文章目錄
- 1.進程地址空間回顧
- 1.1進程地址空間劃分
- 1.2驗證進程地址空間劃分
- 1.簡單劃分
- 2.完整劃分
- 2.初探進程地址空間
- 2.1初看現象
- 2.2Makefile的簡便寫法
- 3.進程地址空間詳解
- 3.1地址空間是什么?
- 3.2地址空間的設計/由來
- 3.3空間區域劃分
- 3.4如何理解地址空間?
- 3.5解釋3.2的🐂🐎現象和fork()函數的返回值
- 3.6linux命令行的指令
- 4.可執行程序運行的底層
- 4.1linux下查看反匯編
- 4.2了解底層
- 5.為什么要大費周折設計地址空間?
- 5.1[地址空間+頁表]對進程的非法訪問進行有效攔截==>有效地保護了物理內存
- 5.2將內存管理模塊和進程管理模塊解耦合 提升內存利用率
- 5.35地址空間和頁表實現了進程的獨立性
- 6.對掛起狀態的理解
- 6.1上篇博客的初識
- 6.2通過程序運行理解掛起狀態

1.進程地址空間回顧
1.1進程地址空間劃分
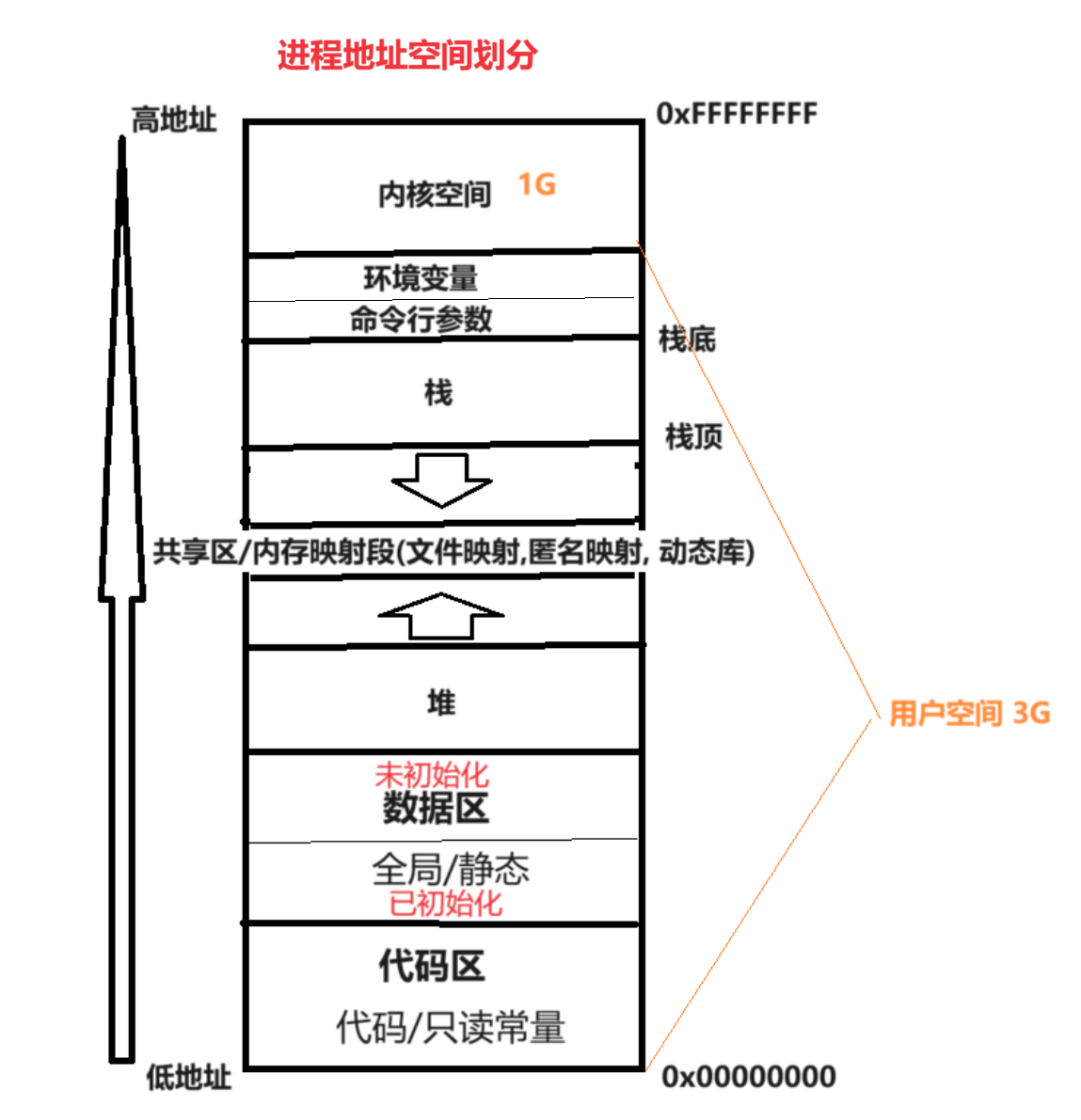
1.2驗證進程地址空間劃分
1.簡單劃分
- 一個C/C++程序 編譯后形成的可執行程序 是一個二進制文件 在Linux下
./test是程序運行之后打印的 本質理解: 程序運行后執行的cout/printf實際上是進程在輸出數據 - 堆和棧相對而生
2.完整劃分
對程序的理解
1. int a = 10;
把字面常量10放到局部變量a
2. 單純的字面常量放在代碼李可以編譯通過如:
"hello linux";
100;
'a';
驗證程序地址空間劃分
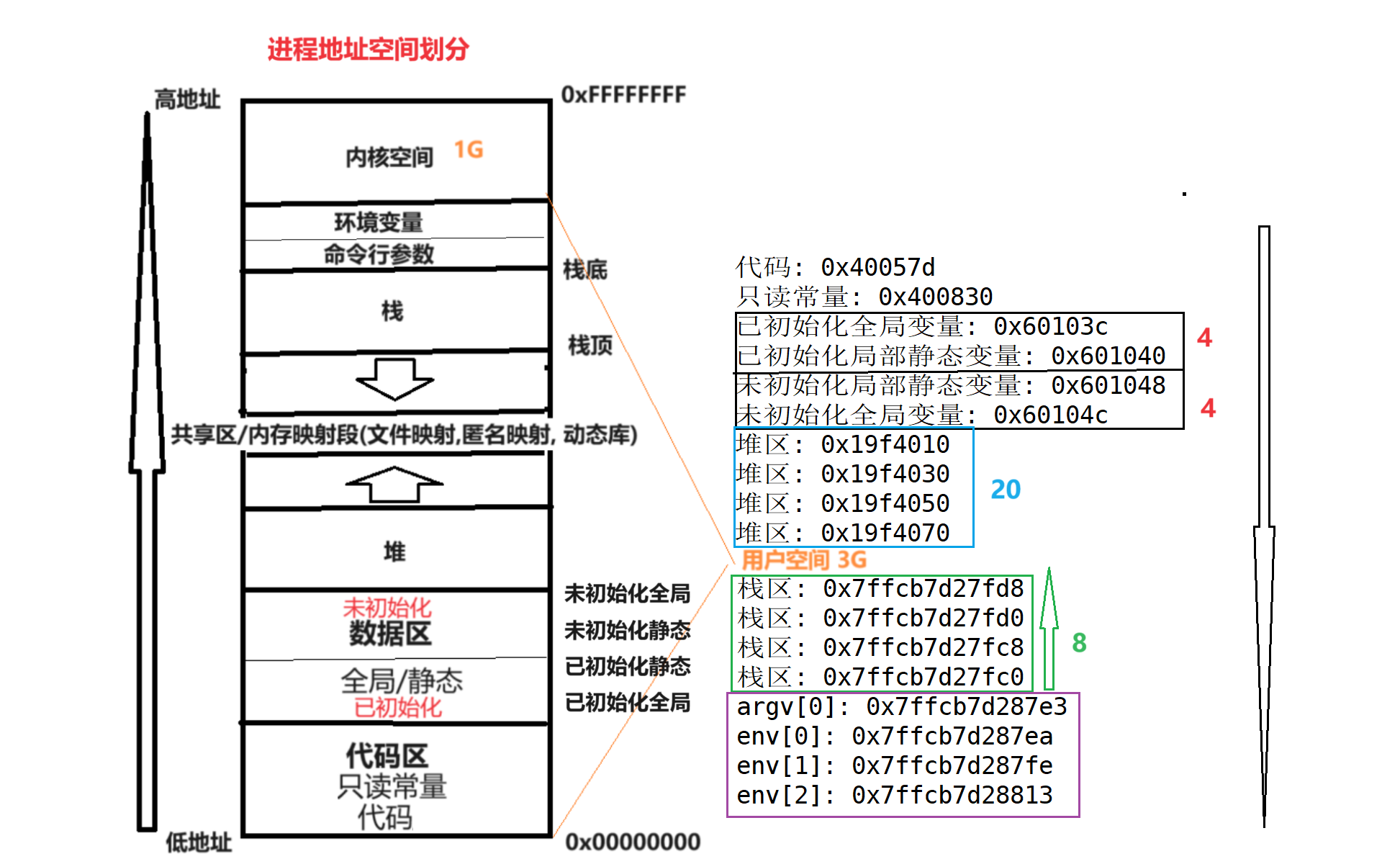
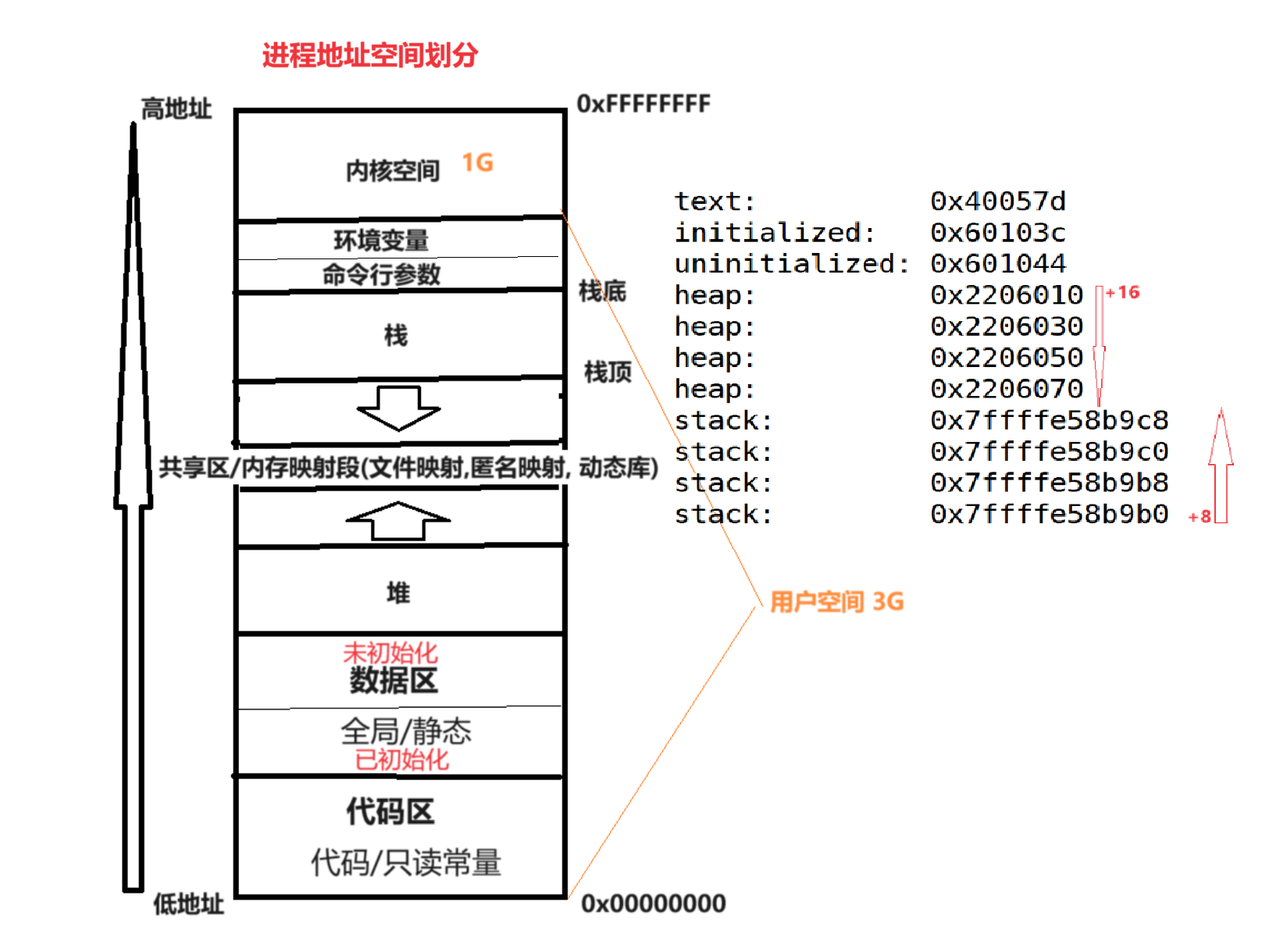
在堆區申請了一塊空間 1. 釋放時為什么只用將空間首地址傳給free() 2. 差值為什么多了10個?
