最近的一個大屏報表統計的接口查詢速度很慢,耗時近一分鐘左右,數據量級只是700萬左右,但很慢,最后優化到4秒左右,客戶還能接受,但其實還可以在優化,先這樣吧,簡單記錄下。這次主要優化的部分數據庫和Java代碼部分,前端的很少。
一、數據庫
優化先從瀏覽器的接口調用看,查看到耗時近1分鐘,根據接口名稱查詢對應的Java代碼,發現代碼中存在兩個SQL的調用,順著引用找到SQL語句,一看是兩個都是關聯查詢的SQL,其中一個還是關聯了5張表,復制出來后,到SQL端執行,確實很慢。
數據庫優化很好用的兩個命令是EXPLAIN和EXPLAIN ANALYZE命令,都是加載查詢語句前面,用于分析查詢計劃和查詢實際執行情況的。
然后是使用EXPLAIN命令查看查詢計劃的的信息,判斷是否有需要添加或修改的索引。
使用案例:
---只需將 EXPLAIN 關鍵字加在查詢語句開頭就行 EXPLAIN SELECT COUNT(DISTINCT h.id)
FROM test h
JOIN test2 s ON h.id = s.father_id
WHERE s.first_classify = 'QC' ;執行結果示例

EXPLAIN 命令可以用來分析 SQL 查詢語句的執行計劃,它返回一組字段信息,提供了有關查詢的重要性能指標和執行計劃的詳細信息。下面是 EXPLAIN 命令返回的字段信息的介紹:
id:查詢的標識符,用于標識查詢中的每個操作步驟。如果查詢有多個操作步驟,id 可能會有多個數字,表示操作步驟的執行順序。
select_type:操作步驟的類型,表示查詢的類型。常見的類型有 SIMPLE(簡單查詢)、PRIMARY(主查詢)、SUBQUERY(子查詢)、DERIVED(派生表查詢)等。
table:操作步驟涉及的表的名稱。
partitions:操作步驟使用的分區。
type:訪問表的方式,表示查詢使用的訪問方法。常見的類型有 const(常量表)、eq_ref(唯一索引查找)、ref(非唯一索引查找)、range(范圍查找)、index(索引掃描)、all(全表掃描)等。一般來說,訪問方法從最好到最差的順序是:const、eq_ref、ref、range、index、all。
possible_keys:可能應用于該操作步驟的索引列表。
key:實際應用于該操作步驟的索引。
key_len:索引字段的長度。
ref:操作步驟使用的索引字段或常量與表之間的關聯。
rows:操作步驟掃描的行數估計。
filtered:操作步驟的行過濾百分比。
Extra:附加信息,提供了關于操作步驟的其他信息,例如是否使用了臨時表、是否使用了文件排序等。
這些字段信息可以了解查詢的執行計劃和性能瓶頸,從而進行性能優化和調整。通過分析這些信息,可以確定是否需要添加索引、優化查詢條件、重構查詢語句等來提高查詢性能。
不同的數據庫管理系統(如MySQL、PostgreSQL等)可能會略有不同的字段信息和含義。
關鍵信息是type類型,盡量少用全表掃描。possible_keys,在適合的字段上加上索引。索引的是使用是用空間換時間。
下面是使用EXPLAIN ANALYZE 命令執行查詢結果分析
---只需將 EXPLAIN ANALYZE 關鍵字加在查詢語句開頭就行 EXPLAIN ANALYZE SELECT COUNT(DISTINCT h.id)
FROM test h
JOIN test2 s ON h.id = s.father_id
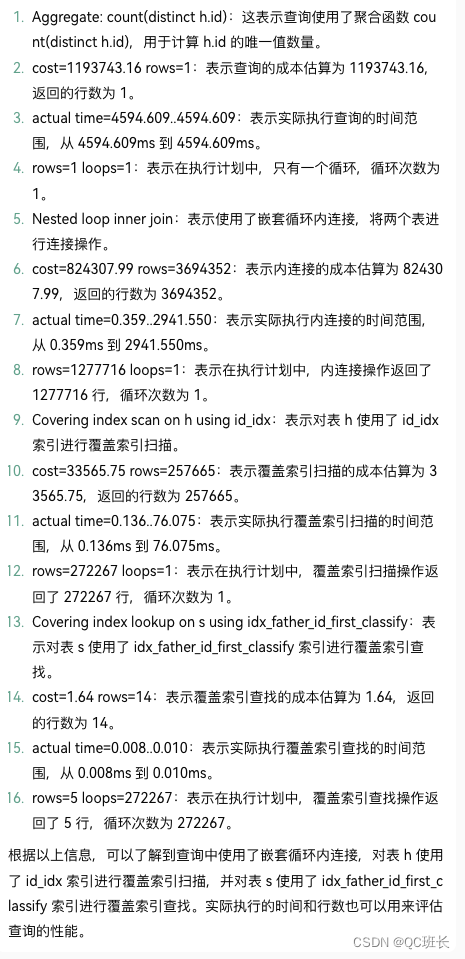
WHERE s.first_classify = 'QC' ;執行結果,如果你看不懂,可以直接把查詢結果丟給ChatGPT讓它給你分析,并逐行注釋。

-> Aggregate: count(distinct h.id) (cost=1193743.16 rows=1) (actual time=4594.609..4594.609 rows=1 loops=1)-> Nested loop inner join (cost=824307.99 rows=3694352) (actual time=0.359..2941.550 rows=1277716 loops=1)-> Covering index scan on h using id_idx (cost=33565.75 rows=257665) (actual time=0.136..76.075 rows=272267 loops=1)-> Covering index lookup on s using idx_father_id_first_classify (father_id=h.id, first_classify='F41A01') (cost=1.64 rows=14) (actual time=0.008..0.010 rows=5 loops=272267)
?
