圖深度學習(Graph Deep Learning) 多年來一直在加速發展。許多現實生活問題使GDL成為萬能工具:在社交媒體、藥物發現、芯片植入、預測、生物信息學等方面都顯示出了很大的前景。
本文將流行的圖神經網絡及其數學細微差別的進行詳細的梳理和解釋,圖深度學習背后的思想是學習具有節點和邊的圖的結構和空間特征,這些節點和邊表示實體及其交互。

圖
在我們進入圖神經網絡之前,讓我們先來探索一下計算機科學中的圖是什么。
圖G(V,E)是包含一組頂點(節點)i∈v和一組連接頂點i和j的邊eij∈E的數據結構,如果連接兩個節點i和j,則eij=1,否則eij=0。可以將連接信息存儲在鄰接矩陣A中:

我假設本文中的圖是無加權的(沒有邊權值或距離)和無向的(節點之間沒有方向關聯),并且假設這些圖是同質的(單一類型的節點和邊;相反的是“異質”)。
圖與常規數據的不同之處在于,它們具有神經網絡必須尊重的結構;不利用它就太浪費了。下面的圖是一個社交媒體圖的例子,節點是用戶,邊是他們的互動(比如關注/點贊/轉發)。

對于圖像來說,圖像本身就是一個圖!這是一種叫做“網格圖”的特殊變體,其中對于所有內部節點和角節點,來自節點的外向邊的數量是恒定的。在圖像網格圖中存在一些一致的結構,允許對其執行簡單的類似卷積的操作。
圖像可以被認為是一種特殊的圖,其中每個像素都是一個節點,并通過虛線與周圍的其他像素連接。當然,以這種方式查看圖像是不切實際的,因為這意味著需要一個非常大的圖。例如,32×32×3的一個簡單的CIFAR-10圖像會有3072個節點和1984條邊。對于224×224×3的較大ImageNet圖像,這些數字會更大。

與圖片相比,圖的不同的節點與其他節點的連接數量不同,并且沒有固定的結構,但是就是這種結構為圖增加了價值。
圖神經網絡
單個圖神經網絡(GNN)層有一堆步驟,在圖中的每個節點上會執行:
-
消息傳遞
-
聚合
-
更新
這些組成了對圖形進行學習的構建塊,GDL的創新都是在這3個步驟的進行的改變。
節點
節點表示一個實體或對象,如用戶或原子。因此節點具有所表示實體的一系列屬性。這些節點屬性形成了節點的特征(即“節點特征”或“節點嵌入”)。
通常,這些特征可以用Rd中的向量表示. 這個向量要么是潛維嵌入,要么是以每個條目都是實體的不同屬性的方式構造的。
例如,在社交媒體圖中,用戶節點具有可以用數字表示的年齡、性別、政治傾向、關系狀態等屬性。在分子圖中,原子節點可能具有化學性質,如對水的親和力、力、能量等,也可以用數字表示。
這些節點特征是GNN的輸入,每個節點i具有關聯的節點特征xi∈Rd和標簽yi(可以是連續的,也可以是離散的,就像單獨編碼一樣)。

邊
邊也可以有特征aij∈Rd '例如,在邊緣有意義的情況下(如原子之間的化學鍵)。我們可以把下面的分子想象成一個圖,其中原子是節點,鍵是邊。雖然原子節點本身有各自的特征向量,但邊可以有不同的邊特征,編碼不同類型的鍵(單鍵、雙鍵、三鍵)。不過為了簡單起見,在本文中我將省略邊的特性。

