在某客戶日志數據遷移到火山引擎使用 ELK 生態的案例中,由于客戶反饋之前 Logstash 經常發生數據丟失和收集性能較差的使用痛點,我們嘗試使用 Flink 替代了傳統的 Logstash 來作為日志數據解析、轉換以及寫入 ElasticSearch 的組件,得到了該客戶的認可,并且已經成功協助用戶遷移到火山。目前,Flink 已經支持該業務高峰期 1000+k/s 的數據寫入。
本文主要介紹 Logstash 的使用痛點以及遷移到 Flink 的優勢,探索在 ELK 生態中,Flink 替換 Logstash 的更多可能,推動用戶從 EL(Logstash)K 遷移到 EF(Flink)K。

Logstash 簡介
ELK 是一套開源的日志及數據監控和分析系統,主要是三個組件的簡稱:Elasticsearch, Logstash and Kibana,功能涵蓋了從日志收集、解析、查詢、分析、可視化等完整的解決方案。
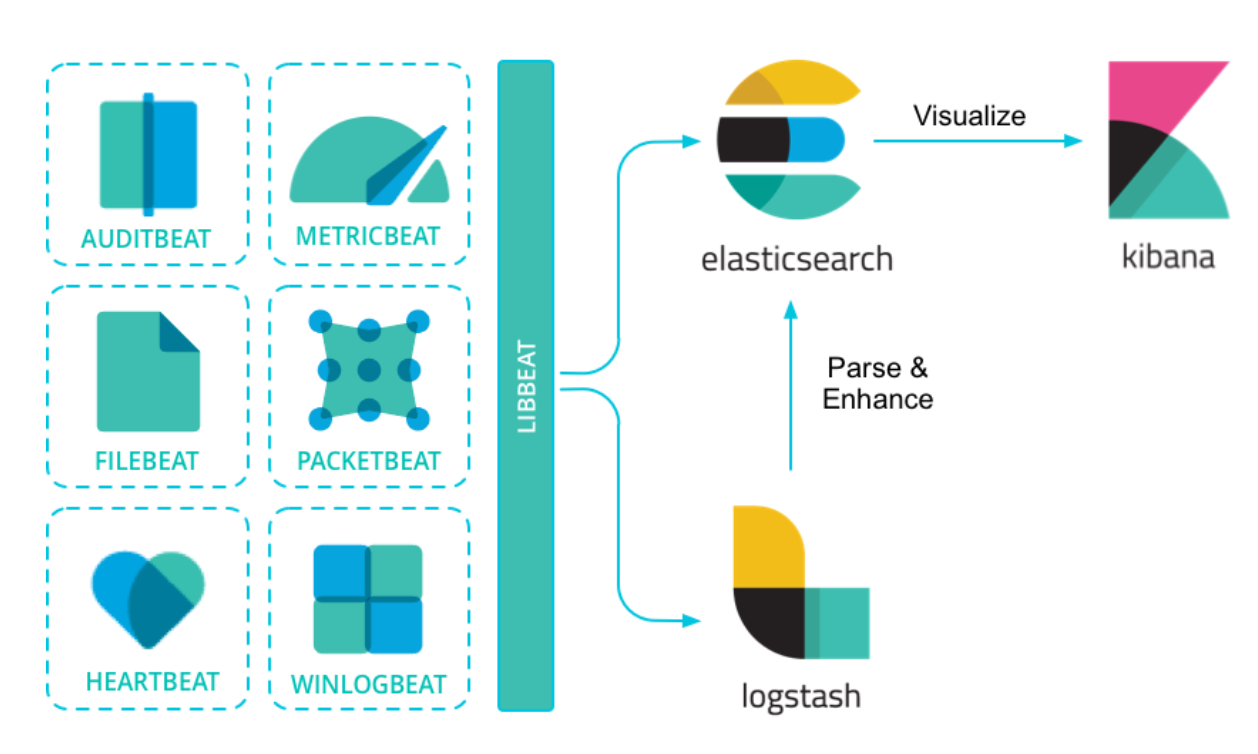
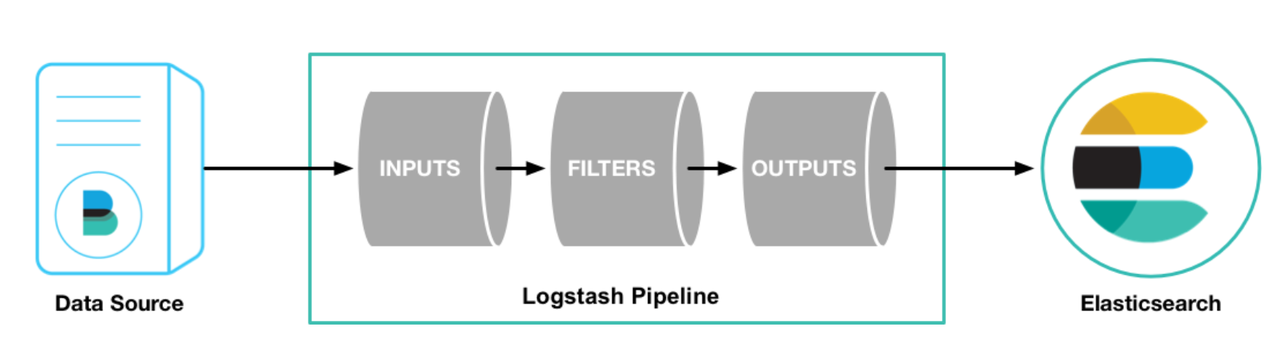
上圖描述了 ELK 里各組件的關系,基于 libbeat 框架的各種 beats 工具將日志及各種數據進行收集,可以直接寫入 ES,也可以先寫入到 Logstash 進行解析和處理再寫入到 ES。如下圖所示,Logstash 主要包括三個部分:
-
輸入插件:負責從各種不同的 source 讀取數據,如文件、beats、Kafka等;
-
過濾插件:負責按照指定的配置修改和處理數據,如 grok 插件可以從固定日志格式中提取對應信息,drop 插件可以丟失諸如 debug 日志等能力;
-
輸出插件:負責將結果數據輸出,如將處理后的日志數據寫入 ES 中。
Logstash 使用痛點
數據易丟失
Logstash 默認使用內存作為寫入數據的緩存,一旦發生重啟或者異常退出的時候,這部分數據就會發生丟失。雖然 Logstash 也提供了持久化隊列來解決這個問題,但是由于數據仍然是寫入機器磁盤中,當發生單機故障的時候,數據同樣也會丟失。同時,數據周期性的落盤也會對數據的處理性能帶來巨大的影響。
排查成本高
當日志數據格式不符合規范(如非標準 Json)造成丟失數據較多的情況時,需要在數據收集、數據解析、寫 ES 等全鏈路排查數據丟失的原因,一般需要查看機器日志,收集、處理節點較多的時候,排查成本也比較高。
除了日志數據本身不規范外,當由于其他原因導致數據不能正確處理的其他情況,比如寫 ES 各種異常,這部分數據也極易發生丟失,也需要查看日志進行跟蹤和定位。雖然 Logstash 單獨提供了死信隊列來處理這些情況,但是在這個鏈路丟失的數據仍然有排查的成本。
收集、解析性能差
