1.研究背景與意義
隨著計算機視覺技術的不斷發展,單目標追蹤(Single Object Tracking, SOT)作為計算機視覺領域的一個重要研究方向,已經在許多實際應用中得到了廣泛的應用。單目標追蹤系統可以通過分析視頻序列中的目標運動,實時地跟蹤目標的位置和形狀變化,從而在許多領域中發揮重要作用,如智能監控、交通管理、無人駕駛等。
然而,由于目標在視頻序列中的外觀變化、遮擋、光照變化等因素的影響,單目標追蹤任務仍然面臨許多挑戰。為了解決這些問題,研究者們提出了許多不同的方法和算法。其中,基于深度學習的方法在單目標追蹤任務中取得了顯著的進展。
SiamFC(Siamese Fully Convolutional Networks)是一種基于孿生網絡的單目標追蹤方法,它通過將目標和背景分別編碼為兩個特征圖,并通過計算它們之間的相似度來實現目標的跟蹤。然而,SiamFC在處理復雜場景和目標變化時仍然存在一些問題,如目標遮擋、光照變化等。
為了進一步提高SiamFC的性能,許多研究者提出了各種改進方法。其中,圖注意力單元(Graph Attention Unit)是一種有效的注意力機制,可以在圖結構數據上學習目標的相關性和重要性。將圖注意力單元引入SiamFC模型中,可以提高模型對目標的關注度,從而提高單目標追蹤的準確性和魯棒性。
因此,本研究的主要目標是基于圖注意力單元的改進SiamFC++的單目標追蹤系統。通過引入圖注意力單元,我們希望能夠提高SiamFC模型在復雜場景和目標變化下的追蹤性能。具體來說,我們將設計一種新的網絡結構,將圖注意力單元嵌入到SiamFC模型中,以提高模型對目標的關注度和區分度。同時,我們還將探索不同的注意力機制和損失函數,以進一步提高模型的性能。
本研究的意義主要體現在以下幾個方面:
-
提高單目標追蹤的準確性和魯棒性:通過引入圖注意力單元,我們希望能夠提高SiamFC模型在復雜場景和目標變化下的追蹤性能。這將有助于提高單目標追蹤系統在實際應用中的準確性和魯棒性。
-
探索圖注意力單元在單目標追蹤中的應用:圖注意力單元是一種有效的注意力機制,可以在圖結構數據上學習目標的相關性和重要性。通過將圖注意力單元引入SiamFC模型中,我們可以探索其在單目標追蹤任務中的應用,為后續的研究提供新的思路和方法。
-
推動深度學習在單目標追蹤中的發展:深度學習在計算機視覺領域取得了巨大的成功,但在單目標追蹤任務中仍然存在一些挑戰。本研究將探索基于圖注意力單元的改進SiamFC++的單目標追蹤系統,有助于推動深度學習在單目標追蹤中的發展,提高其在實際應用中的效果和性能。
總之,本研究的目標是基于圖注意力單元的改進SiamFC++的單目標追蹤系統。通過引入圖注意力單元,我們希望能夠提高SiamFC模型在復雜場景和目標變化下的追蹤性能,推動深度學習在單目標追蹤中的發展,為實際應用提供更準確、魯棒的單目標追蹤解決方案。
2.圖片演示



3.視頻演示
基于圖注意力單元的改進SiamFC++的單目標追蹤系統_嗶哩嗶哩_bilibili
4.基于多特征融合的實時單目標追蹤算法
