redis的性能管理
redis的數據是緩存在內存當中的
系統巡檢:
硬件巡檢、數據庫、nginx、redis、docker、k8s
運維人員必須要關注的redis指標
在日常巡檢中需要經常查看這些指標使用情況
info memory
#查看redis使用內存的指標
used_memory:11285512
#數據占用的內存(單位是字節)
used_memory_rss:24285184
#向操作系統申請的內存(單位是字節)
used_memory_peak:23952088
#redis使用內存的峰值(單位是字節)內存碎片率:used_mem0ry_rss/used_memory
#系統已經分配給了redis,但是未能夠有效利用的內存如何查看內存碎片率?
內存碎片率:used_mem0ry_rss/used_memory
#系統已經分配給了redis,但是未能夠有效利用的內存redis-cli info memory | grep ratio
#查看內存碎片率allocator_frag_ratio:1.03
#分配器碎片比例。由redis主進程調度時產生的內存,比例越小越好,值越高,內存浪費越多。
allocator_rss_ratio:1.80
#表示分配器占用物理內存的比例,主進程調度過程中占用了多少物理內存
rss_overhead_ratio:1.13
#RSS是向系統申請的內存空間,redis占用物理空間額外的開銷比例。比例越低越好。redis實際占用的物理內存和向系統申請的內存越接近額外的開銷就越低
mem_fragmentation_ratio:2.16
#內存碎片的比例。值越低越好。表示內存的使用率越高如何來進行清理碎片?
自動清理碎片
vim /etc/redis/6379.conf
最后一行插入
activedefrag yes
#自動清理碎片
/etc/init.d/redis_6379.conf restart
#重啟redis服務手動清理碎片
redis-cli memory purge
#手動清理碎片設置redis的最大內存閾值
vim /etc/redis/6379.conf
567行
maxmemory 1gb
#一旦到達閾值會開始自動清理,開啟key的回收機制key的回收機制是什么?
就是回收鍵值對
key回收的策略
vim /etc/redis/6379.conf598行
maxmemory-policy volatile-lru
#使用redis內置的LRU算法。把已經設置了過期時間的鍵值對淘汰出去。移除最近最少使用的鍵值對(只是針對已經設置了過期時間的鍵值對)maxmemory-policy volatile-ttl
#在已經設置了過期時間的鍵值對中,挑選一個即將過期的鍵值對(針對的是有設置生命周期的鍵值對)。maxmemory-policy volatile-random
#在已經設置了過期時間的鍵值對中,挑選數據然后隨機淘汰一個鍵值對(對設置了過期時間的鍵值對進行隨機移除)allkeys-lru
#根據redis內置的lru算法,對所有的鍵值對進行淘汰。移除最少使用的鍵值對。(針對所有的鍵值對)allkeys-random
#在所有鍵值對中,任意選擇數據進行淘汰maxmemory-policy noeviction
#禁止對鍵值對回收(不刪除任何鍵值對,知道redis把內存塞滿,寫不下,報錯為止)工作用要么保證數據完整性使用maxmemory-policy noeviction 要么使用maxmemory-policy volatile-ttl挑選一個即將過期的鍵值對清除
在工作當中一定要給redis占用內存設置閾值否則會將整個系統內存占滿為止
redis的雪崩
緩存雪崩:大量的應用請求無法在redis緩存當中處理,請求會全部發送到后臺數據庫。數據庫并發能力并發能力本身就差,數據庫會很快崩潰
什么情況可能會導致雪崩出現?
