MySQL中自增id用完怎么辦?
MySQL里有很多自增的id,每個自增id都是定義了初始值,然后不停地往上加步長。雖然自然數是沒有上限的,但是在計算機里,只要定義了表示這個數的字節長度,那它就有上限。比如,無 符號整型(unsigned int)是4個字節,上限就是2^32 - 1。
接下來我們看看MySQL里面的幾種自增id,分析下它們的值達到上限之后,會出現什么情況。
一,表定義自增值id
表定義的自增值達到上限后的邏輯是:再次申請下一個id時,得到的值保持不變。
CREATE TABLE t (id INT UNSIGNED auto_increment PRIMARY KEY
) auto_increment = 4294967295;
SELECT * from t;
insert into t values(null);
SELECT * from t;
insert into t values(null);
SELECT * from t;
可以看到,第一個insert語句插入數據成功后,這個表的AUTO_INCREMENT沒有改變(還是 4294967295),就導致了第二個insert語句又拿到相同的自增id值,再試圖執行插入語句,報主鍵沖突錯誤。
解決方法:
2^32 - 1(4294967295)不是一個特別大的數,對于一個頻繁插入刪除數據的表來說,是可能會被用完的。因此在建表的時候你需要考察你的表是否有可能達到這個上限,如果有可能,就應該創 建成8個字節的bigint unsigned。
類型 字節/bytes 范圍(無符號unsigned) 范圍(有符號signed)
tinyint 1 0 ~ 2^8-1 -2^7 ~ 2^7-1
smallint 2 0 ~ 2^16-1 -2^15 ~ 2^15-1
mediumint 3 0 ~ 2^24-1 -2^23 ~ 2^23-1
int 4 0 ~ 2^32-1 -2^31 ~ 2^31-1
bigint 8 0 ~ 2^64-1 -2^63 ~ 2^63-1
二,InnoDB系統自增row_id
