目錄
null文章瀏覽閱讀9w次,點贊7次,收藏7次。Java核心知識點整理大全https://blog.csdn.net/lzy302810/article/details/132202699?spm=1001.2014.3001.5501
Java核心知識點整理大全2-筆記_希斯奎的博客-CSDN博客
Java核心知識點整理大全3-筆記_希斯奎的博客-CSDN博客
Java核心知識點整理大全4-筆記-CSDN博客
Java核心知識點整理大全5-筆記-CSDN博客
Java核心知識點整理大全6-筆記-CSDN博客
Java核心知識點整理大全7-筆記-CSDN博客
Java核心知識點整理大全8-筆記-CSDN博客文章瀏覽閱讀762次,點贊29次,收藏27次。Java核心知識點整理大全7-筆記-CSDN博客但是如果鎖的競爭激烈,或者持有鎖的線程需要長時間占用鎖執行同步塊,這時候就不適合 使用自旋鎖了,因為自旋鎖在獲取鎖前一直都是占用 cpu 做無用功,占著 XX 不 XX,同時有大量 線程在競爭一個鎖,會導致獲取鎖的時間很長,線程自旋的消耗大于線程阻塞掛起操作的消耗, 其它需要 cup 的線程又不能獲取到 cpu,造成 cpu 的浪費。https://blog.csdn.net/lzy302810/article/details/134551820?spm=1001.2014.3001.5501

4.1.13.3. 拒絕策略
4.1.13.4. Java 線程池工作過程
4.1.14. JAVA 阻塞隊列原理
4.1.14.1. 阻塞隊列的主要方法:
插入操作:
獲取數據操作:
4.1.14.2. Java 中的阻塞隊列
4.1.14.3. ArrayBlockingQueue(公平、非公平)
4.1.14.4. LinkedBlockingQueue(兩個獨立鎖提高并發)
4.1.14.5. PriorityBlockingQueue(compareTo 排序實現優先)
4.1.14.6. DelayQueue(緩存失效、定時任務 )
4.1.14.7. SynchronousQueue(不存儲數據、可用于傳遞數據)
4.1.14.8. LinkedTransferQueue
4.1.14.9. LinkedBlockingDeque
4.1.15. CyclicBarrier、CountDownLatch、Semaphore 的用法
4.1.15.1. CountDownLatch(線程計數器 )
4.1.15.2. CyclicBarrier(回環柵欄-等待至 barrier 狀態再全部同時執行)
4.1.15.3. Semaphore(信號量-控制同時訪問的線程個數)
上面 4 個方法都會被阻塞,如果想立即得到執行結果,可以使用下面幾個方法
4.1.16. volatile 關鍵字的作用(變量可見性、禁止重排序)
變量可見性
禁止重排序
適用場景
4.1.13.3. 拒絕策略
線程池中的線程已經用完了,無法繼續為新任務服務,同時,等待隊列也已經排滿了,再也 塞不下新任務了。這時候我們就需要拒絕策略機制合理的處理這個問題。 JDK 內置的拒絕策略如下:
1. AbortPolicy : 直接拋出異常,阻止系統正常運行。
2. CallerRunsPolicy : 只要線程池未關閉,該策略直接在調用者線程中,運行當前被丟棄的 任務。顯然這樣做不會真的丟棄任務,但是,任務提交線程的性能極有可能會急劇下降。
3. DiscardOldestPolicy : 丟棄最老的一個請求,也就是即將被執行的一個任務,并嘗試再 次提交當前任務。
4. DiscardPolicy : 該策略默默地丟棄無法處理的任務,不予任何處理。如果允許任務丟 失,這是最好的一種方案。 以上內置拒絕策略均實現了 RejectedExecutionHandler 接口,若以上策略仍無法滿足實際 需要,完全可以自己擴展 RejectedExecutionHandler 接口。
4.1.13.4. Java 線程池工作過程
1. 線程池剛創建時,里面沒有一個線程。任務隊列是作為參數傳進來的。不過,就算隊列里面 有任務,線程池也不會馬上執行它們。
2. 當調用 execute() 方法添加一個任務時,線程池會做如下判斷:
a) 如果正在運行的線程數量小于 corePoolSize,那么馬上創建線程運行這個任務;
b) 如果正在運行的線程數量大于或等于 corePoolSize,那么將這個任務放入隊列;
c) 如果這時候隊列滿了,而且正在運行的線程數量小于 maximumPoolSize,那么還是要 創建非核心線程立刻運行這個任務;
d) 如果隊列滿了,而且正在運行的線程數量大于或等于 maximumPoolSize,那么線程池 會拋出異常 RejectExecutionException。
3. 當一個線程完成任務時,它會從隊列中取下一個任務來執行。
4. 當一個線程無事可做,超過一定的時間(keepAliveTime)時,線程池會判斷,如果當前運 行的線程數大于 corePoolSize,那么這個線程就被停掉。所以線程池的所有任務完成后,它 最終會收縮到 corePoolSize 的大小。
