mglru與原lru算法的兼容
舊的lru算法有active與inactive兩代lru,可參考linux 內存回收代碼注釋(未實現多代lru版本)-CSDN博客
新的算法在引入4代lru的同時,還引入了tier的概念。
新舊算法的切換的實現在lru_gen_change_state,當開啟mglru時,調用fill_evictable,將active list 與 inactive list 的folio遷移到 mglru上(mglru的組織方式是:lruvec[gen][type][zone]),如果是關閉mglru,則調用drain_evictable,將mglru的folio遷移回active/inactive list兩代的情況。
當開啟mglru時,原有shrink_node與shrink_lruvec的路徑會短路,主要體現在兩個地方,對于全局的回收直接調用lru_gen_shrink_node,對于某個memory group 的回收會間接調用lru_gen_shrink_lruvec:
shrink_nodeif (lru_gen_enabled() && root_reclaim(sc)) {lru_gen_shrink_node(pgdat, sc);return;}shrink_lruvecif (lru_gen_enabled() && !root_reclaim(sc)) {lru_gen_shrink_lruvec(lruvec, sc);return;}真正做頁的回收的邏輯還是在shrink_folio_list。?
mglru與原lru算法的差別
與舊的lru算法區別,主要有三個方面:1、修改了一次掃描要掃的數量計算邏輯。2、修改了代與代之間轉換的邏輯。3、添加了refault頁的延遲回收機制
mglru的組織
每個numa node 有一個 pgdat 結構,上面綁定了為每個memory group準備了兩代bin list,分別為young bin list和old bin list,第個bin list 上有8個bin,新加入的memory group會隨機找一個 bin list 加入(lru_gen_online_memcg)。回收總是在old代上做,找一個bin list,從頭掃描到尾。memory group 會隨著它分配的內存大小和是否做了回收,在old與young的bin list 頭尾上游走。(lru_gen_rotate_memcg),具體而言:
1、memory group 的內存超過?soft limit 時,將它移至同代的開頭,下次可能回收它(lru_gen_soft_reclaim,MEMCG_LRU_HEAD)
2、新加入的memory group會放在新代的結尾處,第一次掃描發現頁數少于2^priority或是第一次掃描發現頁數在low水位線以下時,會放在新代的結尾處(MEMCG_LRU_TAIL)
3、當第一次掃描發現內存在min水位以下,或第二次掃描發現上次掃描是小于2^priority的,或是每次掃描完足夠頁數時會把最后一個掃描的memory group 移至新代(MEMCG_LRU_YOUNG)。
4、在移除一個memory group時,需要回收全部內存,會把它放在old代(lru_gen_offline_memcg,MEMCG_LRU_OLD)
bin list 中每一項是memory group的lruvec指針。
lruvec內部分成了4代,每代有兩個type:文件or匿名,每個type又維護了每個zone上的頁框,如下:
// 找一個 group 對應在某個 node 上的lru
lruvec = &memcg->nodeinfo[pgdat->node_id]->lruvec.lrugen;
// 遍歷一個 node 上某個 binlist 的 lru
lrugen = pgdat->memcg_lru.fifo[gen][bin];
// lru 內的頁框
lrugen->folios[gen][type][zone]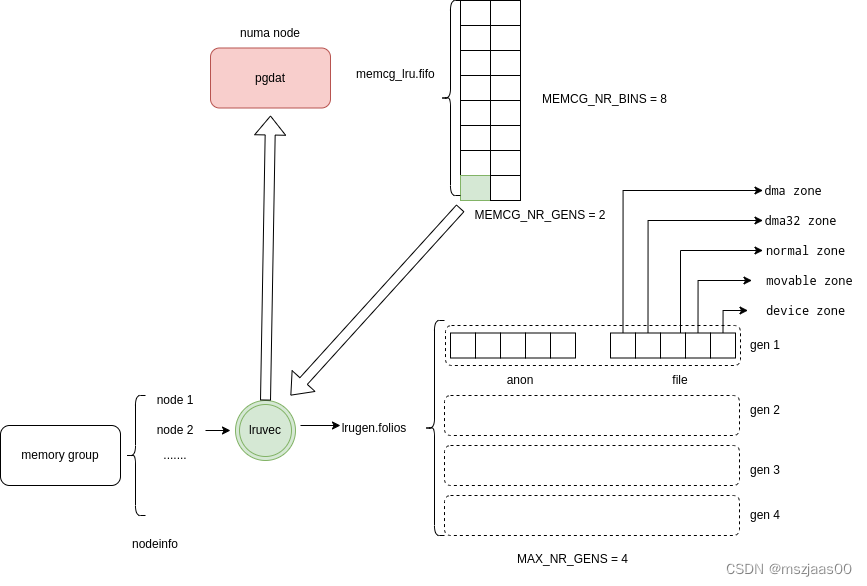
掃描數量
原有的swappiness表示回收匿名頁與文件頁的加權,取值1~200,值越小越支持從匿名頁回收。新算法計算掃描數量的方法變了,只根據swappiness有無賦值來決定要不要計算掃描匿名頁的數量,文件頁一定會掃描回收。計算的方式也比較粗暴:total >>?sc->priority;具體計算邏輯在get_nr_to_scan->should_run_aging。
