在本文中,我們全面探討了文本分類技術的發展歷程、基本原理、關鍵技術、深度學習的應用,以及從RNN到Transformer的技術演進。文章詳細介紹了各種模型的原理和實戰應用,旨在提供對文本分類技術深入理解的全面視角。
關注TechLead,分享AI全維度知識。作者擁有10+年互聯網服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智能實驗室成員,阿里云認證的資深架構師,項目管理專業人士,上億營收AI產品研發負責人。

一、引言
文本分類作為人工智能領域的一個重要分支,其價值和影響力已經深入到我們日常生活的各個角落。在這個數據驅動的時代,文本分類不僅是機器學習和深度學習技術的集中展示,更是智能化應用的基礎。
文本分類的重要性
文本分類的核心是將文本數據按照其含義或屬性分配到預定義的類別中。這聽起來簡單,但在實際操作中卻極具挑戰性。為什么文本分類如此重要?其實,無論是個人用戶還是大型企業,我們都在日常生活中與海量的文本數據打交道。例如,電子郵件自動分類系統可以幫助我們區分垃圾郵件和重要郵件,社交媒體平臺利用文本分類來過濾不恰當的內容,而在商業智能中,文本分類幫助企業從客戶反饋中提取有價值的洞察。
技術發展歷程
文本分類技術的發展經歷了從簡單的基于規則的方法到復雜的機器學習算法,再到今天的深度學習模型的演變。在早期,文本分類依賴于專家系統和簡單的統計方法,但這些方法往往受限于規模和靈活性。隨著機器學習的發展,尤其是支持向量機(SVM)和隨機森林等算法的應用,文本分類的準確性和適應性有了顯著提高。進入深度學習時代,卷積神經網絡(CNN)和循環神經網絡(RNN)等模型極大地提高了文本分類的性能,特別是在處理大規模和復雜的數據集時。
現代應用實例
在現代應用中,文本分類技術已成為許多行業不可或缺的部分。例如,在金融領域,文本分類被用于分析市場趨勢和預測股市動態。金融分析師依賴于算法從新聞報道、社交媒體帖子和財報中提取關鍵信息,以做出更明智的投資決策。此外,醫療保健行業也在利用文本分類技術來處理病歷報告,自動識別疾病模式和病人需求,從而提高診斷的準確性和效率。
通過這些例子,我們可以看到,文本分類不僅是技術的展示,更是現代社會運作和發展的關鍵部分。隨著技術的不斷進步和應用領域的不斷拓展,文本分類的重要性和影響力只會繼續增長。
二、文本分類基礎
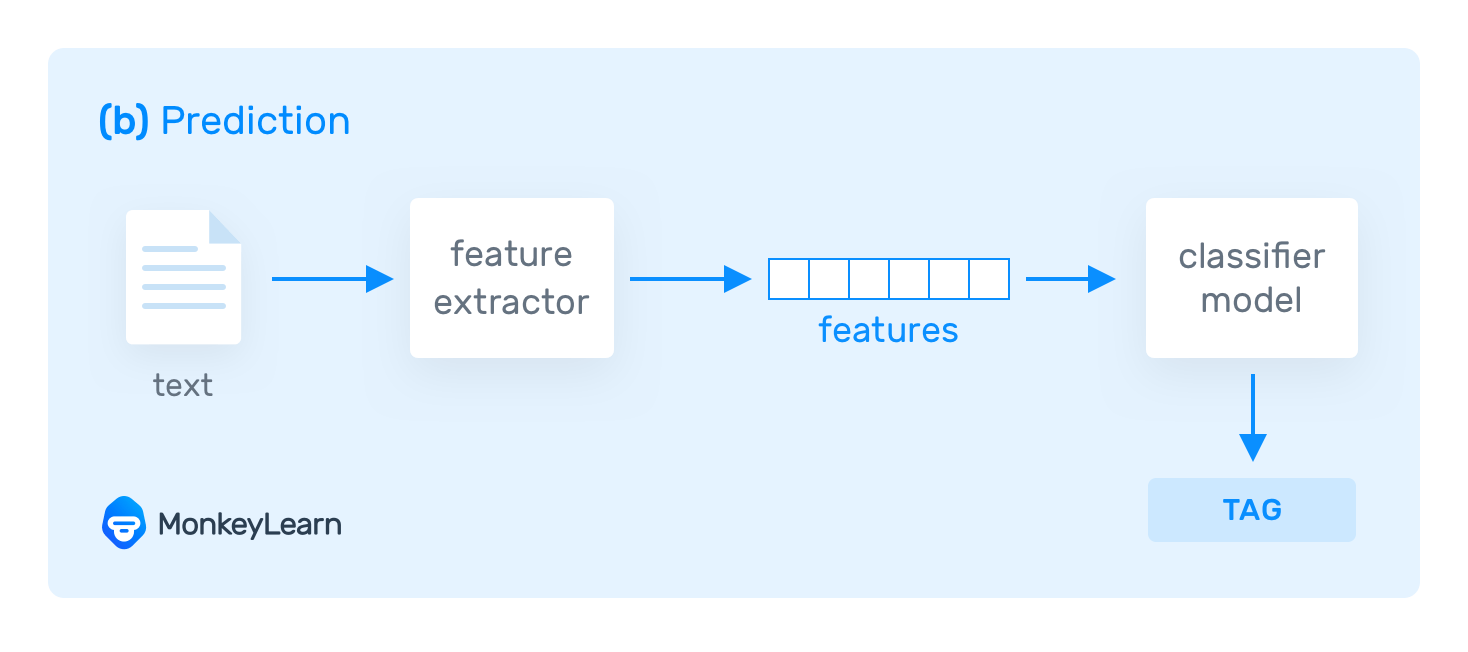
文本分類是人工智能和自然語言處理(NLP)領域的一個核心任務,涉及到理解和處理自然語言文本,將其分類到預定義的類別中。這一任務的基礎是理解文本的含義,并據此做出決策。
文本分類的定義和目的
簡單來說,文本分類是將文本數據(如文檔、郵件、網頁內容等)自動分配到一個或多個預定義類別的過程。這個過程的目的在于簡化信息處理,提高數據組織和檢索的效率,以及支持更復雜的信息處理任務,如情感分析或主題識別。
文本分類的關鍵要素
1. 預處理
- 重要性:預處理是文本分類的首要步驟,涉及清洗和準備原始文本數據。
- 方法:包括去除噪音(如特殊字符、無關信息)、詞干提取、分詞等。
2. 特征提取
- 概念:將文本轉化為機器可理解的形式,通常是數值向量。
- 技術:傳統方法如詞袋模型(Bag of Words)和TF-IDF,以及現代方法如詞嵌入(Word Embeddings)。
3. 分類算法
- 多樣性:文本分類可采用多種機器學習算法,包括樸素貝葉斯、決策樹、支持向量機等。
- 發展:深度學習方法如卷積神經網絡(CNN)和循環神經網絡(RNN)為文本分類帶來了革命性的改進。
文本分類的應用領域
文本分類廣泛應用于多個領域,包括:
- 垃圾郵件檢測:自動識別并過濾垃圾郵件。
- 情感分析:從用戶評論中提取情感傾向,廣泛應用于市場分析和社交媒體監控。
- 主題分類:自動識別文章或文檔的主題,用于新聞聚合、內容推薦等。
挑戰和考量
文本分類雖然技術成熟,但仍面臨一些挑戰:
- 語言多樣性和復雜性:不同語言和文化背景下的文本處理需要特定的適應和處理策略。
- 數據不平衡和偏見:訓練數據的質量直接影響分類性能,需要注意數據偏見和不平衡問題。
- 實時性和可擴展性:在處理大量實時數據時,算法的效率和擴展性變得尤為重要。