現在我們知道了如何在圖中表示節點和邊,讓我們從一個具有一堆節點(具有節點特征)和邊的簡單圖開始。
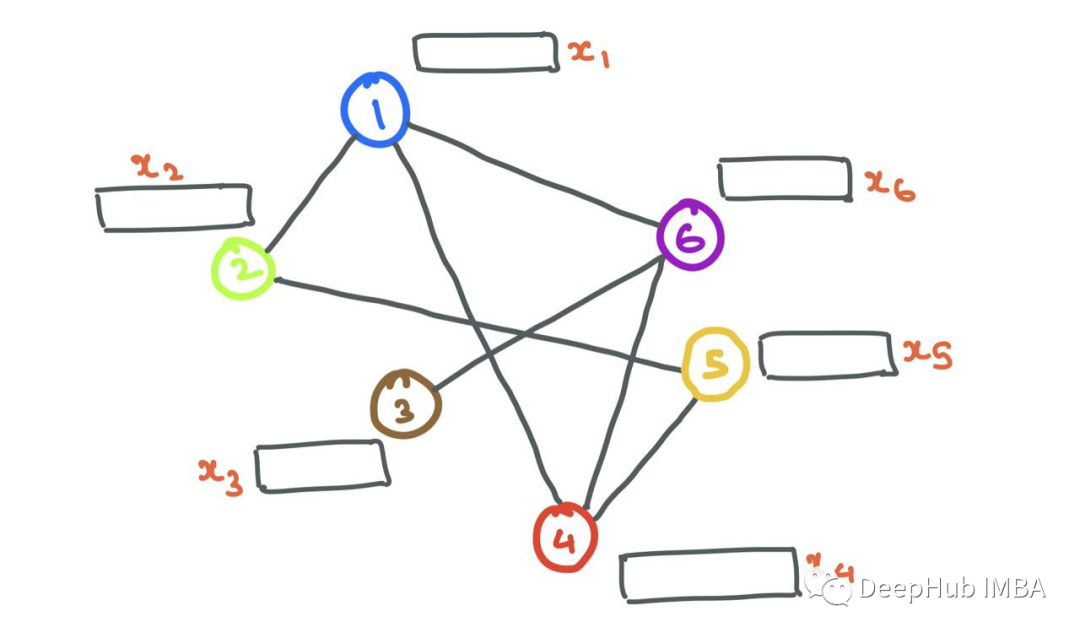
消息傳遞
gnn以其學習結構信息的能力而聞名。通常,具有相似特征或屬性的節點相互連接(比如在社交媒體中)。GNN利用學習特定節點如何以及為什么相互連接,GNN會查看節點的鄰域。
鄰居Ni,節點I的集合定義為通過邊與I相連的節點j的集合。形式為Ni={j: eij∈E}。

一個人被他所處的圈子所影響。類似地GNN可以通過查看其鄰居Ni中的節點i來了解很多關于節點i的信息。為了在源節點i和它的鄰居節點j之間實現這種信息共享,gnn進行消息傳遞。
對于GNN層,消息傳遞被定義為獲取鄰居的節點特征,轉換它們并將它們“傳遞”給源節點的過程。對于圖中的所有節點,并行地重復這個過程。這樣,在這一步結束時,所有的鄰域都將被檢查。
讓我們放大節點6并檢查鄰域N6={1,3,4}。我們取每個節點特征x1、x3和x4,用函數F對它們進行變換,函數F可以是一個簡單的神經網絡(MLP或RNN),也可以是仿射變換F(xj)=Wj?xj+b。簡單地說,“消息”是來自源節點的轉換后的節點特征。

F 可以是簡單的仿射變換或神經網絡。現在我們設F(xj)=Wj?xj為了方便計算 ? 表示簡單的矩陣乘法。
聚合
現在我們有了轉換后的消息{F(x1),F(x3),F(x4)}傳遞給節點6,下面就必須以某種方式聚合(“組合”)它們。有很多方法可以將它們結合起來。常用的聚合函數包括:

假設我們使用函數G來聚合鄰居的消息(使用sum、mean、max或min)。最終聚合的消息可以表示為:

更新
使用這些聚合消息,GNN層就要更新源節點i的特性。在這個更新步驟的最后,節點不僅應該知道自己,還應該知道它的鄰居。這是通過獲取節點i的特征向量并將其與聚合的消息相結合來操作的,一個簡單的加法或連接操作就可以解決這個問題。
使用加法