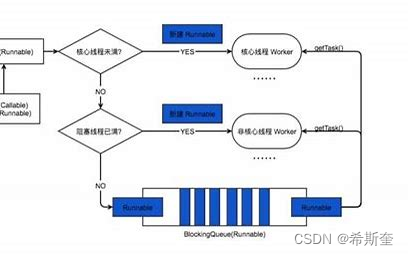
4.1.14. JAVA 阻塞隊列原理
阻塞隊列,關鍵字是阻塞,先理解阻塞的含義,在阻塞隊列中,線程阻塞有這樣的兩種情況:
1. 當隊列中沒有數據的情況下,消費者端的所有線程都會被自動阻塞(掛起),直到有數據放 入隊列。

2. 當隊列中填滿數據的情況下,生產者端的所有線程都會被自動阻塞(掛起),直到隊列中有 空的位置,線程被自動喚醒。
4.1.14.1. 阻塞隊列的主要方法:
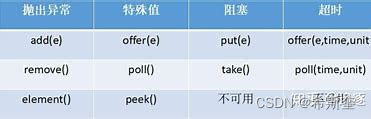
? 拋出異常:拋出一個異常;
? 特殊值:返回一個特殊值(null 或 false,視情況而定)
? 則塞:在成功操作之前,一直阻塞線程
? 超時:放棄前只在最大的時間內阻塞
插入操作:
1:public abstract boolean add(E paramE):將指定元素插入此隊列中(如果立即可行 且不會違反容量限制),成功時返回 true,如果當前沒有可用的空間,則拋 出 IllegalStateException。如果該元素是 NULL,則會拋出 NullPointerException 異常。
2:public abstract boolean offer(E paramE):將指定元素插入此隊列中(如果立即可行 且不會違反容量限制),成功時返回 true,如果當前沒有可用的空間,則返回 false。
3:public abstract void put(E paramE) throws InterruptedException: 將指定元素插 入此隊列中,將等待可用的空間(如果有必要)
public void put(E paramE) throws InterruptedException {checkNotNull(paramE);ReentrantLock localReentrantLock = this.lock;localReentrantLock.lockInterruptibly();try {while (this.count == this.items.length)this.notFull.await();//如果隊列滿了,則線程阻塞等待enqueue(paramE);localReentrantLock.unlock();} finally {localReentrantLock.unlock();}}4:offer(E o, long timeout, TimeUnit unit):可以設定等待的時間,如果在指定的時間 內,還不能往隊列中加入 BlockingQueue,則返回失敗。
獲取數據操作:
1:poll(time):取走 BlockingQueue 里排在首位的對象,若不能立即取出,則可以等 time 參數 規定的時間,取不到時返回 null;
2:poll(long timeout, TimeUnit unit):從 BlockingQueue 取出一個隊首的對象,如果在 指定時間內,隊列一旦有數據可取,則立即返回隊列中的數據。否則直到時間超時還沒有數 據可取,返回失敗。
3:take():取走 BlockingQueue 里排在首位的對象,若 BlockingQueue 為空,阻斷進入等待狀 態直到 BlockingQueue 有新的數據被加入。
4.drainTo():一次性從 BlockingQueue 獲取所有可用的數據對象(還可以指定獲取數據的個 數),通過該方法,可以提升獲取數據效率;不需要多次分批加鎖或釋放鎖。
4.1.14.2. Java 中的阻塞隊列
1. ArrayBlockingQueue :由數組結構組成的有界阻塞隊列。
2. LinkedBlockingQueue :由鏈表結構組成的有界阻塞隊列。
3. PriorityBlockingQueue :支持優先級排序的無界阻塞隊列。
4. DelayQueue:使用優先級隊列實現的無界阻塞隊列。
5. SynchronousQueue:不存儲元素的阻塞隊列。
6. LinkedTransferQueue:由鏈表結構組成的無界阻塞隊列。
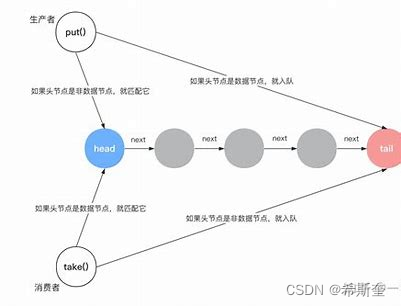
4.1.14.3. ArrayBlockingQueue(公平、非公平)
用數組實現的有界阻塞隊列。此隊列按照先進先出(FIFO)的原則對元素進行排序。默認情況下 不保證訪問者公平的訪問隊列,所謂公平訪問隊列是指阻塞的所有生產者線程或消費者線程,當 隊列可用時,可以按照阻塞的先后順序訪問隊列,即先阻塞的生產者線程,可以先往隊列里插入 元素,先阻塞的消費者線程,可以先從隊列里獲取元素。通常情況下為了保證公平性會降低吞吐 量。我們可以使用以下代碼創建一個公平的阻塞隊列:
ArrayBlockingQueue fairQueue = new ArrayBlockingQueue(1000,true);
4.1.14.4. LinkedBlockingQueue(兩個獨立鎖提高并發)