在本章中,我們對文本分類的基礎進行了全面的介紹,從定義和目的到關鍵技術和挑戰,為深入理解文本分類的技術細節和實際應用打下了堅實的基礎。
三、關鍵技術和模型
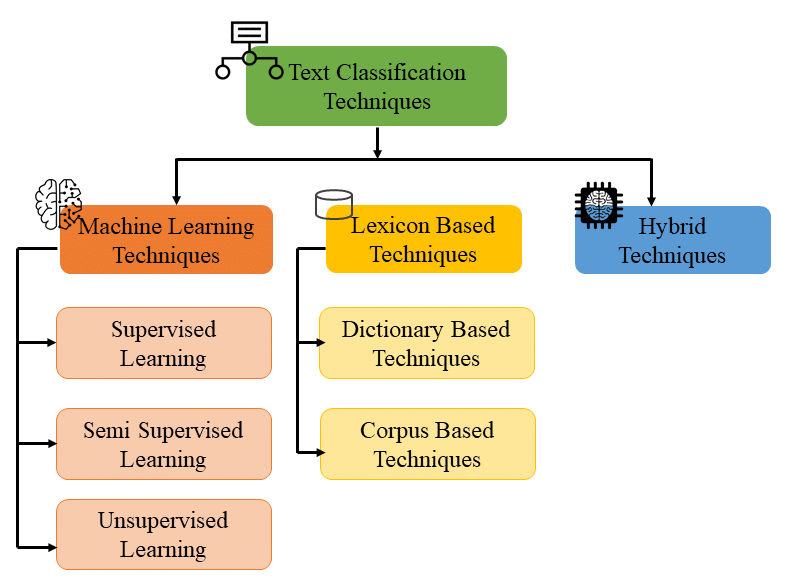
在深入探討文本分類的關鍵技術和模型時,我們會涉及從傳統的機器學習方法到現代的深度學習技術。每種技術都有其獨特之處,并在特定的應用場景下表現出色。在這一部分,我們將通過一些關鍵代碼段來展示這些模型的實現和應用。
傳統機器學習方法
樸素貝葉斯分類器
樸素貝葉斯是一種基于概率的簡單分類器,廣泛用于文本分類。以下是使用Python和scikit-learn實現的一個簡單例子:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline# 創建一個文本分類管道
text_clf_nb = Pipeline([('vect', CountVectorizer()),('clf', MultinomialNB()),
])# 示例數據
train_texts = ["This is a good book", "This is a bad movie"]
train_labels = [0, 1] # 0代表正面,1代表負面# 訓練模型
text_clf_nb.fit(train_texts, train_labels)
支持向量機(SVM)
支持向量機(SVM)是另一種常用的文本分類方法,特別適用于高維數據。以下是使用SVM的示例代碼:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline# 創建一個文本分類管道
text_clf_svm = Pipeline([('tfidf', TfidfVectorizer()),('clf', SVC(kernel='linear')),
])# 訓練模型
text_clf_svm.fit(train_texts, train_labels)
深度學習方法
卷積神經網絡(CNN)
卷積神經網絡(CNN)在圖像處理領域表現突出,也被成功應用于文本分類。以下是使用PyTorch實現文本分類的CNN模型的簡單例子:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass TextCNN(nn.Module):def __init__(self, vocab_size, embed_dim, num_classes):super(TextCNN, self).__init__()self.embedding = nn.Embedding(vocab_size, embed_dim)self.conv = nn.Conv2d(1, 100, (3, embed_dim))self.fc = nn.Linear(100, num_classes)def forward(self, x):x = self.embedding(x) # Embedding layerx = x.unsqueeze(1) # Add channel dimensionx = F.relu(self.conv(x)).squeeze(3) # Convolution layerx = F.max_pool1d(x, x.size(2)).squeeze(2) # Max poolingx = self.fc(x) # Fully connected layerreturn x# 示例網絡創建
vocab_size = 1000 # 詞匯表大小
embed_dim = 100 # 嵌入層維度
num_classes = 2 # 類別數
model = TextCNN(vocab_size, embed_dim, num_classes)
循環神經網絡(RNN)和LSTM
循環神經網絡(RNN)及其變體LSTM(長短期記憶網絡)在處理序列數據,如文本,方面非常有效。以下是使用PyTorch實現RNN的示例:
