- w 1 = 0.1 , w 2 = 50 , b = 50 w_1=0.1,w_2=50,b=50 w1?=0.1,w2?=50,b=50:計算出來的房屋價格是 $ 500 k 500k 500k,正好等于房屋實際價格。
??于是,便考慮將 特征值歸一化,使所有特征值的取值范圍大致相同,這樣就不會影響參數的迭代計算了。如下圖便給出了進行 特征縮放 前后的對比:

左兩圖是訓練樣本散點圖;右兩圖是代價函數等高圖。上兩圖對應特征縮放前;下兩圖對應特征縮放后。
- 特征縮放前:散點圖呈現條形,等高圖呈極窄的橢圓形。這是因為對于范圍較大的特征值( x 1 x_1 x1?)所對應的參數 w 1 w_1 w1?,一點微小的改變就會導致代價函數劇烈變化,進而使得等高圖呈橢圓狀。在使用梯度下降法的時候,由于學習率一樣,每走一小步,就會導致代價函數在 w 2 w_2 w2?方向變化不多、但在 w 1 w_1 w1?方向急劇變化,于是就會“反復橫跳”,增加迭代次數和計算量,甚至不能收斂。
- 特征縮放后:散點圖分布較為均勻,并且等高圖呈圓形。梯度下降法可以徑直朝最小值迭代,減少迭代次數、更快的得到結果。
??好,現在我們知道進行 特征縮放 很有必要,那具體如何進行“特征縮放”,來使得所有特征都有相近的范圍大小呢?主要有下面三種方法,并給出了第三種方法“Z-score歸一化”的特征縮放效果:
- 除以最大值:所有特征除以各自的范圍最大值,使得特征值范圍都在0~1之間。于是 0.15 ≤ x 1 2000 ≤ 1 0.15 \le \frac{x_1}{2000} \le 1 0.15≤2000x1??≤1、 0 ≤ x 2 5 ≤ 1 0 \le \frac{x_2}{5} \le 1 0≤5x2??≤1。
- 均值歸一化(Mean normalization):使得特征值范圍大致為-1~1。假設 x 1 x_1 x1?的平均值為 μ 1 = 600 \mu_1=600 μ1?=600、 x 2 x_2 x2?的平均值為 μ 2 = 2.3 \mu_2=2.3 μ2?=2.3,于是 ? 0.18 ≤ x 1 ? μ 1 2000 ? 300 ≤ 0.82 -0.18 \le \frac{x_1 - \mu_1}{2000 - 300} \le 0.82 ?0.18≤2000?300x1??μ1??≤0.82、 ? 0.46 ≤ x 2 ? μ 2 5 ? 0 ≤ 0.54 -0.46 \le \frac{x_2 - \mu_2}{5 - 0} \le 0.54 ?0.46≤5?0x2??μ2??≤0.54。
- Z-score歸一化(Z-score normalization)【推薦】:使得特征值服從標準正態分布。假設 x 1 x_1 x1?的平均值和標準差分別為 μ 1 = 600 , σ 1 = 450 \mu_1=600,\sigma_1=450 μ1?=600,σ1?=450、 x 2 x_2 x2?的平均值和標準差分別為 μ 2 = 2.3 , σ 2 = 1.4 \mu_2=2.3,\sigma_2=1.4 μ2?=2.3,σ2?=1.4,于是 ? 0.67 ≤ x 1 ? μ 1 σ 1 ≤ 3.1 -0.67 \le \frac{x_1 - \mu_1}{\sigma_1} \le 3.1 ?0.67≤σ1?x1??μ1??≤3.1、 ? 1.6 ≤ x 2 ? μ 2 σ 2 ≤ 1.9 -1.6 \le \frac{x_2 - \mu_2}{\sigma_2} \le 1.9 ?1.6≤σ2?x2??μ2??≤1.9。
注:Z-score歸一化的合理性在于自然界中大部分數據都是服從正態分布的。
均值: μ j = 1 m ∑ i = 0 m ? 1 x ? j ( i ) , j = 0 , 1 , . . . , n . \mu_j = \frac{1}{m} \sum_{i=0}^{m-1}\vec{x}^{(i)}_j , \; j=0,1,...,n. μj?=m1?∑i=0m?1?xj(i)?,j=0,1,...,n.