代際轉換
如果在should_run_aging計算時發現最新一代的頁框數已經是總頁框數的一半,或第三代的頁框數小于總頁框數的四分之一,就觸發一次代際迭換,嘗試發現young 頁,把它們提升至最新代。代際迭換的代碼在try_to_inc_max_seq。
try_to_inc_max_seq():// 硬件不支持自動標記access flagif (!should_walk_mmu()) {iterate_mm_list_nowalk(lruvec, max_seq);return;}// 嘗試掃描 hot pmd 中的 young 頁。 do {is_last = iterate_mm_list(lruvec, walk, &mm);if (mm)walk_mm(lruvec, mm, walk);} while (mm);// 這一代掃描結束,更新代際if (is_last)inc_max_seq(lruvec, can_swap, force_scan);如果硬件支持自動在頁表記錄訪問標記,則掃描一遍(掃描的實現在try_to_inc_max_seq->walk_mm->walk_pgd_range->walk_pud_range->walk_pmd_range->walk_pte_range),通過檢查bloom filter,找到標記為hot的pmd,訪問pmd中全部pte,將標記臟的pte對應頁框標記為臟,并更新至最新代。這里說的bloom filter標記了平均每個cacheline中young頁數大于1的pmd,只需要對這些pmd的全部pte中young 頁的掃描,并標記臟和更新代數,因為這個pmd范圍的young頁多,是個熱點區,意味著后面可能還會產生hot頁。如果硬件不支持自動設置訪問標記,就不能在這個地方掃了,而要等到建立rmap時,folio_referenced_one->lru_gen_look_around
bloom filter的設置有兩個途徑,一個是在上面說的掃描全部pte之后,計算young頁數/total頁數大于cacheline中能裝下的pte數(或者說是不是平均每個cacheline都有一個pte項對應了young頁,實現在suitable_to_scan);另一個是在shrink_folio_list時,會找一個頁框映射的次數(folio_referenced),會調一次lru_gen_look_around,嘗試看下這個pte對應的pmd中全部pte,同樣是在標記完臟頁、統計完young頁數時,計算young頁數/total頁數大于cacheline中能裝下的pte數,并把young 標記清掉。
這個過程大概代碼如下:
walk_pmd_range():
{
restart:for pmd_i in start_addr.. end_addr:// 檢查是不是hot pmdif (!test_bloom_filter(max_seq, pmd_i))continue;// 檢查hot pmd的所有pte中的臟頁,并統計young的頁數和清空young標記(young 指最近有訪問),計算它還是不是hot pmdis_still_hot = walk_pte_range(addr, pmd_end_addr);// 如果是hot的pmd,則在bloom filter 標記一下,下一輪(代)掃描時再檢查一次這個pmdif (is_still_hot)update_bloom_filter(max_seq + 1, pmd + i);}if (i < PTRS_PER_PMD && get_next_vma(PUD_MASK, PMD_SIZE, args, &start, &end))goto restart;
}walk_pte_range():new_gen = lru_gen_from_seq(walk->max_seq);