class TextRNN(nn.Module):def __init__(self, vocab_size, embed_dim, hidden_dim, num_classes):super(TextRNN, self).__init__()self.embedding = nn.Embedding(vocab_size, embed_dim)self.rnn = nn.RNN(embed_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, num_classes)def forward(self, x):x = self.embedding(x)x, _ = self.rnn(x) # RNN layerx = x[:, -1, :] # 獲取序列的最后一個時間步的輸出x = self.fc(x)return x# 示例網絡創建
hidden_dim = 128 # 隱藏層維度
model = TextRNN(vocab_size, embed_dim, hidden_dim, num_classes)
這些代碼段展示了不同文本分類技術的實現,從簡單的機器學習模型到復雜的深度學習網絡。在接下來的章節中,我們將進一步探討這些模型的應用案例和性能評估。
四、深度學習在文本分類中的應用
深度學習技術已成為文本分類領域的重要推動力,為處理自然語言帶來了前所未有的效果。在這一部分,我們將探討深度學習在文本分類中的幾種關鍵應用,并通過示例代碼展示這些模型的實現。
卷積神經網絡(CNN)的應用
CNN在文本分類中的應用,主要是利用其在提取局部特征方面的優勢。以下是用PyTorch實現的一個簡單的文本分類CNN模型:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass TextCNN(nn.Module):def __init__(self, vocab_size, embed_dim, num_classes):super(TextCNN, self).__init__()self.embedding = nn.Embedding(vocab_size, embed_dim)self.conv1 = nn.Conv2d(1, 100, (3, embed_dim))self.conv2 = nn.Conv2d(1, 100, (4, embed_dim))self.conv3 = nn.Conv2d(1, 100, (5, embed_dim))self.fc = nn.Linear(300, num_classes)def forward(self, x):x = self.embedding(x).unsqueeze(1) # 增加一個維度表示通道x1 = F.relu(self.conv1(x)).squeeze(3)x1 = F.max_pool1d(x1, x1.size(2)).squeeze(2)x2 = F.relu(self.conv2(x)).squeeze(3)x2 = F.max_pool1d(x2, x2.size(2)).squeeze(2)x3 = F.relu(self.conv3(x)).squeeze(3)x3 = F.max_pool1d(x3, x3.size(2)).squeeze(2)x = torch.cat((x1, x2, x3), 1) # 合并特征x = self.fc(x)return x# 示例網絡創建
vocab_size = 1000
embed_dim = 100
num_classes = 2
model = TextCNN(vocab_size, embed_dim, num_classes)
循環神經網絡(RNN)和LSTM
RNN和LSTM在處理文本序列時表現出色,特別是在理解長文本和上下文信息方面。以下是使用PyTorch實現的LSTM模型:
class TextLSTM(nn.Module):def __init__(self, vocab_size, embed_dim, hidden_dim, num_classes):super(TextLSTM, self).__init__()self.embedding = nn.Embedding(vocab_size, embed_dim)self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, num_classes)def forward(self, x):x = self.embedding(x)x, _ = self.lstm(x) # LSTM layerx = x[:, -1, :] # 獲取序列最后一個時間步的輸出x = self.fc(x)return x# 示例網絡創建
