25年8月來自武漢大學、阿里達摩院、湖畔研究中心、浙大和清華的論文“Towards Affordance-Aware Robotic Dexterous Grasping with Human-like Priors”。
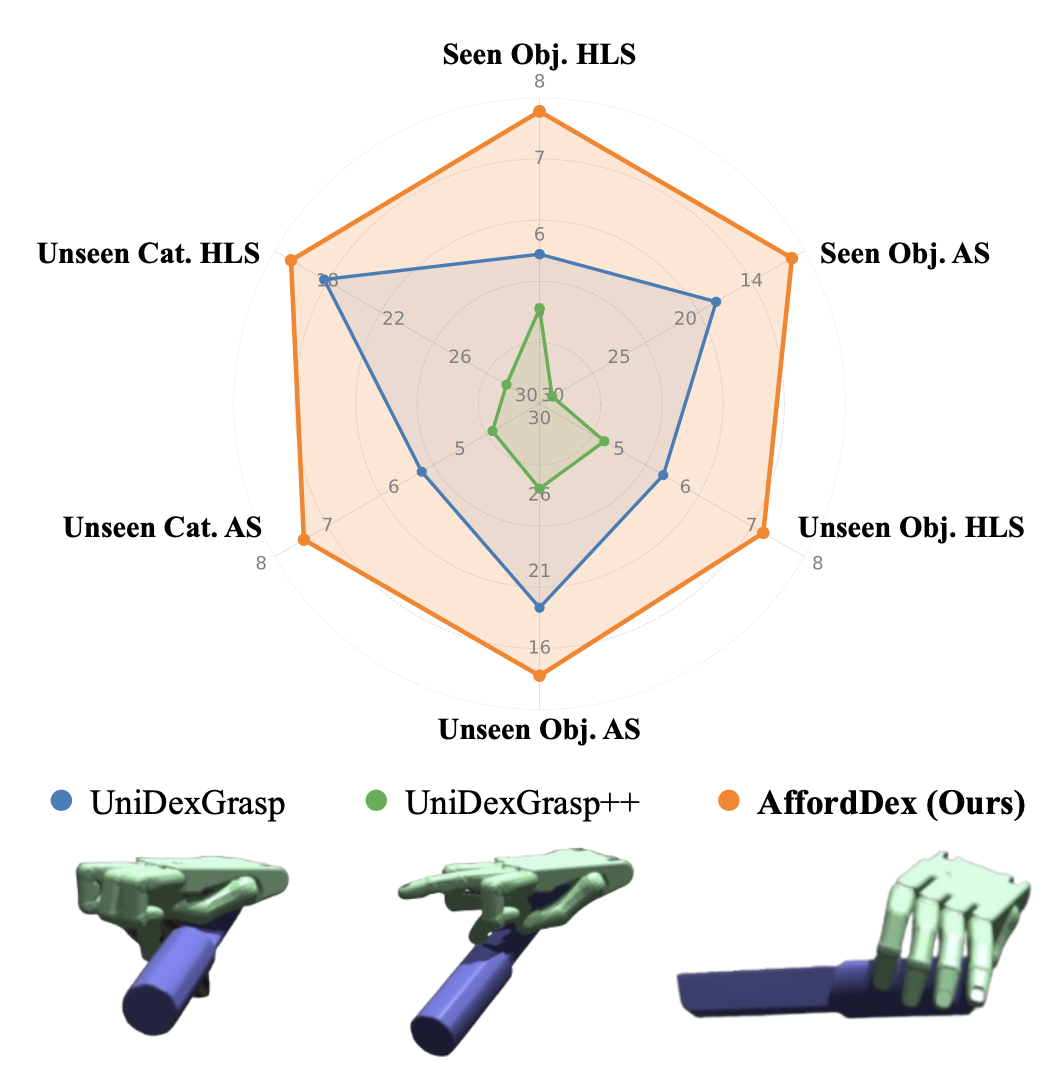
能夠泛化抓取目標的靈巧手是開發通用具身人工智能的基礎。然而,之前的方法僅僅關注低級抓取穩定性指標,而忽略了affordance-覺察的定位和擬人姿態,而這些對于下游操作至關重要。為了突破這些限制,AffordDex,一個采用兩階段訓練的框架,可以學習通用的抓取策略,并固有地理解運動先驗和目標 affordance。在第一階段,軌跡模仿器在大量人類手部動作語料庫上進行預訓練,以灌輸自然運動的強大先驗。在第二階段,訓練殘差模塊,使這些一般的擬人動作適應特定的目標實例。這一改進的關鍵在于兩個組件:負 affordance-覺察分割 (NAA) 模塊,用于識別功能上不合適的接觸區域;以及一個特別的師-生蒸餾過程,用于確保最終基于視覺的策略高度成功。大量實驗表明,AffordDex 不僅實現通用的靈巧抓取,而且在姿勢上保持與人類高度相似的抓取姿勢,并在接觸位置上保持功能上的恰當性。因此,AffordDex 在見過的、未知實例乃至全新類別上的表現均顯著超越最先進的基線模型。
靈巧抓取作為機器人操作的基礎能力,已引起學術界和工業界的廣泛關注 (Zhao et al. 2024b)。與較為簡單的末端執行器(例如平行爪、真空夾持器)相比,五指靈巧手的結構與人手結構更加相似,從而顯著提高了靈活性、精確度和任務適應性 (Zhong et al. 2025)。此外,擬人機器人通過遠程操作加速了豐富的人類演示數據的收集 (Li et al. 2025a)。因此,這種協同效應推動了該領域的快速發展,近期的算法在將抓取泛化至新物體方面取得了很高的成功率 (Fang et al. 2022, 2020; Gou et al. 2021; Wang et al. 2021; Xu et al. 2023; Wan et al. 2023)。
