目標:建立對大數據生態的整體認知,理解HDFS和MapReduce的核心思想。
8:00-9:30:【視頻學習】在B站搜索“Hadoop入門”或“三小時入門大數據”,觀看1-2個高播放量的簡介視頻,了解大數據面臨的問題和Hadoop的解決方案。

大數據技術入門精講(Hadoop+Spark)_嗶哩嗶哩_bilibili
 大數據典型應用場景及架構改進_嗶哩嗶哩_bilibili
大數據典型應用場景及架構改進_嗶哩嗶哩_bilibili

大數據誕生背景與核心概念總結
一、大數據的誕生:解決傳統架構的瓶頸
大數據技術并非憑空出現,而是為了解決傳統數據處理架構在數據量達到海量規模(如PB級)后所面臨的瓶頸而誕生的。
-
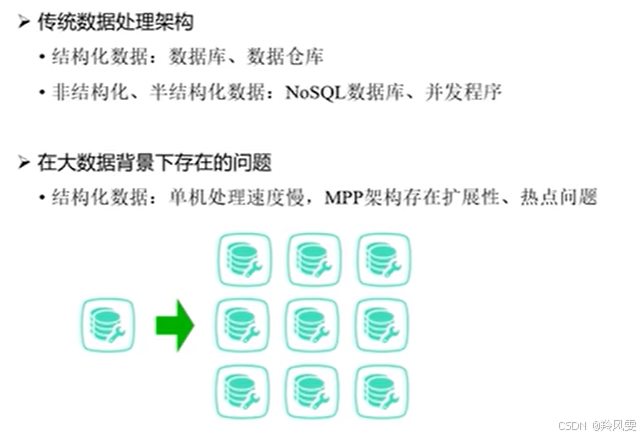
傳統結構化數據處理(數據庫/數據倉庫)的瓶頸:
-
存儲瓶頸:單機數據庫無法存儲海量數據。
-
性能瓶頸:即使能存下,查詢和計算速度也會變得極慢。
-
擴展性瓶頸:采用MPP架構的集群(如Oracle RAC)存在擴展上限(通常到幾十個節點就無法再擴展),且存在熱點問題(負載不均衡)。
-
-
傳統非/半結構化數據處理(NoSQL數據庫)的瓶頸:
-
計算與存儲分離:NoSQL數據庫(如MongoDB)擅長存儲海量非結構化數據,但不擅長計算。
-
網絡開銷巨大:計算時需要將海量數據從存儲節點通過網絡拉到計算節點,當數據量達到TB/PB級時,網絡傳輸成為巨大瓶頸,效率極低。
-
因此,迫切需要一整套能同時解決海量數據(無論結構如何)的【存儲】與【計算】問題,并且具備無限擴展能力的方案。這就是大數據技術誕生的根本原因。
二、大數據的定義
大數據是一門專門用于對海量規模的數據(包括結構化、半結構化和非結構化數據)進行存儲和計算的技術或架構。
-
核心目的:存得下、算得快、可擴展。
-
處理范圍:它不僅處理傳統數據庫擅長的結構化數據,更擅長處理互聯網時代占比更高的半結構化(如日志、JSON)和非結構化數據(如圖片、視頻、音頻)。
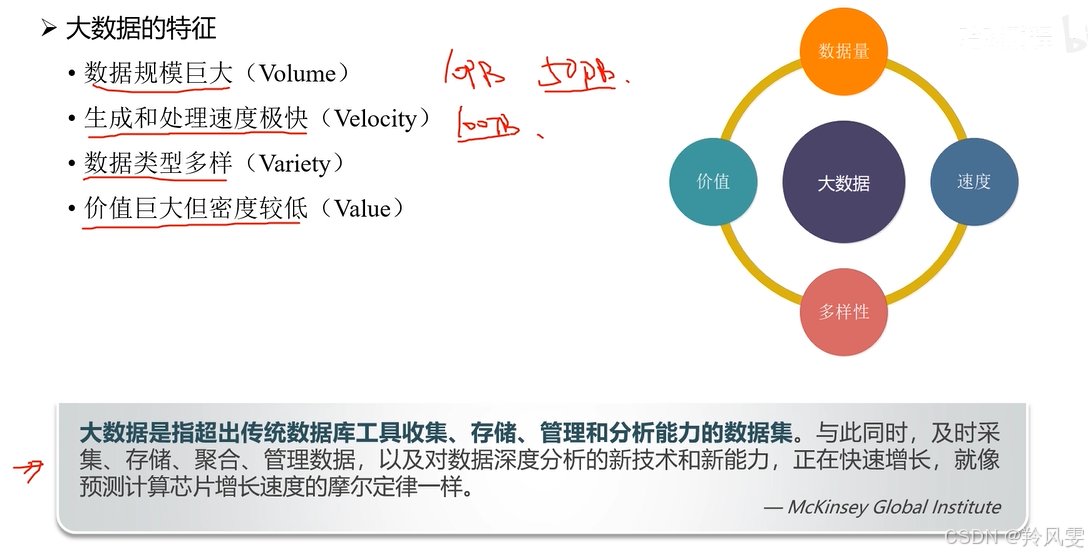
三、大數據的4V特征
滿足以下四個特征的數據場景,我們稱之為大數據場景。這四個特征英文首字母都是“V”,故稱4V特性。
-
Volume(大量):數據體量巨大。這是最基本的特征,數據量從TB級別躍升到PB、EB甚至ZB級別。
-
Velocity(高速):數據生成和處理的速度快。數據在不斷高速產生(例如每日新增TB級數據),同時也要求系統能快速處理并給出結果。
-
Variety(多樣):數據類型繁多。大數據處理的數據類型包括:
-
結構化數據(傳統數據庫表)
-
半結構化數據(日志、JSON、XML)
-
非結構化數據(圖片、視頻、音頻、文本)
互聯網中,非結構和半結構化數據的占比更高。
-
-
Value(低價值密度):價值密度低。這是大數據中一個非常關鍵的特點。
-
總價值高:海量數據中蘊含的總體價值巨大,能挖掘出很多潛在規律,與AI結合能產生巨大效益。
-
密度低:單位數據(如一條記錄或一個文件)所蘊含的價值很低。就像淘金,金礦的總含金量很高(價值高),但礦石中的金元素分布非常稀疏(密度低),需要強大的技術進行“提純”和“挖掘”才能獲得價值。
