1、redis-cluster集群:redis3.0引入的分布式存儲方案
2、集群:由多個node節點組成,redis數據分布在這些節點之中
(1)在集群之中也分主節點和從節點
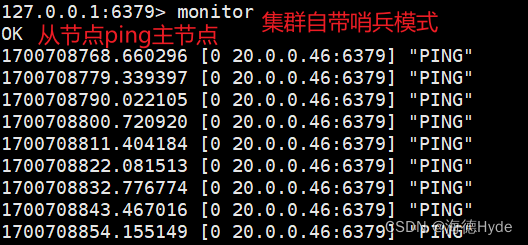
(2)自帶哨兵模式
3、redis-cluster集群的數據流向
(1)集群模式中,主從一一對應,數據寫入和讀取與主從復制一樣,主負責寫,從只能讀
(2)集群模式自帶哨兵模式,可以自動實現故障切換,但是在故障切換完成之前,整個集群都將不可用,切換完畢之后,集群會立刻恢復

4、集群模式按照數據分片
(1)數據分片:集群的核心功能,每個主都可以對外提供讀、寫的功能,但是數據是一一對應寫入主的對應從節點。在集群模式中,可以容忍數據的不完整
(2)高可用:集群的主要目的
5、數據分片的實現過程
(1)redis的集群引入了hash槽的概念,在redis集群當中有16384個hash槽位(0-16383)
(2)根據集群當中的主從節點數,分配hash槽位,每個主從節點只負責一部分的hash槽位
(3)每次讀寫都涉及到hash槽位,key通過CRC16校驗之后,對16384取余數,余數值決定數據放入哪個hash槽位,通過這個值找到對應槽位所在的節點,然后直接跳轉到這個節點
(4)hash槽位的值是連續的,如果出現不連續的hash值,或者有hash槽位沒有被分配,集群將會報錯
(5)主從復制:主宕機之后,主節點原來負責的hash槽位將會不可用,需要從節點代替主節點繼續負責原有的hash槽位,保證集群的正常工作,所有故障切換的過程中,會提示集群不可用,切換完成,集群繼續工作

6、實驗過程
(1)修改配置文件

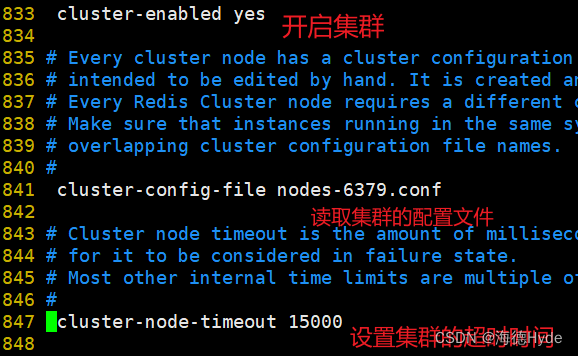


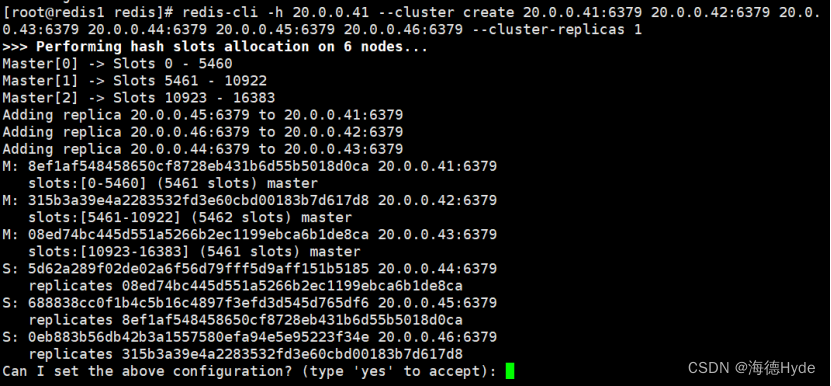
(2)創建集群
redis-cli -h 20.0.0.41 --cluster create 20.0.0.41:6379 20.0.0.42:6379 20.0.0.43:6379 20.0.0.44:6379 20.0.0.45:6379 20.0.0.46:6379 --cluster-replicas 1
replicas 1:規定一個主只有一個從(主從的配合是隨機分配的)
在集群模式當中,只能選擇0庫,集群不能切換庫,只能使用默認庫

查看集群中的所有節點:cluster nodes


error表示:客戶端嘗試讀取鍵值對test1,但是實際槽位在4768,集群要求客戶端移動到4768所在的主機節點獲取數據

添加鍵(創建鍵值對時,hash槽位已經分配好了):
(3)模擬故障

(4)恢復故障


實時監控redis工作過程的日志:monitor

![Java接口自動化測試系列[V1.0.0][概述]](http://pic.xiahunao.cn/Java接口自動化測試系列[V1.0.0][概述])














和 Navicat 集成)