如果你創建的InnoDB表沒有指定主鍵,那么InnoDB會給你創建一個不可見的,長度為6個字節 的row_id。InnoDB維護了一個全局的dict_sys.row_id值,所有無主鍵的InnoDB表,每插入一行數據,都將當前的dict_sys.row_id值作為要插入數據的row_id,然后把dict_sys.row_id的值加1。
實際上,在代碼實現時row_id是一個長度為8字節的無符號長整型(bigint unsigned)。但 是,InnoDB在設計時,給row_id留的只是6個字節的長度,這樣寫到數據表中時只放了最后6個字節
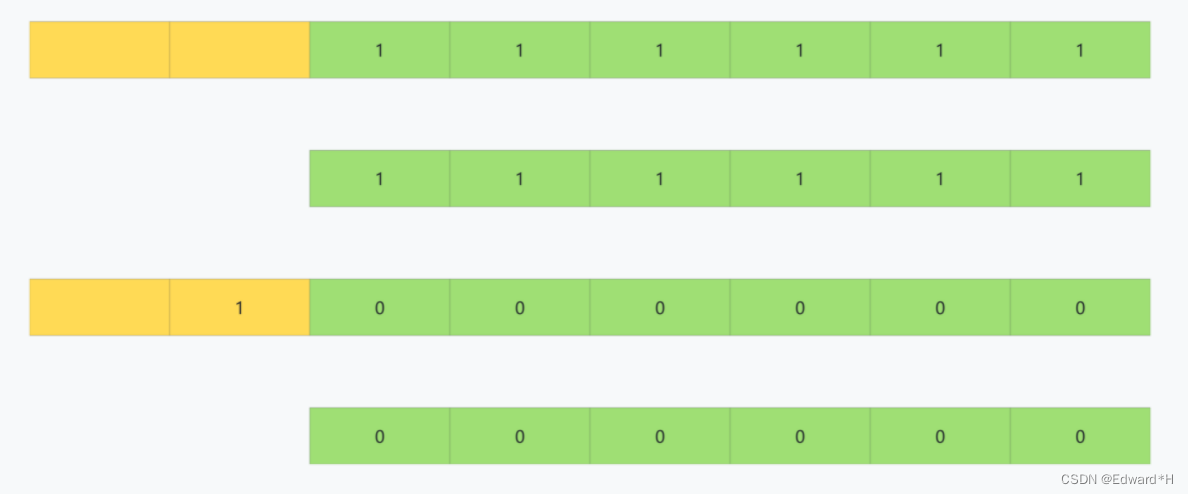
所以row_id能寫到數據表中的值,就有兩個特征:
- row_id寫入表中的值范圍,是從0到2^48 - 1;
- 當dict_sys.row_id=2^48 時,如果再有插入數據的行為要來申請row_id,拿到以后再取最后6個字節的話就是0。
也就是說,寫入表的row_id是從0開始到2^48 -1。達到上限后,下一個值就是0,然后繼續循環。
驗證:
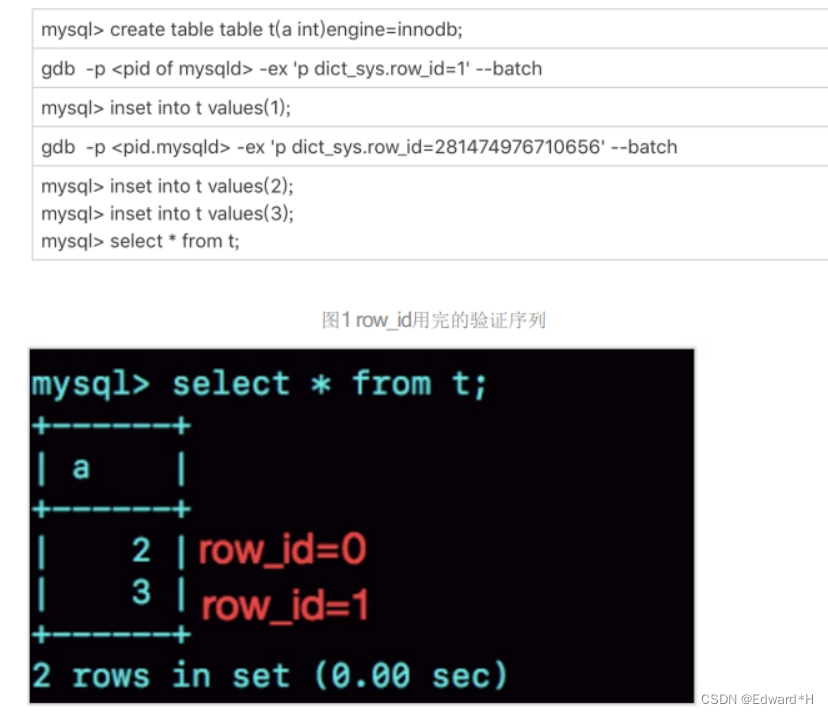
從這個角度看,我們還是應該在InnoDB表中主動創建自增主鍵。因為,表自增id到達上限后, 再插入數據時報主鍵沖突錯誤,是更能被接受的。
畢竟覆蓋數據,就意味著數據丟失,影響的是數據可靠性;報主鍵沖突,是插入失敗,影響的是 可用性。而一般情況下,可靠性優先于可用性。
三,Xid
Xid在MySQL內部是怎么生成的呢?
redo log和binlog相配合的時候,它們有一個共同的字段叫作Xid。它在MySQL中是用來對應事務的。
MySQL內部維護了一個全局變量global_query_id,每次執行語句的時候將它賦值給Query_id, 然后給這個變量加1。如果當前語句是這個事務執行的第一條語句,那么MySQL還會同時把 Query_id賦值給這個事務的Xid。
而global_query_id是一個純內存變量,重啟之后就清零了。所以你就知道了,在同一個數據庫實例中,不同事務的Xid也是有可能相同的。
但是MySQL重啟之后會重新生成新的binlog文件,這就保證了,同一個binlog文件里,Xid一定是惟一的。