基于鏈表的阻塞隊列,同 ArrayListBlockingQueue 類似,此隊列按照先進先出(FIFO)的原則對 元素進行排序。而 LinkedBlockingQueue 之所以能夠高效的處理并發數據,還因為其對于生產者 端和消費者端分別采用了獨立的鎖來控制數據同步,這也意味著在高并發的情況下生產者和消費 者可以并行地操作隊列中的數據,以此來提高整個隊列的并發性能。 LinkedBlockingQueue 會默認一個類似無限大小的容量(Integer.MAX_VALUE)。
4.1.14.5. PriorityBlockingQueue(compareTo 排序實現優先)
是一個支持優先級的無界隊列。默認情況下元素采取自然順序升序排列。可以自定義實現 compareTo()方法來指定元素進行排序規則,或者初始化 PriorityBlockingQueue 時,指定構造 參數 Comparator 來對元素進行排序。需要注意的是不能保證同優先級元素的順序。
4.1.14.6. DelayQueue(緩存失效、定時任務 )
是一個支持延時獲取元素的無界阻塞隊列。隊列使用 PriorityQueue 來實現。隊列中的元素必須實 現 Delayed 接口,在創建元素時可以指定多久才能從隊列中獲取當前元素。只有在延遲期滿時才 能從隊列中提取元素。我們可以將 DelayQueue 運用在以下應用場景:
1. 緩存系統的設計:可以用 DelayQueue 保存緩存元素的有效期,使用一個線程循環查詢 DelayQueue,一旦能從 DelayQueue 中獲取元素時,表示緩存有效期到了。
2. 定時任務調度:使用 DelayQueue 保存當天將會執行的任務和執行時間,一旦從 DelayQueue 中獲取到任務就開始執行,從比如 TimerQueue 就是使用 DelayQueue 實現的。
4.1.14.7. SynchronousQueue(不存儲數據、可用于傳遞數據)
是一個不存儲元素的阻塞隊列。每一個 put 操作必須等待一個 take 操作,否則不能繼續添加元素。 SynchronousQueue 可以看成是一個傳球手,負責把生產者線程處理的數據直接傳遞給消費者線 程。隊列本身并不存儲任何元素,非常適合于傳遞性場景,比如在一個線程中使用的數據,傳遞給 另 外 一 個 線 程 使 用 , SynchronousQueue 的 吞 吐 量 高 于 LinkedBlockingQueue 和 ArrayBlockingQueue。
4.1.14.8. LinkedTransferQueue
是 一 個 由 鏈 表 結 構 組 成 的 無 界 阻 塞 TransferQueue 隊 列 。 相 對 于 其 他 阻 塞 隊 列 , LinkedTransferQueue 多了 tryTransfer 和 transfer 方法。
1. transfer 方法:如果當前有消費者正在等待接收元素(消費者使用 take()方法或帶時間限制的 poll()方法時),transfer 方法可以把生產者傳入的元素立刻 transfer(傳輸)給消費者。如 果沒有消費者在等待接收元素,transfer 方法會將元素存放在隊列的 tail 節點,并等到該元素 被消費者消費了才返回。
2. tryTransfer 方法。則是用來試探下生產者傳入的元素是否能直接傳給消費者。如果沒有消費 者等待接收元素,則返回 false。和 transfer 方法的區別是 tryTransfer 方法無論消費者是否 接收,方法立即返回。而 transfer 方法是必須等到消費者消費了才返回。
對于帶有時間限制的 tryTransfer(E e, long timeout, TimeUnit unit)方法,則是試圖把生產者傳 入的元素直接傳給消費者,但是如果沒有消費者消費該元素則等待指定的時間再返回,如果超時 還沒消費元素,則返回 false,如果在超時時間內消費了元素,則返回 true。
4.1.14.9. LinkedBlockingDeque
是一個由鏈表結構組成的雙向阻塞隊列。所謂雙向隊列指的你可以從隊列的兩端插入和移出元素。 雙端隊列因為多了一個操作隊列的入口,在多線程同時入隊時,也就減少了一半的競爭。相比其 他的阻塞隊列,LinkedBlockingDeque 多了 addFirst,addLast,offerFirst,offerLast, peekFirst,peekLast 等方法,以 First 單詞結尾的方法,表示插入,獲取(peek)或移除雙端隊 列的第一個元素。以 Last 單詞結尾的方法,表示插入,獲取或移除雙端隊列的最后一個元素。另 外插入方法 add 等同于 addLast,移除方法 remove 等效于 removeFirst。但是 take 方法卻等同 于 takeFirst,不知道是不是 Jdk 的 bug,使用時還是用帶有 First 和 Last 后綴的方法更清楚。 在初始化 LinkedBlockingDeque 時可以設置容量防止其過渡膨脹。另外雙向阻塞隊列可以運用在 “工作竊取”模式中。
4.1.15. CyclicBarrier、CountDownLatch、Semaphore 的用法
4.1.15.1. CountDownLatch(線程計數器 )
