文章目錄
- 摘要
- 引言
- 算法
- 架構
- 結構
- 損失函數
- 實驗
- 數據集
- 評估
- SOTA比較
- 模型是否過擬合到修復區域
- 泛化到真實圖片
- 消融實驗
- 討論及結論
- 限制
- 參考文獻
摘要
作者調研自動放置目標到背景進行圖像合成的問題。提供背景圖、分割的目標,訓練模型預測合理放置信息(位置及尺寸)。當前工作主要是生成候選框或者使用滑窗搜索,但是不能在背景圖中建模局部信息。本文通過transformer學習目標特征與所有局部背景特征之間相關性。稀疏對比損失用于進一步訓練模型。通過網絡前向生成3D heatmap表明所有合理位置/尺度組合。訓練時可以使用具體標注也可使用現有inpaint模型,已超過SOTA方法。用戶研究表明訓練的模型可泛化到真實圖片。
引言
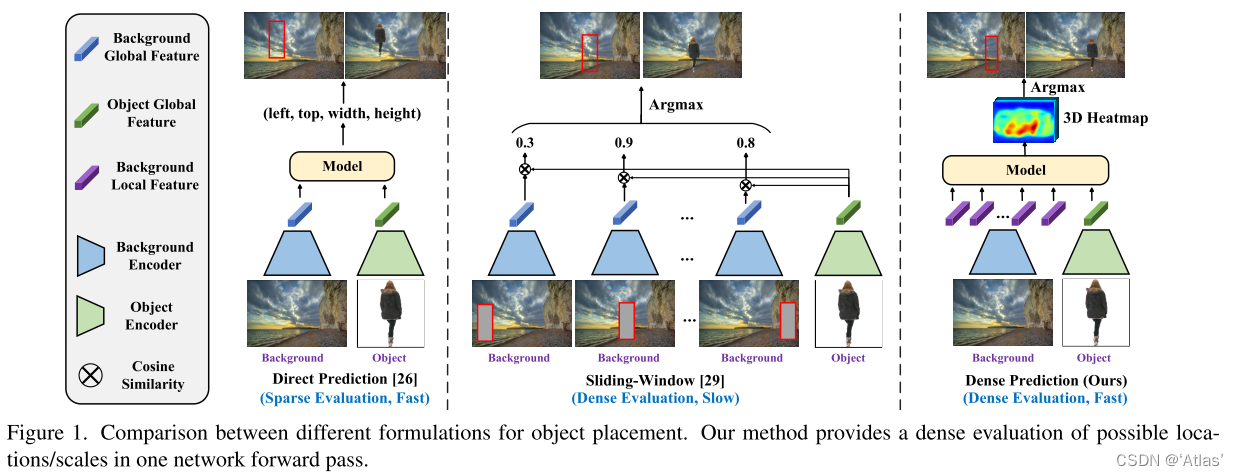
如圖1,現有方法【26】直接預測多個變換或邊界框,表明提供目標的位置和尺度,但僅推薦top,不提供其他可能位置及尺度。【29】使用檢索模型評估給定位置的合理性,并以滑動窗口的方式評估位置和尺度的網格,這導致推理速度慢。
本文作者提出的TopNet,將目標放置轉化為稠密點預測問題:通過一次網絡前向生成包含位置、尺度的稠密網格評估。之前方法僅在全局層級結合前景及背景,而TopNet學習全局前景特征與局部背景特征之間相關性,可高效評估所有可能放置位置。
作者訓練TopNet時僅提供一個邊界框,因此使用稀疏對比損失,真值位置/尺寸有一個相對高的得分,同時最小化其他組合及比真值得分高的組合,通過在預測的3D熱度圖上尋找局部最大值生成候選邊界框位置。
本文貢獻:
1、一種新穎的基于transformer的結構建模目標圖與來自背景圖的局部信息之間相關關系;
2、稀疏對比損失訓練稠密預測網絡;
3、在inpaint數據集和標定數據集充分實驗驗證達到SOTA
算法
架構
提供一張背景 I b I_b Ib?及前景 I o I_o Io?,模型預測的3D熱度圖 H H H, c = 16 c=16 c=16,表示尺度值s,0.15-0.9,間隔0.05,每個空間位置與放置邊界框的中心有關。
推理時,首先對 H H H歸一化,尋找top-1或top-k候選框。
結構
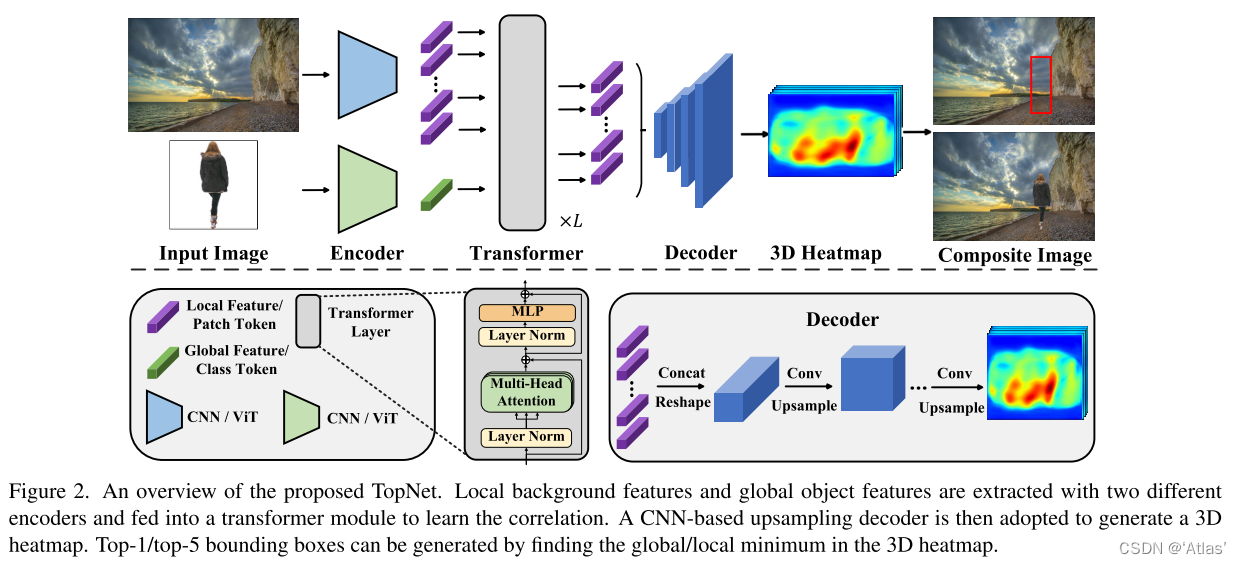
如圖2,使用兩個編碼器學習背景和目標特征,為確定特定位置的目標尺寸是否合適,背景圖中局部信息可提供細節信息,因此保留來自背景encoder中最后一個卷積層或transformer層的局部特征/token;對于前景相對簡單,保留全局特征。
使用多層transformer學習目標全局特征與背景局部特征之間相關性,class token替換為目標全局特征,最后一層所有patch token送入上采樣decoder;對于transformer降采樣后的特征進行concat及reshape,而后經過4個卷積層進行上采樣。
損失函數
通過mask原始目標后進行修復,生成純背景圖,從而構造訓練集。損失函數第一項Lcon如式1,
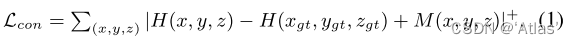
真值處得分最大,其中對于真值附近的點,M為0,其余位置為0.1;損失函數第二項Lrange,如式2,
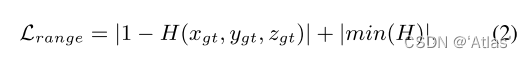
鼓勵H的最低分趨近于0,防止謀學位置預測得分高。整體損失函數L=Lcon+Lrange
實驗
數據集