其中σ是一個激活函數(ReLU, ELU, Tanh), H是一個簡單的神經網絡(MLP)或仿射變換,K是另一個MLP,將加法的向量投影到另一個維度。
使用連接:

為了進一步抽象這個更新步驟,我們可以將K看作某個投影函數,它將消息和源節點嵌入一起轉換:

初始節點特征稱為xi,在經過第一GNN層后,我們將節點特征變為hi。假設我們有更多的GNN層,我們可以用hli表示節點特征,其中l是當前GNN層索引。同樣,顯然h0i=xi(即GNN的輸入)。
整合在一起
現在我們已經完成了消息傳遞、聚合和更新步驟,讓我們把它們放在一起,在單個節點i上形成單個GNN層:

這里我們使用求和聚合和一個簡單的前饋層作為函數F和H。設hi∈Rd, W1,W2?Rd ' ×d其中d '為嵌入維數。
使用鄰接矩陣
到目前為止,我們通過單個節點i的視角觀察了整個GNN正向傳遞,當給定整個鄰接矩陣a和X?RN×d中所有N=∥V∥節點特征時,知道如何實現GNN正向傳遞也很重要。
在 MLP 前向傳遞中,我們想要對特征向量 xi 中的項目進行加權。這可以看作是節點特征向量 xi∈Rd 和參數矩陣 W?Rd′×d 的點積,其中 d′ 是嵌入維度:

如果我們想對數據集中的所有樣本(矢量化)這樣做,我們只需將參數矩陣和特征矩陣相乘,就可以得到轉換后的節點特征(消息):

在gnn中,對于每個節點i,消息聚合操作包括獲取相鄰節點特征向量,轉換它們,并將它們相加(在和聚合的情況下)。
單行Ai對于Aij=1的每個指標j,我們知道節點i和j是相連的→eij∈E。例如,如果A2=[1,0,1,1,0],我們知道節點2與節點1、3和4連接。因此,當我們將A2與Z=XW相乘時,我們只考慮列1、3和4,而忽略列2和5:

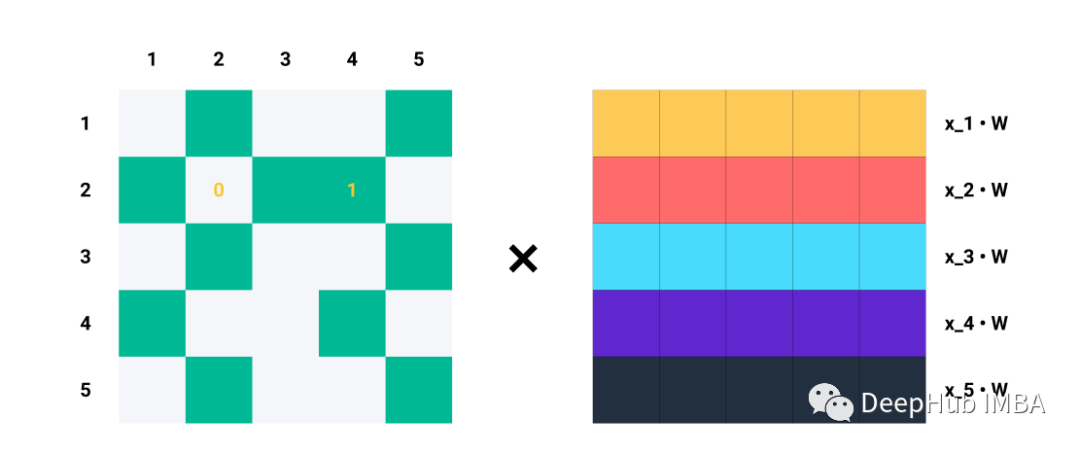

比如說A的第二行。

矩陣乘法就是A中的每一行與Z中的每一列的點積,這就是消息聚合的含義!!
獲取所有N的聚合消息,根據圖中節點之間的連接,將整個鄰接矩陣A與轉換后的節點特征進行矩陣乘法:

但是這里有一個小問題:觀察到聚合的消息沒有考慮節點i自己的特征向量(正如我們上面所做的那樣)。所以我們將自循環添加到A(每個節點i連接到自身)。
這意味著對角線的而數值需要進行修改,用一些線性代數,我們可以用單位矩陣來做這個!