Logstash 提供的各種插件基本都是用 Ruby 實現的,雖然 Logstash 本身也運行在 Java 的 JVM 上,并通過 JRuby 將各種插件也跑在 JVM 上,但是相比 Flink 100% Java 語言運行和執行效率會更低一些。
當開啟持久化隊列(為了保證數據盡可能少丟失),由于數據需要頻繁寫磁盤,Logstash 處理性能會進一步降低。同時,Logstash 處理性能較差也是業界的一大共識。
不支持資源動態擴縮容
由于 Logstash 本身的資源部署不支持動態擴縮容,會造成低峰期較大的資源浪費。在該客戶的案例中,業務高峰期的日志數據和活動期間的日志數據是在低峰期數據的 24 倍左右(高峰期 100w+ QPS,低峰期 50k QPS),且呈周期性變化。因此實際在業務低峰期,使用很少的資源就能夠保證日志數據的收集和解析,所以支持資源動態擴縮容是必須且必要的。
Flink 使用優勢
數據處理支持“at-least-once”語義
Flink 基于狀態引入分布式 checkpoint 機制,用于保證數據消費的“at-least-once”語義。其中狀態保存通過定期持久化到遠端可靠存儲(HDFS)來保證狀態不丟失。
需要說明的是,Flink 本身基于狀態是能夠做到嚴格意義上的“exactly-once”語義的,即消費和處理的不丟不重。如果 ES 支持了主鍵的配置,也就是相同主鍵寫入是冪等的情況下,則能在全鏈路做到“exactly-once”語義。
在該客戶的案例中,我們通過工具讀 Kafka 來統計寫入條數,跟實際 Flink 寫入 ES 的條數進行對比,證明了數據消費的“at-least-once”語義,解決了客戶在友商上使用 Logstash 經常發生數據丟失的痛點。
靈活的異常數據處理
對于 Kafka 中解析失敗的數據(比如格式為非 Json 的數據),在該客戶的案例中,我們支持了這部分的異常數據寫入獨立的 ES 索引,同時標識數據寫入原因(非標準 Json);對于寫 ES 異常失敗的數據,我們同樣會將這部分數據寫入獨立的 ES 索引,并且記錄寫 ES 失敗的原因,比如字段數超 1000,數據類型和模板定義的不一致等。
可以方便用戶對異常日志數據做治理,如該客戶推所有的上游業務日志標準 Json 化寫入 Kafka 等。相對的,在該客戶使用原友商的 Lostash 寫入 ES 的時候,這部分的數據丟失不僅不易排查(甚至不易知曉),而且也難以治理(丟失了寫 ES 失敗的原因)。
高吞吐、低延遲的處理性能
Flink 作為當前最熱的流式處理引擎,支持高吞吐、低延遲的處理日志數據,對數據處理能夠達到秒級的延遲且經過業內在其他 Kafka 數據更復雜處理場景的大量驗證,穩定而可靠。
資源自動擴縮容
在字節 Serverless Flink 中,我們也將支持資源隨著寫入 QPS 的動態調整,能夠節省較大的資源。目前,該功能已經在字節內部得到了實際驗證,在資源利用上取得了較大的收益。
更復雜的數據分析能力