CountDownLatch 類位于 java.util.concurrent 包下,利用它可以實現類似計數器的功能。比如有 一個任務 A,它要等待其他 4 個任務執行完畢之后才能執行,此時就可以利用 CountDownLatch 來實現這種功能了。
final CountDownLatch latch = new CountDownLatch(2);new Thread(){public void run() {System.out.println("子線程"+Thread.currentThread().getName()+"正在執行");Thread.sleep(3000);System.out.println("子線程"+Thread.currentThread().getName()+"執行完畢");latch.countDown();
};}.start();
new Thread(){ public void run() {System.out.println("子線程"+Thread.currentThread().getName()+"正在執行");Thread.sleep(3000);System.out.println("子線程"+Thread.currentThread().getName()+"執行完畢");latch.countDown();
};}.start();
System.out.println("等待 2 個子線程執行完畢...");
latch.await();
System.out.println("2 個子線程已經執行完畢");
System.out.println("繼續執行主線程");
}4.1.15.2. CyclicBarrier(回環柵欄-等待至 barrier 狀態再全部同時執行)
字面意思回環柵欄,通過它可以實現讓一組線程等待至某個狀態之后再全部同時執行。叫做回環 是因為當所有等待線程都被釋放以后,CyclicBarrier 可以被重用。我們暫且把這個狀態就叫做 barrier,當調用 await()方法之后,線程就處于 barrier 了。 CyclicBarrier 中最重要的方法就是 await 方法,它有 2 個重載版本:
1. public int await():用來掛起當前線程,直至所有線程都到達 barrier 狀態再同時執行后續任 務;
2. public int await(long timeout, TimeUnit unit):讓這些線程等待至一定的時間,如果還有 線程沒有到達 barrier 狀態就直接讓到達 barrier 的線程執行后續任務。
具體使用如下,另外 CyclicBarrier 是可以重用的
public static void main(String[] args) {int N = 4;CyclicBarrier barrier = new CyclicBarrier(N);for(int i=0;i<N;i++)new Writer(barrier).start();}static class Writer extends Thread{private CyclicBarrier cyclicBarrier;public Writer(CyclicBarrier cyclicBarrier) {this.cyclicBarrier = cyclicBarrier;}@Overridepublic void run() {try {Thread.sleep(5000); //以睡眠來模擬線程需要預定寫入數據操作
System.out.println("線程"+Thread.currentThread().getName()+"寫入數據完
畢,等待其他線程寫入完畢");cyclicBarrier.await();} catch (InterruptedException e) {e.printStackTrace();}catch(BrokenBarrierException e){e.printStackTrace();}System.out.println("所有線程寫入完畢,繼續處理其他任務,比如數據操作");}}
4.1.15.3. Semaphore(信號量-控制同時訪問的線程個數)
Semaphore 翻譯成字面意思為 信號量,Semaphore 可以控制同時訪問的線程個數,通過 acquire() 獲取一個許可,如果沒有就等待,而 release() 釋放一個許可。 Semaphore 類中比較重要的幾個方法:
1. public void acquire(): 用來獲取一個許可,若無許可能夠獲得,則會一直等待,直到獲得許 可。
2. public void acquire(int permits):獲取 permits 個許可
3. public void release() { } :釋放許可。注意,在釋放許可之前,必須先獲獲得許可。
4. public void release(int permits) { }:釋放 permits 個許可
上面 4 個方法都會被阻塞,如果想立即得到執行結果,可以使用下面幾個方法
1. public boolean tryAcquire():嘗試獲取一個許可,若獲取成功,則立即返回 true,若獲取失 敗,則立即返回 false