雖然MySQL重啟不會導致同一個binlog里面出現兩個相同的Xid,但是如果global_query_id達到上限后,就會繼續從0開始計數。從理論上講,還是就會出現同一個binlog里面出現相同Xid的場景。
因為global_query_id定義的長度是8個字節,這個自增值的上限是2^64 - 1。要出現這種情況,必須是下面這樣的過程:
- 執行一個事務,假設Xid是A;
- 接下來執行2^64 次查詢語句,讓global_query_id回到A;
- 再啟動一個事務,這個事務的Xid也是A。
不過,2^64 這個值太大了,大到你可以認為這個可能性只會存在于理論上。
四,Innodb trx_id
Xid和InnoDB的trx_id是兩個容易混淆的概念。
Xid是由server層維護的。InnoDB內部使用Xid,就是為了能夠在InnoDB事務和server之間做關聯。但是,InnoDB自己的trx_id,是另外維護的。
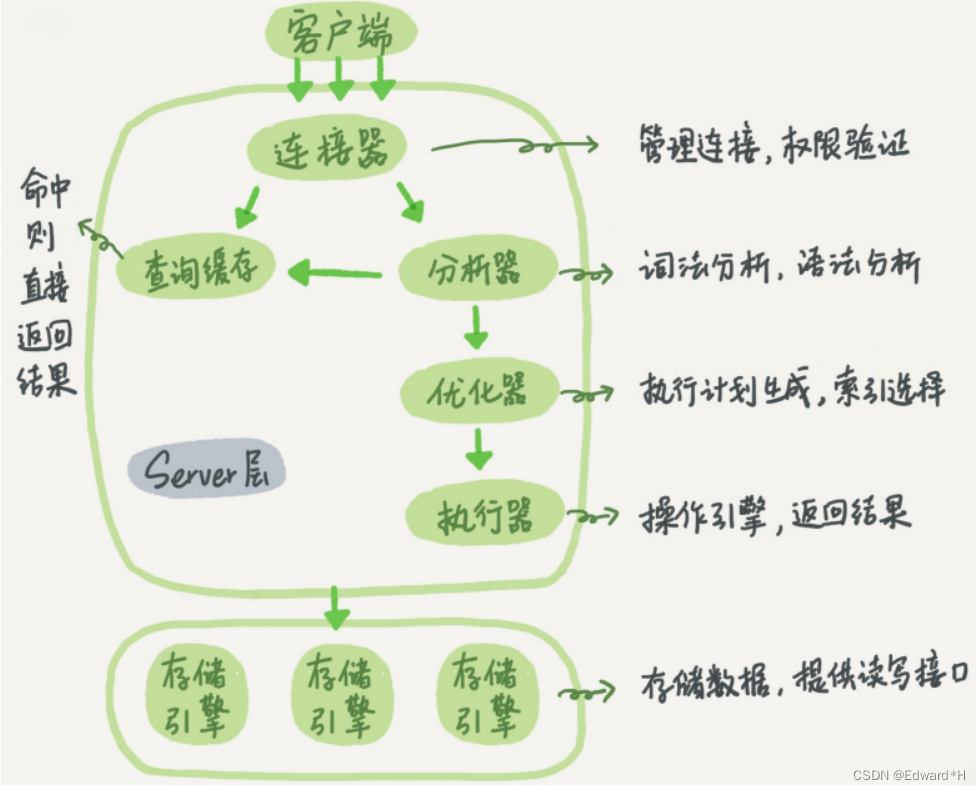
其實,trx_id就是mvcc中用到的事務id(transaction id)。
InnoDB數據可見性的核心思想是:每一行數據都記錄了更新它的trx_id,當一個事務讀到一行數據的時候,判斷這個數據是否可見的方法,就是通過事務的一致性視圖與這行數據的trx_id做對 比。
InnoDB內部維護了一個max_trx_id全局變量,每次需要申請一個新的trx_id時,就獲得 max_trx_id的當前值,然后并將max_trx_id加1。
對于正在執行的事務(活躍事務),你可以從information_schema.innodb_trx表中看到事務的一些相關信息如:trx_id。
現在,我 們一起來看一個事務現場:
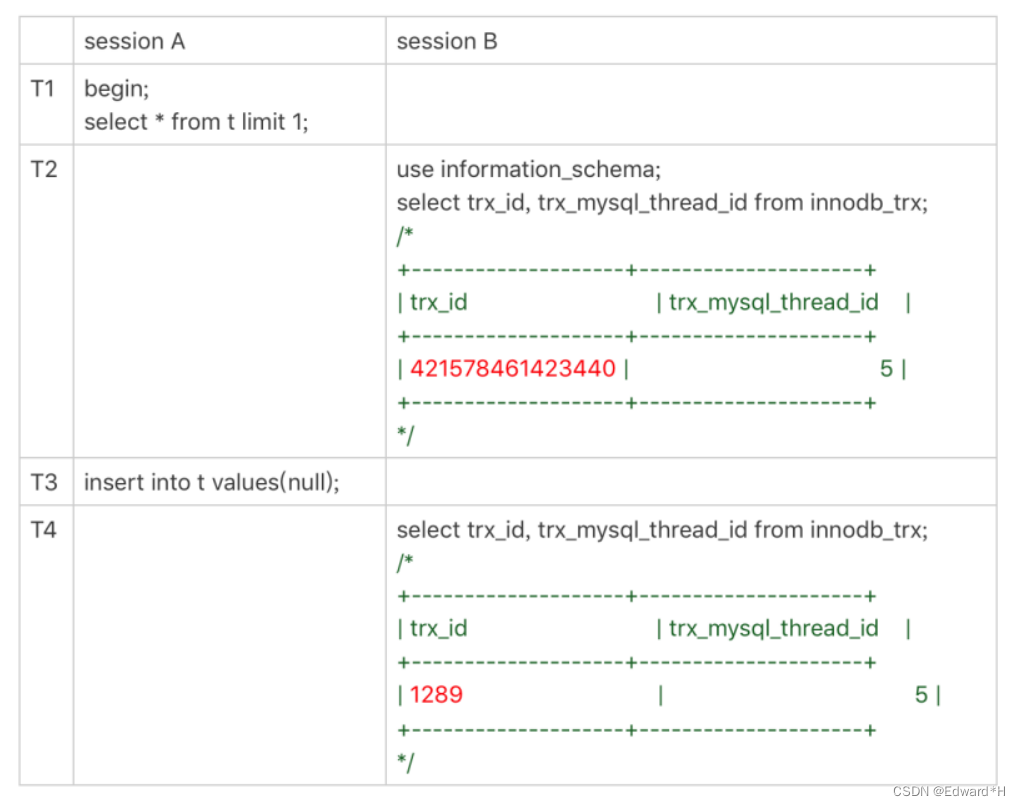
事務的trx_id session B里,我從innodb_trx表里查出的這兩個字段,第二個字段trx_mysql_thread_id就是線程 id。顯示線程id,是為了說明這兩次查詢看到的事務對應的線程id都是5,也就是session A所在的線程。
可以看到,T2時刻顯示的trx_id是一個很大的數;T4時刻顯示的trx_id是1289,看上去是一個比 較正常的數字。這是什么原因呢?