hidden_dim = 128
model = TextLSTM(vocab_size, embed_dim, hidden_dim, num_classes)
Transformer和BERT
Transformer模型,特別是BERT(Bidirectional Encoder Representations from Transformers),已經成為NLP領域的一個重要里程碑。BERT通過預訓練和微調的方式,在多種文本分類任務上取得了革命性的進展。以下是使用Hugging Face的Transformers庫來加載預訓練的BERT模型并進行微調的代碼:
from transformers import BertTokenizer, BertForSequenceClassification
import torch# 加載預訓練模型和分詞器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=num_classes)# 示例文本
texts = ["This is a good book", "This is a bad movie"]
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")# 微調模型
outputs = model(**inputs)
在這一章節中,我們展示了深度學習在文本分類中的幾種關鍵應用,包括CNN、RNN、LSTM和Transformer模型。這些模型的代碼實現為我們提供了一個實際操作的視角,幫助我們理解它們在文本分類任務中的作用和效果。
五、PyTorch實戰:文本分類
在這一章節中,我們將通過一個具體的例子,展示如何使用PyTorch框架實現文本分類任務。我們將構建一個簡單的深度學習模型,用于區分文本的情感傾向,即將文本分類為正面或負面。
場景描述
我們的目標是創建一個文本分類模型,能夠根據用戶評論的內容,自動判斷其為正面或負面評價。這種類型的模型在各種在線平臺,如電子商務網站、電影評價網站中都有廣泛應用。
輸入和輸出
- 輸入:用戶的文本評論。
- 輸出:二元分類結果,即正面(positive)或負面(negative)。
處理過程
1. 數據預處理
首先,我們需要對文本數據進行預處理,包括分詞、去除停用詞、轉換為小寫等,然后將文本轉換為數字表示(詞嵌入)。
2. 構建模型
我們將使用一個基于LSTM的神經網絡模型,它能有效地處理文本數據的序列特性。
3. 訓練模型
使用標記好的數據集來訓練我們的模型,通過調整參數優化模型性能。
4. 評估模型
在獨立的測試集上評估模型性能,確保其準確性和泛化能力。
完整的PyTorch實現代碼
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import torch.nn.functional as F# 示例數據集
class TextDataset(Dataset):def __init__(self, texts, labels):self.texts = textsself.labels = labelsdef __len__(self):return len(self.texts)def __getitem__(self, idx):return self.texts[idx], self.labels[idx]# 文本分類模型
class TextClassifier(nn.Module):def __init__(self, vocab_size, embed_dim, hidden_dim, num_classes):super(TextClassifier, self).__init__()self.embedding = nn.Embedding(vocab_size, embed_dim)self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, num_classes)def forward(self, x):x = self.embedding(x)x, _ = self.lstm(x)x = x[:, -1, :]x = self.fc(x)return x# 參數設置
