在前文中我們基于經典的YOLOv5開發構建了鋼鐵產業產品智能自動化檢測識別系統,這里本文的主要目的是想要實踐應用DETR這一端到端的檢測模型來開發構建鋼鐵產業產品智能自動化檢測識別系統。
DETR (DEtection TRansformer) 是一種基于Transformer架構的端到端目標檢測模型。與傳統的基于區域提議的目標檢測方法(如Faster R-CNN)不同,DETR采用了全新的思路,將目標檢測問題轉化為一個序列到序列的問題,通過Transformer模型實現目標檢測和目標分類的聯合訓練。
DETR的工作流程如下:
輸入圖像通過卷積神經網絡(CNN)提取特征圖。
特征圖作為編碼器輸入,經過一系列的編碼器層得到圖像特征的表示。
目標檢測問題被建模為一個序列到序列的轉換任務,其中編碼器的輸出作為解碼器的輸入。
解碼器使用自注意力機制(self-attention)對編碼器的輸出進行處理,以獲取目標的位置和類別信息。
最終,DETR通過一個線性層和softmax函數對解碼器的輸出進行分類,并通過一個線性層預測目標框的坐標。
DETR的優點包括:
端到端訓練:DETR模型能夠直接從原始圖像到目標檢測結果進行端到端訓練,避免了傳統目標檢測方法中復雜的區域提議生成和特征對齊的過程,簡化了模型的設計和訓練流程。
不受固定數量的目標限制:DETR可以處理變長的輸入序列,因此不受固定數量目標的限制。這使得DETR能夠同時檢測圖像中的多個目標,并且不需要設置預先確定的目標數量。
全局上下文信息:DETR通過Transformer的自注意力機制,能夠捕捉到圖像中不同位置的目標之間的關系,提供了更大范圍的上下文信息。這有助于提高目標檢測的準確性和魯棒性。
然而,DETR也存在一些缺點:
計算復雜度高:由于DETR采用了Transformer模型,它在處理大尺寸圖像時需要大量的計算資源,導致其訓練和推理速度相對較慢。
對小目標的檢測性能較差:DETR模型在處理小目標時容易出現性能下降的情況。這是因為Transformer模型在處理小尺寸目標時可能會丟失細節信息,導致難以準確地定位和分類小目標。
首先看下實例效果:
?
簡單看下數據集:

PyTorch訓練代碼和DETR(DEDetection-TRansformer)的預訓練模型。我們用Transformer替換了完全復雜的手工制作的對象檢測管道,并將Faster R-CNN與ResNet-50匹配,使用一半的計算能力(FLOP)和相同數量的參數在COCO上獲得42個AP。
官方項目地址在這里,如下所示:

可以看到目前已經收獲了超過1.2w的star量,還是很不錯的了。
DETR整體數據流程示意圖如下所示:

官方也提供了對應的預訓練模型,可以自行使用:
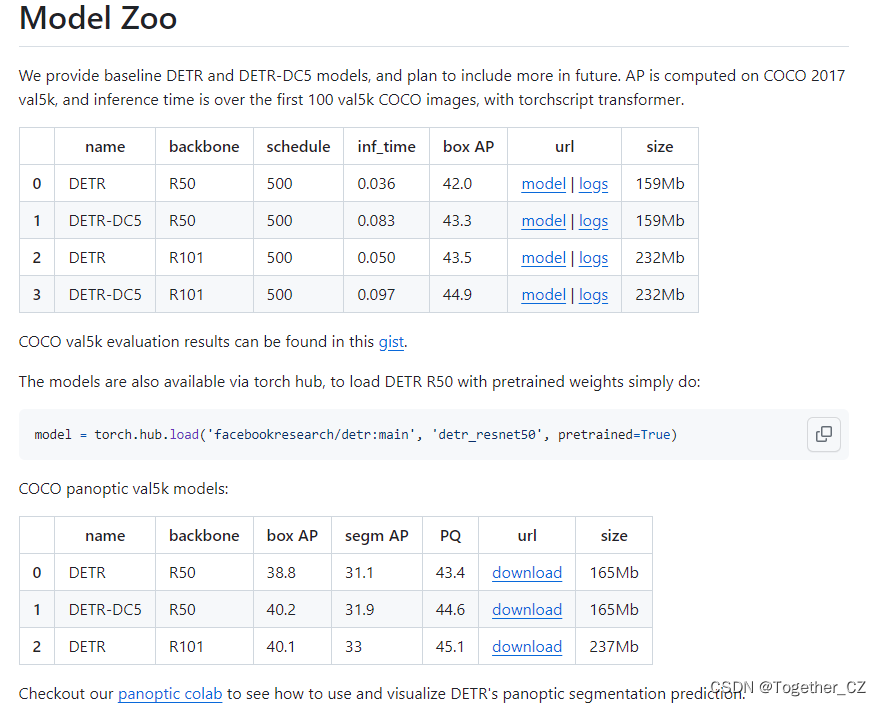
本文選擇的預訓練官方權重是detr-r50-e632da11.pth,首先需要基于官方的預訓練權重開發能夠用于自己的 個性化數據集的權重,如下所示:
pretrained_weights = torch.load("./weights/detr-r50-e632da11.pth")
num_class = 10 + 1
pretrained_weights["model"]["class_embed.weight"].resize_(num_class+1,256)
pretrained_weights["model"]["class_embed.bias"].resize_(num_class+1)
torch.save(pretrained_weights,'./weights/detr_r50_%d.pth'%num_class)因為這里我的類別數量為10,所以num_class修改為:10+1,根據自己的實際情況修改即可。生成后如下所示:
![]()
之后按照官方說明準備好數據集即可,啟動訓練模型命令如下所示:
python main.py --dataset_file "coco" --coco_path "/0000" --epoch 100 --lr=1e-4 --batch_size=32 --num_workers=0 --output_dir="outputs" --resume="weights/detr_r50_11.pth"
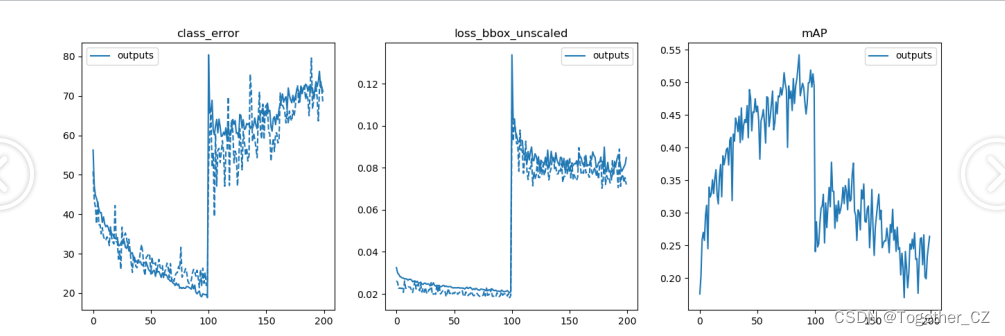
