精讀視頻:雙流網絡論文逐段精讀【論文精讀】_嗶哩嗶哩_bilibili
Two-Stream Convolutional Networks for Action Recognition in Videos
傳統的神經網絡難以學習到物體的運動信息,雙流網絡則通過光流將物體運動信息抽取出來再傳遞給神經網絡 給模型提供先驗信息,再讓網絡學習動作和輸出的映射關系
其他論文:deep video
- Spatial stream ConvNet:空間流神經網絡,關注 appearance 信息,輸入是單幀圖片 輸出分類概率,從靜止圖像中做動作識別 是圖像分類任務,可以預訓練
- Temporal stream ConvNet:時間流神經網絡,關注 motion information,輸入一系列光流(optical flow)圖片 輸出也是分類概率
- 兩者分類概率取加權平均 得到最終預測

光流網絡
光流
每兩張圖片得到一張光流 四張連續幀得到三個光流,分為水平運動和垂直運動的兩維光流,每個像素點都有對應光流值

兩種疊加光流圖片輸入到神經網絡的方法
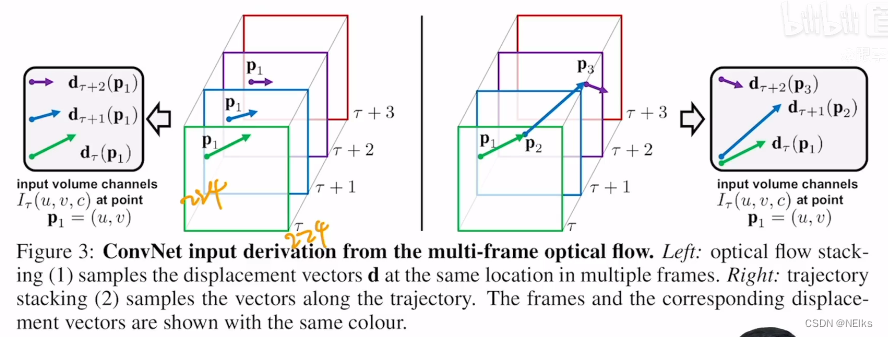
方法一:左邊的圖,直接堆疊,在每張圖同樣位置的像素點處詢問該點的運動軌跡
方法二:根據像素點的軌跡,下一幀運動到另一點 再從那一點繼續
Bi-directional optical flow 雙向光流
上述兩種方法都是前向的光流計算,而光流反過來計算也是可以的
作者把一個視頻的前半段用于計算前向光流,后半段計算反向光流
光流網絡的輸入
空間流網絡:輸入 channel = 3,RGB三通道
時間流網絡:L+1 張連續單幀圖像得到 L 張光流圖,輸入的 channel 數是 2L,光流圖的疊加是先疊加水平、后疊加豎直方向的光流位移
實現細節
測試部分

- 不論視頻多長,等間隔抽取 25 幀
- 空間流:對每一幀,取四角和中心得到5張圖,將該幀翻轉過來后同樣操作,共計得到10張;25幀則共250張圖,都經過空間流神經網絡得到結果
- 時間流:對每一幀都往后取11幀圖 抽取得到10張光流圖
如何預處理和計算光流

每一幀、每個像素點都有光流值,處理需要的時間空間都太大,所以進行壓縮:把光流值壓縮到0~255且變成整數,并把光流存成JPEG圖片形式 光流圖變小了


有效的括號)


)
:后悔藥 - 撤銷變更)

)




學習筆記)


)


