反射編程
reflect.TypeOf vs reflect.ValueOf

func TestTypeAndValue(t *testing.T) {var a int64 = 10t.Log(reflect.TypeOf(a), reflect.ValueOf(a))t.Log(reflect.ValueOf(a).Type())
}

判斷類型 - Kind()
當我們需要對反射回來的類型做判斷時,Go 語言內置了一個枚舉,可以通過 Kind() 來返回這個枚舉值:
const (Invalid Kind = iotaBoolIntInt8Int16Int32Int64UintUint8Uint16Uint32Uint64// ...
)
package reflectimport ("fmt""reflect""testing"
)// 檢查反射類型
// 用空接口接收任意類型
func CheckType(v interface{}) {t := reflect.TypeOf(v)switch t.Kind() {case reflect.Int, reflect.Int32, reflect.Int64:fmt.Println("Int")case reflect.Float32, reflect.Float64:fmt.Println("Float")default:fmt.Println("unknown type")}
}func TestBasicType(t *testing.T) {var f float32 = 1.23CheckType(f)
}

利用反射編寫靈活的代碼

reflect.TypeOf() 和 reflect.ValueOf() 都有 FieldByName() 方法。
// s必須是一個 struct 類型// reflect.ValueOf()只會返回一個值
reflect.ValueOf(s).FieldByName("Name")// reflect.TypeOf()可以返回兩個值,第二個值可以用來判斷這個值有沒有;
reflect.TypeOf(s).FieldByName("Name")
FieldByName() 方法返回的是一個 StructField 類型的值。

我們可以通過這個 StructField 來訪問 Struct Tag:
type StructField struct {// Name是字段的名字。PkgPath是非導出字段的包路徑,對導出字段該字段為""。// 參見http://golang.org/ref/spec#Uniqueness_of_identifiersName stringPkgPath stringType Type // 字段的類型Tag StructTag // 字段的標簽Offset uintptr // 字段在結構體中的字節偏移量Index []int // 用于Type.FieldByIndex時的索引切片Anonymous bool // 是否匿名字段
}
FieldByName() 方法調用者必須是一個 struct,而不是指針,源碼如下:

// 訪問 MethodByName() 必須是指針類型
reflect.ValueOf(&s).MethodByName("method_name").Call([]reflect.Value{reflect.ValueOf("new_value")})
type Employee struct {EmployeeID string// 注意后面的 struct tag 的寫法,詳情見第5點講解Name string `format:"normal"`Age int
}// 更新名字,注意這里的 e 是指針類型
func (e *Employee) UpdateName(newVal string) {e.Name = newVal
}// 通過反射調用結構體的方法
func TestInvokeByName(t *testing.T) {e := Employee{"1", "Jane", 18}// reflect.TypeOf()可以返回兩個值,第二個值可以用來判斷這個值有沒有;// 而reflect.ValueOf()只會返回一個值t.Logf("Name: value(%[1]v), Type(%[1]T)", reflect.ValueOf(e).FieldByName("Name"))if nameField, ok := reflect.TypeOf(e).FieldByName("Name"); !ok {t.Error("Failed to get 'Name' field")} else {// 獲取反射取到的字段的 tag 的值t.Log("Tag:Format", nameField.Tag.Get("format"))}// 訪問 MethodByName() 必須是指針類型 reflect.ValueOf(&e).MethodByName("UpdateName").Call([]reflect.Value{reflect.ValueOf("Mike")})t.Log("After update name: ", e)
}

Elem()
因為 FieldByName() 必須要結構體才能調用,如果參數是一個指向結構體的指針,我們需要用到 Elem() 方法,它會幫你獲得指針指向的結構。
Elem()用來獲取指針指向的值- 如果參數不是指針,會報 panic 錯誤
- 如果參數值是 nil,獲取的值為 0
// reflect.ValueOf(demoPtr)).Elem() 返回的是字段的值
reflect.ValueOf(demoPtr).Elem()// reflect.ValueOf(st)).Elem().Type() 返回的是字段類型
reflect.ValueOf(demoPtr).Elem().Type()// 傳遞指針類型參數調用 FieldByName() 方法
reflect.ValueOf(demoPtr).Elem().FieldByName("Name")// 傳遞指針類型參數調用 FieldByName() 方法
reflect.ValueOf(demoPtr).Elem().Type().FieldByName("Name")
Struct Tag
結構體里面可以對某些字段做特殊的標記,它是一個 `key: “value”` 的格式。