堆區申請x個字節 實際上c標準庫給當前程序申請的比x多 多出來的空間 用來存儲此次申請的屬性信息 稱作"Cokkie" 餅干數據 用來記錄 什么時間申請的 申請的空間多大 等 上圖中堆區數據字節差值為20也驗證了這句話
總結:
- 32位下,一個進程的地址空間,取值范圍是0x0000 0000 ~ 0xFFFF FFFF
[0,3GB]: 用戶空間
[3GB,4GB]:內核空間 - 上面的結論,默認只在linux有效 [在windows下會跑出不一樣的結果 windows注重地址安全 增加了一些自己的設計
2.初探進程地址空間
2.1初看現象
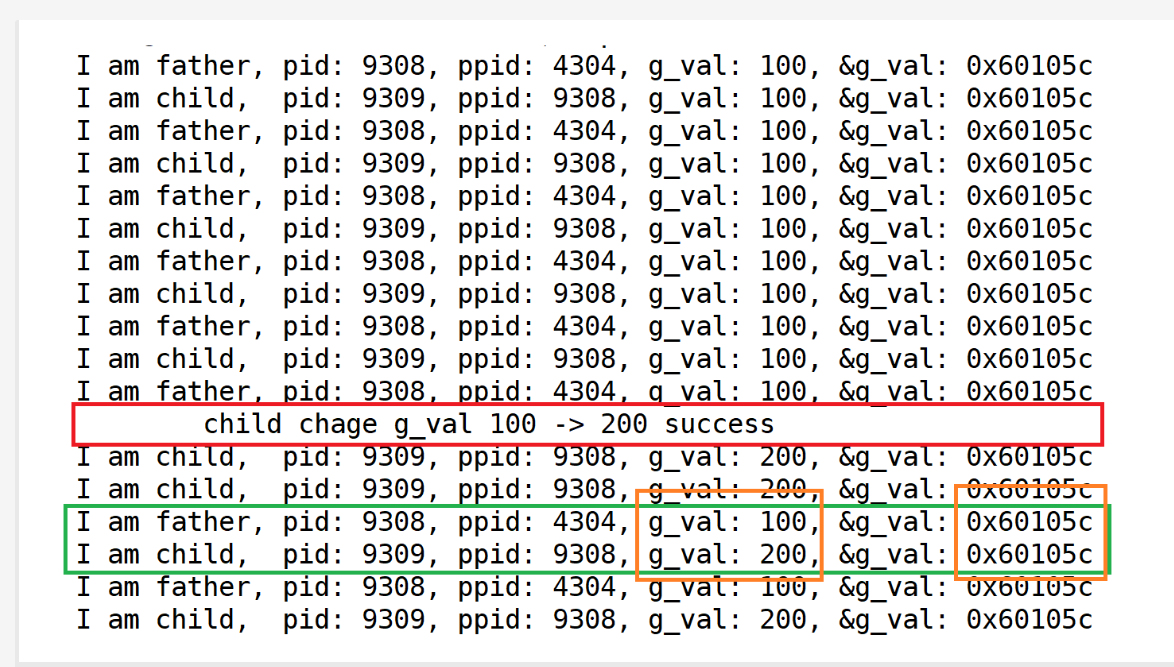
來看一個比較牛馬的場景
#include <stdio.h>
#include <unistd.h>int g_val = 100;int main()
{pid_t id = fork();if(id == 0){int cnt = 0;//childwhile(1){printf("I am child, pid: %d, ppid: %d, g_val: %d, &g_val: %p\n",\getpid(), getppid(), g_val, &g_val);sleep(1);cnt++;if(cnt == 5){g_val = 200;printf(" child chage g_val 100 -> 200 success\n");}}}else {//fatherwhile(1){printf("I am father, pid: %d, ppid: %d, g_val: %d, &g_val: %p\n",\getpid(), getppid(), g_val, &g_val);sleep(1);}}
}同時訪問同一個地址出現了不同的值[在3.5解釋]
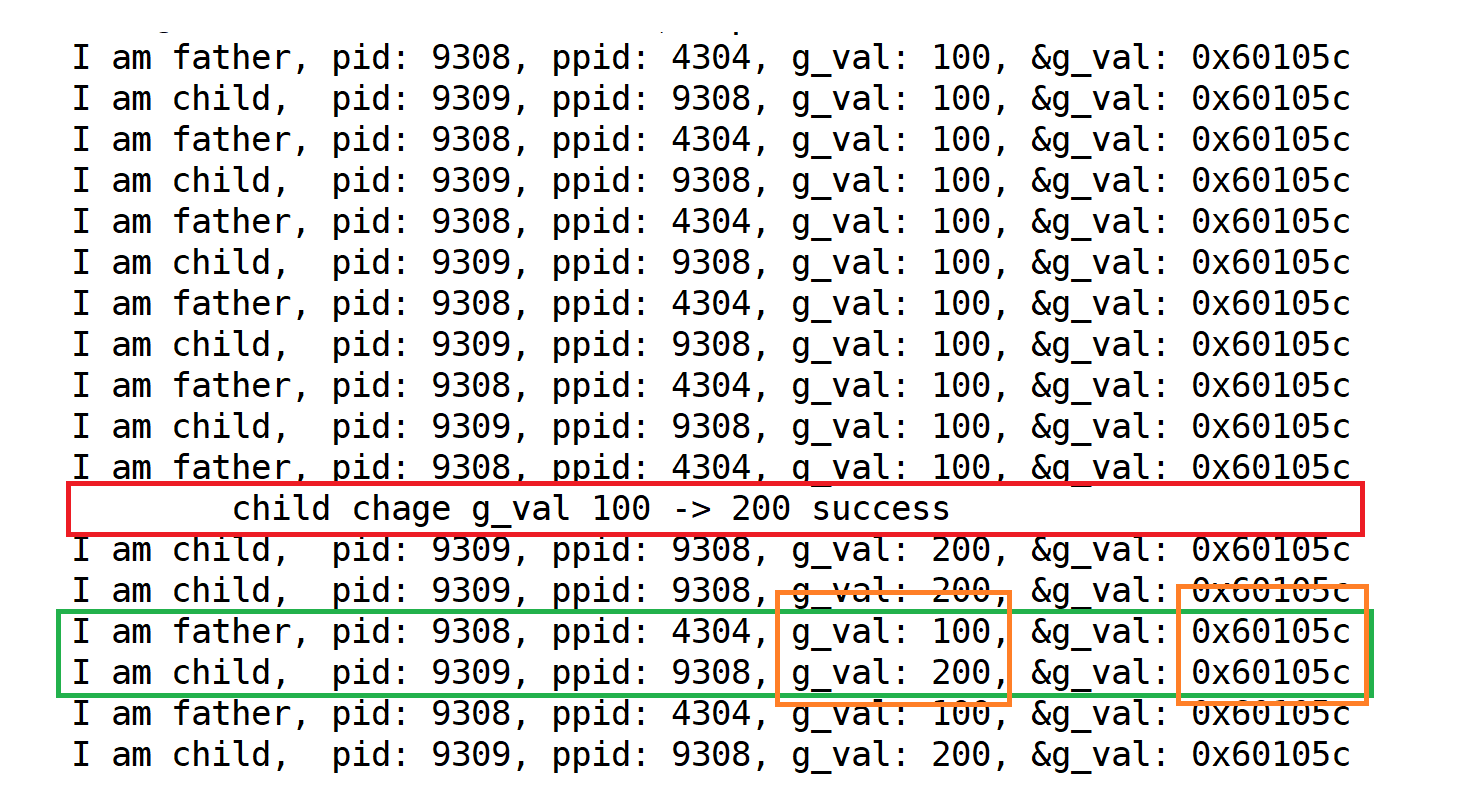