Pixabay:使用LAMA進行目標擦除,對于圖中少于3個目標的圖片,額外增加一個mask,如圖4,防止模型過擬合到修復的物體。訓練集367, 384對,測試集41, 166
OPA:訓練集21, 350,測試集3, 566。
評估
Top-k IOU:top k個候選框與真值框iou的最大值
Normalized Score:熱度圖歸一化后,在真值處的得分應該相對高,因此計算NS均值以及NS高于一定閾值的百分比。
SOTA比較
Regression表示直接預測真值框;
?Retrieval表示通過檢索尋找合理位置;
Classifier表示通過分類器預測合成圖是否合理,為檢索方案的進一步擴充;
PlaceNet表示通過對抗訓練預測框是否合理。
表1展示top-5 IOU評估結果,該方法遠超過現有方法,同時速度也比較快;
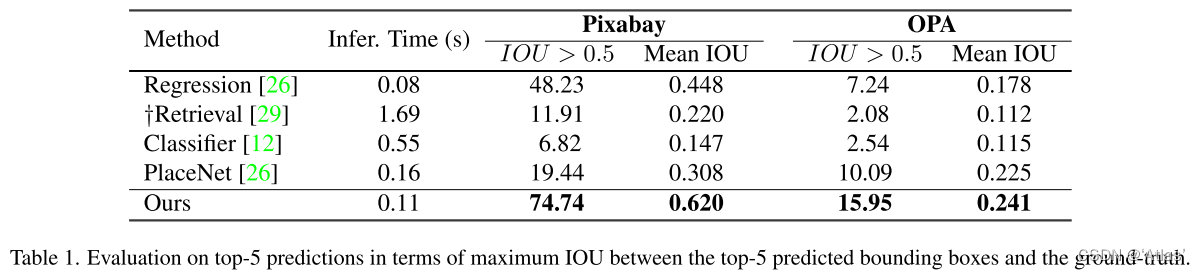
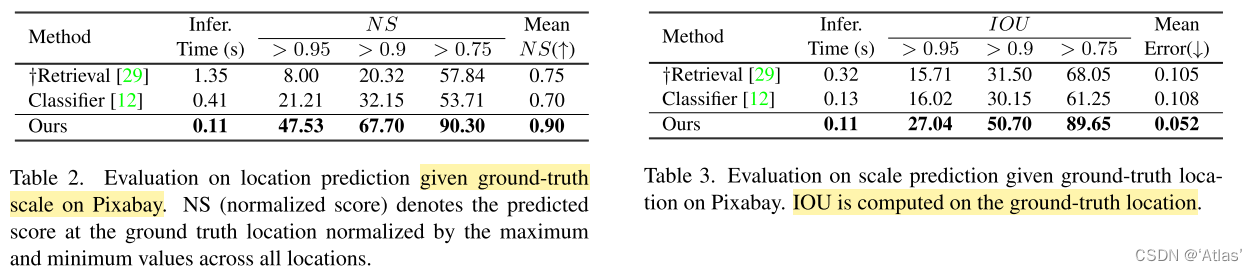
表2、表3表示對應真值位置NS結果及iou結果;
模型是否過擬合到修復區域
圖5表明模型未過擬合到LAMA修復區域。