借助于plot_util.py模塊可以實現對模型的評估和可視化,如下:
def plot_logs(logs, fields=('class_error', 'loss_bbox_unscaled', 'mAP'), ewm_col=0, log_name='log.txt'):'''Function to plot specific fields from training log(s). Plots both training and test results.:: Inputs - logs = list containing Path objects, each pointing to individual dir with a log file- fields = which results to plot from each log file - plots both training and test for each field.- ewm_col = optional, which column to use as the exponential weighted smoothing of the plots- log_name = optional, name of log file if different than default 'log.txt'.:: Outputs - matplotlib plots of results in fields, color coded for each log file.- solid lines are training results, dashed lines are test results.'''func_name = "plot_utils.py::plot_logs"# verify logs is a list of Paths (list[Paths]) or single Pathlib object Path,# convert single Path to list to avoid 'not iterable' errorif not isinstance(logs, list):if isinstance(logs, PurePath):logs = [logs]print(f"{func_name} info: logs param expects a list argument, converted to list[Path].")else:raise ValueError(f"{func_name} - invalid argument for logs parameter.\n \Expect list[Path] or single Path obj, received {type(logs)}")# Quality checks - verify valid dir(s), that every item in list is Path object, and that log_name exists in each dirfor i, dir in enumerate(logs):if not isinstance(dir, PurePath):raise ValueError(f"{func_name} - non-Path object in logs argument of {type(dir)}: \n{dir}")if not dir.exists():raise ValueError(f"{func_name} - invalid directory in logs argument:\n{dir}")# verify log_name existsfn = Path(dir / log_name)if not fn.exists():print(f"-> missing {log_name}. Have you gotten to Epoch 1 in training?")print(f"--> full path of missing log file: {fn}")return# load log file(s) and plotdfs = [pd.read_json(Path(p) / log_name, lines=True) for