-
簡單來說,大數據就是為解決“數據又多、又快、又雜、而且像金礦一樣需要提煉”這些問題而出現的一整套技術方案。
轉型大數據,要在恰當的時機_嗶哩嗶哩_bilibili
轉型大數據,時機要恰當
一、核心誕生背景:解決海量數據瓶頸
大數據技術誕生的根本原因是傳統數據處理架構(單機數據庫、MPP數據庫、NoSQL)在數據量達到PB級海量規模后,在存儲和計算上遇到了無法克服的瓶頸。大數據就是為了解決這些瓶頸而出現的一整套技術方案。
二、【極其重要的補充】:不要盲目使用大數據
您補充的這一點非常關鍵,是實踐中最容易犯的錯誤,也是區分工程師是否真正理解大數據的關鍵。
-
核心原則:技術選型要匹配數據規模。
-
中小規模數據(如TB級以下):
-
首選傳統架構,如單機MySQL/PostgreSQL、MPP數據庫、或NoSQL數據庫。它們完全能夠勝任,且效率更高、架構更簡單、運維更輕松。
-
-
為什么大數據對中小數據效率反而低?
-
大數據框架(如Hadoop/Spark)為分布式而生,本身有較高的調度開銷(啟動任務、協調節點、數據分發等)。處理小數據時,調度開銷可能遠大于實際計算時間,導致“殺雞用牛刀”,效果反而更差。
-
-
何時應考慮引入大數據技術?
-
當傳統架構確實出現明顯瓶頸時,例如:
-
存儲層面:數據量巨大,單機或傳統集群已經存不下了。
-
計算層面:作業運行時間過長,無法滿足業務時效性要求(比如一個報表跑一天都跑不完)。
-
擴展性層面:現有系統無法再通過增加硬件來線性提升性能(達到了MPP的擴展上限)。
-
-
結論:大數據是“不得已而為之”的解決方案,而不是為了追求技術時髦。一定要根據實際業務數據和性能需求進行評估選型。
三、大數據的基本概念:一句話總結
忘掉復雜冗長的定義,記住最核心的一句話:
大數據是一門專門用于對海量規模的數據進行存儲和計算的技術生態。
-
目標:解決海量數據的存儲與計算問題。
-
形態:它是一個技術生態,包含HDFS、YARN、Spark、Hive、Kafka等眾多組件,而非單一產品。
四、區分:“大數據技術” vs “大數據場景(4V特性)”
這是一個容易混淆的點,您做了很好的區分:
-
大數據技術:指的是解決方案和工具,即我們上面說的“技術生態”。它是手段。
-
大數據場景(4V特性):指的是數據本身所具有的特征,用來描述和判斷一個問題是否屬于大數據問題。它是前提和特征。
-
Volume(大量):數據體量大。
-
Velocity(高速):數據增長和處理速度快。
-
Variety(多樣):數據類型多(結構、半結構、非結構)。
-
Value(低價值密度):數據價值高但密度低,需要挖掘。
-
簡單來說:當一個應用場景具備了4V特征,我們就需要采用大數據技術來解決它。
如何區分大數據離線與實時場景_嗶哩嗶哩_bilibili
離線?實時?——取決于:數據是否有界
批處理,流處理
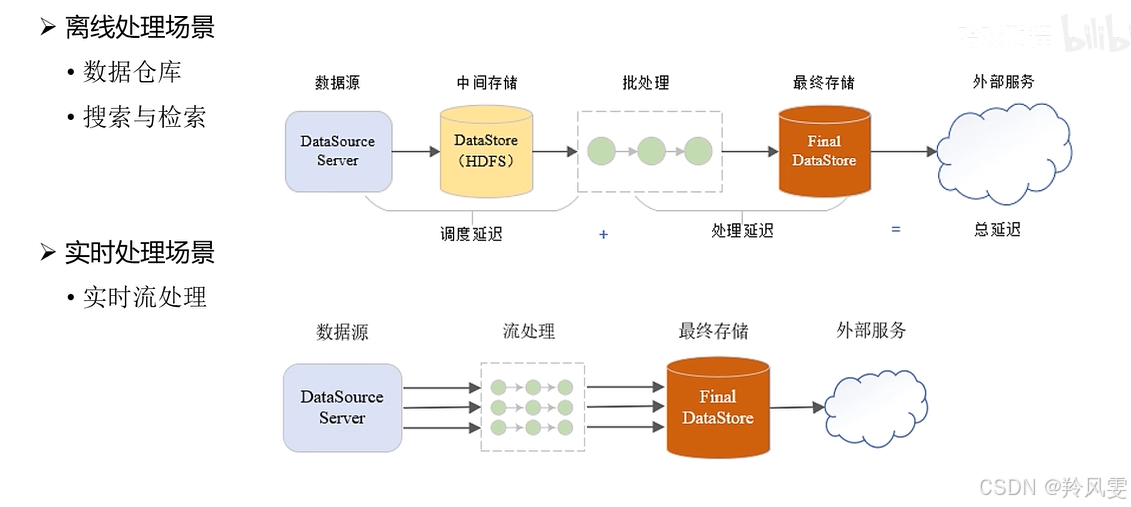
大數據兩大應用場景:離線處理和實時處理
大數據處理的所有應用場景,歸根結底可以劃分為兩大類:離線處理和實時處理。理解它們的本質區別至關重要。