方差: σ j 2 = 1 m ∑ i = 0 m ? 1 ( x ? j ( i ) ? μ j ) 2 , j = 0 , 1 , . . . , n . \sigma^2_j = \frac{1}{m} \sum_{i=0}^{m-1} (\vec{x}^{(i)}_j-\mu_j)^2, \; j=0,1,...,n. σj2?=m1?∑i=0m?1?(xj(i)??μj?)2,j=0,1,...,n.
標準差: σ j = σ j 2 , j = 0 , 1 , . . . , n . \sigma_j = \sqrt{\sigma^2_j}, \; j=0,1,...,n. σj?=σj2??,j=0,1,...,n.
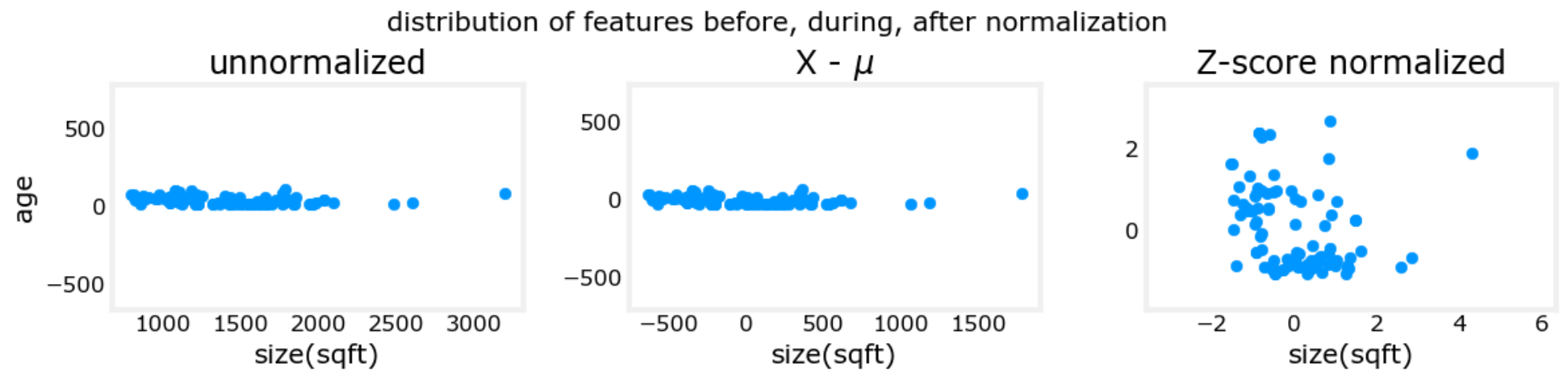

上面三個圖的橫縱坐標分別為兩個特征:房屋面積、房屋年齡。可以看到特征縮放后,樣本散點圖分布的更加均勻。
下面兩個圖的橫縱坐標同樣是兩個特征:房屋面積、臥室數量。可以看到特征縮放后,等高線圖趨近圓形。
圖片來自:C1_W2_Lab03_Feature_Scaling_and_Learning_Rate_Soln:
最后要說明一點,特征縮放后,只要所有特征值的范圍在一個數量級就都可以接受,但若數量級明顯不對等就需要 重新縮放。
2.2 判斷梯度下降是否收斂
??本節主要介紹 橫坐標為迭代次數 的“學習曲線(learning carve)”。學習曲線可以幫助我們判斷梯度下降法 是否正在收斂,或者判斷梯度下降法 是否已經收斂。如下圖給出了正常的學習曲線,
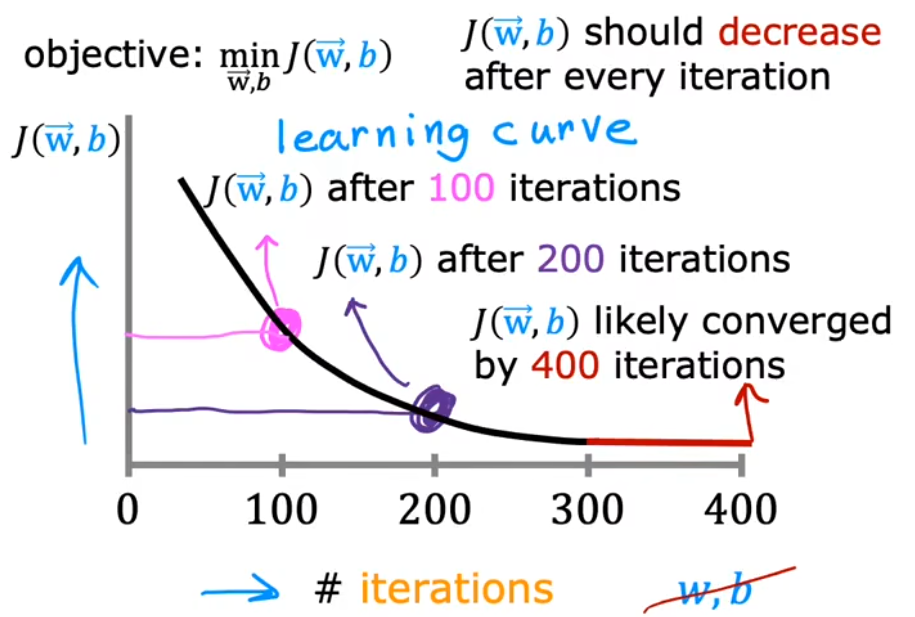
- 正常情況:每次迭代后,代價函數都應該下降。直到某次迭代后,代價函數幾乎不再下降,就認為是收斂。
- 算法沒有收斂:若某次迭代后,代價函數變大,則算法沒有收斂,可能意味著學習率 α \alpha α過大。
- 算法已經收斂:上圖中的紅色段,可以看到代價函數幾乎不再下降。