p in logs]fig, axs = plt.subplots(ncols=len(fields), figsize=(16, 5))for df, color in zip(dfs, sns.color_palette(n_colors=len(logs))):for j, field in enumerate(fields):if field == 'mAP':coco_eval = pd.DataFrame(np.stack(df.test_coco_eval_bbox.dropna().values)[:, 1]).ewm(com=ewm_col).mean()axs[j].plot(coco_eval, c=color)else:df.interpolate().ewm(com=ewm_col).mean().plot(y=[f'train_{field}', f'test_{field}'],ax=axs[j],color=[color] * 2,style=['-', '--'])for ax, field in zip(axs, fields):ax.legend([Path(p).name for p in logs])ax.set_title(field)def plot_precision_recall(files, naming_scheme='iter'):if naming_scheme == 'exp_id':# name becomes exp_idnames = [f.parts[-3] for f in files]elif naming_scheme == 'iter':names = [f.stem for f in files]else:raise ValueError(f'not supported {naming_scheme}')fig, axs = plt.subplots(ncols=2, figsize=(16, 5))for f, color, name in zip(files, sns.color_palette("Blues", n_colors=len(files)), names):data = torch.load(f)# precision is n_iou, n_points, n_cat, n_area, max_detprecision = data['precision']recall = data['params'].recThrsscores = data['scores']# take precision for all classes, all areas and 100 detectionsprecision = precision[0, :, :, 0, -1].mean(1)scores = scores[0, :, :, 0, -1].mean(1)prec = precision.mean()rec = data['recall'][0, :, 0, -1].mean()print(f'{naming_scheme} {name}: mAP@50={prec * 100: 05.1f}, ' +f'score={scores.mean():0.3f}, ' +f'f1={2 * prec * rec / (prec + rec + 1e-8):0.3f}')axs[0].plot(recall, precision, c=color)axs[1].plot(recall, scores, c=color)axs[0].set_title('Precision / Recall')axs[0].legend(names)axs[1].set_title('Scores / Recall')axs[1].legend(names)return fig, axs
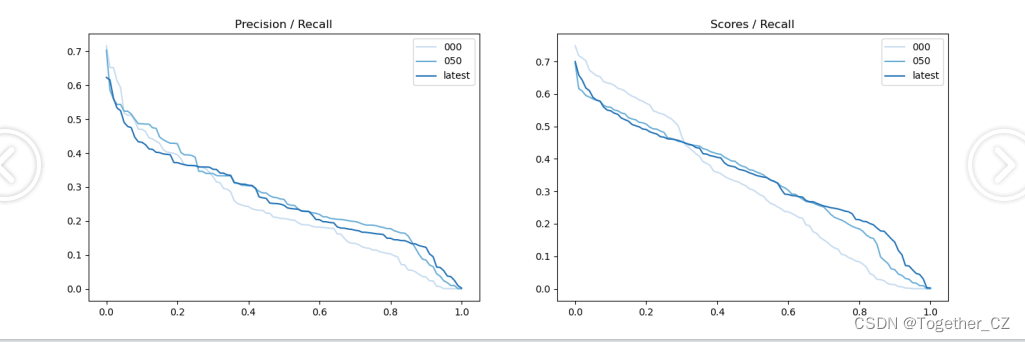
結果如下所示:
iter 000: mAP@50= 24.0, score=0.317, f1=0.341
iter 050: mAP@50= 27.7, score=0.339, f1=0.400
iter latest: mAP@50= 26.4, score=0.348, f1=0.393