由于靈巧手具有較高的自由度 (DOF),傳統的基于運動規劃的方法 (Andrews & Kry 2013;Bai & Liu 2014) 難以處理如此復雜的手部關節運動。強化學習 (RL) 的最新進展 (Wan et al. 2023;Mandikal and Grauman 2022;Christen et al. 2022;Nagabandi et al. 2020;Mandikal and Grauman 2021) 已在復雜的靈巧操作中展現出良好的效果。然而,抓取的目標不僅僅是舉起一個物體。它涉及與人類意圖的一致性,并為后續的操作任務做好準備,例如避開刀刃或準備打開瓶蓋。現有方法雖然側重于低級抓握穩定性指標,但在很大程度上忽略了 affordance-覺察定位與類人運動學之間的關鍵結合,從而限制了它們在現實世界多步驟操作場景中的實用性。
本文通過建模負 affordance(需要避開的區域)來關注安全性和功能正確性這一關鍵方面,這些區域提供了清晰明確的負約束,從而簡化學習問題。 AffordDex,可以學習一種通用的抓握策略,該策略既具有類人運動能力,又能夠感知物體 affordance。其通過一個結構化的兩階段訓練范式來實現這一點。在第一階段,基于大量人類手部動作對基礎策略進行預訓練,以灌輸自然運動的強大先驗知識。在第二階段,訓練一個殘差模塊,使預訓練策略中的類人運動適應特定物體。如圖所示,AffordDex 生成的抓取動作不僅成功,而且非常類似于人類,功能正確,例如安全地握住刀柄。
