引導
????????前面幾節,我們介紹了有關樹的數據結構,我們繼續來介紹一種樹結構——堆。堆的應用場景有很多,比如從大量數據中找出top n的數據;根據優先級處理網絡請求;這些情景都可以使用堆數據結構來實現。
什么是堆?
正如上文所說,堆是一種樹結構。它的定義滿足以下兩點:
- 堆是一個完全二叉樹
- 堆中每個節點的值必須大于等于(或小于等于)其子樹中每個節點的值
完全二叉樹在前面我們已經講過;第二點,其實等價于堆中每個節點大于等于(或小于等于)其左右子節點。
對于每個節點大于等于左右子節點,我們稱為大頂堆;每個節點小于等于左右子節點,我們稱為小頂堆。
堆的操作
堆這種數據結構有點不一樣。不適合查找或刪除指定值的操作。
但是它可以幫助我們解決一些特定的問題。但是不同的問題,都離不開以下核心操作:插入一個元素,刪除堆頂元素。
創建一個堆
我們知道完全二叉樹適合用數組進行保存。因為它不需要保存左右指針,通過數組下標就可以實現。
數組下表為i的節點,其左子節點的數組下標為2*i,右子節點的數組下標為 2 *i+1;任意節點的父節點下標為i/2;根節點的下標為1.
插入一個元素
????????向堆中插入一個數據,我們可以將新加入的數據加入到堆的后面,使其繼續維持一個完全二叉樹。
????????但是插入一個新的數據就無法保證其父節點大于等于(或小于等于)左右子節點了。于是我們還要進行調整,使其滿足堆的特性。我們稱為這個過程為堆化。堆化的過程,其實也簡單,只要循著插入節點,向上對比,進行交換即可。
| / |
刪除堆頂元素
由堆的特性所致,刪除堆頂元素,實際上就是找出最大或者最小值的過程。刪除堆頂元素其實也簡單,可按照以下思路進行:
- 將最后一個元素放到堆頂,保證樹是一個完全二叉樹
- 從堆頂開始進行堆化,使其滿足特質二
| / |
????????通過插入一個數據和刪除堆頂元素的操作流程,我們知道時間的消耗主要集中在堆化中。由于完全二叉樹的樹高不會超過logn。所以堆的插入數據和刪除堆頂元素的時間復雜度都是O(logn)。
如何實現堆排序?
????????我們已經知道堆的性質以及基本的操作。但是對于一組數據我們該如何進行堆排序呢?原始的數據肯定是無序也不是堆結構的。因此我們第一步應該是建立堆。
建堆
建堆的方式有兩種
第一種最簡單:首先假設堆中的數據為0,依次將原始數據放到堆中。我們知道插入數據的時間復雜度是O(logn)。故插入第一個數據的消耗的時間為log1,第二個數據消耗的時間為log2...以此推測,第n個數據消耗時間為logn。
方法一消耗的時間為:log1+log2+log3...+logn=O(logn!),并且需要額外的內存。
第二種思路就比較特殊:對于完全二叉樹而言,下標從n/2 + 1到n的節點都是葉子節點,并且葉子節點是不需要堆化的。
因此我們只需要將原始數據中下標從1到n/2進行堆化即可,并且不需要額外的內存。
| int buildheap(int heap[],int count) |
那么第二種思路的時間復雜度是多少呢?
我們知道堆化的操作和所在節點的高度有關。由于葉子節點不需要堆化,并且每層節點和節點高度成正比,如圖:
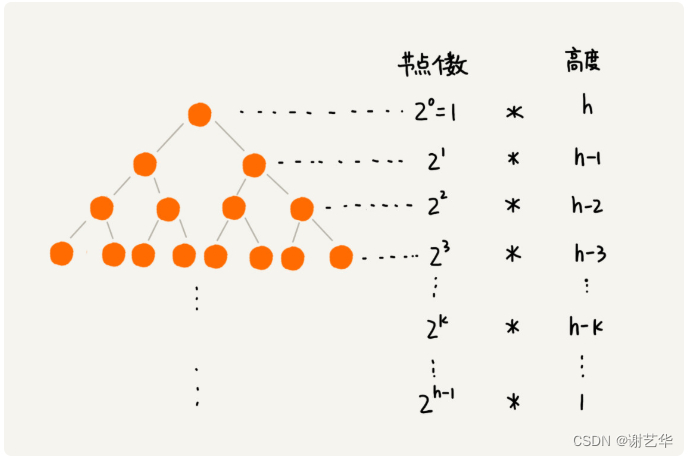
故消耗的時間為:
| T = 2^0 |
由于h=logn(以2為底)通過化簡,得出時間復雜度為O(2n-h-2)=O(n)。
至此,我們已將完成建堆
排序
在刪除堆頂元素時,我就說過了,這就是排序的過程。因此堆排序,就是將堆頂元素不斷刪除,直至堆為空。
代碼如下:
| int heapsort() |
現在我們看堆排序的時間復雜度是多少?