近年來,隨著計算機技術和光學成像技術的快速發展,計算機視覺引起學界的廣泛關注。日益增長的社會需求也對計算機視覺的現實應用提出了更高的要求。單目標追蹤作為計算機視覺的重要研究方向之一,在研究過程中除了追求準確性之外也要保證實時性,才能有效提高現實適用性。本章針對實時單目標追蹤問題,利用雙邊加權最小二乘模糊支持向量機,提出了基于多特征融合的實時追蹤算法FSCFI4]。在所提算法中,針對基于局部HOG特征的分類器,利用相關濾波框架克服計算復雜度高的矩陣求逆運算,并通過多基樣本擴充訓練數據和背景信息;針對基于全局顏色特征的分類器,利用獨熱編碼的數值化優點實現快速計算。在公開數據集上的實驗結果表明:與已有的高性能單目標追蹤算法相比,所提FSCF算法在形變、快速運動、運動模糊等多個方面均表現出了更優的追蹤性能。
本章的結構如下:在第3.1節中,首先簡要介紹了基于雙邊加權最小二乘模糊支持向量機的FST算法;在第3.2節和第3.3節中,分別詳細介紹了所提的基于局部HOG特征和全局顏色特征訓練的雙邊加權最小二乘模糊支持向量機;在第3.4節中,介紹了所提兩個分類器的融合方法;第3.5節是實驗設計及結果分析;第3.6節是全章工作的小結。
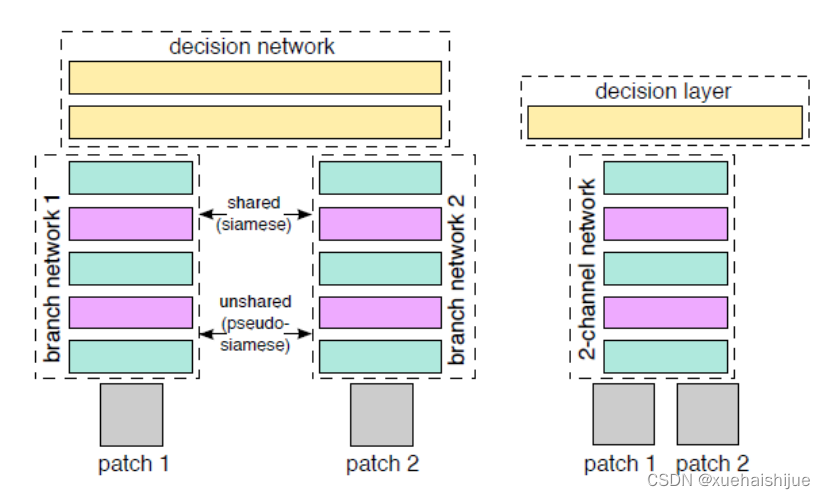
雙通道網絡
圖像相似度計算是計算機視覺和圖像分析中最基本的任務之一,在諸多視覺任務中發揮著尤為重要的作用[2-4]。在CVPR2015上,Zagoruyko等在一篇關于計算圖像相似度的論文中提出雙通道網絡(2-channel network),其核心思想在于把孿生網絡的雙分支合并在一起[5]。孿生網絡和雙通道網絡的網絡架構圖如圖所示。孿生網絡,又稱為雙分支網絡(2-branches network),其網絡結構是由兩個共享參數的分支組成。與孿生網絡不同,雙通道網絡的體系結構中沒有直接的特征描述符概念。Zagoruyko 等是把孿生網絡的雙分支合并在一起,將輸入的兩張單通道的灰色圖像合并為一張雙通道圖像,例如,原本輸入的patch1、patch2的維度均為(127,127,1),合成后的雙通道圖像維度則為(127,127,2)。然后,將雙通道圖像經過特征提取器得到特征向量。特征提取器在底層網絡中,由一系列卷積、ReLU和最大池化層組成。最后,將這部分的輸出作為輸入提供給線性決策層。該線性決策層僅由具有1個輸出神經元的全連接層組成,輸出值表示輸入圖像對的相似度。
5.核心代碼講解
5.1 Graph_Attention_Union.py
class Graph_Attention_Union(nn.Module):def __init__(self, in_channel, out_channel):super(Graph_Attention_Union, self).__init__()self.support = nn.Conv2d(in_channel, in_channel, 1, 1)self.query = nn.Conv2d(in_channel, in_channel, 1, 1)self.g = nn.Sequential(nn.Conv2d(in_channel, in_channel, 1, 1),nn.BatchNorm2d(in_channel),nn.ReLU(inplace=True),)self.fi = nn.Sequential(nn.Conv2d(in_channel * 2, out_channel, 1, 1),nn.BatchNorm2d(out_channel),nn.ReLU(inplace=True),)def forward(self, zf, xf):xf_trans = self.query(xf)zf_trans = self.support(zf)xf_g = self.g(xf)zf_g = self.g(zf)shape_x = xf_trans.shapeshape_z = zf_trans.shapezf_trans_plain = zf_trans.view(-1, shape_z[1], shape_z[2] * shape_z[3])zf_g_plain = zf_g.view(-1, shape_z[1], shape_z[2] * shape_z[3]).permute(0, 2, 1)xf_trans_plain = xf_trans.view(-1, shape_x[1], shape_x[2] * shape_x[3]).permute(0, 2, 1)similar = torch.matmul(xf_trans_plain, zf_trans_plain)similar = F.softmax(similar, dim=2)embedding = torch.matmul(similar, zf_g_plain).permute(0, 2, 1)embedding = embedding.view(-1, shape_x[1], shape_x[2], shape_x[3])output = torch.cat([embedding, xf_g], 1)output = self.fi(output)return output
這個程序文件是一個名為Graph_Attention_Union的神經網絡模型類。它繼承自nn.Module和ABC類,并包含了一些卷積層和線性變換層。
這個模型類的初始化函數接受兩個參數:in_channel和out_channel,分別表示輸入通道數和輸出通道數。在初始化函數中,定義了一些卷積層和線性變換層,用于對輸入數據進行線性變換和特征提取。
模型的前向傳播函數forward接受兩個輸入zf和xf,分別表示搜索區域節點和目標模板節點。在前向傳播過程中,首先對輸入數據進行線性變換,然后進行消息傳遞操作,計算相似度,并根據相似度計算嵌入特征。最后,將嵌入特征和xf的特征進行拼接,并通過一個卷積層得到最終的輸出。
整個模型的目的是實現圖注意力機制,用于處理圖結構數據的特征提取和聚合。
5.2 SiamFC_plus.py
class FeatureExtraction(nn.Module):def __init__(self):super(FeatureExtraction, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)self.conv3 = nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1)def forward(self, x):x = F.relu(self.conv1(x))x = F.relu(self.conv2(x))x = F.relu(self.conv3(x))return xclass SiamFCNet(nn.Module):def __init__(self):super(SiamFCNet, self).