為了生成具有 affordance-覺察定位和類人運動的抓取動作(這對于促進下游操作至關重要),提出一個兩階段框架。第一階段通過在大規模人體運動數據集 (Zhan et al. 2024) 上通過模仿學習預訓練基本策略 πH 來建立強大的人體運動先驗。這將策略限制為一系列自然的類人運動。在第二階段,凍結 πH 的權重并通過強化學習 (RL) 訓練輕量級殘差模塊,使這些一般運動適應特定的物體交互。這個 RL 細化階段主要由兩個組件引導:負 affordance-覺察分割 (NAA) 模塊,它對物體不能接觸的位置提供明確的約束;以及一個師-生蒸餾框架,它利用特別狀態信息來顯著提升最終策略的性能。如圖展示該方法的概述:
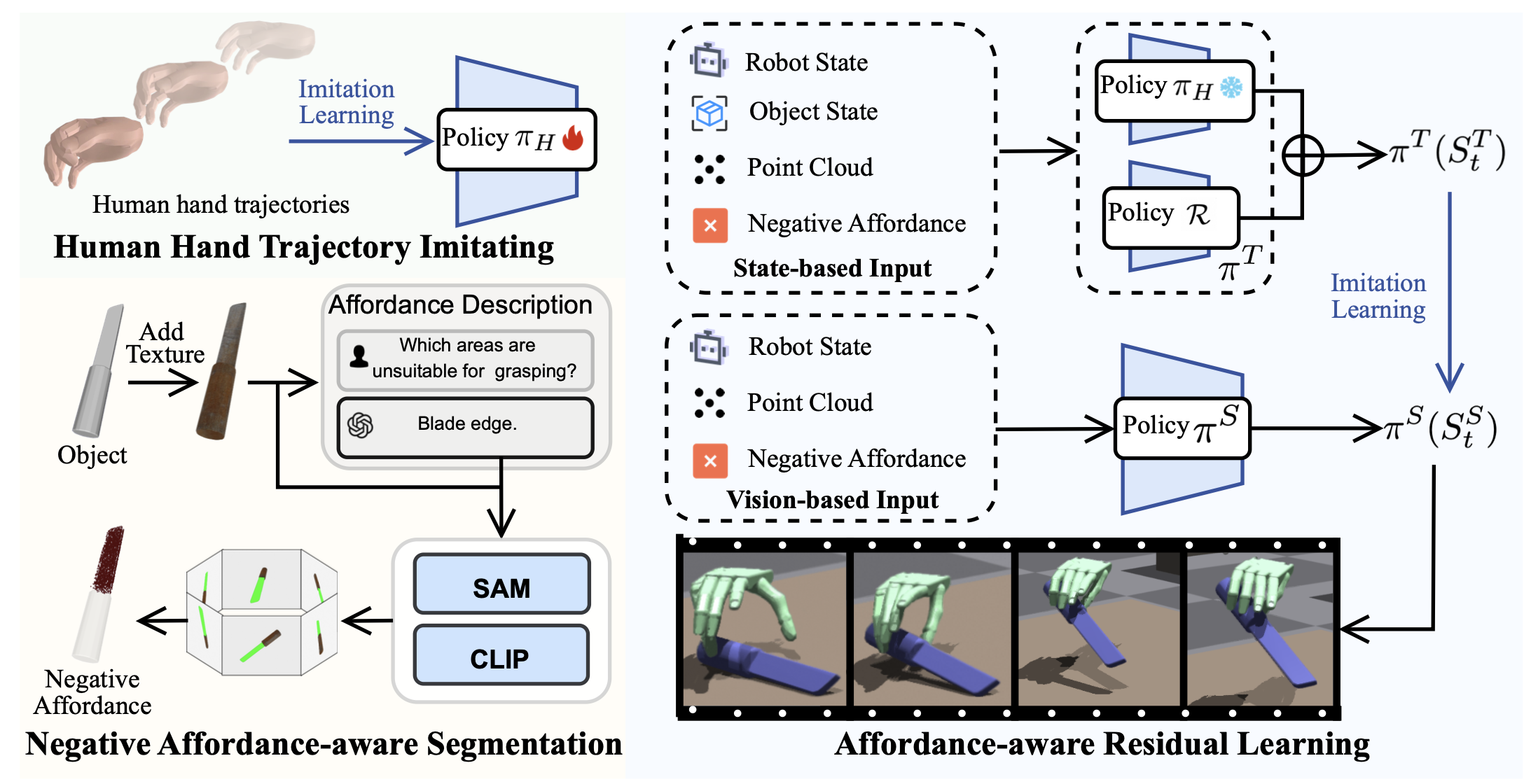
人手軌跡模仿
在此階段,目標是學習一個基礎策略πH,該策略能夠捕捉自然人手運動的運動學先驗。將此任務表述為一個強化學習 (RL) 問題,其中策略 πH (a_t|SH_t) 學習基于時刻 t 的當前狀態 SH_t 生成靈巧的手部動作。為了便于后續的微調階段,狀態由機器人狀態 R_t、物體狀態 O_t 和物體的點云表示 P_t組成,即SH_t = {R_t, O_t, P_t}。
獎勵函數。設計一個獎勵函數rH,以促進對人手軌跡的精確模仿和運動穩定性。它由兩個項組成:手指模仿獎勵 rH_finger 和平滑度獎勵 rH_smooth。
手指模仿獎勵 rH_finger 鼓勵靈巧手緊密跟蹤人手數據集中的參考手指姿勢。根據 (Li et al. 2025b) 的研究,根據機器人靈巧手和 MANO 手上對應關鍵點 F 之間的距離來定義此獎勵。
平滑度獎勵 rH_smooth 通過懲罰過度功耗來鼓勵節能運動。它通過關節速度和施加扭矩的元素乘積來計算。
負 affordance-覺察分割
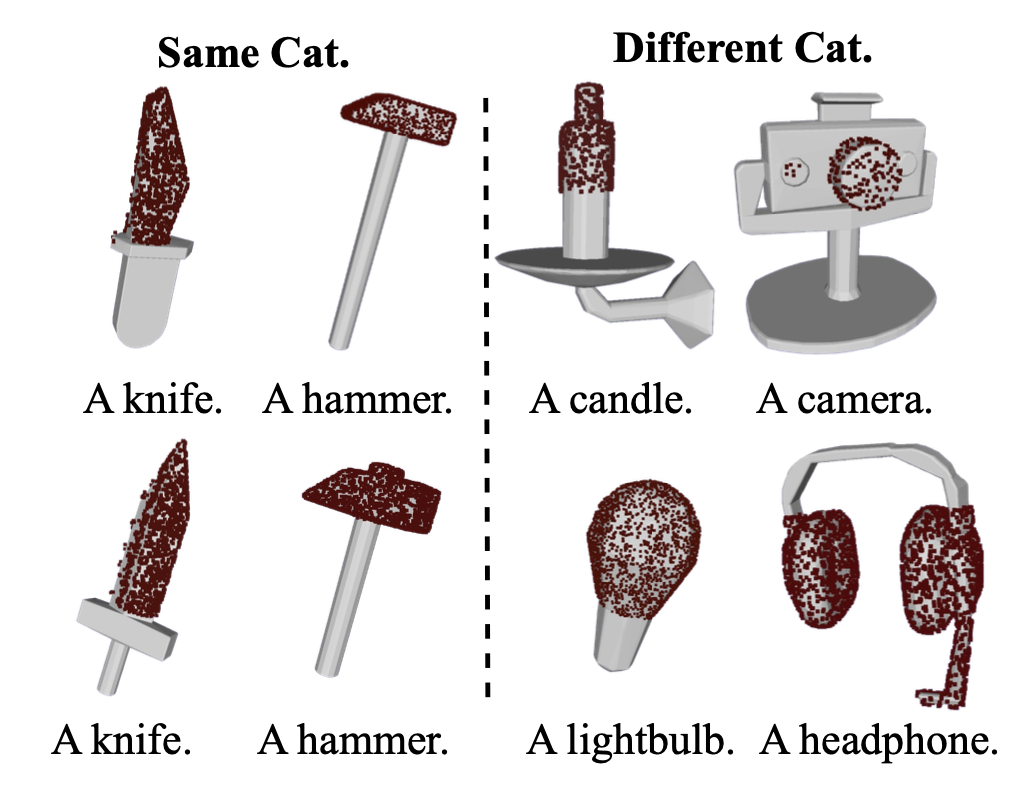