由此得出結論 這里的地址絕對不是物理內存的地址!那他是什么🐂🐎?
- 這個🐂🐎是是虛擬地址/線性地址
- 之前學到的編程語言中的
"地址"概念不是物理地址而是虛擬地址 - OS不讓用戶直接訪問物理地址 — 新手上路會犯錯破壞內存 通過虛擬地址來保護
拓展知識
磁盤/網卡/顯卡等外設也有寄存器 外設保存數據的寄存器可以稱為端口/串口[硬件級別]

了解虛擬地址

邏輯地址

線性地址


2.2Makefile的簡便寫法
Makefile格式: target : prerequisties 目標文件: 先決條件
hello:hello.c hello.c1 hello.c2gcc -o $@ $^
$@: 依賴方法對應的依賴關系中的目標文件即hello
$^: 所有的依賴文件 即hello.c hello.c1 hello.c2這一堆文件
$< 第一個依賴文件 即hello.c
$? 比目標還要新的依賴文件列表
3.進程地址空間詳解
3.1地址空間是什么?


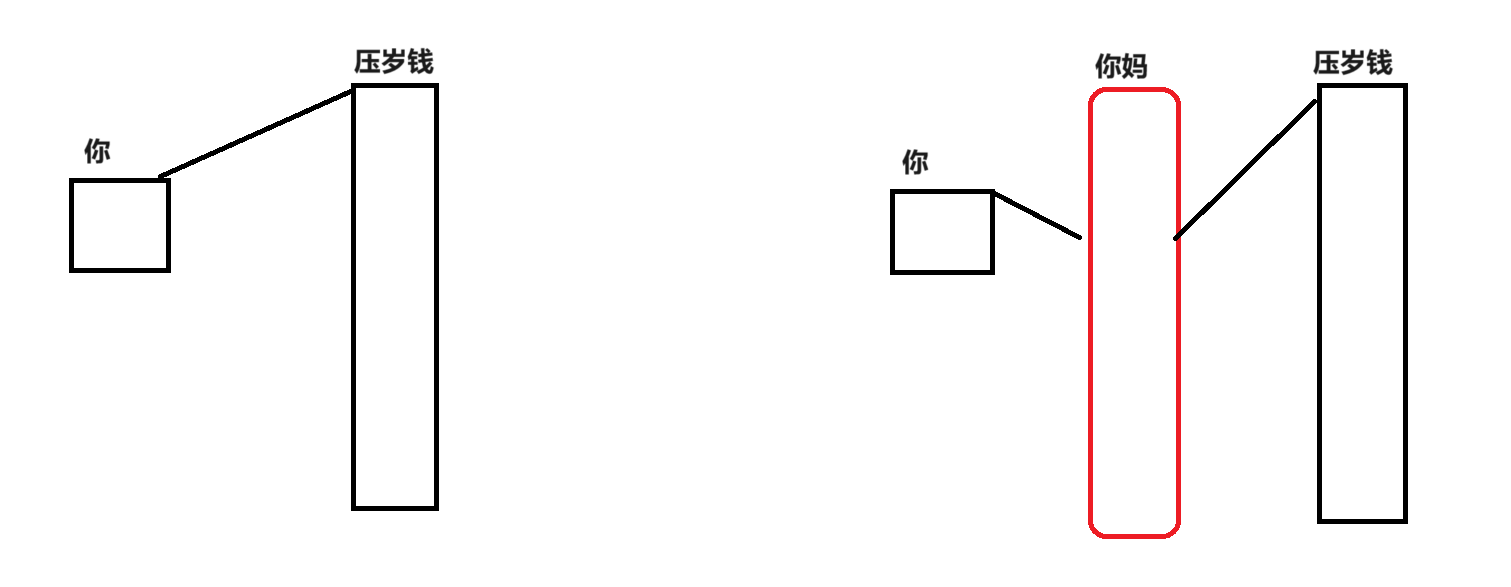
富翁有10億 底下有三個私生子 三個私生子互不知道對方的存在 富翁對他們三人分別承諾 他死后10億就是他的 三人分別相信了 在富翁還存活時 三人找他要錢用 富翁也會給 但是如果要得太多 比如一次要了一億 富翁就不給了 因為沒有正當用途等原因
富翁 – OS 私生子 – 進程 老爹畫的餅 – 地址空間
要注意的是:
內核中的地址空間 當未來和某一進程聯系起來時 它實際上也是一種數據結構 因為他要對進程進行描述組織 即 富翁/OS 要對他畫的餅/地址空間 進行組織 否則餅/進程太多了可能會露餡
3.2地址空間的設計/由來
我們首先要了解 計算機早期的設計是直接訪問物理內存的 后來才引入了 線性地址/虛擬地址 顯而易見引入虛擬地址是為了讓計算機更好的工作 無論是安全問題或者是效率問題 看下面這種情況 就可以了解直接訪問物理內存是極其危險的!