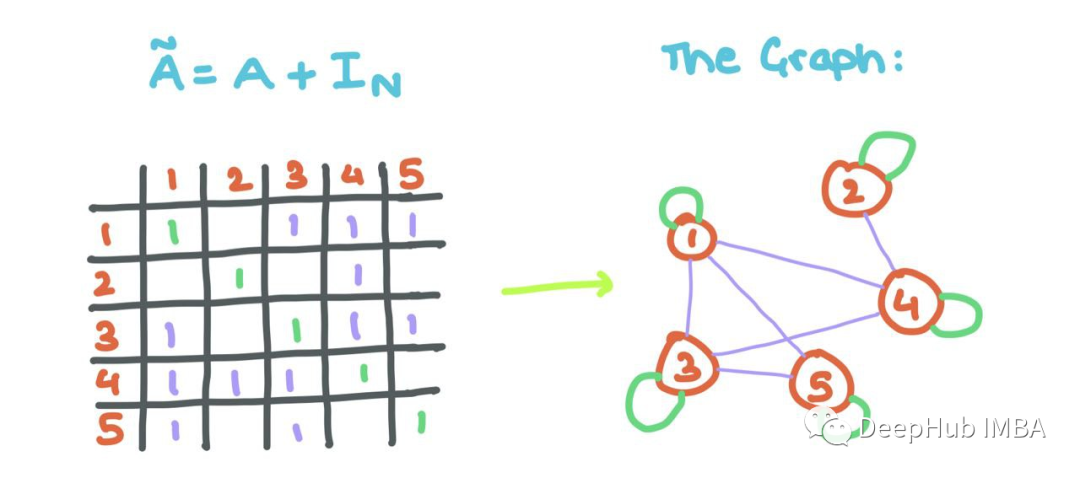
添加自循環可以允許GNN將源節點的特征與其鄰居節點的特征一起聚合!!
有了這些,你就可以用矩陣而不是單節點來實現GNN的傳遞。
?要執行平均值聚合(mean),我們可以簡單地將總和除以1,對于上面的例子,由于A2=[1,0,0,1,1]中有三個1,我們可以將∑j∈N2Wxj除以3,但是用gnn的鄰接矩陣公式來實現最大(max)和最小聚合(min)是不可能的。
GNN層堆疊
上面我們已經介紹了單個GNN層是如何工作的,那么我們如何使用這些層構建整個“網絡”呢?信息如何在層之間流動,GNN如何細化節點(和/或邊)的嵌入/表示?
-
第一個GNN層的輸入是節點特征X?RN×d。輸出是中間節點嵌入H1?RN×d1,其中d1是第一個嵌入維度。H1由h1i: 1→N∈Rd1組成。
-
H1是第二層的輸入。下一個輸出是H2?RN×d2,其中d2是第二層的嵌入維度。同理,H2由h2i: 1→N∈Rd2組成。
-
經過幾層之后,在輸出層L,輸出是HL?RN×dL。最后,HL由hLi: 1→N∈RdL構成。
這里的{d1,d2,…,dL}的選擇完全取決于我們,可以看作是GNN的超參數。把這些看作是為MLP層選擇單位(“神經元”的數量)。

節點特征/嵌入(“表示”)通過GNN傳遞。雖然結構保持不變,但節點表示在各個層中不斷變化。邊表示也將改變,但不會改變連接或方向。
HL也可以做一些事情:
我們可以沿著第一個軸(即∑Nk=1hLk)將其相加,得到RdL中的向量。這個向量是整個圖的最新維度表示。它可以用于圖形分類(例如:這是什么分子?)