__init__()self.feature_extraction = FeatureExtraction()self.head_cls = nn.Conv2d(256, 1, kernel_size=1, stride=1)self.head_reg = nn.Conv2d(256, 4, kernel_size=1, stride=1)def forward(self, z, x):z_feat = self.feature_extraction(z)x_feat = self.feature_extraction(x)cls_score = F.conv2d(x_feat, z_feat)reg_score = F.conv2d(x_feat, z_feat)cls_score = self.head_cls(cls_score)reg_score = self.head_reg(reg_score)return cls_score, reg_scoreclass SiamFCLoss(nn.Module):def __init__(self):super(SiamFCLoss, self).__init__()def forward(self, cls_preds, reg_preds, cls_targets, reg_targets):cls_loss = F.binary_cross_entropy_with_logits(cls_preds, cls_targets)reg_loss = F.smooth_l1_loss(reg_preds, reg_targets)combined_loss = cls_loss + reg_lossreturn combined_loss
這個程序文件是一個用于目標跟蹤的Siamese網絡的實現。它包含了三個主要的模塊:特征提取模塊、Siamese網絡架構和損失函數。
特征提取模塊(FeatureExtraction)是一個簡單的卷積神經網絡,它包含了三個卷積層,用于從輸入圖像中提取特征。
Siamese網絡架構(SiamFCNet)包含了一個特征提取模塊和兩個頭部(Classification head和Regression head)。特征提取模塊用于提取目標和搜索圖像的特征,然后通過卷積運算計算出兩者之間的相關性。頭部部分分別用于分類和回歸任務,其中分類頭部輸出目標是否存在的概率,回歸頭部輸出目標的位置。
損失函數(SiamFCLoss)定義了Siamese網絡的訓練損失。它包含了兩個部分:分類損失和回歸損失。分類損失使用二元交叉熵損失函數,用于衡量分類結果的準確性。回歸損失使用平滑L1損失函數,用于衡量目標位置的準確性。最后,將分類損失和回歸損失相加得到綜合損失。
這個程序文件提供了一個基本的Siamese網絡實現,可以用于目標跟蹤任務的訓練和推理。
6.融合雙通道網絡和 SiamFC 的 SiamFC_plus 算法