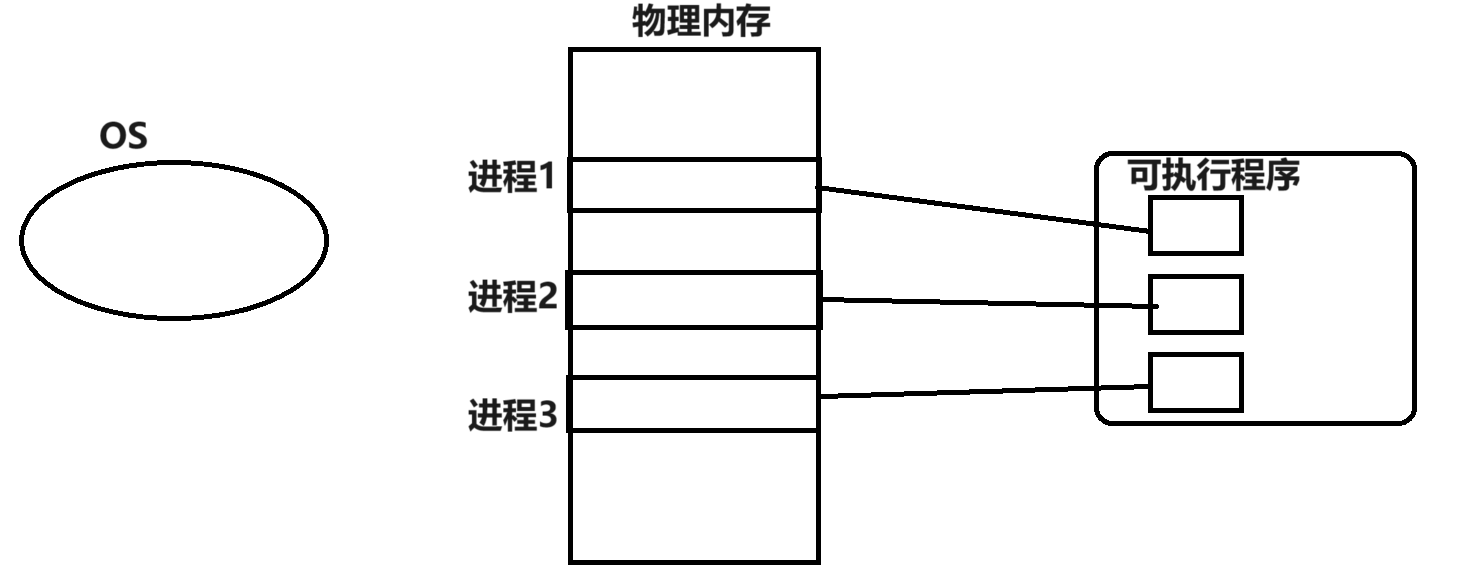
- 假設進程1中有一個野指針
int* p = 亂碼進程1要對指針p進行訪問/修改/刪除操作 而這個指針恰好指向了進程2/3所在的內存 那么此時就芭比Q了[內存本身可以隨時被讀寫] - 進程2是一個合法的正在運行的程序 一個hacker自己寫了一個程序 在物理內存上運行 若此時進程2執行了讓用戶輸入密碼的操作 那么進程1可以通過在進程2中的相同地址處設一個指針接收 此時 hacker就獲得了密碼 這不徹底完蛋
- 進程1/2/3并不是一個個緊挨著的 此時就會有內存碎片問題 假設現在進程4來了 但是沒有足夠的地方 而實際上所有的碎片加起來是有地方的 那么OS就不得不把進程1/2/3再一個個挨著放 — 效率低下
上述這些問題的原因: 直接訪問的是物理內存 對應的就是物理地址 現代計算機怎么設計的呢?
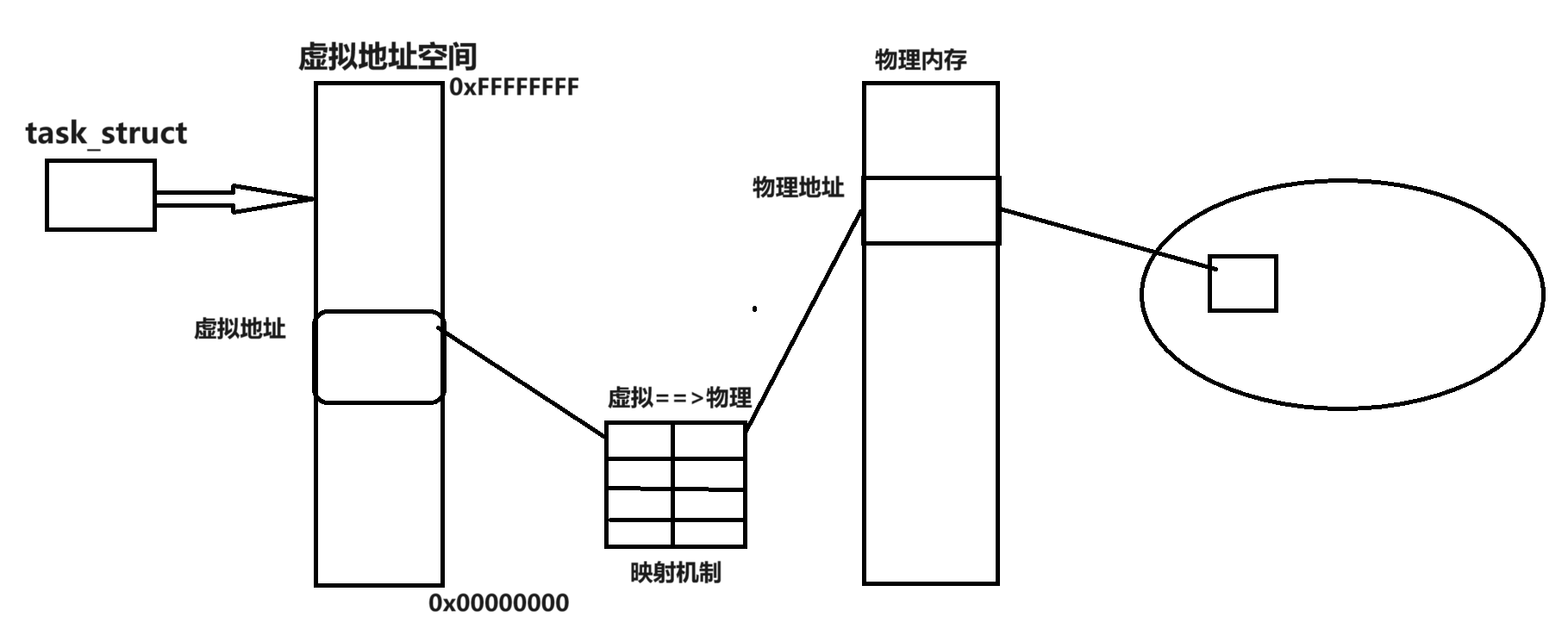
- 通過某種映射機制不直接訪問物理內存
- 當虛擬地址是一個非法地址 禁止映射去訪問物理內存
3.3空間區域劃分
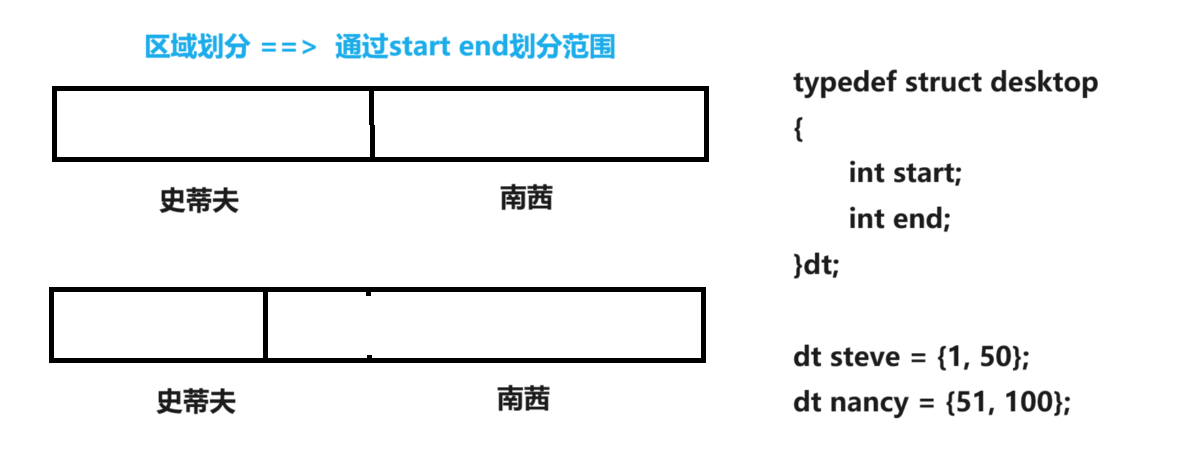
源碼

3.4如何理解地址空間?