restart:for pte_i in start_addr.. end_addr: {// 硬件標記pte臟的,但頁框沒有標記臟,且這是文件頁或未換出的匿名頁,則在頁框上標記下臟if (pte_dirty(ptent) && !folio_test_dirty(folio) &&!(folio_test_anon(folio) && folio_test_swapbacked(folio) &&!folio_test_swapcache(folio)))folio_mark_dirty(folio);// 將這一頁框更新到最新代old_gen = folio_update_gen(folio, new_gen);// 更新統計walk->nr_pages[old_gen][type][zone] 和 walk->nr_pages[new_gen][type][zone]if (old_gen >= 0 && old_gen != new_gen)update_batch_size(walk, folio, old_gen, new_gen);}if (i < PTRS_PER_PTE && get_next_vma(PMD_MASK, PAGE_SIZE, args, &start, &end))goto restart;// 計算young頁數/total頁數大于cacheline中能裝下的pte數(或者說是不是平均每個cacheline都有一個pte項對應了young頁)return suitable_to_scan(total, young);
}Refault頁的延遲回收
refault指缺頁讀入后又換出又讀入。mglru引入tier概念,組織形式為lrugen->refaulted[hist][type][tier]。為file 和anon類型的頁,維護了4代統計直方圖(hist),每個直方圖中有4個范圍(tier),分別統計了本輪回收中訪問了1次,2次,4次,8次的頁數。
當觸發refault時,會統計累加本輪回收中,已經refault這么多次的頁數。(lru_gen_refault)
lru_gen_refault():// recent 指refault與上次回收在同一代內recent = lru_gen_test_recent(shadow, type, &lruvec, &token, &workingset);// 總共有4代histogram,根據當前代數算出它在那個histogram中hist = lru_hist_from_seq(READ_ONCE(lrugen->min_seq[type]));// 每代有4個tier,tier的index = log2(本輪掃描中這頁的 access 數),即分別為訪問1次,2次,4次,8次的tier。tier = lru_tier_from_refs(refs);// 統計累加本輪掃描過程中發生 2^tier 次 refault 的頁數。atomic_long_add(delta, &lrugen->refaulted[hist][type][tier]);在決定是否回收頁時,evict_folios->isolate_folios,會平衡本輪發生refault 的頁數與回收+延時回收頁數的比值,計算一個控制值(refaulted/(evicted+protected)),可以理解為發生refault的頻繁程度。如果發生n次refault的頻繁程度達到了發生1次refault頻繁程度的2倍,則發生n次以上refault的頁都不再回收。
isolate_folios():// 計算refault次數超過多少后不再釋放tier_idx = get_tier_idx(lruvec, type);isolate_folios->scan_folios->sort_folio():// 本輪掃描中 refault 次數超過2^tier_idx 次的頁不再釋放,而是推到下一代if (tier > tier_idx) {// 將頁放在下一次lru尾(回收是從本代的頭開始的)gen = folio_inc_gen(lruvec, folio, false);list_move_tail(&folio->lru, &lrugen->folios[gen][type][zone]);// 累加本代中不釋放頁的頁數int hist = lru_hist_from_seq(lrugen->min_seq[type]);WRITE_ONCE(lrugen->protected[hist][type][tier - 1],lrugen->protected[hist][type][tier - 1] + delta);return true;}在回收過程中,每完成一次分離出回收頁的計算后(isolate_folios),會將這一代的統計值更新為新值與歷史值的滑動平均值。
在一輪回收結束時,會調inc_max_seq將下一輪回收的代統計值清空,為最新代的統計留出位置。





)












)