一、核心區別:數據邊界
離線和實時最根本的區別不是速度快慢,而是它們所處理數據的本質不同。
| 特性 | 離線處理 (Offline Processing) | 實時處理 (Real-time Processing) |
|---|---|---|
| 數據本質 | 有界數據 (Bounded Data) | 無界數據 (Unbounded Data) |
| 核心概念 | 處理已經存儲好的、完整的、不會再變更的數據集。例如:處理昨天產生的全部10GB日志文件。 | 處理持續不斷生成的、沒有盡頭的數據流。例如:處理正在源源不斷產生的用戶點擊流。 |
| 類比 | 處理一本已經寫完并裝訂成冊的書。 | 處理一個永不結束的現場直播信號。 |
| 網絡依賴 | 數據處理任務可以脫離網絡進行(因為數據已全部就位)。 | 必須持續在線,一旦中斷就會丟失數據或導致結果不準確。 |
二、處理方式:批處理 vs. 流處理
不同的數據本質,自然需要不同的處理方式。
| 特性 | 批處理 (Batch Processing) | 流處理 (Stream Processing) |
|---|---|---|
| 對應場景 | 離線處理場景的默認選擇。 | 實時處理場景的默認選擇。 |
| 工作模式 | 階段式處理:將所有數據作為一個整體,先完成第一階段的所有計算,再將全部結果送入下一階段。在任意時刻,所有數據都處于同一個處理階段。 | 流水線式處理:像工廠流水線,數據像零件一樣逐個或逐小批地流過每個處理階段。每個階段處理完立刻發送給下一階段。在任意時刻,數據分布在各個不同的處理階段。 |
| 目標 | 計算全局的、最終準確的結果。注重吞吐量(一次處理的數據總量)。 | 計算近似的、快速及時的結果。注重低延遲(處理一條數據的耗時)。 |
簡單比喻:
-
批處理:洗衣服時,攢夠一桶再統一扔進洗衣機清洗。追求的是“省水省電”(高吞吐)。
-
流處理:洗碗時,來一個臟盤子就立刻沖干凈放好。追求的是“隨時有干凈盤子用”(低延遲)。
三、典型應用場景
-
離線批處理場景 (Offline Batch)
-
數據倉庫:每天凌晨定時計算前一天的各類業務報表。
-
數據分析與挖掘:對歷史全量數據進行復雜的統計分析、訓練機器學習模型。
-
搜索與檢索的索引構建:定期全量掃描數據,重新構建搜索引擎的索引。
-
-
實時流處理場景 (Real-time Streaming)
-
實時監控與預警:實時監控系統日志,發現錯誤立即告警;實時監控金融交易,發現欺詐行為。
-
實時推薦系統:根據用戶當前的點擊和行為,實時推薦可能感興趣的商品或內容。
-
實時大屏:雙十一的實時成交額大屏,數據不斷滾動更新。
-
核心結論
-
劃分標準:用數據是有界還是無界來區分離線和實時,而不是速度。
-
技術選型:處理有界數據(離線)用批處理框架(如MapReduce, Spark);處理無界數據(實時)用流處理框架(如Flink, Spark Streaming)。
-
價值導向:離線求“準”,追求最終結果的全局準確性;實時求“快”,追求結果的即時性。
大數據典型應用場景及架構改進_嗶哩嗶哩_bilibili