1、 redis集群大面積故障
2、 redis緩存中,大量數據同時過期,大量的請求無法得到處理
3、 redis實例宕機
防止雪崩出現的方法
事前:高可用架構,防止整個緩存故障。主從復制和哨兵模式、redis集群
事中:在國內用得較多的方式:HySTRIX有三種方式:熔斷、降級、限流。可以使用這三個手段來降低雪崩發生之后的損失。確保數據庫不死即可,慢可以,但是不能沒有響應。
事后:redis數據備份的方式來恢復數據或使用快速緩存預熱的方式
redis的緩存擊穿
緩存擊穿主要是熱點數據緩存過期或者被刪除,多個請求并發訪問熱點數據。請求也是轉發到后臺數據庫了,導致數據庫的性能快速下降。
經常被請求的緩存數據最好設置為永不過期
redis緩存穿透
緩存中沒有數據,數據庫中也沒有對應數據,但是有用戶一直發起這個沒有的請求,而且請求的數據格式很大。
可能是黑客在利用漏洞攻擊,壓垮應用數據庫。
redis的集群架構
高可用方案:
1、 持久化
2、 高可用:主從復制、哨兵模式、集群
主從復制
主從復制是redis實現高可用的基礎,哨兵模式和集群都是在主從復制的基礎上實現高可用。
主從復制實現數據的多機備份,以及讀寫分離(主服務器負責寫,從服務器只能讀)
缺陷:故障無法自動恢復,需要人工干預。無法實現寫操作的負載均衡
主從復制的工作原理
1、 主節點(master)和從節點(slave)組成。數據的復制時單項的,只能從主節點到從節點。
主從復制節點最少要有三臺
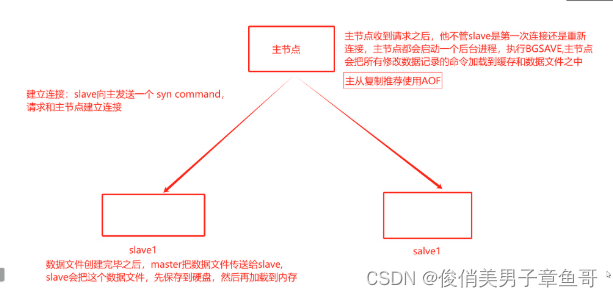
主從復制的數據流向和工作流程圖:
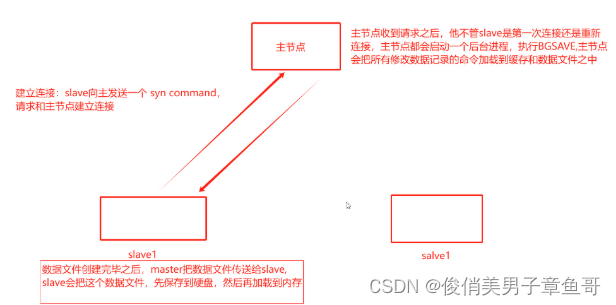
1、 從與主建立連接。從會發送一個syn command,請求和主建立連接
2、 主節點收到請求之后,不管slave是第一次連接還是重新連接。主節點都會啟動一個后臺進程。執行BGsave。
3、 主節點會把所有修改數據記錄的命令也加載到緩存和數據文件之中。
4、 數據文件創建完畢之后,是由主系欸但把數據文件傳送給從節點,從節點會把數據文件保存到硬盤當中后再加載到內存中去。
主從復制推薦使用AOF,通過AOF文件實現實時持久化,主從節點都開啟AOF持久化服務。從節點同步的就是aof文件。
主從復制工作流程圖:
主從復制實驗
實驗準備:
20.0.0.26 master
20.0.0.27 slave1
20.0.0.28 slave2
三臺機器都需要安裝redis服務做完后拍個快照systemctl stop firewalld
setenforce 0
#關閉三臺機器的防火墻和安全機制主節點:
vim /etc/redis/6379.conf
修改網段 0.0.0.0
daemonize yes
700行
開啟aof模式
/etc/init.d/redis_6379 restart從節點1:
vim /etc/redis/6379.conf
修改網段 0.0.0.0
288行
replicaof <masterip> <masterport>
replicaof 20.0.0.26 6379
#指向主的ip和端口
700行
開啟aof模式
/etc/init.d/redis_6379 restart
開啟了指向后從節點將變為只讀模式從節點2:
vim /etc/redis/6379.conf
修改網段 0.0.0.0
288行
replicaof <masterip> <masterport>
replicaof 20.0.0.26 6379
#指向主的ip和端口
700行
開啟aof模式
/etc/init.d/redis_6379 restart
開啟了指向后從節點將變為只讀模式主節點:
tail -f /var/log/redis_6379.log
#查看主節點日志,看是否指向成功驗證效果:
主從都登錄redis
主節點:
set test1 1
#創建一個鍵值對
主上創建成功后到兩臺從節點查看一下看是否可以查看到從節點:
set test2 2
#在從節點上測試是否為只讀模式
報錯,說明搭建成功從節點已經設置為只讀模式了實驗完成!redis-cli info replication
#查看主從配置信息停止一個從節點來測試。停機期間插入的數據,服務重啟后依舊可以同步哨兵模式
哨兵模式依賴于主從模式,先有主從再有哨兵