地址空間是一種內核數據結構 它里面要有各個區域的劃分
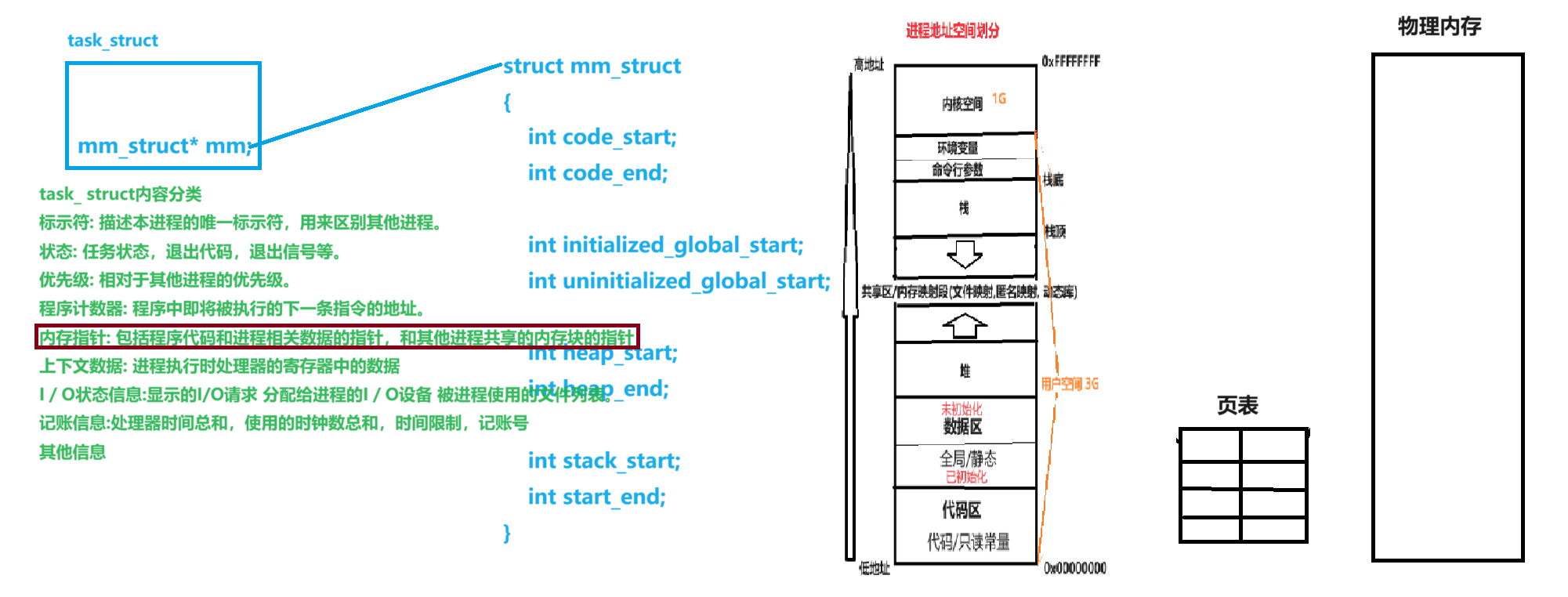
- 每一個進程的頁表映射的是物理內存的不同區域 這樣保證了進程之間不相互干擾 保證進程之間的獨立性
- 每一個進程都有自己的地址空間和頁表
3.5解釋3.2的🐂🐎現象和fork()函數的返回值
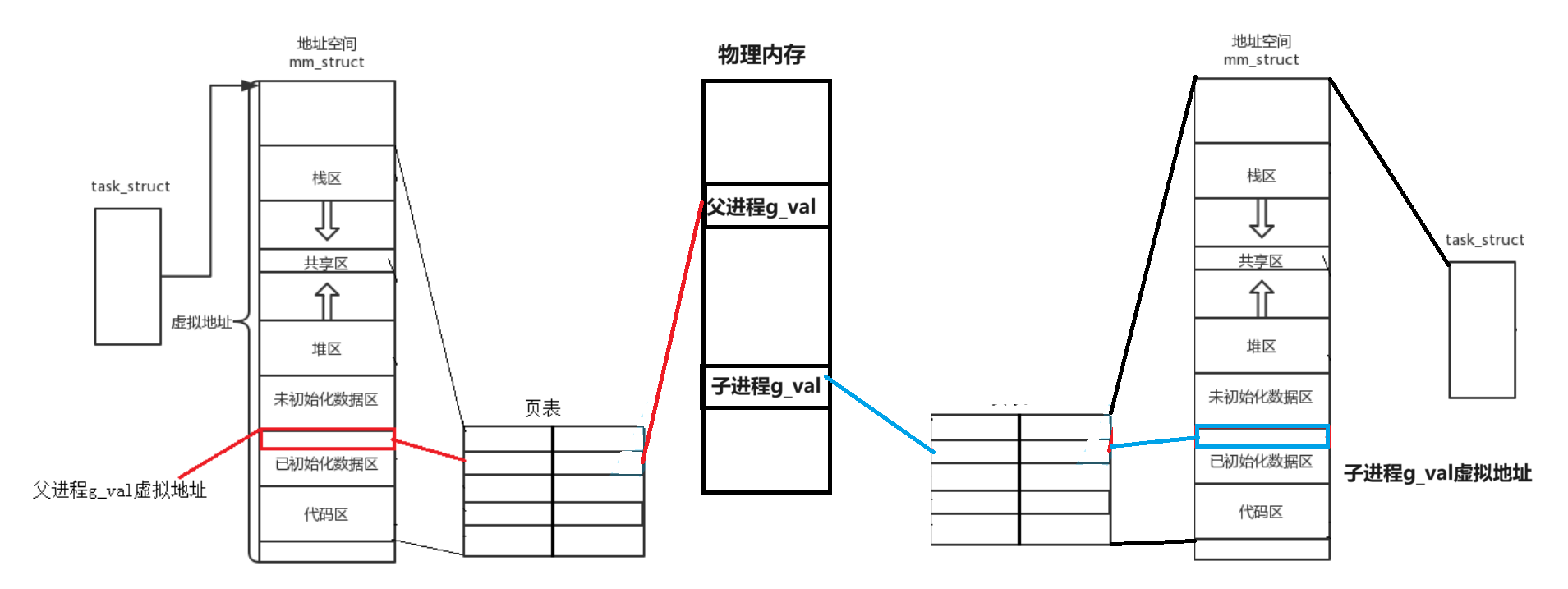
- 子進程的PCB大部分和父進程相同 少部分自己修改獨有 val在父子進程的虛擬地址相同 映射機制相同
- 父子進程中的變量的虛擬地址相同 如果不發生拷貝 子進程的變量和父進程的變量在物理內存中是同一塊空間
- 如果發生拷貝 此時在內存中當場為val開辟一塊內存 用來存子進程新的值 這個過程叫寫時拷貝 寫時拷貝的優勢在于 如果不發生拷貝 既符合虛擬地址的設計又不浪費空間
- 這就是為什么相同的地址(虛擬地址)有不同的值(不同的物理地址對應的不同值)
- 地址相同: 打印的地址是虛擬地址 值不同: 映射機制被改 子進程的值指向了自己的變量空間
解釋之前講的fork()函數一個返回值同時保存兩個不同的值的問題
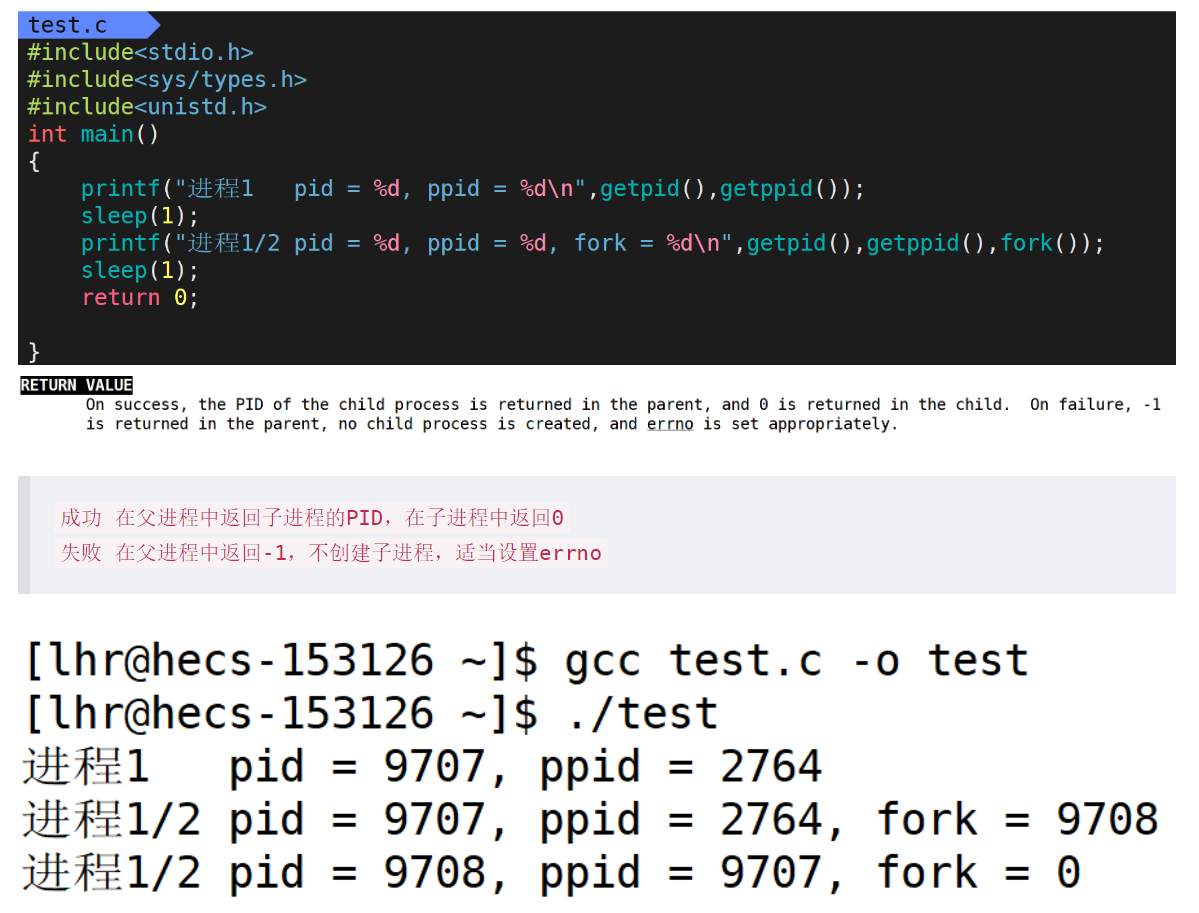
pid_t fork()
{//創建子進程return id;
}
pid_t Id = fork();
- 在
return id;之前 子進程已經被創建出來 父子進程分別return 自己代碼的id值 return id;在fork()函數即將返回 執行return語句時 對Id值進行修改/寫入 ===> 發生寫時拷貝- 父子進程在物理內存中有各自的屬于自己的變量空間 在用戶層用同一個變量/虛擬地址來標識
3.6linux命令行的指令
readelf的用法
readelf是一個Linux下的命令行工具,用于查看ELF格式的目標文件或可執行文件的信息。ELF(Executable and Linkable Format)是一種常見的二進制文件格式,用于在Linux系統中表示可執行文件、共享庫、目標文件等。使用readelf命令可以查看這些文件的頭部、節區、符號表、重定位表等信息。以下是readelf命令的一些常用選項和用法:
- 查看目標文件的頭部信息:
readelf -h <file>
- 查看目標文件的節區信息:
readelf -S <file>
- 查看目標文件的符號表信息:
readelf -s <file>
- 查看目標文件的重定位表信息:
readelf -r <file>
- 查看目標文件的動態符號表信息:
readelf -d <file>
- 查看目標文件的字符串表信息:
readelf -p <section_name> <file>
例如,要查看可執行文件ls的頭部信息,可以使用以下命令:
readelf -h /bin/ls
objdump的用法
objdump是一個二進制文件反匯編工具,可以用于查看二進制文件的匯編代碼、符號表、重定位表等信息。在Linux下,可以使用objdump命令來進行反匯編操作。以下是一些常用的objdump命令:
- 查看二進制文件的匯編代碼
objdump -d <binary_file>
其中,-d表示反匯編操作,<binary_file>表示要反匯編的二進制文件。
- 查看二進制文件的符號表
objdump -t <binary_file>
其中,-t表示查看符號表。
- 查看二進制文件的重定位表
objdump -r <binary_file>
其中,-r表示查看重定位表。
- 查看二進制文件的頭部信息
objdump -x <binary_file>
其中,-x表示查看頭部信息。
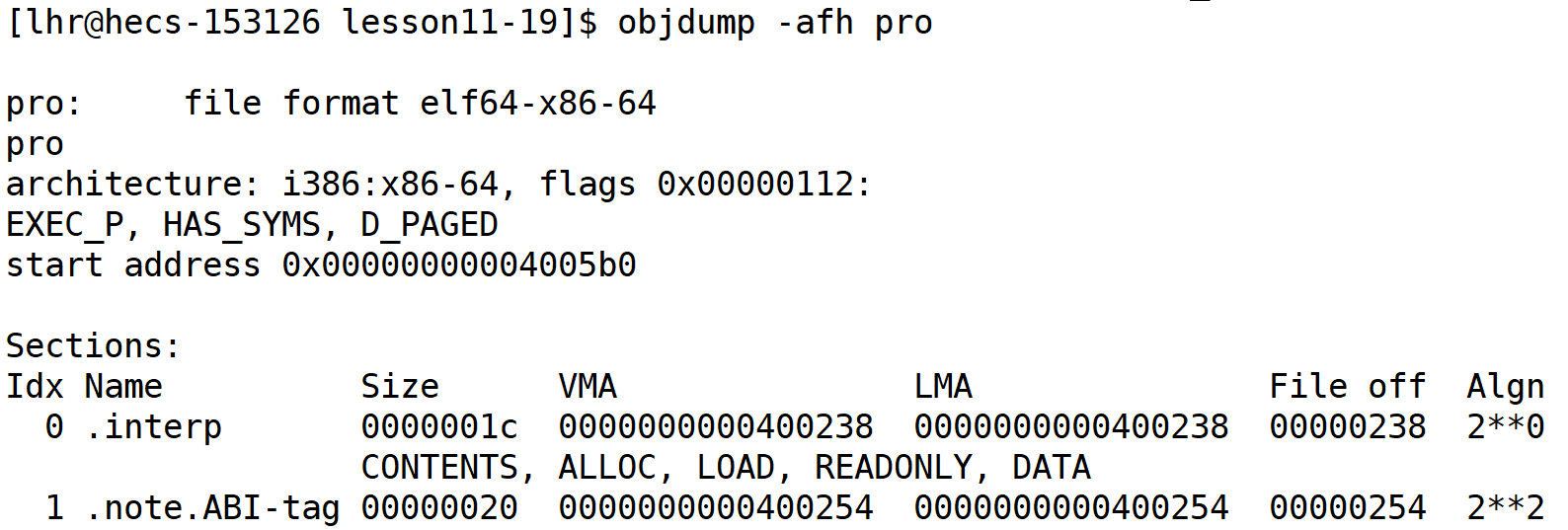
objdump是一個二進制文件分析工具,可以用來查看二進制文件的匯編代碼、符號表、重定位表等信息。-a選項表示顯示所有信息,-f選項表示顯示文件頭信息,-h選項表示顯示節頭信息。
在Linux中,可以使用以下命令來查看二進制文件的所有信息:
objdump -afh <filename>
其中,<filename>是要查看的二進制文件的文件名。執行該命令后,會輸出該二進制文件的所有信息,包括文件頭信息、節頭信息、符號表、重定位表等。
舉個例子,如果要查看可執行文件/bin/ls的所有信息,可以執行以下命令:
objdump -afh /bin/ls
4.可執行程序運行的底層
4.1linux下查看反匯編
程序編譯形成可執行程序 沒有加載到內存時 在程序內部實際上已經有地址 – 可執行程序編譯時內部已經有地址

4.2了解底層
- 地址空間不僅OS內部遵守,編譯器也要遵守!
- 編譯器編譯代碼的時候,已經形成了各個區域: 代碼區,數據區 堆區 棧區…
- 采用和Linux內核中一樣的編址方式,給每一個變量,每一行代碼都進行了編址
- 程序在編譯的時候,每一個字段(所有的代碼和數據)早已經具有了一個虛擬地址
- 當可執行程序加載到內存時 每行代碼/變量/函數便具有了一個外部物理地址
- CPU讀取每一條執行時 指令內部也有地址 這個地址是虛擬地址
- 每一個變量/函數 都有一個編譯器給出的虛擬地址 虛擬地址連同代碼加載到了內存中
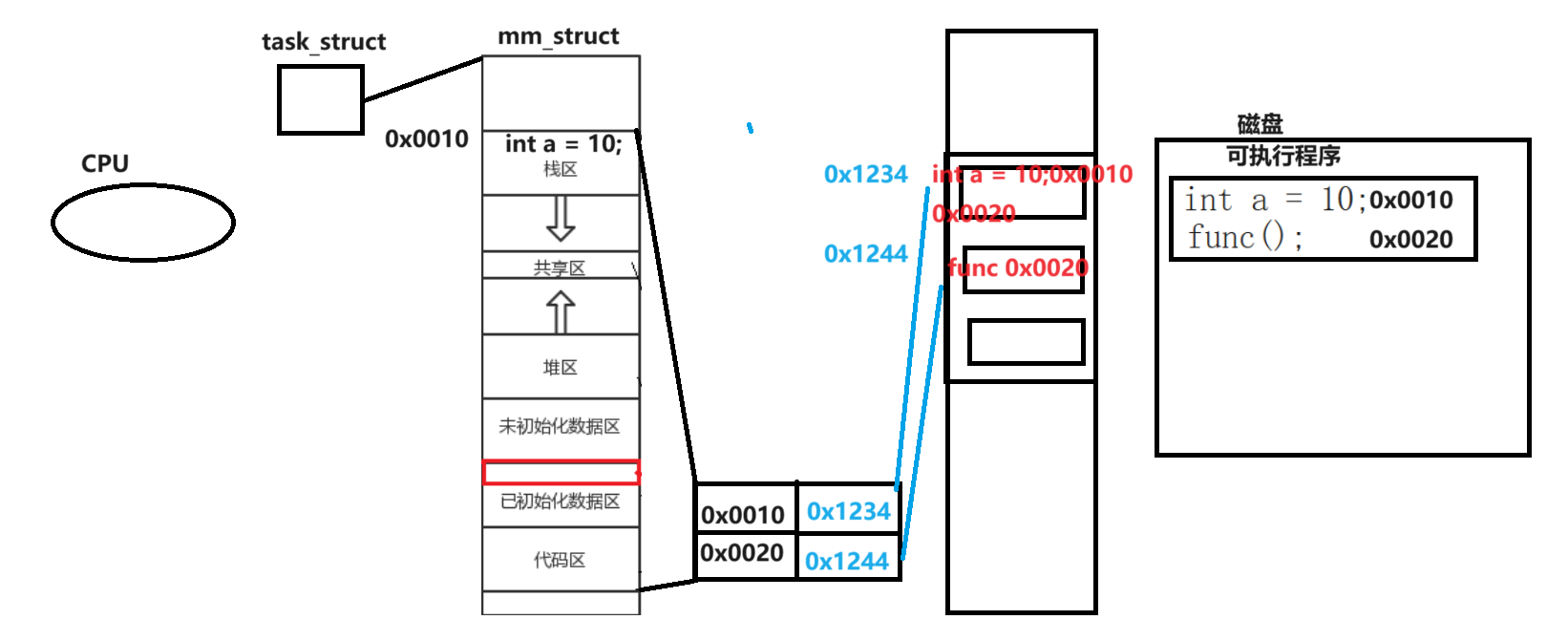
- 可執行程序運行 進入main函數 在虛擬地址(mm_struct)將0x0010到0x0019作為棧的start和end 變量a的虛擬地址為0x0010 其他亦然 將虛擬地址放在頁表左側 根據映射機制 映射一個物理地址作為變量a在物理內存的位置 物理地址放在頁表右側
- 假設訪問完函數A后訪問函數B 根據函數A的虛擬地址訪問物理內存上的函數A 獲取函數B的虛擬地址 按照虛擬地址查找頁表 獲取函數B的物理地址 (頁表底層和哈希表相似
- 程序在編譯的鏈接階段鏈接動態庫實際上是在代碼中拷貝了庫函數/調用接口的地址 依據地址去訪問
- 這樣CPU每次拿到的都是虛擬地址
- 地址空間: OS為進程設計的一種看待內存/外設的一種方案
5.為什么要大費周折設計地址空間?