type Demo struct {// 先用這個符號(``)包起來,然后寫上 key: value 的格式Name string `format:"normal"`
}
Go 內置的 Json 解析會用到 tag 來做一些標記。
反射是把雙刃劍
反射是一個強大并富有表現力的工具,能讓我們寫出更靈活的代碼。但是反射不應該被濫用,原因有以下三個:
- 基于反射的代碼是極其脆弱的,反射中的類型錯誤會在真正運行的時候才會引發 panic,那很可能是在代碼寫完的很長時間之后。
- 大量使用反射的代碼通常難以理解。
- 反射的性能低下,基于反射實現的代碼通常比正常代碼運行速度慢一到兩個數量級。
萬能程序
DeepEqual
我們都知道兩個 map 類型之間是不能互相比較的,兩個 slice 類型之間也不能進行比較,但是反射包中的 DeepEqual() 可以幫我們實現這個功能。
用 DeepEqual() 比較 map
// 用 DeepEqual() 比較兩個 map 類型
func TestMapComparing(t *testing.T) {m1 := map[int]string{1: "one", 2: "two", 3: "three"}m2 := map[int]string{1: "one", 2: "two", 3: "three"}if reflect.DeepEqual(m1, m2) {t.Log("yes")} else {t.Log("no")}
}

用 DeepEqual() 比較 slice
// 用 DeepEqual() 比較兩個切片類型
func TestSliceComparing(t *testing.T) {s1 := []int{1, 2, 3, 4}s2 := []int{1, 2, 3, 5}if reflect.DeepEqual(s1, s2) {t.Log("yes")} else {t.Log("no")}
}

用反射實現萬能程序
場景:我們有 Employee 和 Customer 兩個結構體,二者有兩個相同的字段(Name 和 Age),我們希望寫一個通用的程序,可以同時填充這兩個不同的結構體。
type Employee struct {EmployeeId intName stringAge int
}type Customer struct {CustomerId intName stringAge int
}// 用同一個數據填充不同的結構體
// 思路:既然是不同的結構體,那么要想通用,所以參數必須是一個空接口才行。
// 因為是空接口,所有我們需要對參數類型寫斷言
func fillDifferentStructByData(st interface{}, data map[string]interface{}) error {// 先判斷傳過來的類型是不是指針if reflect.TypeOf(st).Kind() != reflect.Ptr {return errors.New("第一個參數必須傳一個指向結構體的指針")}// 再判斷指針指向的類型是否為結構體// Elem() 用來獲取指針指向的值// 如果參數不是指針,會報 panic 錯誤// 如果參數值是 nil, 獲取的值為 0if reflect.TypeOf(st).Elem().Kind() != reflect.Struct {return errors.New("第一個參數必須是一個結構體類型")}if data == nil {return errors.New("填充用的數據不能為nil")}var (field reflect.StructFieldok bool)for key, val := range data {// 如果結構體里面沒有 key 這個字段,則跳過// reflect.ValueOf(st)).Elem().Type() 返回的是字段類型// reflect.ValueOf(st)).Elem().Type() 等價于 reflect.TypeOf(st)).Elem()if field, ok = reflect.TypeOf(st).Elem().FieldByName(key); !ok {continue}// 如果字段的類型相同,則用 data 的數據填充這個字段的值if field.Type == reflect.TypeOf(val) {// reflect.ValueOf(st)).Elem() 返回的是字段的值reflect.ValueOf(st).Elem().FieldByName(key).Set(reflect.ValueOf(val))}}return nil
}// 填充姓名和年齡
func TestFillNameAndAge(t *testing.T) {// 聲明一個 map,用來存放數據,這些數據將會填充到 Employee 和 Customer 這兩個結構體中data := map[string]interface{}{"Name": "Jane", "Age": 18}e := Employee{}// 傳給通用的填充方法if err := fillDifferentStructByData(&e, data); err != nil {t.Fatal(err)}c := Customer{}// 傳給通用的填充方法if err := fillDifferentStructByData(&c, data); err != nil {t.Fatal(err)}t.Log(e)t.Log(c)
}