離線場景
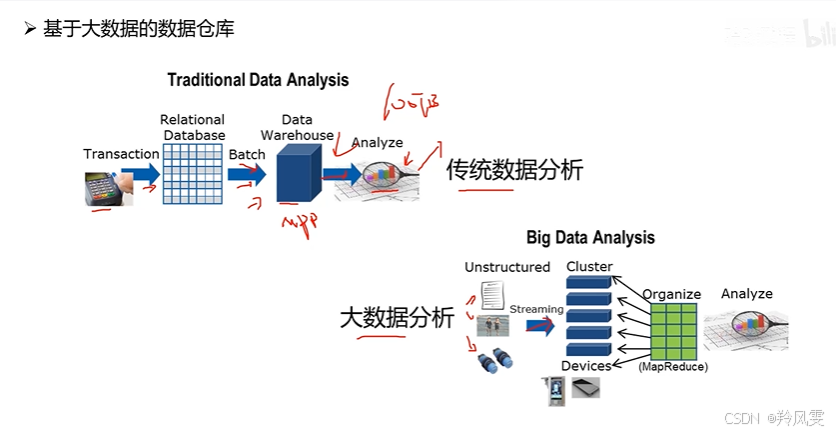
實時場景
大數據應用場景
本節課深入剖析了大數據的兩大核心場景(離線和實時),并重點解釋了大數據架構是如何解決傳統架構瓶頸的。
一、離線處理場景 (Offline Processing)
典型代表:數據倉庫
-
與傳統數倉的對比:
-
傳統數倉:基于單機大型機或MPP架構。問題在于擴展性有上限,存儲和計算能力最終會遇到瓶頸。
-
大數據數倉:基于完全分布式架構(如Hadoop、Spark)。擴展性近乎無限,可以通過增加普通服務器節點來線性提升存儲和計算能力。
-
-
大數據解決海量數據問題的兩大核心思想:
-
分而治之(存儲):將超大文件(如1TB)切分成多個小塊(如128MB),并分散存儲到集群的各個節點上。這解決了海量數據存不下的問題。
-
移動計算而非移動數據(計算):將計算任務(代碼)分發到各個存有數據的節點上,進行本地計算,產生部分結果,最后只需匯總這些小的結果。這極大地減少了網絡傳輸開銷,解決了海量數據算得慢的問題。
-
再次強調:這種架構為海量數據設計,處理中小規模數據時調度開銷遠大于計算本身,效率反而不如傳統數據庫。
-
-
其他離線場景:
-
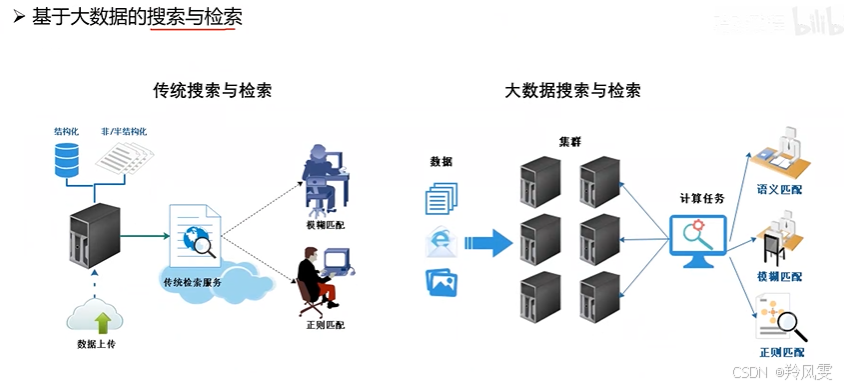
搜索與檢索:在海量數據中快速進行模糊、正則、語義等復雜匹配并返回結果。(例如:Elasticsearch)
-
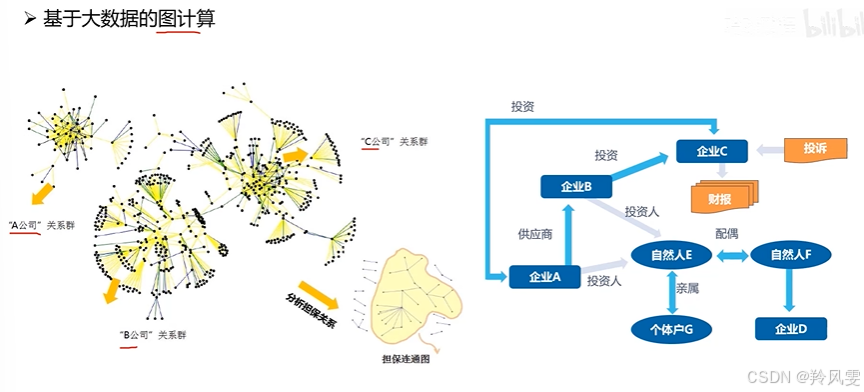
圖計算:分析數據之間的關系,而非數據本身。適用于風控領域(發現擔保鏈、循環投資)、反洗錢、社交網絡分析等。
-
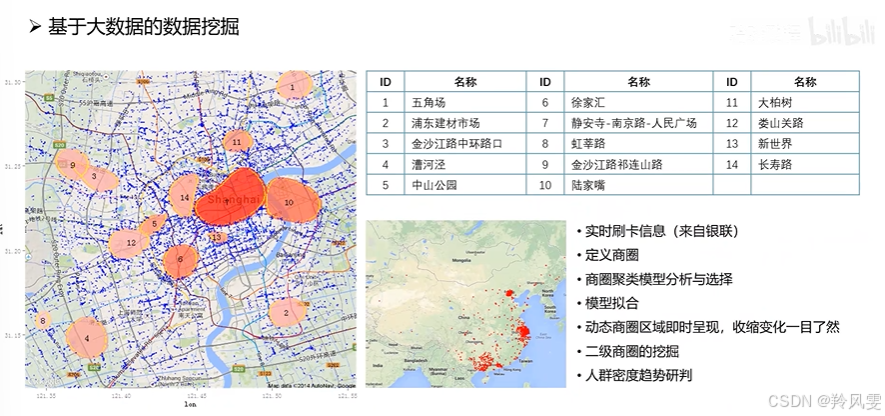
數據挖掘與AI:基于全量歷史數據進行深度分析、機器學習模型訓練,挖掘潛在價值,甚至進行預測(如預測城市人流高峰,輔助公共安全決策)。
-
二、實時處理場景 (Real-time Processing)
典型代表:實時流計算
-
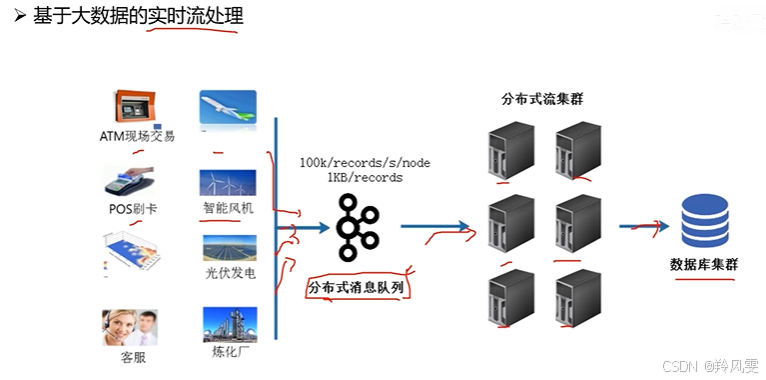
核心架構:為什么需要消息隊列?
-
數據源(如傳感器、POS機、APP日志)產生的數據不直接送入流計算集群(如Flink、Spark Streaming),而是先進入一個分布式消息隊列(如Kafka)。
-
核心目的:抗壓與解耦。
-
應對不可預測的流量峰值:如明星緋聞、突發新聞帶來的流量風暴,消息隊列可以緩沖這些洪峰,保護后端的流計算集群不被沖垮,保證集群穩定性。
-
解耦生產與消費:數據生產者和消費者速率不同,消息隊列作為緩沖區,允許流處理集群按照自己的能力消費數據。
-
-
-
處理流程:
-
數據源 -> (實時產生) -> 消息隊列/Kafka -> (緩沖) -> 流計算集群 -> (實時處理) -> 輸出結果 -
這種架構確保了系統的高可用性和可靠性,即使處理不過來,也只是數據在隊列中短暫積壓,而不會導致系統崩潰。
-
總結與啟示
-
思想升華:大數據的威力不僅在于技術組件,更在于其核心設計思想——“分而治之”和“移動計算”。這些思想是解決超大規模問題的鑰匙。