5.1[地址空間+頁表]對進程的非法訪問進行有效攔截==>有效地保護了物理內存
- 對于非法的訪問或映射 OS會識別并終止此進程 [代碼運行后成為進程 由于代碼寫的不對 進程崩潰 即進程退出 實際上是OS殺死了這個不正確/不合法的進程]
- 地址空間和頁表是OS創建并維護的 想使用地址空間和頁表進行映射 要在OS的監管之下來進行訪問
- 保護了物理內存中的所有的合法數據(各個進程,內核相關有效數據)
什么叫非法的訪問/映射?
int main()
{char* str = "hello linux!\n";*str = 'H';
明顯上述代碼會報錯 str存在于棧上 字符串存在只讀常量區 不可修改 頁表不僅會把虛擬地址映射為物理地址 還會有權限的檢查 如果不具有寫的權限 就終止 內存可以隨時任意讀寫 地址空間和頁表的存在使得它不在可以那么隨意了!
5.2將內存管理模塊和進程管理模塊解耦合 提升內存利用率
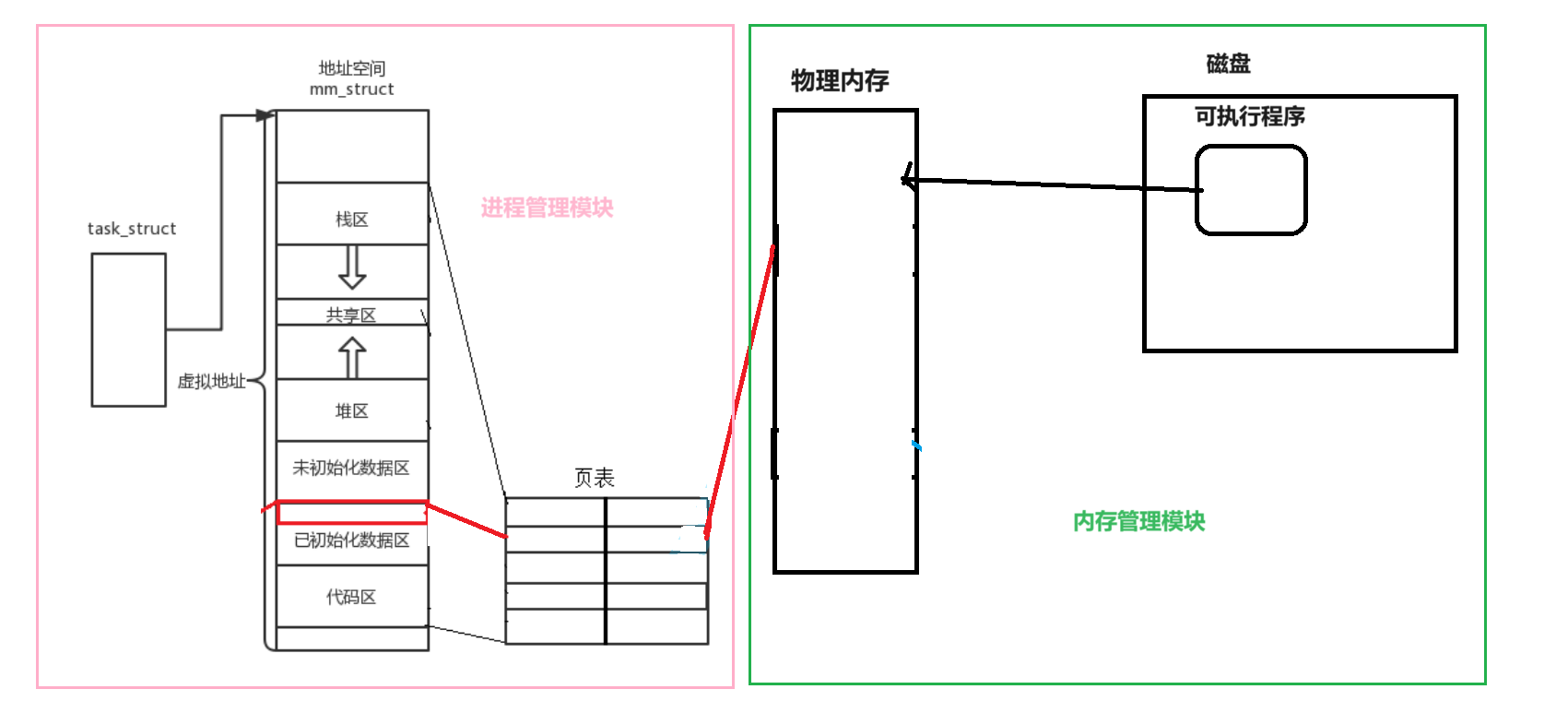
地址空間 + 頁表的映射 使得在物理內存中可以對未來加入內存的數據進行任意位置的加載(前提是有空間) 使得物理內存分配就和進程管理的工作分離 即內存管理模塊和進程管理模塊完成了解耦合
C/C++語言中父進程malloc/new空間時,本質是在虛擬地址空間申請的 優勢:
-
代碼寫完形成可執行程序 這個程序可能不是馬上運行 如果在寫代碼或者形成可執行程序時就為其申請了空間 那么程序不運行它不用這個空間 別的程序也沒法用 這是一種極大的浪費 且 會造成效率大大降低
-
有地址空間的存在,上層申請空間是在地址空間上申請的,物理內存可以/甚至一個字節都不給(此時的申請的空間其實壓根就不是空間只不過是編譯器按照進程地址空間劃分為每一句代碼都生成了虛擬地址申請的空間也為他們生成了虛擬地址 當這個程序運行成為進程時通過映射才會真正的去物理內存申請空間)
-
當進行對物理地址空間訪問的時候,才執行內存的相關管理算法缺頁中斷==>[操作系統自動完成用戶和進程,完全0感知]然后在進行內存的訪問
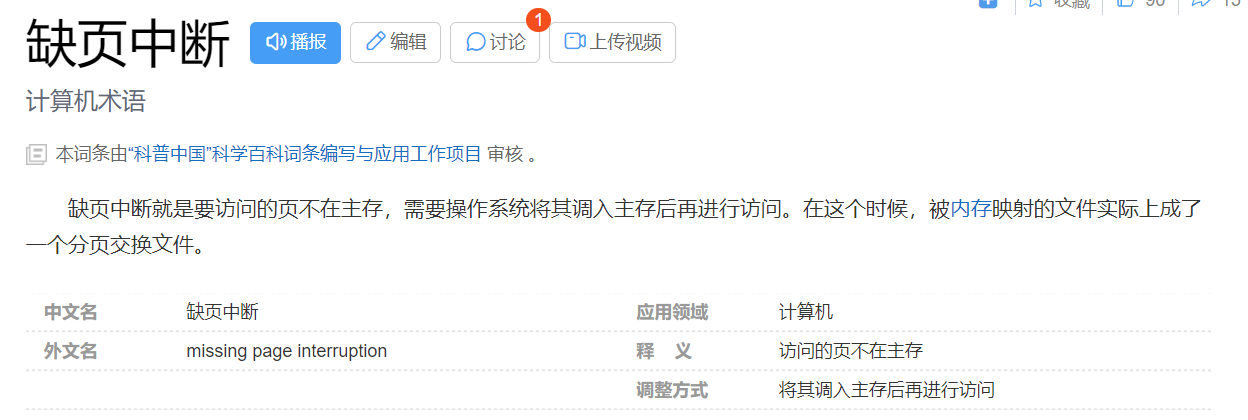
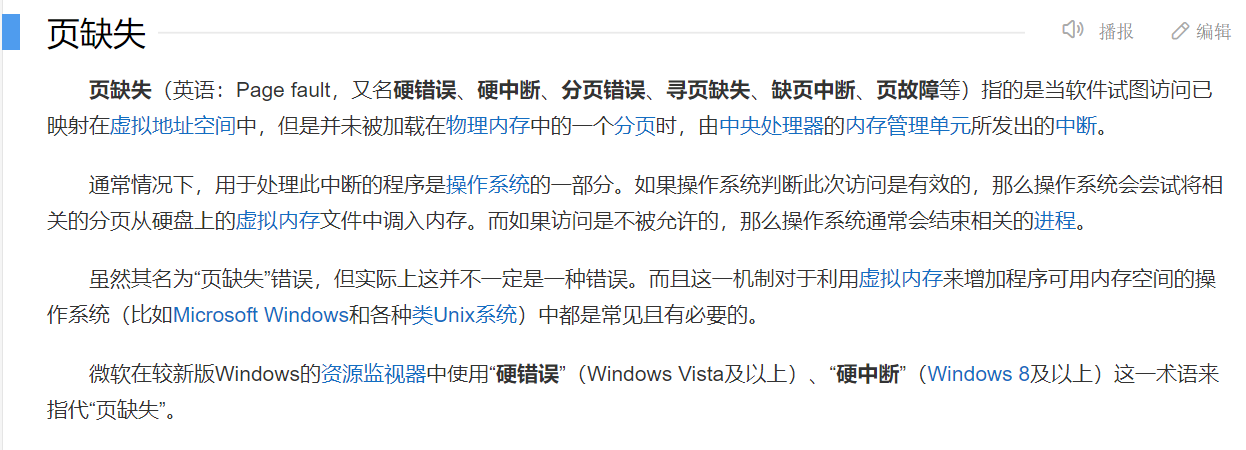
-
申請了物理空間,不立馬使用是空間的浪費 通過延遲分配的策略來提高整機的效率 使得內存的有效使用幾乎100%
5.35地址空間和頁表實現了進程的獨立性
- 理論上 物理內存可以對未來加入內存的數據進行任意位置的加載 那么實際上物理內存中的幾乎所有數據和代碼在內存中是亂序的