兩個結構體的 name 和 age 都填充上了,符合預期。
不安全編程-UnSafe
不安全編程指的是 go 語言中有一個 package 叫:unsafe,它的使用場景一般是要和外部 c 程序實現的一些高效的庫來進行交互。
“不安全行為”的危險性

Go 語言中是不支持強制類型轉換的,而我們一旦使用 unsafe.Pointer 拿到指針后,我們可以將它轉換為任意類型的指針,這樣我們是否能利用它來實現強制類型轉換呢?我們可以用代碼來測試一下:
func TestUnsafe(t *testing.T) {i := 10f := *(*float64)(unsafe.Pointer(&i))t.Log(unsafe.Pointer(&i))t.Log(f)
}

可以看到結果根本不是 10,是一串數字字母的組合,所以這是非常危險的。
合理的類型轉換
在 Go 語言中,不同類型的指針是不允許相互賦值的,但是通過合理地使用 unsafe 包,則可以打破這種限制。
例如:int 類型是可以進行轉換賦值的。
func TestConvert1(t *testing.T) {var num int = 10var uintNum uint = *(*uint)(unsafe.Pointer(&num))var int32Num int32 = *(*int32)(unsafe.Pointer(&num))t.Log(num, uintNum, int32Num)t.Log(reflect.TypeOf(num), reflect.TypeOf(uintNum), reflect.TypeOf(int32Num))
}

訪問修改結構體私有成員變量
type User struct {name stringid int
}func TestOperateStruct(t *testing.T) {user := new(User)user.name = "張三"fmt.Printf("%+v\n", user)// 突破第一個私有變量,因為是結構體的第一個字段,所以不需要額外的指針計算*(*string)(unsafe.Pointer(user)) = "李四"fmt.Printf("%+v\n", user)// 突破第二個私有變量,因為是第二個成員字段,需要偏移一個字符串占用的長度即 16 個字節*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(user)) + uintptr(16))) = 1fmt.Printf("%+v\n", user)
}