相較于傳統的 ELK 鏈路,在 Logstash 中對日志數據進行簡單的數據格式匹配、內容替換等處理,Flink 還支持更強大的數據分析和處理,支持事件和業務處理時間,支持窗口計算、聚合、去重等。能對日志數據做更強大的數據處理和分析,將處理數據寫入 ES 后,能實現 OLAP 數據查詢和分析。
這部分數據處理和分析的能力也在字節內部得到了廣泛的應用,為業務帶來了很多實際的收益。
Flink vs Logstash 總結
對 Logstash 進行簡單介紹后,結合該客戶的案例,這里對比下 Flink 和 Logstash 的優劣:
| Logstash | Flink | 實際用戶案例 | |
| 數據一致性 | 數據消費和寫入均可能發生數據丟失,且開啟持久化隊列后對性能影響較大 | 基于狀態提供嚴格意義上的“at-least-once”語義 |
|
| 異常數據處理 | 需要單獨配置死信隊列和對應的處理私信隊列的邏輯,且處理失敗原因不易追蹤 | 提供數據解析失敗和寫 ES 失敗數據單獨往獨立索引寫入的能力,且同時記錄處理失敗原因,方便上游對日志進行治理 |
|
| 處理性能 | Ruby 語言本身執行效率低,且開啟持久化隊列后性能下降明顯 | 純 Java 執行語言,在大數據處理場景得到了廣泛的驗證,具有高吞吐、低延遲的特點 |
|
| 彈性擴縮容 | 無 | (未來)提供自動彈性擴縮容機制,在業務低峰期節省資源和成本 |
|
| 復雜數據分析 | 不支持,官方插件僅支持基本日志字段處理 | 提供基于處理時間和事件時間,窗口計算等強大的處理語義和邏輯 | 暫未使用 |
【火山引擎流式計算 Flink版】
火山引擎流式計算 Flink版是脫胎于字節跳動最佳實踐的新一代全托管、云原生實時計算平臺。一套代碼輕松搞定流批一體,助力企業將大數據平臺向云原生、實時化、智能化方向升級。
目前,流式計算 Flink版 新人首購專享活動正在進行中。注冊用戶首次購買 Flink 產品包年包月,即可享受首月4折優惠,歡迎咨詢體驗。

「了解更多產品信息」
參考資料
ELK Introduction — Log Consolidation with ELK Stack 1.2 documentation
Filebeat overview | Filebeat Reference [8.10] | Elastic
How Logstash Works | Logstash Reference [8.10] | Elastic
Persistent queues (PQ) | Logstash Reference [8.10] | Elastic
http://thomaslau.xyz/2019/08/14/2019-08-14-on_logstash_quiz1/
Mid-uh 對比(圖表)



)


5V/8A同步降壓恒流恒壓軟啟動帶EN功能只需極少外圍元件)
)

)




AD采集中的10種經典軟件濾波程序優缺點分析)