????????建堆的時間復雜度是O(n),排序的時間復雜度是O(nlogn)(實際上應該是logn+log(n-1)+log(n-2)+...+log(1),這里方便,我們記錄為O(logn))。故堆排序的時間復雜度為O(nlogn)。
快速排序的性能為什么比堆排序的要好?
在排序章節,我們提到了快速排序,它是時間復雜度也是O(nlogn)。但是在實際開發過程中,我們快速排序的性能優于堆排序。我覺得原因有以下幾點:
- 堆排序的訪問沒有快速排序好。即使堆排序也是以數組為存儲。但是由于它訪問不是連續的,不能很好的利用CPU緩存。
- 對于同樣的數據,堆排序的數據交換要多于快速排序。
堆應用
優先級隊列
????????在工作中,我們經常會遇到定時任務的問題。一般思路:將每個任務保存到數組中,每過一個時間間隔(1秒),就檢測一下數組,看哪個任務達到了設定時間,如果到達了就取出任務執行,并刪除。
其實這樣的定時器效率是很低的,為什么呢?
- 往往到達下一個任務之間的間隔是需要很長時間,那么在達到之前所有的檢測都是無用的,這是在浪費系統資源
- 如果任務列表的長度很大,那么每次遍歷,都會消耗很多的資源。這也是不可取的。
針對該類問題,我們可以采用優先級隊列來解決。我們按照任務時間進行堆化。堆頂就是最先要被執行的任務。
修改方案:
- 根據任務時間進行堆化(小堆頂),堆頂任務就是下一個將要被執行的任務
- 計算現在距離下一個任務的時間T,sleep T秒,再執行堆頂任務。這樣在執行下一個任務之前,定時器不需要做任何事情,性能大大提高。
Top k
堆在求top k的問題中,表現的也同樣出色。
求top K的問題,我們可以先將數據排序,再取前K個元素。我們可以通過快排,那么求top K的時間復雜度是O(nlogn),這同樣也很快,難道堆會更好嗎?
堆應用的思路:
- 取數據中的前K個元素,建立小頂堆。
- 繼續遍歷數組中的元素,如果元素大于堆頂元素,則加入堆中,并刪除堆頂元素。若比堆頂元素小,則不進行處理。
- 當遍歷完整個數組后,堆中的數據就是前top K數據。
假設每個元素都需要進行插入,那么就是堆化n個元素,堆化的時間復雜度是O(logK),故使用過堆求top K的問題,其時間復雜度是O(nlogk)。
求中位數
在求中位數的問題中,我們一般的思路是將原始數據進行排序。
再求中位數,如果n為奇數的話,中位數就是n/2+1;如果n為偶數的話,中位數就是n/2或n/2+1。這種方式的消耗主要集中在對n個數據排序上面,使用快速排序,它的時間復雜度就是O(nlogn)。
但這樣的方式比較適合靜態數據,當數據能夠動態添加時,再采取這樣的方式,就不再適合了。
堆對于這種動態數據,求中位數有其優勢。我們的思路是這樣的:
- 先將現有數據進行升序排序,取前n/2個數據進行大堆頂堆化。后n/2個數據進行小堆頂堆化。(假設n為偶數。若n為奇數,取前n/2+1個數據為大堆頂)
- 當n為偶數時,中位數就是大堆頂和小堆頂的堆頂元素;當n為奇數時,中位數就是大堆頂的堆頂元素;
- 插入一個元素時,如果插入元素小于等于大堆頂元素,我們就將元素插入到大堆頂;反之插入到小堆頂。這樣就容易不滿足我們的預定:取前n/2個數據進行大堆頂堆化。后n/2個數據進行小堆頂堆化。(假設n為偶數。若n為奇數,取前n/2+1個數據為大堆頂)。我們就需要將兩個堆的堆頂元素互相調整,使其滿足上訴約定
????????通過上述的邏輯,我們就可以得到一個適合動態數據,求中位數的方案。其時間復雜度主要集中在堆化過程O(logn)。
總結
????????本節,我們介紹了堆這種數據結構以及堆結構的定義。也從代碼的角度去實現了堆和堆排序。
????????最后也比較了快速排序相對于堆排序的優點。我后面會繼續總結一個關于堆排序的應用方向的一系列題。爭取吃透。



或者AOP @Before)




)




)