先前研究在抓握合成方面存在一個顯著的局限性 (Xu et al. 2023; Wan et al. 2023; Zhong et al. 2025),即忽略了交互的語義和功能背景。一個典型的例子是刀:雖然刀刃在幾何上對于抓握來說是穩定的,但任何這樣的抓握在功能上都是不正確且不安全的。為了解決這一局限性,引入負 affordance-覺察分割 (NAA) 模塊,以融入負 affordance——推理物體的哪些部分不應該被觸碰。提出的 NAA 能夠利用視覺-語言模型 (VLM) 中豐富的世界知識 (Radford et al. 2021; Achiam et al. 2023),以開放詞匯的方式進行操作,并自動受益于未來基礎模型的進展。這確保了生成的抓取不僅在幾何上穩定,而且在語義上連貫且具有任務感知能力。
VLM 難以解釋無紋理的 3D 網格,因為這些模型主要依賴于從圖像中學習的豐富視覺線索。為了彌補這一缺陷,首先對原始網格應用程序化紋理 (Zhang et al. 2024c),該方法基于幾何分析生成語義上合理的紋理,確保在不同物體形狀上的魯棒性。接下來,從六個基本方向渲染帶紋理的物體,以創建多視圖圖像集 I 作為整體視覺表示。雖然這可能無法捕捉高度復雜物體的所有凹面,但它為基準數據集中物體的 affordance 預測提供了充分的基礎,體現了覆蓋范圍和計算成本之間的實際權衡。然后,本文查詢 GPT-4V (Achiam et al. 2023) 以引出物體 affordance 的詳細描述。
視覺-語言模型 (VLM) (Radford,2021) 和多模態大語言模型 (MLLM) (Achiam,2023) 在圖像級理解方面表現出色,但在分割所需的細粒度空間定位方面卻舉步維艱。為了解決這個問題,不再要求 CLIP (Radford,2021) 從圖像中找出“葉片部件”,而是將分割任務轉變為一個簡單得多的分類任務。生成一組精確的物體-部件掩碼 M_i,并將它們用作視覺提示,讓 CLIP 識別 M_i 中哪個掩碼與文本描述“葉片部件”的語義相似度最高。