本篇的主要脈絡同樣依據中科大何向南教授、合工大汪萌教授聯合在 TKDE 上的一篇綜述文章展開:Bias and Debias in Recommender System: A Survey and Future Directions。
下面按照前導文章中介紹的數據偏差 Selection Bias、Conformity Bias、Exposure Bias、Position Bias,分別介紹相應的去偏方法。Popularity Bias、Unfairness 以及如何減緩閉環累積誤差的方法,暫時不會在本文中涉及。
一、基礎概念
1. Propensity Score
Propensity Score 的詳細介紹建議查看下文,,注意掌握幾個變量定義:干預變量 T,結果變量 Y,混淆變量 X,觀測變量 U
集智科學家:如何在觀測數據下進行因果效應評估78 贊同 · 1 評論文章?編輯
-
- 定義:在干預變量之外的其他特征變量為一定值的條件下,個體被處理的概率
- 傾向指數概括了群體的特征變量,如果兩個群體的傾向指數相同,那他們的干預變量就是與其他特征變量相獨立的。對于藥物實驗來說,如果能保證兩群人的他吃藥的概率完全一樣,那么可以說這兩群人其他特征分布也是一樣
- 傾向指數在實際應用中觀測不到,但可以使用有監督學習的方法進行估計,一般是回歸
在推薦中來說“被處理”可以理解為“被觀測到”,如何計算某個 item 被某個 user 觀測到的概率?容易想到的思路是在保持其他條件相同再計算概率,例如排序隊列位置不同時重復同個 user 在同個 item 上的觀測概率,但這種理想情況一般會傷害用戶體驗。
如何計算 Propensity Score 是一個獨立問題,可以 naive 的統計方法(統計歷史上同位置的平均點擊率)、隱變量學習(例如 click models 中預估 position bias 的方法,可以參考我之前的文章? 成指導:深入點擊模型(二)PBM, UBM 與 EM 算法),或者 [SIGIR 2018] Unbiased Learning to Rank with Unbiased Propensity Estimation 中介紹的通過對偶學習 Ranking Model 和 Propensity Model 來求解 Propensity Score 思路,也可以用于參考。
2. 點擊模型(click models)
介紹點擊模型之前,需要區分 click models 區別于 FM/FFM/Wide&Deep/DeepFM 等一系列近年大火的 CTR 模型,點擊模型關注更多的是可解釋性,通過人為知識提出先驗假設,再通過概率圖模型獨立建模各因素,更多時候依賴于 EM 算法求解。因此各種 bias 其實都可以作為其中一個因素存在于概率圖,然后被求解出來。點擊模型被廣泛使用于解決 exposure bias/ position bias 中,之前我有兩篇文章深入介紹過點擊模型,這里就不重復寫了:
- 成指導:深入點擊模型(一)RCM, CTR, CM 與 極大似然估計
- 成指導:深入點擊模型(二)PBM, UBM 與 EM 算法
二、數據偏差
數據偏差的處理方法有一些共通思路,這里先把共通思路介紹一下,再分開介紹各種 Bias 的獨特處理方法。一般需要去偏的步驟有 2 個,分別是在評估中去偏、訓練中去偏。
1. 評估去偏
評估推薦系統在評分預測、推薦準確率上的常見 user-item 評估度量指標吧δ_{u,i}可以是 AUC、MAE、MSE、DCG@K、Precision@K,對多個評分樣本的評估度量?H(R^)?,一般是單個樣本度量的加權平均。這里“多個樣本”常規做法是指觀測到的樣本而不是真實的全量樣本,此時會出現 selection bias 造成的評估指標上的偏差,修正后的評估度量為?
常用工具有 Propensity Score(傾向分數) 。做法是在單個樣本的評估指標中加入?IPS(逆傾向得分,即傾向指數的倒數),傾向性?P_{u,i}定義為觀測某個 user-item 評分值的邊際概率?P(O_{u,i}=1)?,因此修正評估度量
2. 訓練去偏
- 數據代入法。數據偏差的本質是缺少無偏數據,那么通過協同過濾、社交關系加強等方式,補充盡可能相似的數據源,并且根據相似程度決定數據源的貢獻程度
- 傾向分數。這個比較好理解,利用 IPS(逆傾向分數)修正每組樣本的 loss 貢獻值,如?
,其中Reg(θ)?是參數的正則化限制
- Meta Learning。Meta Learning 的 motivation 就是如果模型可以先在數據較多的數據集上學到這些有關“該如何學習新的知識”的先驗知識,由此讓模型先學會“如何快速學習一個新的知識”,再去數據較少的數據集上學習就變得很容易了。這么看 Meta Learning 完美契合 selection bias 的解決方案,但因為這是個獨立學科方向,建議參考以下回答單獨理解:
什么是meta-learning?599 關注 · 17 回答問題?編輯
三、選擇偏差
1. 評估去偏
- ATOP
ATOP 是另一種度量推薦系統效果的無偏指標。ATOP 方法同時建立在 2 個假設之上:(1)高相關性評分在觀測數據上是隨機缺失的;(2)其他評級值允許任意丟失數據機制只要丟失的概率高于相關的評分值。這兩個假設實際上較難同時符合,因此 ATOP 的應用也較少
記為用戶 u 已觀測到的相關性 item 的個數,
?為在 TopK item 中的個數,作者證明 ATOP 是對平均召回率的無偏估計,并與用戶的平均精度成正比