- 頁表將地址空間上的虛擬地址和物理地址進行映射,在進程的視角下 內存分布是有序的 即地址空間+頁表將內存的分布有序化
- 進程要訪問的物理內存中的數據和代碼,可能目前并沒有在物理內存中,頁表可以讓不同的進程映射到不同的物理內存,即實現了進程獨立性(不干擾其他進程+不知道有其他進程的存在)
- 地址空間的存在使得每一個進程都認為自己擁有 各個區域是有序的4GB空間(32位) ,不同的進程通過頁表映射到不同的區域,實現了進程的獨立性 每一個進程不知道也不需要知道其他進程的存在
6.對掛起狀態的理解
6.1上篇博客的初識
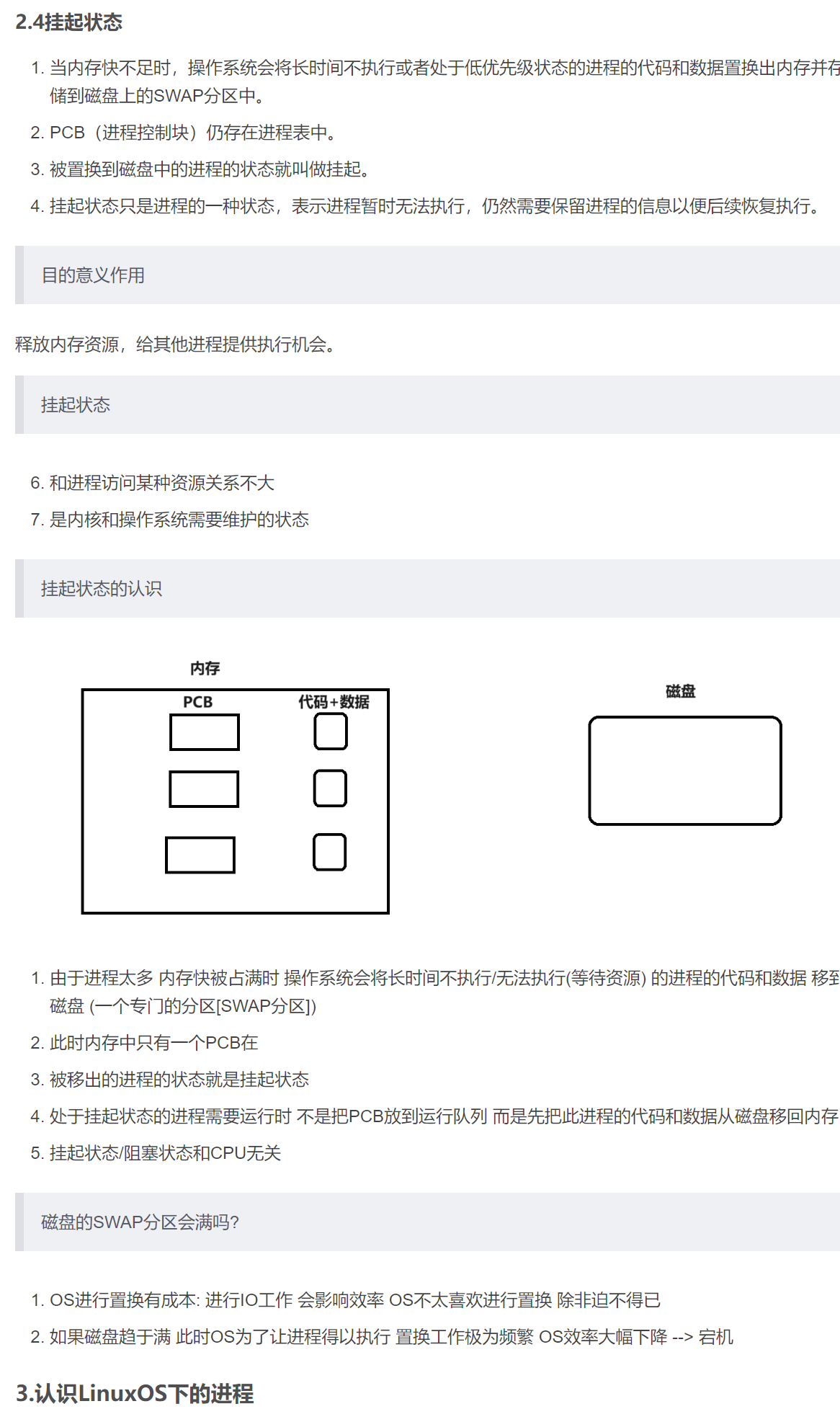
6.2通過程序運行理解掛起狀態
- 前面我們講到
進程 = 進程內核數據結構(PCB) + 進程對應的磁盤上的可執行程序(代碼+數據)現在我們了解到進程內核數據結構不僅僅有task_struct還有task_struct內的mm_struct* mm指針指向的mm_struct現在我們對進程的認識是進程 = 進程內核數據結構task_struct/mm_struct/頁表 + 進程對應的磁盤上的可執行程序(代碼+數據) - 程序是存放在磁盤上的,創建一個進程不是一開始就把所有的數據全部加載到內存里的,如果寫了一百萬行代碼,程序大小4個G,結果運行的代碼就幾十行,把整個程序加載到內存中就是浪費內存
- 把代碼和數據加載到內存本質就是創建進程 但是創建進程不是立馬就把程序的所有代碼和數據都加載到了內存中也不是立馬創建內核數據結果建立映射關系 極端情況下 只有內核數據結構
task_struct/mm_struct被創建出來了 頁表映射關系/代碼和數據加載到內存 工作都沒有完成 這個只創建了task_struct/mm_struct的狀態叫新建狀態當真正運行這個程序時 代碼和數據才被加載到內存 - 理論上 可以實現對程序的分批加載 既然可以分批加載/換入(將磁盤上的代碼和數據換入到內存) 那么也就可以分批換出 當這個進程短時間不會被執行如阻塞狀態(需要等待某種資源: 網絡 磁盤…) 這個進程的代碼和數據 就可以被換出以節省空間讓急于執行的/準備好的進程的代碼和數據換入 被換出代碼和數據的進程的狀態叫掛起狀態











|LeetCode416. 分割等和子集)

![[Docker]九.Docker compose講解](http://pic.xiahunao.cn/[Docker]九.Docker compose講解)

)



——基于jrtplib實現tcp被動和主動發流)