雙通道網絡和孿生網絡最大的區別在于,孿生網絡是在最后的全連接層中才將兩張圖片的相關神經元關聯在一起,而雙通道網絡則是從最初就將輸入的兩張圖片聯系在一起。與孿生網絡相比,雙通道網絡共同處理了兩個patch,提供了更大的靈活性。通過實驗,Zagoruyko等證明了雙通道網絡不僅訓練速度更快,而且模型精度更高[5]。
在單目標追蹤的深度學習算法研究中,針對以SiamFC為代表的孿生網絡類算法離線訓練階段中在相似度度量學習問題上的瓶頸,考慮到雙通道網絡在度量學習上具有高效性和魯棒性,本節將雙通道網絡引入到單目標追蹤領域中,提出了一個融合雙通道網絡和 SiamFC的實時單目標追蹤算法SiamFC_plus。所提SiamFC_plus 算法的網絡框架如圖所示。

模型的輸入是一個目標原型圖像(Exemplar Image)和一個更大尺寸的搜索區域圖像(Search Image)。在搜索區域圖像上,與目標原型圖像大小一致的滑動窗口被視為實例,即為候選區域。目標和實例的坐標距離小于閾值時對應類標為正,否則為負。記目標原型圖像為z,搜索區域圖像為x。SiamFC_plus將目標追蹤看作是嵌入空間上的相似性學習問題,旨在學習一個相似性度量函數f(x, z),函數f通過比較目標原型圖像z和搜索區域圖像x,返回目標響應圖(Response Map) o:u cZ2。具體過程如下:首先,以z為濾波器,對x的各個顏色通道進行互相關操作,從而將這兩張尺寸不同的圖像融合在一起;再將這部分輸出直接作為輸入,傳送到CNN特征提取器中提取深度特征;然后,經由決策層輸出每個候選區域的得分構成目標響應圖o。該決策層是線性決策層,由一個不含有激活函數的全連接層組成。最后,將響應圖中分數最高的位置通過雙三次插值算法(Bicubic Interpolation)映射到搜索區域中,從而可確定目標的所在位置。
網絡訓練過程使用的是由目標原型圖像和搜索區域圖像組成的圖像對。SiamFC_plus 的損失函數為hinge損失函數加上L2正則化項,公式如式(4-1)所示。對比交叉嫡損失函數關注全局的所有樣本,hinge損失函數更關注類別難以區分的部分樣本,對學習有著更嚴格的要求。在同等的理想條件下,hinge損失函數能使模型具有更優的泛化性能。網絡參數包括每層網絡的權重和偏置,考慮到精確擬合偏置所需的數據量通常要比權重少許多,正則化偏置參數可能會導致明顯的欠擬合,故只對權重做正則懲罰,而不對偏置做正則懲罰。
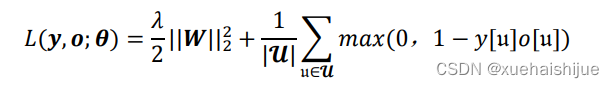
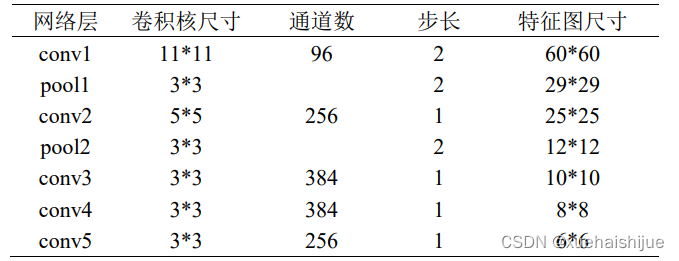
其中,a為正則化參數,0為網絡參數,y[u]∈{—1,+1}為單個原型-實例對在目標響應圖的每個位置u ∈ u上所對應的真實類標,o[u]為其對應的網絡輸出。網絡中所使用的特征提取器是全卷積神經網絡,該網絡應用于目標追蹤中只需要輸入搜索區域的圖像即可轉換為各個子窗口的相似度得分,避免在檢測時輸入多個候選區域并逐個計算。與SiamFC算法一致,網絡中的CNN特征提取器是基于Krizhevsky等提出的AlexNet 網絡所構建的特征提取器[8]。在預處理階段,將目標模板圖像的尺寸縮放為1271273,搜索區域圖像則縮放為2552553,以目標模板圖片為濾波器,對搜索區域圖片逐層進行互相關操作后所得的融合圖片尺寸為1291293。特征提取階段的具體網絡結構如表6-1所示。