哨兵模式是在主從復制的基礎上實現主節點故障的自動切換
哨兵模式的工作原理
哨兵:是一個分布式系統。部署在每一個redis節點上用于在主從結構之間對每臺redis的服務進行監控。
哨兵模式的投票機制
主節點出現故障時,從節點通過投票的方式選擇一個新的master
哨兵模式也需要至少三個節點
哨兵模式的結構
哨兵節點和數據節點
哨兵節點:監控,不存儲數據
數據節點:主節點和從節點,都是數據節點
哨兵模式的工作機制
哨兵模式的架構和工作機制圖:
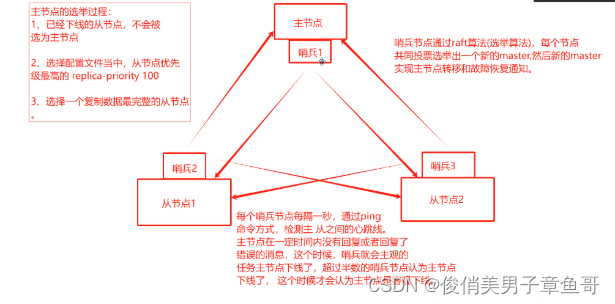
哨兵1節點會對應監控從節點1和從節點2
哨兵2節點會對應監控主節點和從節點2
哨兵3節點會監控主節點和從節點1
哨兵節點會互相監控架構內的其他節點主機
哨兵模式的投票機制:
1、 每個哨兵節點每隔1秒,通過ping命令的方式檢測主從之間的心跳線。
2、 當主節點在一定時間內沒有回復或者回復了錯誤的信息。哨兵會主觀的認為主節點下線了。
3、 當有超過半數的哨兵節點認為主節點下線了,才會認為主節點是客觀下線了
主節點選舉過程:
哨兵節點會通過redis自帶的raft算法(選舉算法),每個節點共同投票,選舉出一個新的master。
新的master來實現主節點的轉移和故障恢復通知
1、 已經下線的從節點,不會被選擇為主節點
2、 選擇配置文件當中,從節點優先級最高的 replica-priority 100
3、 選擇一個復制數據最完整的從節點
哨兵模式監控的是節點不是哨兵
故障恢復可能會優點延遲
最好是以復制數據最完整的從節點作為新的主節點
哨兵模式實驗
主節點:
cd redis-5.0.7
vim sentinel.conf
#哨兵模式的配置文件17行
protected-mode no
#解除注釋daemonize yes
#開啟后臺運行逃兵模式36行
logfile "/var/log/sentinel.log"
#指定日志文件的存放位置65行
dir"/var/lib/redis/6379"
#指定數據庫存放的位置85行
sentinel monitor mymaster 20.0.0.26 6379 2
#聲明主節點的IP和端口號.2代表至少要有2臺服務認為主已經下線才會進行主從切換。一般配置為主從服務器的一半113行
sentinel down-after-milliseconds mymaster 30000
#服務器宕機的最小時間。單位是毫秒。30秒之內如果主節點但沒有響應,主觀認為主下線了。時間可以改可以自定義146行
sentinel failover-timeout mymaster 180000
#服務器宕機的最大時間,180秒之內如果主節點但沒有響應,從節點開始投票,客觀認為主下線了。時間可以改可以自定義兩臺從節點配置和主節點配置一致即可三臺配置完成后需要先起主節點再起從節點三臺主機在redis的源碼包中啟動哨兵模式
redis-sentinel sentinel.conf &
#啟動哨兵模式。&表示后臺運行主節點:
redis-cli -p 26379 info Sentinel
#查看整個集群的哨兵情況查看主從信息:
tail -f /var/log/redis_6379.log
#查看主節點日志,查看主從信息模擬故障切換:
可能會有延遲不是立刻切換
ps-elf | grep redis
#查看主節點
kill -9 redis的主進程或者/etc/init.d/redis_6379 stop停止redis都可以測試測試新主是否可以正常插入數據
測試兩從是否可以數據同步
測試舊主機是否還有插入數據舊主失去寫的功能,新主增加寫的功能。從2的配置文件指向了新的主
而舊主的配置文件中指向自己的配置將會消失小模式用哨兵,大模式用集群
總結
運維人員日常巡檢中關注的指標
#查看redis使用內存的指標
used_memory:11285512
#數據占用的內存(單位是字節)
used_memory_rss:24285184
#向操作系統申請的內存(單位是字節)
used_memory_peak:23952088
#redis使用內存的峰值(單位是字節)
內存碎片:
內存碎片率:used_mem0ry_rss/used_memory
#系統已經分配給了redis,但是未能夠有效利用的內存redis-cli info memory | grep ratio