-
場景驅動:技術選型完全由業務場景決定。
-
分析歷史全量數據,追求最終準確性?-> 選用離線批處理。
-
處理持續不斷的數據流,追求低延遲即時性?-> 選用實時流處理,并必須引入消息隊列作為緩沖。
-
-
價值體現:大數據的價值在這些場景中得以兌現:從傳統的報表分析,到實時的風險控制、智能推薦,再到超前的趨勢預測,構成了數據驅動決策的核心體系。
大數據發展史:從編年史角度看大數據興起_嗶哩嗶哩_bilibili


大數據技術生態全景一覽_嗶哩嗶哩_bilibili
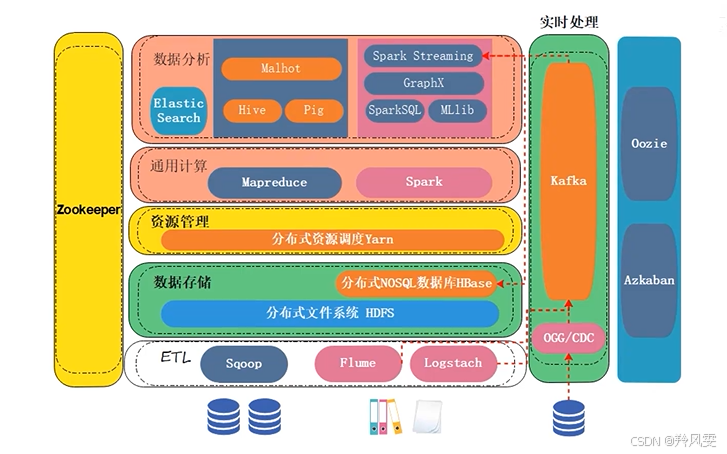
大數據生態架構
一、核心設計思想:分層解耦
整個大數據生態體系并非一個單一產品,而是由眾多專門化的產品組合而成。其核心架構可以劃分為四層,各層職責明確,相互配合:
-
數據采集層:負責從各種數據源抽取數據。
-
數據存儲層:負責海量數據的可靠存儲。
-
資源管理與計算層:負責調度集群資源和執行計算任務。
-
數據應用層:提供易用的接口(如SQL、API)進行數據分析與處理。
二、數據處理流程詳解
第1步:數據采集 (Data Ingestion)
數據來源多樣,采集工具因數據結構和時效性需求而異。
-
結構化數據?(如MySQL、Oracle等數據庫中的表):
-
T+1批量抽取:常用?Sqoop。通過JDBC連接數據庫,定期(通常是每天)將數據批量導入大數據平臺。延遲較高。
-
實時抽取:常用?CDC?(Change Data Capture) 或?OGG?(Oracle專用)。通過實時監控數據庫日志(如MySQL的binlog)來捕捉數據變更,并將變動數據實時發送到Kafka消息隊列。延遲低,不影響數據庫性能。
-
-
非結構化/半結構化數據?(如日志、JSON、圖片、視頻):
-
實時抽取:常用?Flume?或?Logstash。實時監控文件或數據流,一旦有新數據產生就立即采集。
-
重要架構設計:實時數據不直接存入存儲層,而是先送入?Kafka?消息隊列。Kafka起到緩沖和抗壓的作用,保護后端系統不被數據洪峰沖垮。
-
結論:無論何種數據類型,Kafka?都是實時數據管道中的核心組件,承接采集層的數據,并輸送給計算層處理。
第2步:數據存儲 (Data Storage)
采集來的數據最終需要持久化存儲。
-
HDFS:分布式文件系統,是大數據存儲的基石。成熟穩定,但直接操作文件對用戶不友好。
-
HBase:構建在HDFS之上的分布式NoSQL數據庫。解決了HDFS的小文件問題,提供更易用的數據庫操作接口(如KV查詢)。實時計算的結果通常存入HBase,以避免大量小文件對HDFS的沖擊。
第3步:資源管理與計算 (Resource Management & Computation)
數據存儲后,需要進行計算分析。
-
YARN:分布式資源調度框架。核心作用是管理集群資源(CPU、內存),并將計算任務調度到存有數據的節點上執行,實現“移動計算而非移動數據”,極大提升效率。
-
計算引擎:
-
MapReduce:早期批處理模型,穩定但速度較慢。
-