vocab_size = 10000 # 詞匯表大小
embed_dim = 100 # 嵌入維度
hidden_dim = 128 # LSTM隱藏層維度
num_classes = 2 # 類別數(正面/負面)
batch_size = 64 # 批處理大小
learning_rate = 0.001 # 學習率# 數據準備
train_dataset = TextDataset([...], [...]) # 訓練數據集
test_dataset = TextDataset([...], [...]) # 測試數據集train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 初始化模型
model = TextClassifier(vocab_size, embed_dim, hidden_dim, num_classes)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)# 訓練過程
for epoch in range(num_epochs):for texts, labels in train_loader:outputs = model(texts)loss = F.cross_entropy(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()# 測試過程
correct = 0
total = 0
with torch.no_grad():for texts, labels in test_loader:outputs = model(texts)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'Accuracy of the model on the test texts: {100 * correct / total}%')
六、總結
在本文中,我們對文本分類技術進行了全面的探討,從其基本原理到高級應用,從傳統機器學習方法到最新的深度學習技術。我們的目的是為讀者提供一個從基礎到前沿的知識架構,幫助他們深入理解文本分類在人工智能領域的重要地位和發展趨勢。
-
技術融合的重要性:文本分類的進步不僅僅源于單一技術的突破,而是多種技術的融合與創新。例如,深度學習的興起給傳統的文本分類方法帶來了新的生命力,而最新的模型如Transformer則是自然語言處理領域的一個重大革命。
-
數據的核心作用:無論技術多么先進,高質量的數據始終是文本分類成功的關鍵。數據的準備、預處理和增強對于構建高效、準確的模型至關重要。
-
模型的可解釋性與道德責任:隨著文本分類技術的廣泛應用,模型的可解釋性和道德責任成為了不可忽視的話題。如何確保模型的決策公平、透明,并考慮到潛在的倫理影響,是我們未來需要深入探討的問題。
-
持續的技術革新:文本分類領域持續經歷著快速的技術革新。從最初的基于規則的系統,到現在的基于深度學習的模型,技術的進步推動了文本分類應用的邊界不斷擴展。
-
實踐與理論的結合:理論知識和實際應用的結合是理解和掌握文本分類技術的關鍵。通過實戰案例,我們能更深刻地理解理論,并在實際問題中找到合適的解決方案。
在文本分類的未來發展中,我們預計將看到更多的技術創新和應用探索。這不僅會推動人工智能領域的進步,也將在更廣泛的領域產生深遠的影響。我們期待看到這些技術如何在不同的行業中發揮作用,同時也關注它們如何更好地服務于社會和個人。
關注TechLead,分享AI全維度知識。作者擁有10+年互聯網服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智能實驗室成員,阿里云認證的資深架構師,項目管理專業人士,上億營收AI產品研發負責人。
)












)





