論文標題: MedSegDiff: Medical Image Segmentation with Diffusion Probabilistic Model
翻譯:
MedSegDiff:基于擴散概率模型的醫學圖像分割
名詞解釋:
高頻分量(高頻信號)對應著圖像變化劇烈的部分,也就是圖像的邊緣(輪廓)或者噪聲以及細節部分。
1. 動態條件編碼
在大多數條件DPM中,條件先驗是一個唯一的給定信息。然而,醫學圖像分割是出了名的模糊對象。病變或組織通常很難從其背景中區分出來。
低對比度的圖像模式,如核磁共振成像或超聲圖像,使其更糟。只給定靜態圖像作為每一步的條件將很難學習。為了解決這個問題,我們提出了每個步驟的動態條件編碼。我們注意到,一方面原始圖像包含準確的分割目標信息,但難以與背景區分,另一方面,當前步分割圖包含增強的目標區域,但不準確。這促使我們去整合當前步分割信息xt轉化為有條件的原始圖像編碼進行相互補全。具體地說,我們在功能級別上實現集成。在原始圖像編碼器中,我們利用當前步長編碼特征來增強其中間特征。條件特征圖m k I的每個尺度與形狀相同的xt編碼特征m k x融合,k為層的指數。這種融合是通過一種類似于注意力的機制a來實現的。特別是,首先將兩個特征映射應用層歸一化并相乘以獲得親和映射。然后將親和映射與條件編碼特征相乘,增強關注區域。
雖然該策略是有效的,但另一個具體的問題是,積分xt嵌入會產生額外的高頻噪聲。為了解決這個問題,我們提出了FF-Parser來約束特征中的高頻成分。
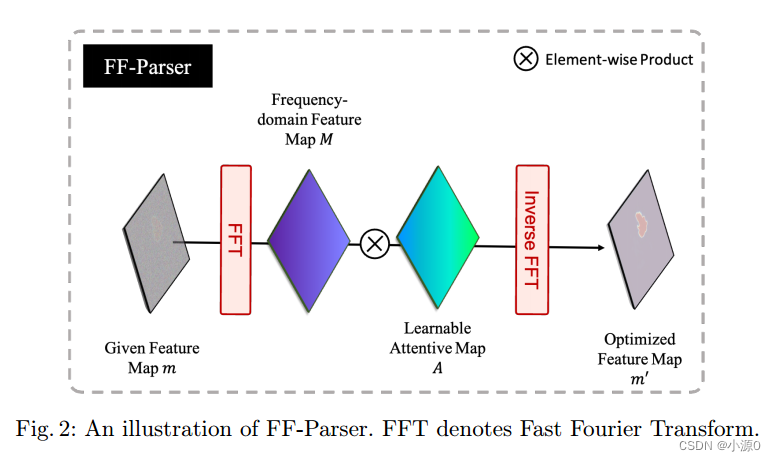
2. FF-Parser
我們以特征集成的路徑方式連接ff解析器。它的功能是約束xt特性中與噪聲相關的組件。我們的主要思想是學習一個參數化的關注(權重)映射應用于傅里葉空間特征。給定一個解碼器特征映射m,我們首先沿著空間維度執行二維FFT(快速傅立葉變換),然后,我們通過將參數化的關注映射A乘以M來調制M的頻譜,最后,我們采用逆FFT將M0逆回空間域。
FF-Parser可以看作是頻率濾波器的一種可學習版本,頻率濾波器廣泛應用于數字圖像處理。與空間關注不同,它對特定頻率的分量進行全局調整。從而可以學會約束高頻分量進行自適應積分。
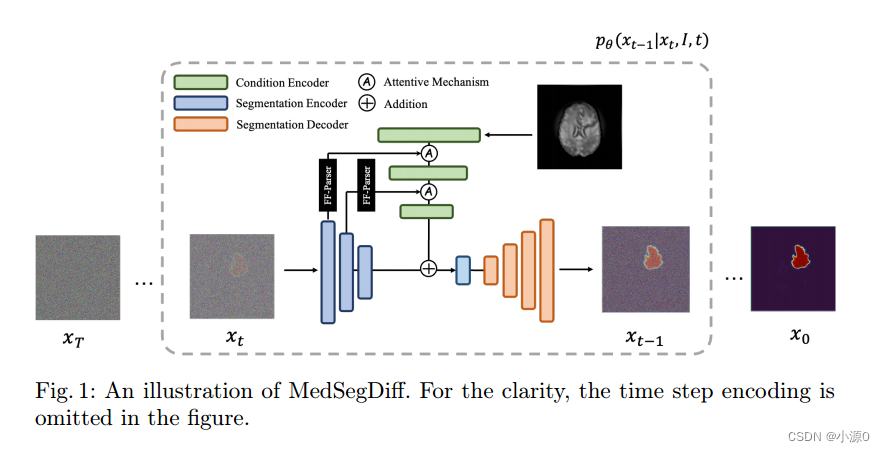
總體結構
總體結構,如圖顯示了一個t階段示例。為了實現分割,我們通過原始圖像先驗條件步長估計函數,在本例中為原始圖像嵌入,E x t為當前步驟的分割映射特征嵌入。將這原始圖片嵌入和分割映射特征嵌入這兩個分量相加并發送到UNet解碼器D進行重構。步驟索引t與添加的嵌入和解碼器功能集成在一起。在每一種情況下,它都是使用共享學習查找表嵌入的。




)