Spark:新一代計算引擎,基于內存計算,速度更快。生態豐富,涵蓋批處理、流處理、機器學習等領域。
-
第4步:數據應用與易用性 (Data Application & Usability)
直接使用MapReduce/Spark編程仍較復雜,因此需要更上層的封裝。
-
SQL-on-Hadoop:Hive。允許用戶使用SQL語句進行查詢,Hive會自動將其轉換為底層的MapReduce或Spark任務執行。極大降低了使用門檻,是數據倉庫建設的核心工具。
-
Spark生態:
-
Spark SQL:使用SQL執行Spark計算。
-
Spark Streaming:用于實時流計算。
-
MLlib:機器學習庫。
-
-
其他框架:如Pig(腳本式)、Mahout(機器學習),但目前應用較少。
生態圈歸屬:
-
基于HDFS、MapReduce、YARN的技術棧屬于?Hadoop生態圈。
-
以Spark為核心的技術棧屬于?Spark生態圈。兩者并非完全隔離,如Hive既可跑在MapReduce上,也可跑在Spark上。
三、其他重要輔助組件
-
ZooKeeper:分布式協調服務。是許多大數據組件的“神經中樞”,負責分布式環境下的協調工作,如:服務發現、節點狀態監控、分布式鎖、領導者選舉(如HDFS NameNode、Kafka Controller的選舉)。Kafka等組件強依賴它。
-
任務調度:Oozie?/?Azkaban。用于管理和調度有復雜依賴關系的批量作業(Job),例如設置任務執行順序、定時任務(如每天凌晨執行ETL任務)。
-
獨立產品:Elasticsearch。一個功能強大的搜索與分析引擎。不依賴Hadoop/Spark生態,自身就包含了存儲、計算、檢索等功能,常用于日志分析、全文檢索等場景。
四、總結與核心要點
-
流程驅動:大數據處理遵循?采集 -> 緩沖 -> 存儲 -> 計算 -> 應用?的標準流程。
-
Kafka是關鍵樞紐:作為消息隊列,它解耦了數據采集和數據處理,是構建實時數據管道不可或缺的一環。
-
存儲選擇:HDFS用于原始數據和大文件存儲;HBase用于提供低延遲訪問和存儲計算結果,避免小文件問題。
-
計算模式:YARN管資源;Spark是更高效的計算引擎首選;Hive等工具提供易用的SQL接口。
-
生態豐富:Hadoop生態與Spark生態并存且融合,還有其他像ES這樣的獨立強者,需根據具體場景選擇合適工具。
-
協調與調度:ZooKeeper負責底層分布式協調,Oozie/Azkaban負責上層作業流調度。
這套架構通過組合各種專用工具,共同協作,完成了從數據產生到價值提取的完整閉環。
類比一下,秒懂大數據模式_嗶哩嗶哩_bilibili
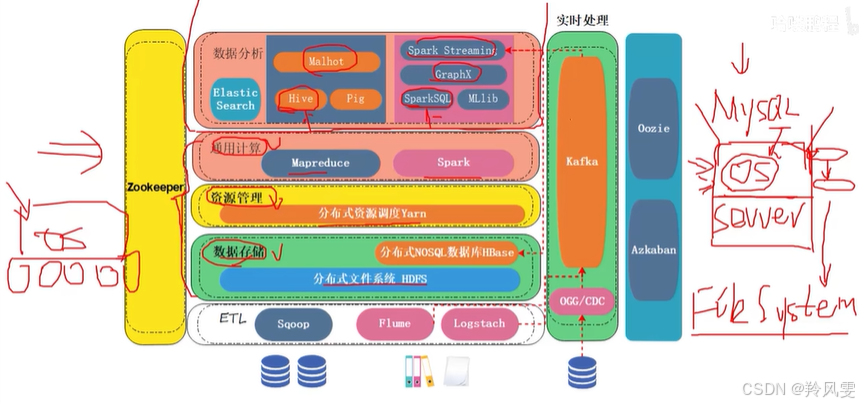
核心洞見:大數據生態 = 分布式操作系統 + 上層應用
大數據架構和傳統單機開發在邏輯上是一模一樣的,其根本區別在于運行環境從“單機”變成了“集群”。
一、傳統單機架構(類比)
-
硬件層:一臺物理服務器。
-
操作系統 (OS):如 Linux、Windows。
-