我們可以在HL中連接向量(即?Nk=1hk,其中⊕是向量連接操作),并將其傳遞給一個Graph Autoencoder。當輸入圖有噪聲或損壞,而我們想要重建去噪圖時,就需要這個操作。
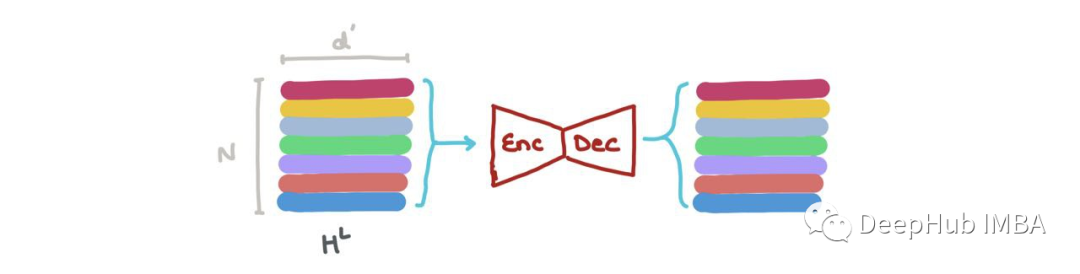
我們可以做節點分類→這個節點屬于什么類?在特定索引hLi (i:1→N)處嵌入的節點可以通過分類器(如MLP)分為K個類(例如:這是碳原子、氫原子還是氧原子?)

我們還可以進行鏈接預測→某個節點i和j之間是否存在鏈接?hLi和hLj的節點嵌入可以被輸入到另一個基于sigmoid的MLP中,該MLP輸出這些節點之間存在邊的概率。

這些就是GNN在不同的應用中所進行的操作,無論哪種方式,每個h1→N∈HL都可以被堆疊,并被視為一批樣本。我們可以很容易地將其視為批處理。
對于給定的節點i, GNN聚合的第l層具有節點i的l跳鄰域。節點看到它的近鄰,并深入到網絡中,它與鄰居的鄰居交互。
這就是為什么對于非常小、稀疏(很少邊)的圖,大量的GNN層通常會導致性能下降:因為節點嵌入都收斂到一個向量,因為每個節點都看到了許多跳之外的節點。對于小的圖,這是沒有任何作用的。
這也解釋了為什么大多數GNN論文在實驗中經常使用≤4層來防止網絡出現問題。
以節點分類為例訓練GNN
在訓練期間,對節點、邊或整個圖的預測可以使用損失函數(例如:交叉熵)與來自數據集的ground-truth標簽進行比較。也就是說gnn能夠使用反向傳播和梯度下降以端到端方式進行訓練。
訓練和測試數據
與常規ML一樣,圖數據也可以分為訓練和測試。這有兩種方法:
1、Transductive
訓練數據和測試數據都在同一個圖中。每個集合中的節點相互連接。只是在訓練期間,測試節點的標簽是隱藏的,而訓練節點的標簽是可見的。但所有節點的特征對于GNN都是可見的。
我們可以對所有節點進行二進制掩碼(如果一個訓練節點i連接到一個測試節點j,只需在鄰接矩陣中設置Aij=0)。

訓練節點和測試節點都是同一個圖的一部分。訓練節點暴露它們的特征和標簽,而測試節點只暴露它們的特征。測試標簽對模型隱藏。二進制掩碼需要告訴GNN什么是訓練節點,什么是測試節點。
2、Inductive
另外一種方法是單獨的訓練圖和測試圖。這類似于常規的ML,其中模型在訓練期間只看到特征和標簽,并且只看到用于測試的特征。訓練和測試在兩個獨立的圖上進行。這些測試圖分布在外,可以檢查訓練期間的泛化質量。