EXPLAIN ANALYZE 命令是一種用于分析 SQL 查詢語句執行計劃和實際執行時間的命令。它返回的字段信息包括 EXPLAIN 命令的字段信息,同時還包括以下字段:
QUERY PLAN:查詢執行計劃的詳細信息,包括操作步驟、訪問方法、索引使用等。
Planning Time:查詢規劃階段的時間,表示生成查詢執行計劃所花費的時間。
Execution Time:查詢執行階段的時間,表示實際執行查詢所花費的時間。
Actual Rows:實際掃描的行數,表示查詢實際掃描的行數。
Actual Loops:實際循環次數,表示查詢實際執行的循環次數。
Actual Startup Time:實際開始執行查詢的時間。
Actual Total Time:實際執行查詢的總時間。
Actual Time:實際執行查詢的時間,以毫秒為單位。
EXPLAIN ANALYZE 命令返回的字段信息可以幫助您更全面地了解查詢的執行計劃和實際執行情況。通過分析這些信息,可以確定查詢的性能瓶頸、優化查詢計劃、減少查詢執行時間等。同時,還可以比較不同查詢語句的執行效果,選擇性能最佳的查詢方式。
最后通過ANALYZE TABLE 命令來優化下對應的表,
---只需將 EXPLAIN TABLE 關鍵字加在表名開頭就行
ANALYZE TABLE test;ANALYZE TABLE 命令是用于分析和收集數據庫表統計信息的命令。它的主要作用是幫助優化查詢性能和執行計劃。
ANALYZE TABLE 命令會完成以下任務:
優化查詢計劃:通過分析表的統計信息,數據庫管理系統可以更準確地估計查詢的成本和選擇最優的執行計劃。
選擇合適的索引:通過分析表的索引長度和數據分布情況,可以判斷是否需要創建或刪除索引,以及選擇合適的索引類型和列順序。
優化存儲空間:通過分析表的行數和平均行長度,可以估計表的總大小,并根據需要進行存儲空間的調整。
檢測表的完整性:通過分析更新時間和自增值,可以檢測表的數據是否完整,并及時發現可能存在的問題。
數據庫的查詢,通過加索引大部分都能解決,在這個過程中善于用ChatGPT來幫助解決很重要。
二、Java程序代碼
下面是程序代碼的部分,原本的程序代碼并不是我寫的,打開看了之后,有兩個執行查詢的代碼段是可以同時執行的,所以改成并發執行。
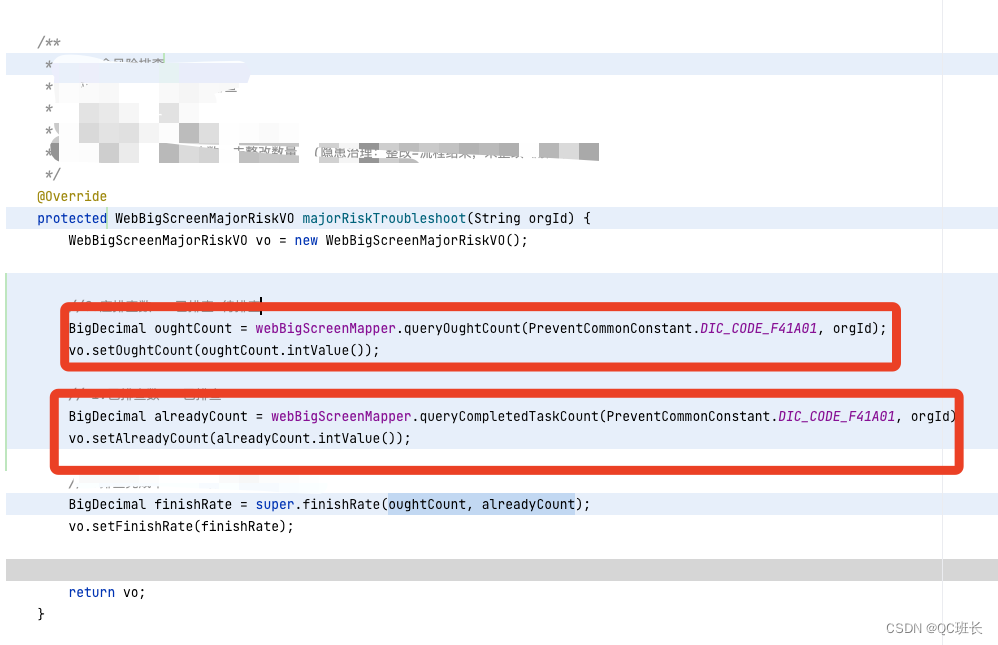