2. public boolean tryAcquire(long timeout, TimeUnit unit):嘗試獲取一個許可,若在指定的 時間內獲取成功,則立即返回 true,否則則立即返回 false
3. public boolean tryAcquire(int permits):嘗試獲取 permits 個許可,若獲取成功,則立即返 回 true,若獲取失敗,則立即返回 false
4. public boolean tryAcquire(int permits, long timeout, TimeUnit unit): 嘗試獲取 permits 個許可,若在指定的時間內獲取成功,則立即返回 true,否則則立即返回 false
5. 還可以通過 availablePermits()方法得到可用的許可數目。
例子:若一個工廠有 5 臺機器,但是有 8 個工人,一臺機器同時只能被一個工人使用,只有使用完 了,其他工人才能繼續使用。那么我們就可以通過 Semaphore 來實現:
int N = 8; //工人數Semaphore semaphore = new Semaphore(5); //機器數目for(int i=0;i<N;i++)new Worker(i,semaphore).start();}static class Worker extends Thread{private int num;private Semaphore semaphore;public Worker(int num,Semaphore semaphore){this.num = num;this.semaphore = semaphore;}@Overridepublic void run() {try {semaphore.acquire();System.out.println("工人"+this.num+"占用一個機器在生產...");Thread.sleep(2000);System.out.println("工人"+this.num+"釋放出機器");semaphore.release();} catch (InterruptedException e) {e.printStackTrace();}
}
CountDownLatch 和 CyclicBarrier 都能夠實現線程之間的等待,只不過它們側重點不 同;CountDownLatch 一般用于某個線程 A 等待若干個其他線程執行完任務之后,它才執行;而 CyclicBarrier 一般用于一組線程互相等待至某個狀態,然后這一組線程再同時 執行;另外,CountDownLatch 是不能夠重用的,而 CyclicBarrier 是可以重用的。
Semaphore 其實和鎖有點類似,它一般用于控制對某組資源的訪問權限。
4.1.16. volatile 關鍵字的作用(變量可見性、禁止重排序)
Java 語言提供了一種稍弱的同步機制,即 volatile 變量,用來確保將變量的更新操作通知到其他 線程。volatile 變量具備兩種特性,volatile 變量不會被緩存在寄存器或者對其他處理器不可見的 地方,因此在讀取 volatile 類型的變量時總會返回最新寫入的值。
變量可見性
其一是保證該變量對所有線程可見,這里的可見性指的是當一個線程修改了變量的值,那么新的 值對于其他線程是可以立即獲取的。
禁止重排序
volatile 禁止了指令重排。 比 sychronized 更輕量級的同步鎖 在訪問 volatile 變量時不會執行加鎖操作,因此也就不會使執行線程阻塞,因此 volatile 變量是一 種比 sychronized 關鍵字更輕量級的同步機制。volatile 適合這種場景:一個變量被多個線程共 享,線程直接給這個變量賦值。
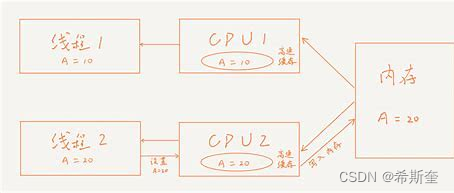
當對非 volatile 變量進行讀寫的時候,每個線程先從內存拷貝變量到 CPU 緩存中。如果計算機有 多個 CPU,每個線程可能在不同的 CPU 上被處理,這意味著每個線程可以拷貝到不同的 CPU cache 中。而聲明變量是 volatile 的,JVM 保證了每次讀變量都從內存中讀,跳過 CPU cache 這一步。
適用場景
值得說明的是對 volatile 變量的單次讀/寫操作可以保證原子性的,如 long 和 double 類型變量, 但是并不能保證 i++這種操作的原子性,因為本質上 i++是讀、寫兩次操作。在某些場景下可以 代替 Synchronized。但是,volatile 的不能完全取代 Synchronized 的位置,只有在一些特殊的場景下,才能適用 volatile。總的來說,必須同時滿足下面兩個條件才能保證在并發環境的線程安 全:
(1)對變量的寫操作不依賴于當前值(比如 i++),或者說是單純的變量賦值(boolean flag = true)。
(2)該變量沒有包含在具有其他變量的不變式中,也就是說,不同的 volatile 變量之間,不 能互相依賴。只有在狀態真正獨立于程序內其他內容時才能使用 volatile。

或者AOP @Before)




)




)