泛化到真實圖片
圖6展示幾個有挑戰性目標放入背景示例,本文所提方法效果更出色;

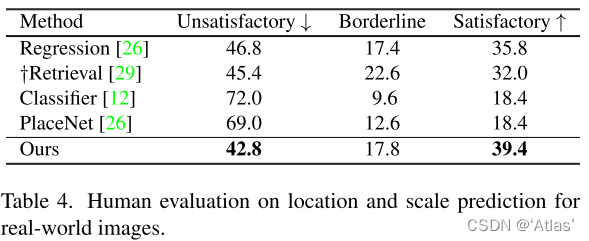
表4展示本文方法生成圖片滿意度更高;
消融實驗
表5展示稀疏對比損失性能提升明顯;

表6表示Local Atten效果最佳。

Global Only表示concat全局背景及前景特征;
Local Concat表示concat全局目標特征及每個局部背景特征;
Local Atten表示通過transformer結合全局前景特征及局部背景特征
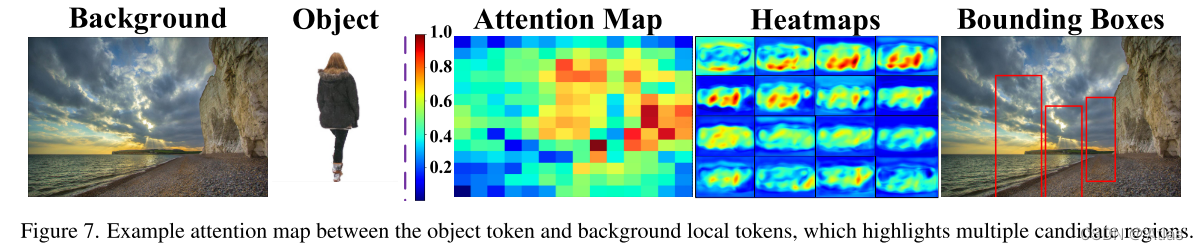
圖7為可視化展示前景token與局部背景token之間attention;16個熱度圖展示不同尺度目標推薦不同位置;
討論及結論
TopNet通過transformer結合目標特征及局部背景特征,預測目標尺度及放置位置,超越現有SOTA方法,并且在真實圖片具有泛化性。
限制
- 未考慮光照、陰影、遮擋等信息;
- 依賴于修復網絡構建數據集,與真實圖存gap
參考文獻
[26] Lingzhi Zhang, Tarmily Wen, Jie Min, Jiancong Wang, David Han, and Jianbo Shi. Learning object placement by in- painting for compositional data augmentation. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow,UK, August 23–28, 2020, Proceedings, Part XIII 16, pages 566–581. Springer, 2020. 1, 2, 6, 7
[29] Sijie Zhu, Zhe Lin, Scott Cohen, Jason Kuen, Zhifei Zhang, and Chen Chen. Gala: Toward geometry-and- lighting-aware object search for compositing. arXiv preprint arXiv:2204.00125, 2022. 1, 2, 5, 6, 7




Mysql中索引、觸發器、存儲過程、存儲函數的概念、作用,以及如何使用索引、存儲過程,代碼操作演示)








)