實際上,在T1時刻,session A還沒有涉及到更新,是一個只讀事務。而對于只讀事務,InnoDB 并不會分配trx_id。也就是說:
- 在T1時刻,trx_id的值其實就是0。而這個很大的數,只是顯示用的。一會兒我會再和你說說 這個數據的生成邏輯。
- 直到session A 在T3時刻執行insert語句的時候,InnoDB才真正分配了trx_id。所以,T4時刻,session B查到的這個trx_id的值就是1289。
需要注意的是,除了顯而易見的修改類語句外,如果在select 語句后面加上for update,這個事 務也不是只讀事務。
實驗的時候發現不止加1。這是因為:
- update 和 delete語句除了事務本身,還涉及到標記刪除舊數據,也就是要把數據放到purge 隊列里等待后續物理刪除,這個操作也會把max_trx_id + 1, 因此在一個事務中至少加2;
- InnoDB的后臺操作,比如表的索引信息統計這類操作,也是會啟動內部事務的,因此你可能看到,trx_id值并不是按照加1遞增的。
那么,T2時刻查到的這個很大的數字是怎么來的呢?
其實,這個數字是每次查詢的時候由系統臨時計算出來的。它的算法是:把當前事務的trx變量的 指針地址轉成整數,再加上2^48。使用這個算法,就可以保證以下兩點:
- 因為同一個只讀事務在執行期間,它的指針地址是不會變的,所以不論是在 innodb_trx還是 在innodb_locks表里,同一個只讀事務查出來的trx_id就會是一樣的。
- 如果有并行的多個只讀事務,每個事務的trx變量的指針地址肯定不同。這樣,不同的并發只讀事務,查出來的trx_id就是不同的。
為什么還要再加上2^48 呢?
在顯示值里面加上2^48 ,目的是要保證只讀事務顯示的trx_id值比較大,正常情況下就會區別于讀 寫事務的id。但是,trx_id跟row_id的邏輯類似,定義長度也是8個字節。因此,在理論上還是可 能出現一個讀寫事務與一個只讀事務顯示的trx_id相同的情況。不過這個概率很低,并且也沒有 什么實質危害,可以不管它。
只讀事務不分配trx_id,有什么好處呢?