與常規ML一樣,訓練數據和測試數據是分開保存的。GNN只使用來自訓練節點的特征和標簽。這里不需要二進制掩碼來隱藏測試節點,因為它們來自不同的集合。
反向傳播和梯度下降
在訓練過程中,一旦我們向前通過GNN,我們就得到了最終的節點表示hLi∈HL, 為了以端到端方式訓練,可以做以下工作:
-
將每個hLi輸入MLP分類器,得到預測^yi
-
使用ground-truth yi和預測yi→J(yi,yi)計算損失
-
使用反向傳播來計算?J/?Wl,其中Wl是來自l層的參數矩陣
-
使用優化器更新GNN中每一層的參數Wl
-
(如果需要)還可以微調分類器(MLP)網絡的權重。

🥳這意味著gnn在消息傳遞和訓練方面都很容易并行。整個過程可以矢量化(如上所示),并在gpu上執行!!
流行圖神經網絡總結
上面我們介紹完了古神經網絡的基本流程,下面我們總結一下流行圖神經網絡,并將它們的方程和數學分為上面提到的3個GNN步驟。許多體系結構將消息傳遞和聚合步驟合并到一起執行的一個函數中,而不是顯式地一個接一個執行,但為了數學上的方便,我們將嘗試分解它們并將它們視為一個單一的操作!
1、消息傳遞神經網絡
https://arxiv.org/abs/1704.01212
消息傳遞神經網絡(MPNN)將正向傳播分解為具有消息函數Ml的消息傳遞階段和具有頂點更新函數Ul的讀出階段
MPNN將消息傳遞和聚合步驟合并到單個消息傳遞階段:

讀取階段是更新步驟:

其中ml+1v是聚合的消息,hl+1v是更新的節點嵌入。這與我上面提到的過程非常相似。消息函數Ml是F和G的混合,函數Ul是k,其中eij表示可能的邊緣特征,也可以省略。

2、圖卷積
https://arxiv.org/abs/1609.02907
圖卷積網絡(GCN)論文以鄰接矩陣的形式研究整個圖。在鄰接矩陣中加入自連接,確保所有節點都與自己連接以得到~A。這確保在消息聚合期間考慮源節點的嵌入。合并的消息聚合和更新步驟如下所示:

其中Wl是一個可學習參數矩陣。這里將X改為H,以泛化任意層l上的節點特征,其中H0=X。
由于矩陣乘法的結合律(A(BC)=(AB)C),我們在哪個序列中乘矩陣并不重要(要么是~AHl先乘,然后是Wl后乘,要么是HlWl先乘,然后是~A)。作者Kipf和Welling進一步引入了度矩陣~D作為"renormalisation"的一種形式,以避免數值不穩定和爆炸/消失的梯度:

“renormalisation”是在增廣鄰接矩陣^A=D?12A~D?12上進行的。新的合并消息傳遞和更新步驟如下所示:

3、圖注意力網絡
https://arxiv.org/abs/1710.10903
聚合通常涉及在和、均值、最大值和最小值設置中平等對待所有鄰居。但是在大多數情況下,一些鄰居比其他鄰居更重要。圖注意力網絡(GAT)通過使用Vaswani等人(2017)的Self-Attention對源節點及其鄰居之間的邊緣進行加權來確保這一點。
邊權值αij如下。

這里的Wa∈R2d '和W?Rd ' ×d為學習參數,d '為嵌入維數,⊕是向量拼接運算。
雖然最初的消息傳遞步驟與MPNN/GCN相同,但合并的消息聚合和更新步驟是所有鄰居和節點本身的加權和:

邊緣重要性加權有助于了解鄰居對源節點的影響程度。與GCN一樣,添加了自循環,因此源節點可以將自己的表示形式考慮到未來的表示形式中。

4、GraphSAGE
https://arxiv.org/abs/1706.02216
GraphSAGE:Graph SAmple and AggreGatE。這是一個為大型、非常密集的圖形生成節點嵌入的模型。
這項工作在節點的鄰域上引入了學習聚合器。不像傳統的gat或GCNs考慮鄰居中的所有節點,GraphSAGE統一地對鄰居進行采樣,并對它們使用學習的聚合器。
假設我們在網絡(深度)中有L層,每一層L∈{1,…,L}查看一個更大的L跳鄰域w.r.t.源節點。然后在通過MLP的F和非線性σ傳遞之前,通過將節點嵌入與采樣消息連接來更新每個源節點。
對于某一層l
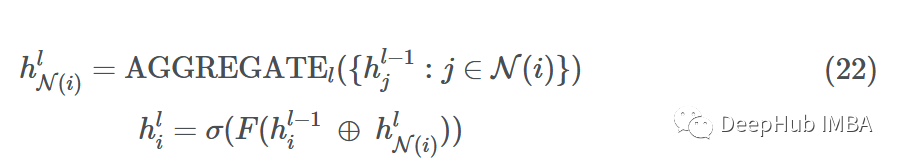
其中⊕是向量拼接運算,N(i)是返回所有鄰居的子集的統一抽樣函數。如果一個節點有5個鄰居{1,2,3,4,5},N(i)可能的輸出將是{1,4,5}或{2,5}。

Aggregator ?k=1從1-hop鄰域聚集采樣節點(彩色),而Aggregator k=2從2 -hop鄰域聚集采樣節點(彩色)
論文中用K和K表示層指數。但在本文中分別使用L和L來表示,這是為了和前面的內容保持一致性。此外,論文用v表示源節點i,用u表示鄰居節點j。
5、時間圖網絡
https://arxiv.org/abs/2006.10637
到目前為止所描述的網絡工作在靜態圖上。大多數實際情況都在動態圖上工作,其中節點和邊在一段時間內被添加、刪除或更新。時間圖網絡(TGN)致力于連續時間動態圖(CTDG),它可以表示為按時間順序排列的事件列表。
論文將事件分為兩種類型:節點級事件和交互事件。節點級事件涉及一個孤立的節點(例如:用戶更新他們的個人簡介),而交互事件涉及兩個可能連接也可能不連接的節點(例如:用戶a轉發/關注用戶B)。
TGN提供了一種模塊化的CTDG處理方法,包括以下組件:
-
消息傳遞函數→孤立節點或交互節點之間的消息傳遞(對于任何類型的事件)。
-
消息聚合函數→通過查看多個時間步長的時間鄰域,而不是在給定時間步長的局部鄰域,來使用GAT的聚合。
-
記憶更新→記憶(Memory)允許節點具有長期依賴關系,并表示節點在潛在(“壓縮”)空間中的歷史。這個模塊根據一段時間內發生的交互來更新節點的內存。
-
時間嵌入→一種表示節點的方法,也能捕捉到時間的本質。
-
鏈接預測→將事件中涉及的節點的時間嵌入通過一些神經網絡來計算邊緣概率(即,邊緣會在未來發生嗎?)。在訓練過程中,我們知道邊的存在,所以邊的標簽是1,所以需要訓練基于sigmoid的網絡來像往常一樣預測這個。

每當一個節點參與一個活動(節點更新或節點間交互)時,記憶就會更新。
對于批處理中的每個事件1和2,TGN為涉及該事件的所有節點生成消息。TGN聚合所有時間步長t的每個節點mi的消息;這被稱為節點i的時間鄰域。然后TGN使用聚合消息mi(t)來更新每個節點si(t)的記憶。

一旦所有節點的內存si(t)是最新的,它就用于計算批處理中特定交互中使用的所有節點的“臨時節點嵌入”zi(t)。然后將這些節點嵌入到MLP或神經網絡中,獲得每個事件發生的概率(使用Sigmoid激活)。這樣可以像往常一樣使用二進制交叉熵(BCE)計算損失。
總結
上面就是我們對圖神經網絡的數學總結,圖深度學習在處理具有類似網絡結構的問題時是一個很好的工具集。它們很容易理解,我們可以使用PyTorch Geometric、spectral、Deep Graph Library、Jraph(jax)以及TensorFlow-gnn來實現。GDL已經顯示出前景,并將繼續作為一個領域發展。

)


)

)











)