文件系統:如 ext4、NTFS,管理單機磁盤存儲。 ->?對應大數據的 HDFS
-
資源管理:調度單機的 CPU、內存給各個進程。 ->?對應大數據的 YARN
-
通用計算:提供 C、Java、Python 等語言的運行環境。 ->?對應大數據的 MapReduce/Spark
-
-
上層應用:在 OS 之上安裝 MySQL、Oracle 等數據庫應用,直接使用 SQL 進行業務開發。
在這個模式下,操作系統免費提供了存儲、資源和計算三大核心能力。
二、大數據分布式架構(現狀)
由于沒有現成的、能直接安裝的“分布式操作系統”,我們必須用軟件自己構建一個。
-
硬件層:多臺物理服務器組成的集群。
-
(軟件構建的)分布式操作系統:
-
分布式文件系統 (HDFS):代替單機文件系統,管理跨多臺機器的存儲。
-
分布式資源管理 (YARN):代替單機資源調度,管理整個集群的 CPU和內存。
-
分布式通用計算 (MapReduce, Spark):提供能在集群上并行運行的編程模型和計算框架。
-
(這三大件合起來,就是 Hadoop 的核心)
-
-
上層應用:在構建好的“分布式OS”之上,安裝各種應用。
-
做數據倉庫?-> 安裝?Hive?(提供SQL接口)
-
做機器學習?-> 安裝?Mahout 或使用?Spark MLlib
-
做流計算?-> 安裝?Spark Streaming
-
做圖計算?-> 使用?Spark GraphX
-
這就完美解釋了為什么大數據組件這么多:一部分是用來“造OS”的,另一部分是在這個“OS”上跑的“App”。
三、通用計算的角色(數據處理與清洗)
您進一步澄清了通用計算(MapReduce/Spark編程)的角色,這又是一個精妙的類比:
-
在傳統開發中,我們有時會用?Java/Python/C++?編寫程序,來處理操作系統上的原始文件(比如解析日志),處理干凈后再存入MySQL供業務使用。
-
在大數據中,角色完全一樣!我們用?MapReduce/Spark?編寫程序,來處理HDFS上的原始數據(進行清洗、轉換),處理干凈后再存入Hive或HBase,供上層的SQL分析使用。
所以,直接使用MapReduce/Spark編程,就相當于在傳統領域使用C/Java進行底層開發,它負責的是最基礎的數據預處理工作。
四、未來展望
您指出了當前架構的一個潛在瓶頸和未來方向:現在的“分布式OS”是跑在單機OS之上的,性能有折損。未來的理想狀態是能有一個真正的分布式操作系統直接安裝在裸機硬件上,消除中間層,從而極致地提升性能。
您的講解通過一個強大的核心比喻(自建分布式OS),將看似龐雜的大數據技術棧梳理得井井有條:
-
HDFS, YARN, MapReduce/Spark:是自己搭建的“分布式操作系統”。
-
Hive, Spark SQL, Mahout?等:是運行在這個“OS”之上的“應用程序”。
-
這種架構思想與傳統單機開發(硬件->OS->App)?在邏輯上完全一致,只是實現尺度不同。
這極大地幫助了學習者從自己熟悉的知識體系出發,去理解和遷移到大數據領域,消除了對眾多組件的恐懼感。這是一個非常高明和有效的講解方式。
大數據開發的工作內容與流程_嗶哩嗶哩_bilibili