iter 000: mAP@50= 24.0, score=0.317, f1=0.341
iter 050: mAP@50= 27.7, score=0.339, f1=0.400
iter latest: mAP@50= 26.4, score=0.348, f1=0.393可視化如下所示:
【Precision曲線】
精確率曲線(Precision-Recall Curve)是一種用于評估二分類模型在不同閾值下的精確率性能的可視化工具。它通過繪制不同閾值下的精確率和召回率之間的關系圖來幫助我們了解模型在不同閾值下的表現。
精確率(Precision)是指被正確預測為正例的樣本數占所有預測為正例的樣本數的比例。召回率(Recall)是指被正確預測為正例的樣本數占所有實際為正例的樣本數的比例。
繪制精確率曲線的步驟如下:
使用不同的閾值將預測概率轉換為二進制類別標簽。通常,當預測概率大于閾值時,樣本被分類為正例,否則分類為負例。
對于每個閾值,計算相應的精確率和召回率。
將每個閾值下的精確率和召回率繪制在同一個圖表上,形成精確率曲線。
根據精確率曲線的形狀和變化趨勢,可以選擇適當的閾值以達到所需的性能要求。
通過觀察精確率曲線,我們可以根據需求確定最佳的閾值,以平衡精確率和召回率。較高的精確率意味著較少的誤報,而較高的召回率則表示較少的漏報。根據具體的業務需求和成本權衡,可以在曲線上選擇合適的操作點或閾值。
精確率曲線通常與召回率曲線(Recall Curve)一起使用,以提供更全面的分類器性能分析,并幫助評估和比較不同模型的性能。
【Recall曲線】
召回率曲線(Recall Curve)是一種用于評估二分類模型在不同閾值下的召回率性能的可視化工具。它通過繪制不同閾值下的召回率和對應的精確率之間的關系圖來幫助我們了解模型在不同閾值下的表現。
召回率(Recall)是指被正確預測為正例的樣本數占所有實際為正例的樣本數的比例。召回率也被稱為靈敏度(Sensitivity)或真正例率(True Positive Rate)。
繪制召回率曲線的步驟如下:
使用不同的閾值將預測概率轉換為二進制類別標簽。通常,當預測概率大于閾值時,樣本被分類為正例,否則分類為負例。
對于每個閾值,計算相應的召回率和對應的精確率。
將每個閾值下的召回率和精確率繪制在同一個圖表上,形成召回率曲線。
根據召回率曲線的形狀和變化趨勢,可以選擇適當的閾值以達到所需的性能要求。
通過觀察召回率曲線,我們可以根據需求確定最佳的閾值,以平衡召回率和精確率。較高的召回率表示較少的漏報,而較高的精確率意味著較少的誤報。根據具體的業務需求和成本權衡,可以在曲線上選擇合適的操作點或閾值。
召回率曲線通常與精確率曲線(Precision Curve)一起使用,以提供更全面的分類器性能分析,并幫助評估和比較不同模型的性能。
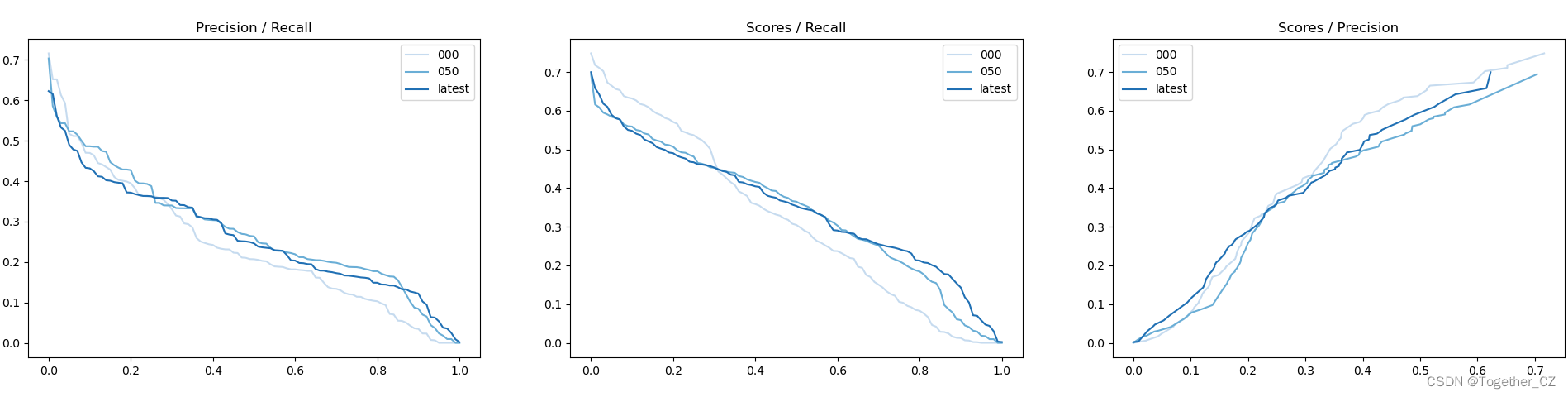
【PR曲線】
精確率-召回率曲線(Precision-Recall Curve)是一種用于評估二分類模型性能的可視化工具。它通過繪制不同閾值下的精確率(Precision)和召回率(Recall)之間的關系圖來幫助我們了解模型在不同閾值下的表現。
精確率是指被正確預測為正例的樣本數占所有預測為正例的樣本數的比例。召回率是指被正確預測為正例的樣本數占所有實際為正例的樣本數的比例。
繪制精確率-召回率曲線的步驟如下:
使用不同的閾值將預測概率轉換為二進制類別標簽。通常,當預測概率大于閾值時,樣本被分類為正例,否則分類為負例。
對于每個閾值,計算相應的精確率和召回率。
將每個閾值下的精確率和召回率繪制在同一個圖表上,形成精確率-召回率曲線。
根據曲線的形狀和變化趨勢,可以選擇適當的閾值以達到所需的性能要求。
精確率-召回率曲線提供了更全面的模型性能分析,特別適用于處理不平衡數據集和關注正例預測的場景。曲線下面積(Area Under the Curve, AUC)可以作為評估模型性能的指標,AUC值越高表示模型的性能越好。
通過觀察精確率-召回率曲線,我們可以根據需求選擇合適的閾值來權衡精確率和召回率之間的平衡點。根據具體的業務需求和成本權衡,可以在曲線上選擇合適的操作點或閾值。?
感興趣的話可以自行動手實踐嘗試下!









上安裝mysql)

:package_info中配置禁用CMakeDeps生成使用項目自己生成的config.cmake)