2. 訓練去偏
Doubly Robust 模型。這個方法需要根據已有數據,再學習一個預測的模型反事實評估某個個體在干預變量變化后,結果變量的期望值。經過證明,只要傾向指數的估計模型和反事實預測模型中有一個是對的,計算出的平均因果效應就是無偏的;但如果兩個模型估計都是錯誤的,那產生的誤差可能會非常大(看起來也并非多么 robust)。
四、一致性偏差
conformity bias 大多數情況下是由于人們的“從眾心理”導致的,比較簡單的處理方法就是將投票人數(樣本數量)、投票分布、得分平均值,都作為建模的輸入信號,用一個擬合器去擬合去偏后的修正得分值。本質上就是希望把“社會因素“作為考慮的一部分。
五、曝光偏差
1. 訓練去偏
- 傾向分數
類似 selection debias 小節,使用逆傾向分數計算即可。當計算度量指標的時除以傾向分數。這里提一篇文章 [WSDM 2020] Unbiased Recommender Learning from Missing-Not-At-Random Implicit Feedback,先假設:即物品必須曝光給用戶且相關才會發生點擊。之后定義了一個理想化的 loss 函數對 label=0/1 的樣本求損失和,每個樣本會被相關性等級度量:?
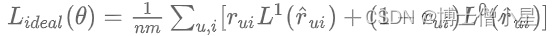
經過去偏操作之后,能夠得到修正后的損失函數無偏預估值形式:
- 采樣
雖然曝光的內容有偏,但是一般學習中使用到的正負樣本都是采樣得到的,那么這里就有一個階段需要獨立處理:采樣。而在一般的信息檢索問題中,負例一般是遠遠大于正例,所以對冗余的負例選擇性采樣是一個需要探索的問題。可以使用最簡單的隨機采樣,或者對于比較流行的負例內容做重復采樣(流行數據一般經過充分曝光,負例程度比較確信)。更復雜的思路里,會把樣本的 side information 或者圖關系作為預測采樣率的工具,按照采樣率工作。
這里多說一點,實際工作中,我們嘗試對于未曝光的樣本,適當采樣作為”偽負樣本“(因為不確定未曝光是正是負,但因為推薦問題中正例占比很低)可以增加模型的泛化能力。
六、位置偏差
Position bias 廣泛存在于搜索系統中(大家自己想想是不是經常性點擊百度/谷歌搜索結果的第一位返回結果),推薦系統中也同樣存在。而經典去偏方法就是使用點擊模型(包括 click models 的各種書籍或經典論文中,一般也都是拿 position bias 作為分析示例)。同理,逆傾向分數同樣適用。點擊模型、傾向分數的解釋,請參考本文的文章開頭。
在神經網絡 CTR 模型中,華為發表的[RecSys 2019] PAL: A Position-bias Aware Learning Framework for CTR Prediction in Live Recommender Systems,以及 Youtube 發表的 [RecSys 2019] Recommending What Video to Watch Next: A Multitask Ranking System,嘗試過將 position bias 作為多塔建模的單獨一塔或作為獨立一塔的主要輸入,并且顯式地通過 logits 相乘來反應
即物品必須曝光給用戶且相關才會發生點擊,而是否曝光僅與物品所處位置?
決定。
至此,常見數據偏差的去偏思路與方法已經介紹完成了。

)







)







)