表6-1 SiamFC plus算法特征提取階段的網絡結構
網絡參數0則通過隨機梯度下降法計算得出。
網絡的訓練過程由前向傳播過程和后向傳播過程組成。前向傳播過程是依照從前往后的順序,從輸入層開始經由隱藏層到達輸出層,逐層計算出每個網絡層的激活值。得到網絡輸出值后,將其代入損失函數中即可計算損失值。反向傳播過程則是依照從后往前的順序,從輸出層開始經由隱藏層到達輸入層,逐層計算出每個網絡層的誤差項,進而計算各層網絡參數的梯度,最后根據梯度值更新各層網絡參數。
7.SiamFC_plus 的前向傳播
網絡的前向傳播過程是按照從前往后的順序,從輸入層開始經由隱藏層到達輸出層,逐層計算出各個網絡層的激活值,最后得到網絡輸出值。網絡一共有L=9層,結合表6-1可知其中包括了1個輸入層,5個卷積層,2個池化層,1個全連接層。記上標表示樣本序號,下標表示網絡層號,星號*表示卷積運算,*a表示每個顏色通道上的互相關操作,W表示權重,b表示偏量,o表示ReLU激活函數,Pool表示重疊最大池化法。第1層是輸入層,輸入目標模板圖像z和搜索區域圖像x,以z為濾波器,在每個顏色通道上對x做互相關操作,其輸出為:

8.SiamFC_plus 的反向傳播
完成前向傳播過程后,開始進行網絡的反向傳播。反向傳播過程是按照從后往前的順序,從輸出層開始經由隱藏層到達輸入層,逐層計算出每個網絡層的誤差項,進而計算各層網絡參數的梯度,最后根據梯度值更新各層網絡參數。記下標表示層數,星號*表示卷積運算,〇表示Hadamard積(矩陣點乘),rot180表示翻轉180度,即將矩陣上下翻轉一次以及左右翻轉一次。通過公式的損失函數計算輸出層的誤差項為:
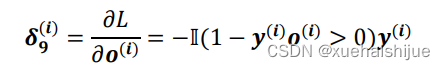
9.網絡結構
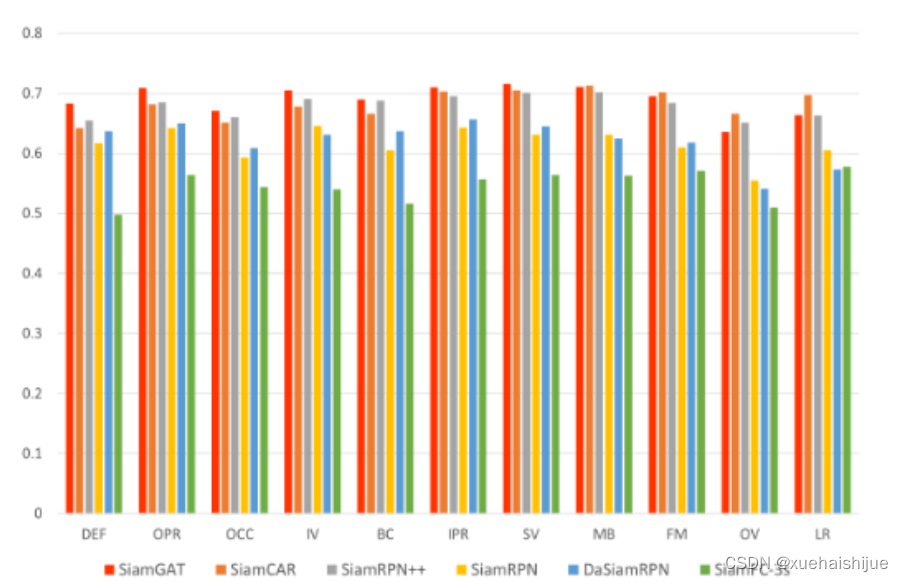
以往的跟蹤器都通過模板分支和搜索分支之間的互相關實現相似性學習。原算法的作者認為這種方式存在以下缺點:
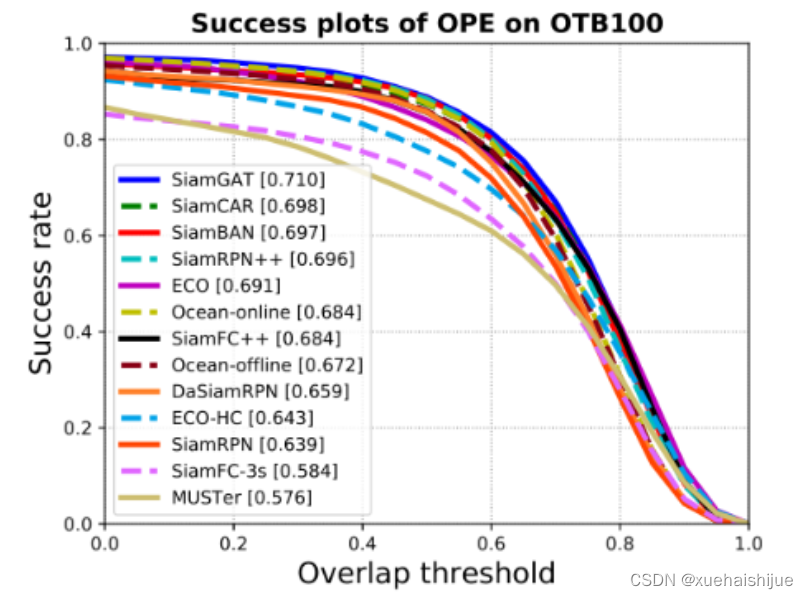
以往跟蹤器一般是以目標中點為中心取m*m大小的區域作為模板,這會導致提取到部分背景信息或者丟失部分目標信息。本文只提取目標所在bbox區域作為模板幀。
以往跟蹤器互相關是將提取到的模板特征在搜索區域上做全局搜索,無法適應旋轉、姿態變化、遮擋等情況。
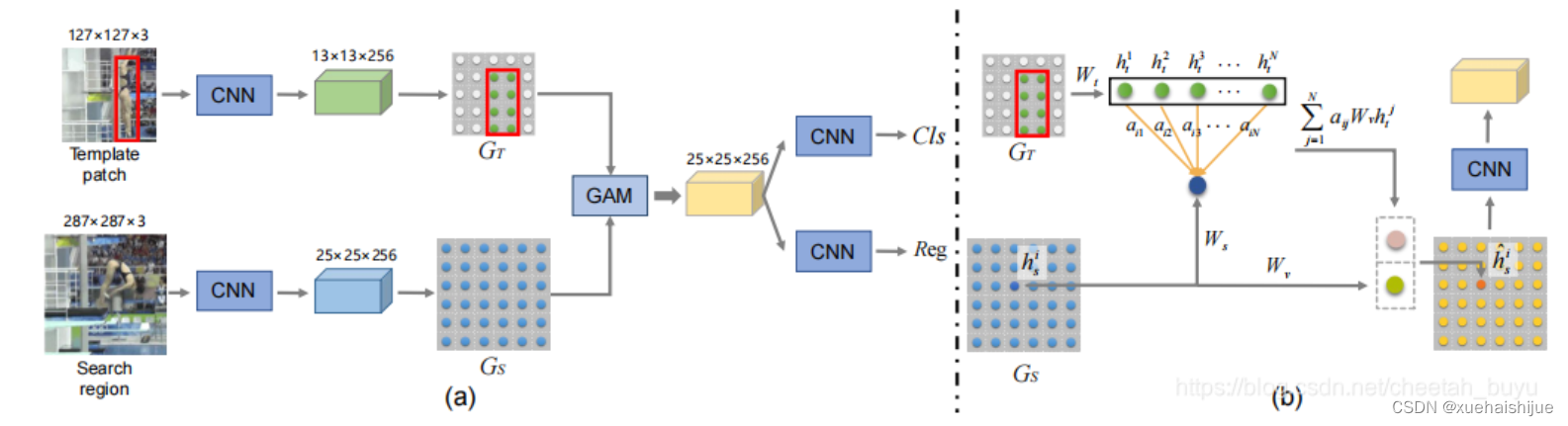
GAM:提出圖注意力模塊(Graph Attention Module),有效將目標信息從模板特征傳遞至搜索特征。
SiamGAT:在SiamCAR基礎上做了改進,設計 target-aware 的選擇機制以適應不同目標的大小和長寬比變化。
整體網絡結構如圖,特征提取使用GoogleNet,頭部和SiamFC++一樣。
10.系統整合
下圖完整源碼&數據集&環境部署視頻教程&自定義UI界面

參考博客《基于圖注意力單元的改進SiamFC++的單目標追蹤系統》





演示案例)