- 一個好處是,這樣做可以減小事務視圖里面活躍事務數組的大小。因為當前正在運行的只讀 事務,是不影響數據的可見性判斷的。所以,在創建事務的一致性視圖時,InnoDB就只需要 拷貝讀寫事務的trx_id。
- 另一個好處是,可以減少trx_id的申請次數。在InnoDB里,即使你只是執行一個普通的select 語句,在執行過程中,也是要對應一個只讀事務的。所以只讀事務優化后,普通的查詢語句 不需要申請trx_id,就大大減少了并發事務申請trx_id的鎖沖突。
由于只讀事務不分配trx_id,一個自然而然的結果就是trx_id的增加速度變慢了。
但是,max_trx_id會持久化存儲,重啟也不會重置為0,那么從理論上講,只要一個MySQL服務 跑得足夠久,就可能出現max_trx_id達到2^48 -1的上限,然后從0開始的情況。
當達到這個狀態后,MySQL就會持續出現一個臟讀的bug,我們來復現一下這個bug。
首先我們需要把當前的max_trx_id先修改成2^48 -1。注意:這個case里使用的是可重復讀隔離級 別。具體的操作流程如下:
create table t(id int primary key, c int)engine=innodb;
insert into t values(1,1);
gdb -p <pid.mysqld> -ex 'p trx_sys->max_trx_id=281474976710655' --batch;

由于我們已經把系統的max_trx_id設置成了2^48 -1,所以在session A啟動的事務TA的低水位就是 2^48 - 1。
在T2時刻,session B執行第一條update語句的事務id就是2^48 - 1,而第二條update語句的事務id 就是0了,這條update語句執行后生成的數據版本上的trx_id就是0。
在T3時刻,session A執行select語句的時候,判斷可見性發現,c=3這個數據版本的trx_id,小于事務TA的低水位,因此認為這個數據可見。
但,這個是臟讀。
由于低水位值會持續增加,而事務id從0開始計數,就導致了系統在這個時刻之后,所有的查詢都會出現臟讀的。
并且,MySQL重啟時max_trx_id也不會清0,也就是說重啟MySQL,這個bug仍然存在。
那么,這個bug也是只存在于理論上嗎?
假設一個MySQL實例的TPS是每秒50萬,持續這個壓力的話,在17.8年后,就會出現這個情 況。如果TPS更高,這個年限自然也就更短了。但是,從MySQL的真正開始流行到現在,恐怕 都還沒有實例跑到過這個上限。不過,這個bug是只要MySQL實例服務時間夠長,就會必然出現的。
五,thread_id
接下來,我們再看看線程id(thread_id)。其實,線程id才是MySQL中最常見的一種自增id。平時我們在查各種線程的時候,show processlist里面的第一列,就是thread_id。
thread_id的邏輯很好理解:系統保存了一個全局變量thread_id_counter,每新建一個連接,就 將thread_id_counter賦值給這個新連接的線程變量。
thread_id_counter定義的大小是4個字節,因此達到2^32 -1后,它就會重置為0,然后繼續增加。 但是,你不會在show processlist里看到兩個相同的thread_id。
這,是因為MySQL設計了一個唯一數組的邏輯,給新線程分配thread_id的時候,邏輯代碼是這 樣的:
do {
new_id= thread_id_counter++;
} while (!thread_ids.insert_unique(new_id).second);
總結
每種自增id有各自的應用場景,在達到上限后的表現也不同:
- 表的自增id達到上限后,再申請時它的值就不會改變,進而導致繼續插入數據時報主鍵沖突 的錯誤。
- row_id達到上限后,則會歸0再重新遞增,如果出現相同的row_id,后寫的數據會覆蓋之前 的數據。
- Xid只需要不在同一個binlog文件中出現重復值即可。雖然理論上會出現重復值,但是概率極 小,可以忽略不計。
- InnoDB的max_trx_id 遞增值每次MySQL重啟都會被保存起來,所以我們文章中提到的臟讀 的例子就是一個必現的bug,好在留給我們的時間還很充裕。
- thread_id是我們使用中最常見的,而且也是處理得最好的一個自增id邏輯了。
不同的自增id有不同的上限值,上限值的大小取決于聲明的類型長度。


)

)


![Java接口自動化測試系列[V1.0.0][概述]](http://pic.xiahunao.cn/Java接口自動化測試系列[V1.0.0][概述])