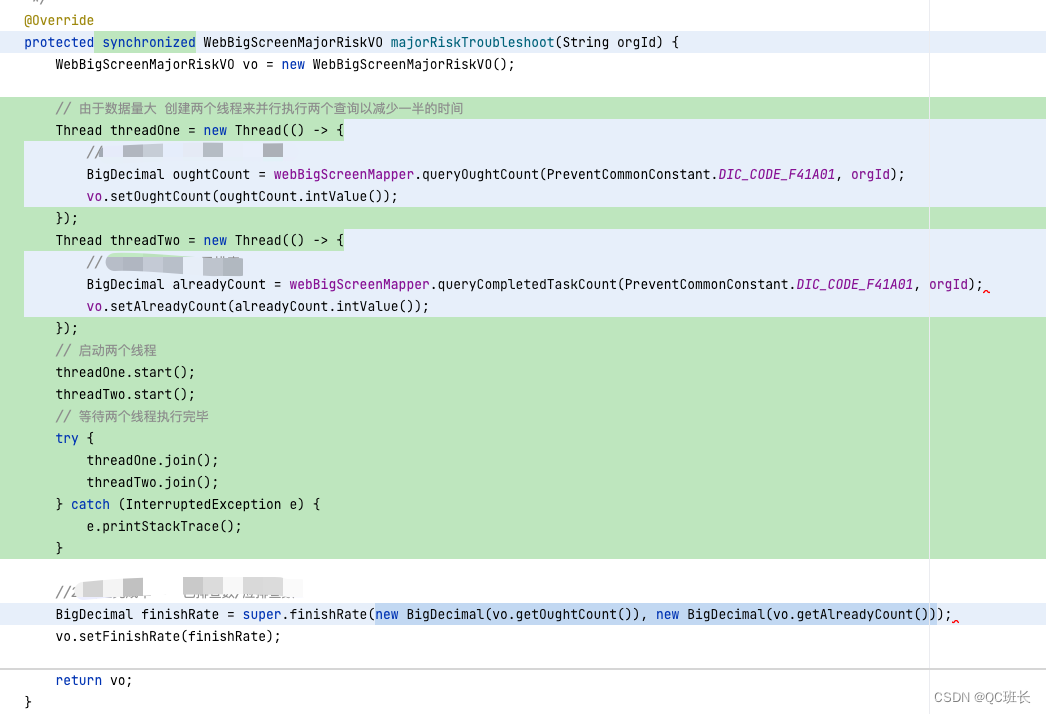 程序上改后,接口時間就減少一半了,接口時間來到了4.5秒左右,但其實還是慢。
程序上改后,接口時間就減少一半了,接口時間來到了4.5秒左右,但其實還是慢。
三、前端React代碼
在改改前端,前端的話,可以把這個接口的查詢放在最開始執行,以減少用戶使用的等待延遲感受。前段端代碼就省略了。下次有機會在寫吧。
四、總結拓展
性能優化某種意義上是對資源取舍利用的問題。通常是就是空間和時間的互換與取舍。
以下是我收集到的常見的6種互換手段。
1、索引
索引的原理是拿額外的存儲空間換取查詢時間,增加了寫入數據的開銷,但使讀取數據的時間復雜度一般從O(n)降低到O(logn)甚至O(1)。
在數據集比較大時,不用索引就像從一本沒有目錄而且內容亂序的新華字典查一個字,得一頁一頁全翻一遍才能找到;用索引之后,就像用拼音先在目錄中先找到要查到字在哪一頁,直接翻過去就行了。書籍的目錄是典型的樹狀結構。
2、緩存
緩存優化性能的原理和索引一樣,是拿額外的存儲空間換取查詢時間。Phil Karlton 曾說過:計算機科學中只有兩件困難的事情:緩存失效和命名規范。緩存的使用除了帶來額外的復雜度以外,還面臨如何處理緩存失效的問題。
3、壓縮
壓縮的原理消耗計算的時間,換一種更緊湊的編碼方式來表示數據。對數據的壓縮雖然消耗了時間來換取更小的空間存儲,但更小的存儲空間會在另一個維度帶來更大的時間收益。
能減少的就減少:
-
JS打包過程“搖樹”,去掉沒有使用的文件、函數、變量;
-
開啟HTTP/2和高版本的TLS,減少了Round Trip,節省了TCP連接,自帶大量性能優化;
-
減少不必要的信息,比如Cookie的數量,去掉不必要的HTTP請求頭;
-
更新采用增量更新,比如HTTP的PATCH,只傳輸變化的屬性而不是整條數據;
-
縮短單行日志的長度、縮短URL、在具有可讀性情況下用短的屬性名等等;
-
使用位圖和位操作,用風騷的位操作最小化存取的數據。典型的例子有:用Redis的位圖來記錄統計海量用戶登錄狀態;布隆過濾器用位圖排除不可能存在的數據;大量開關型的設置的存儲等等。
能刪除的就刪除:
-
刪掉不用的數據;
-
刪掉不用的索引;
-
刪掉不該打的日志;
-
刪掉不必要的通信代碼,不去發不必要的HTTP、RPC請求或調用,輪詢改發布訂閱;