自動收斂測試(automatic convergence test):若兩次迭代之間,代價函數的減少值 ≤ ? = 1 0 ? 3 \le \epsilon=10^{-3} ≤?=10?3(自定義),即可認為收斂。但是通常 ? \epsilon ?的選取很困難,所以還是建議使用上圖所示的學習曲線進行判斷。
注意不同的算法或問題,其收斂的迭代次數都不同,有些問題可能幾十次就收斂,有些問題可能需要上萬次才能收斂。由于很難提前知道梯度下降法是否會收斂,所以可以根據這個學習曲線來進行判斷。
2.3 如何設置學習率
??之前提到,學習率太小,收斂太慢;學習率太大,可能不會收斂。那如何選擇合適的學習率呢?正確的做法是,迭代較小的次數,快速地、粗略地選出合適的學習率。具體的選擇策略是從一個較小的學習率(如0.01)開始,逐漸增大,直到出現不收斂的情況。如下圖所示:
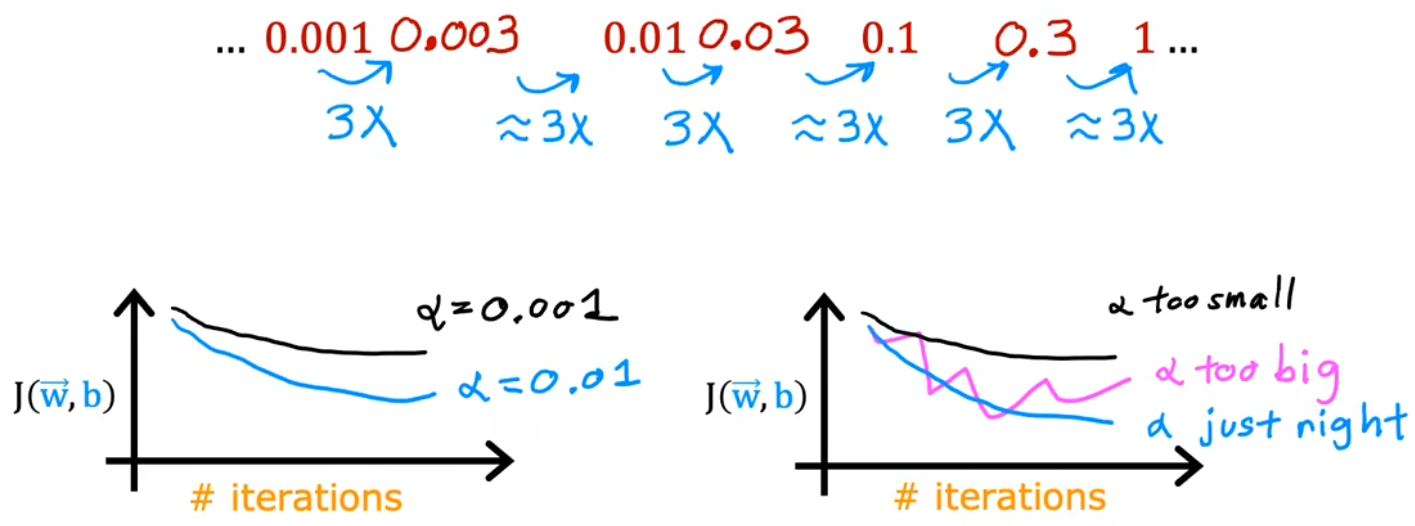
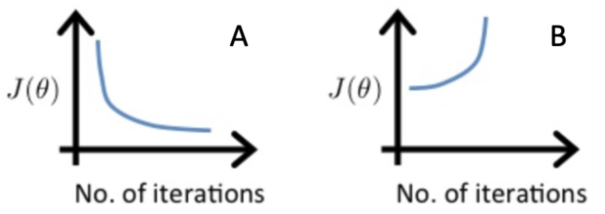
- 代價函數起伏不定:代碼邏輯有bug(比如迭代方向寫反),或者學習率太大。
- 驗證代碼邏輯正常:當學習率很小時,代價函數會不斷減小,即使很慢。
3. 特征工程
??“特征工程”這個標題聽起來怪怪的,其實就是如何挑選、組合、使用“特征”的一套方法論。特征工程(Feature engineering)使用先驗知識或直覺來轉換或組合原始特征,從而設計出新的特征,進而簡化算法或者使預測結果更準確。
關于Python仿真:scikit-learn是一個非常廣泛使用的開源機器學習庫,但是老師希望能理解線性回歸的原理,而不是盲目地調用scikit-learn的函數。
3.1 選擇合適的特征
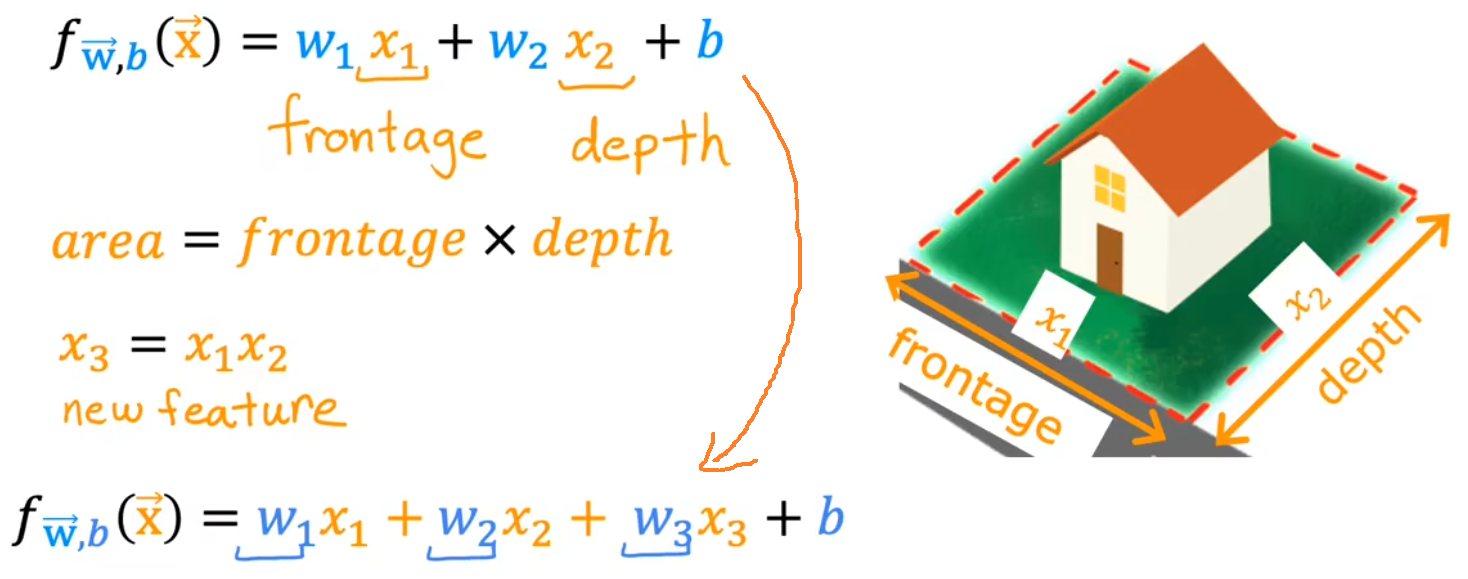