當然我們可以更簡單的獲取到結構體變量的偏移量,這樣就不需要自己計算了:
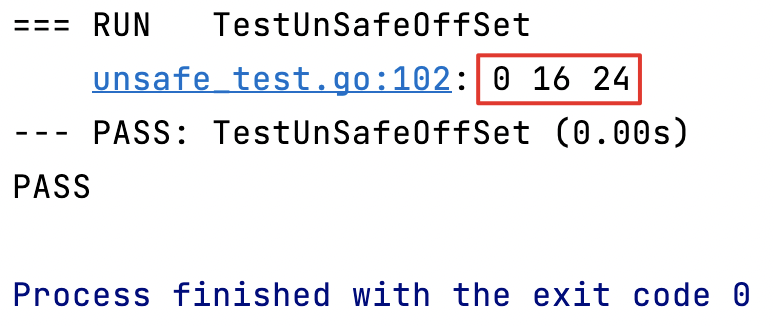
type Person struct {Name stringAge intHeight float64
}func TestUnSafeOffSet(t *testing.T) {nameOffset := unsafe.Offsetof(Person{}.Name)ageOffset := unsafe.Offsetof(Person{}.Age)heightOffset := unsafe.Offsetof(Person{}.Height)t.Log(nameOffset, ageOffset, heightOffset) // 輸出字段的偏移量
}
實現 []byte 和字符串的零拷貝轉換
通過查看源碼,可以發現 slice 切片類型和 string 字符串類型具有類似的結構。
// runtime/slice.go
type slice struct {array unsafe.Pointer // 底層數組指針,真正存放數據的地方len int // 切片長度,通過 len(slice) 返回cap int // 切片容量,通過 cap(slice) 返回
}// runtime/string.go
type stringStruct struct {str unsafe.Pointer // 底層數組指針len int // 字符串長度,可以通過 len(string) 返回
}
看到這里,你是不是發現很神奇,這兩個數據結構底層實現基本相同,而 slice 只是多了一個cap 字段。可以得出結論:slice 和 string 在內存布局上是對齊的,我們可以直接通過 unsafe 包進行轉換,而不需要申請額外的內存空間。
代碼實現
func StringToBytes(str string) []byte {var b []byte// 切片的底層數組、len字段,指向字符串的底層數組,len字段*(*string)(unsafe.Pointer(&b)) = str// 切片的 cap 字段賦值為 len(str) 的長度,切片的指針、len 字段各占8個字節,直接偏移16個字節*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&b)) + 2*uintptr(8))) = len(str)return b
}func BytesToString(data []byte) string {// 直接轉換return *(*string)(unsafe.Pointer(&data))
}func TestStringAndBytesConvert(t *testing.T) {str := "hello"b := StringToBytes(str)t.Log(reflect.TypeOf(b), b)// 此時 b 已經是切片類型,我們再將它轉換為string類型s := BytesToString(b)t.Log(reflect.TypeOf(s), s)
}
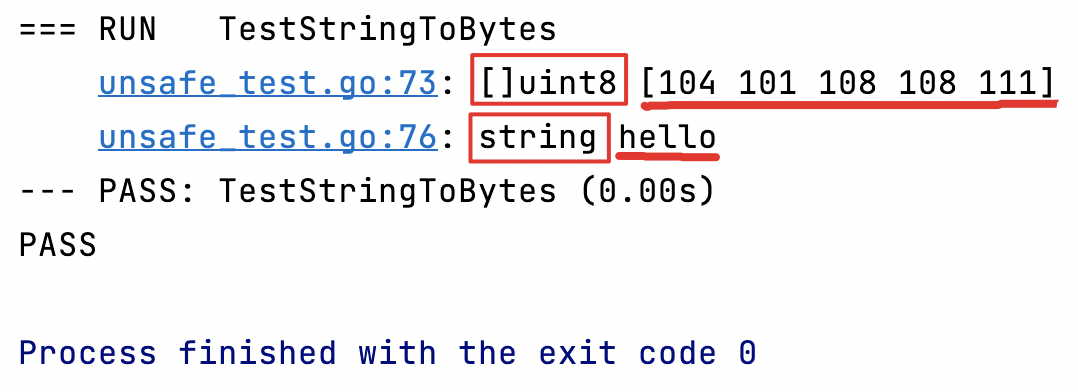
符合預期。
原子類型操作
我們會用到 golang 內置 package 中的 atomic 原子操作,它提供了指針的原子操作,通常用在并發讀寫一塊共享緩存時,保證線程安全。
我們在寫數據的時候寫在另外一塊空間,完全寫完之后,我們使用原子操作把讀的指針和寫的指針指向我們新寫入的空間,保證下次再讀的時候就是新寫好的內容了。指針的切換要具有線程安全的特性。
func TestAtomic(t *testing.T) {var shareBufPtr unsafe.Pointer// 寫方法writeDataFn := func() {data := []int{}for i := 0; i < 9; i++ {data = append(data, i)}// 使用原子操作將data的指針指向shareBufPtratomic.StorePointer(&shareBufPtr, unsafe.Pointer(&data))}// 讀方法readDataFn := func() {data := atomic.LoadPointer(&shareBufPtr) // 使用原子操作讀取shareBufPtrfmt.Println(data, *(*[]int)(data)) // 打印shareBufPtr中的數據}var wg sync.WaitGroupwriteDataFn()// 啟動3個讀協程,3個寫協程,每個協程執行3次讀/寫操作for i := 0; i < 3; i++ {wg.Add(1)go func() {for i := 0; i < 3; i++ {writeDataFn()time.Sleep(time.Microsecond * 100)}wg.Done()}()wg.Add(1)go func() {for i := 0; i < 3; i++ {readDataFn()time.Sleep(time.Microsecond * 100)}wg.Done()}()}wg.Wait()
}

使用 atomic + unsafe 來實現共享 buffer 安全的讀寫。
總結
通過 unsafe 包,我們可以繞過 golang 編譯器的檢查,直接操作地址,實現一些高效的操作。但正如 golang 官方給它的命名一樣,它是不安全的,濫用的話可能會導致程序意外的崩潰。關于 unsafe 包,我們應該更關注于它的用法,生產環境不建議使用!!!
- 筆記整理自極客時間視頻教程:Go語言從入門到實戰
- UnSafe部分內容參考:go unsafe包使用指南








)




)