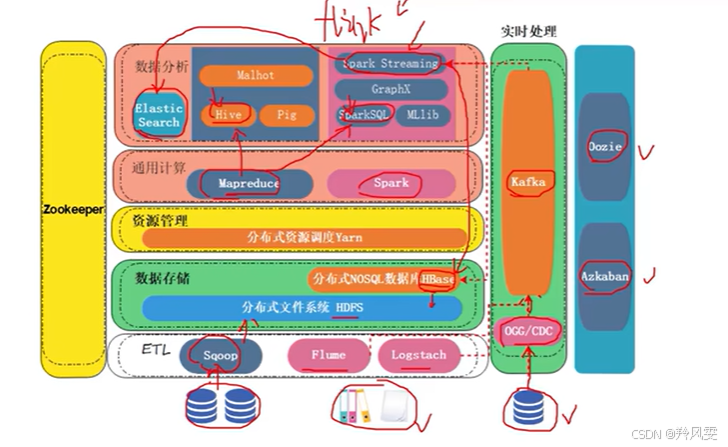
大數據生態架構應用場景總結
整個大數據生態產品繁多,但在實際開發中,我們并非使用所有組件,而是根據不同的業務場景,像搭積木一樣挑選特定的組件組合來完成目標。主要分為兩大場景:
場景一:數據倉庫開發(T+1批處理)
核心目標:對海量數據進行清洗、整合和分析,以支持后續的BI報表、即席查詢等。
典型技術選型與流程:
-
數據抽取:使用?Sqoop?從傳統結構化數據庫(如MySQL、Oracle)中批量抽取數據到HDFS。
-
數據清洗與計算:使用?Spark?或?MapReduce?編寫分布式計算任務,對抽取來的原始數據進行清洗、轉換和復雜的業務邏輯處理。
-
數據存儲與管理:處理后的結果數據(通常是結構化的表)會存入?Hive(開源數倉首選)或使用?Spark SQL?進行管理。它們提供了熟悉的SQL接口,方便后續的查詢和分析。
-
任務調度:整個數據處理流程(如先Sqoop抽數,再Spark計算,最后導入Hive)是一個有依賴關系的任務流,由Azkaban?或?Oozie?這類調度工具進行定時和依賴管理。
核心特點:T+1延時,處理的是歷史數據,流程是周期性的批處理。
場景二:實時流處理
核心目標:對持續產生的數據流進行即時處理,快速響應并得到結果,用于實時監控、實時推薦等場景。
典型技術選型與流程:
-
實時數據采集:
-
對于非/半結構化數據(如日志、點擊流):使用?Flume?或?Logstash?進行實時采集。
-
對于結構化數據變更(如數據庫Binlog):使用?CDC(如Debezium)或?OGG(Oracle專用)實時監控數據庫日志變化。
-
-
數據緩沖:所有實時數據源都首先寫入?Kafka?消息隊列。Kafka在此核心作用是解耦、緩沖和抗壓,確保數據洪峰不會沖垮后續的處理系統。
-
實時計算:流處理引擎(如?Spark Streaming、Flink)從Kafka中實時消費數據,并進行計算處理。開發者需要在此編寫大量的流處理邏輯。
-
結果存儲:
-
實時計算的結果通常是持續產生的小批量數據,因此不能直接存入HDFS(會導致小文件問題)。
-
結果首選存入?HBase:因為其底層機制能有效處理高頻寫入和小文件。
-
或存入?Elasticsearch:如果結果數據需要提供快速檢索和查詢能力(如實時儀表盤)。
-
核心特點:低延遲,處理的是正在發生的數據,流程是持續的流處理。
總結對比
| 場景 | 數據倉庫(批處理) | 實時流處理 |
|---|---|---|
| 目標 | 分析歷史數據,支持決策 | 實時響應,即時監控 |
| 延時 | T+1(天級別) | 秒級/毫秒級 |
| 數據 | 有界的批量數據 | 無界的持續數據流 |
| 關鍵技術 | Sqoop, Spark,?Hive, Azkaban | Flume/CDC,?Kafka, Spark Streaming/Flink,?HBase/ES |
大數據開發就是根據業務需求,從龐大的生態工具箱中選出最合適的工具,組合成一條高效的數據流水線。



