#查看內存碎片率allocator_frag_ratio:1.03
#分配器碎片比例。由redis主進程調度時產生的內存,比例越小越好,值越高,內存浪費越多。
allocator_rss_ratio:1.80
#表示分配器占用物理內存的比例,主進程調度過程中占用了多少物理內存
rss_overhead_ratio:1.13
#RSS是向系統申請的內存空間,redis占用物理空間額外的開銷比例。比例越低越好。redis實際占用的物理內存和向系統申請的內存越接近額外的開銷就越低
mem_fragmentation_ratio:2.16
#內存碎片的比例。值越低越好。表示內存的使用率越高如何清理碎片:
自動清理碎片
vim /etc/redis/6379.conf
最后一行插入
activedefrag yes
#自動清理碎片
/etc/init.d/redis_6379.conf restart
#重啟redis服務手動清理碎片
redis-cli memory purge
#手動清理碎片如何設置閾值:
vim /etc/redis/6379.conf567行maxmemory 1gb
#一旦到達閾值會開始自動清理,開啟key的回收機制工作用要么保證數據完整性使用maxmemory-policy noeviction 要么使用maxmemory-policy volatile-ttl挑選一個即將過期的鍵值對清除
在工作當中一定要給redis占用內存設置閾值否則會將整個系統內存占滿為止
redis的緩存擊穿:
緩存擊穿主要是熱點數據緩存過期或者被刪除,多個請求并發訪問熱點數據。請求也是轉發到后臺數據庫了,導致數據庫的性能快速下降。
經常被請求的緩存數據最好設置為永不過期
主從復制:
主從復制是redis實現高可用的基礎,哨兵模式和集群都是在主從復制的基礎上實現高可用。
主從復制實現數據的多機備份,以及讀寫分離(主服務器負責寫,從服務器只能讀)
缺陷:故障無法自動恢復,需要人工干預。無法實現寫操作的負載均衡
哨兵模式:
哨兵模式監控的是節點不是哨兵
故障恢復可能會優點延遲
最好是以復制數據最完整的從節點作為新的主節點
拓展
運維人員必須要關注的redis指標:
在日常巡檢中需要經常查看這些指標使用情況
info memory
#查看redis使用內存的指標
used_memory:11285512
#數據占用的內存(單位是字節)
used_memory_rss:24285184
#向操作系統申請的內存(單位是字節)
used_memory_peak:23952088
#redis使用內存的峰值(單位是字節)如何查看內存碎片率?
內存碎片率:used_mem0ry_rss/used_memory
#系統已經分配給了redis,但是未能夠有效利用的內存redis-cli info memory | grep ratio
#查看內存碎片率allocator_frag_ratio:1.03
#分配器碎片比例。由redis主進程調度時產生的內存,比例越小越好,值越高,內存浪費越多。
allocator_rss_ratio:1.80
#表示分配器占用物理內存的比例,主進程調度過程中占用了多少物理內存
rss_overhead_ratio:1.13
#RSS是向系統申請的內存空間,redis占用物理空間額外的開銷比例。比例越低越好。redis實際占用的物理內存和向系統申請的內存越接近額外的開銷就越低
mem_fragmentation_ratio:2.16
#內存碎片的比例。值越低越好。表示內存的使用率越高redis占用的內存效率問題如何解決?
1、 日常巡檢中,針對redis的占用情況做監控
2、 給redis設置一個占用系統內存的閾值,避免占用系統的全部內容
3、 內存碎片清理,分為手動和自動兩種模式
4、配置一個合適的key的回收機制。一般都是設置寫滿報錯的方式(maxmemory-policy noeviction),通過運維人員手動維護。或者挑選一個即將過期的鍵值對清除(maxmemory-policy volatile-ttl)。
redis的緩存擊穿
緩存擊穿主要是熱點數據緩存過期或者被刪除,多個請求并發訪問熱點數據。請求也是轉發到后臺數據庫了,導致數據庫的性能快速下降。
經常被請求的緩存數據最好設置為永不過期



