-
終極方案:砍掉整個功能。
4、預取
預取通常搭配緩存一起用,其原理是在緩存空間換時間基礎上更進一步,再加上一次“時間換時間”,也就是:用事先預取的耗時,換取第一次加載的時間。
當可以猜測出以后的某個時間很有可能會用到某種數據時,把數據預先取到需要用的地方,能大幅度提升用戶體驗或服務端響應速度。
5、削峰填谷
削峰填谷的原理也是“時間換時間”,谷時換峰時。
削峰填谷與預取是反過來的:預取是事先花時間做,削峰填谷是事后花時間做。就像三峽大壩可以抗住短期巨量洪水,事后雨停再慢慢開閘防水。軟件世界的“削峰填谷”是類似的,只是不是用三峽大壩實現,而是用消息隊列、異步化等方式。
6、批量處理
批量處理同樣可以看成“時間換時間”,其原理是減少了重復的事情,是一種對執行流程的壓縮。以個別批量操作更長的耗時為代價,在整體上換取了更多的時間。
-
前端把所有文件打包成單個JS,大部分時候并不是最優解。Webpack提供了很多分塊的機制,CSS和JS分開、JS按業務分更小的Chunk結合懶加載、一些體積大又不用在首屏用的第三方庫設置external或單獨分塊,可能整體性能更高。不一定要一批搞定所有事情,分幾個小批次反而用戶體驗的性能更好。
-
Redis的MGET、MSET來批量存取數據時,每批大小不宜過大,因為Redis主線程只有一個,如果一批太大執行期間會讓其他命令無法響應。經驗上一批50-100個Key性能是不錯的,但最好在真實環境下用真實大小的數據量化度量一下,做Benchmark測試才能確定一批大小的最優值。
-
MySQL、Oracle這類RDBMS,最優的批量Insert的大小也視數據行的特性而定。我之前在2U8G的Oracle上用一些普遍的業務數據做過測試,批量插入時每批5000-10000條數據性能是最高的,每批過大會導致DML的解析耗時過長,甚至單個SQL語句體積超限,單批太多反而得不償失。
-
消息隊列的發布訂閱,每批的消息長度盡量控制在1MB以內,有些云服務商提供的消息隊列限制了最大長度,那這個長度可能就是性能拐點,比如AWS的SQS服務對單條消息的限制是256KB。
?
還有與提升并行能力有點關的4中方式:
- 榨干計算資源
- 水平擴容
- 分片
- 無鎖
參考文獻
性能優化的 10 個技巧!(文末送書)?









)
)






)

