Standalone模式兩種提交任務方式
一、Standalone-client提交任務方式
1、提交命令
./spark-submit --master spark://mynode1:7077
--class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.3.1.jar 100或者
./spark-submit --master spark://mynode1:7077
--deploy-mode client
--class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.3.1.jar 1002、執行原理圖解
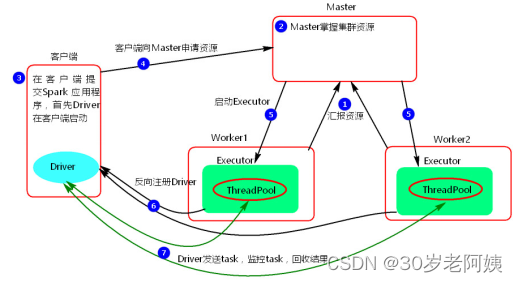
1)、執行流程
1、client模式提交任務后,會在客戶端啟動Driver進程。
2、Driver會向Master申請啟動Application啟動的資源
3、Master收到請求之后會在對應的Worker節點上啟動Executor
4、Executor啟動之后,會注冊給Driver端,Driver掌握一批計算資源
5、Driver端將task發送到worker端執行。worker將task執行結果返回到Driver端。
2)、總結
client模式適用于測試調試程序。Driver進程是在客戶端啟動的,這里的客戶端就是指提交應用程序的當前節點。在Driver端可以看到task執行的情況。生產環境下不能使用client模式,是因為:假設要提交100個application到集群運行,Driver每次都會在client端啟動,那么就會導致客戶端100次網卡流量暴增的問題。client模式適用于程序測試,不適用于生產環境,在客戶端可以看到task的執行和結果
二、Standalone-cluster提交任務方式
1、提交命令
./spark-submit --master spark://mynode1:7077
--deploy-mode cluster
--class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.3.1.jar 1002、執行原理圖解
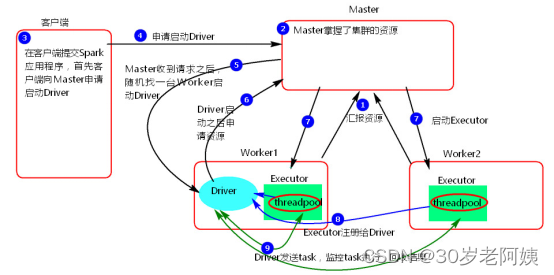
1)、執行流程
1、cluster模式提交應用程序后,會向Master請求啟動Driver
2、Master接受請求,隨機在集群一臺節點啟動Driver進程
3、Driver啟動后為當前的應用程序申請資源
4、Driver端發送task到worker節點上執行
5、worker將執行情況和執行結果返回給Driver端
2)、總結
Driver進程是在集群某一臺Worker上啟動的,在客戶端是無法查看task的執行情況的。假設要提交100個application到集群運行,每次Driver會隨機在集群中某一臺Worker上啟動,那么這100次網卡流量暴增的問題就散布在集群上。
- 總結Standalone兩種方式提交任務,Driver與集群的通信包括:
1. Driver負責應用程序資源的申請
2. 任務的分發。
3. 結果的回收。
4. 監控task執行情況。








)
)