??最簡單的特征工程就是“選擇合適的特征”。比如下圖中,原始特征應該為房子所在地塊的長度(frontage)和寬度(depth),但占地面積(frontage × depth)應該是更符合直觀的特征,于是就利用兩個原始特征創造出了新的特征。
3.2 多項式回歸
??另一種特征工程就是對某個特征進行冪次,進而實現使用非直線來擬合數據,也就是“多項式回歸(Polynomial Regression)”。比如給出下圖中紅叉所示的訓練樣本,顯然用直線擬合并不符合直觀,于是:
- 二次函數擬合:雖然前半段看起來很好,但是終歸會下降,這不符合“面積越大,房子越貴”的常識。
- 三次函數擬合:符合直覺,但后面房價隨面積快速上升。
- 開根號擬合:符合直覺,房價隨著面積緩慢上升。
注:冪次越高,特征縮放就顯得越重要,否則參數的為微小變化將引起代價函數的劇烈波動,很可能會導致算法無法收斂。

在Course2中將介紹如何挑選不同的特征,現在只是明確用戶可以挑選特征,并且使用“特征工程”和“多項式函數”可以擬合出曲線,來更加貼合樣本。
Which of the following is a valid step used during feature scaling?
× Add the mean (average) from each value and and then divide by the (max - min).
√ Subtract the mean (average) from each value and then divide by the (max - min).
Suppose a friend ran gradient descent three separate times with three choices of the learning rate α \alpha α and plotted the learning curves for each (cost J J J for each iteration). For which case, A or B, was the learning rate a likely too large?
√ case B only.
× Both Cases A and B.
× case A only.
× Neither Case A nor B.
Of the circumstances below, for which one is feature scaling particularly helpful?
× Feature scaling is helpful when all the features in the original data (before scaling is applied) range from 0 to 1.
√ Feature scaling is helpful when one feature is much larger (or smaller) than another feature.
注:本題想表達的意思是,原始特征值范圍都在0~1附近時,就沒必要進行特征縮放了。You are helping a grocery store predict its revenue, and have data on its items sold per week, and price per item. What could be a useful engineered feature?
√ For each product, calculate the number of items sold times(乘) price per item.
× For each product, calculate the number of items sold divided(除) by the price per item.注:C1_W2_Linear_Regression包含單變量線性回歸、多線線性回歸的練習題,值得一做。












)



)