具體來說,對于每幅圖像 I_i ∈ I,提示“SAM”(Kirillov,2023),在 I_i 上疊加一個密集的點網格 G,這會提示 SAM 執行詳盡的分割,識別所有潛在的物體和部件。然后使用非最大抑制 (NMS) 對得到的掩碼集合進行細化,以消除重復,從而產生一個干凈的候選掩碼集 M_i。對于每個掩碼 M_ij ∈ M_i,用高斯濾波器模糊掩碼外部的區域來生成視覺提示圖像 I_ij (Yang et al. 2023)。然后,將提示圖像集 {I_ij} 與文本查詢一起傳遞給 CLIP,以計算每個圖像-文本對的相似度得分。選擇相似度得分最高的掩碼作為最終的分割掩碼。然后,將掩碼投影到 3D 空間中,以分割目標點云的相應區域,從而獲得負 affordance N_t,如圖所示。
affordance-覺察的殘差學習
基于提出的NAA預測負 affordance,用殘差模塊 R 來改進預訓練策略πH。由于視覺姿態估計本質上不如使用特別狀態信息精確,直接訓練有效的基于視覺的策略可能具有挑戰性。因此,首先訓練一個基于狀態的教師策略πT,它可以訪問環境的真實狀態(例如物體狀態),以學習殘差動作來改進πH預測的初始動作。教師策略πT完成訓練后,用模仿學習算法DAgger(Ross、Gordon和Bagnell,2011)將 πT 蒸餾為基于視覺的學生策略 πS,該策略可以訪問預言機信息,并讓策略輔助和簡化基于視覺的策略學習。
基于狀態的教師策略。在此階段,輸入為機器人狀態 R_t、物體狀態 O_t、場景點云 P_t 和預測的負 affordance N_t。場景點云由多視角深度攝像頭融合。目標是學習殘差動作 ?_a_t = πT (S_tT),并結合 PPO (Schulman et al. 2017) 預測的負affordance。最終,動作通過逐元素加法計算得出。
獎勵函數。獎勵函數 rT 定義為:rT =?rT_d ?rT_g +rT_s ?r_n,其中抓握獎勵 r_dT 懲罰靈巧手與物體之間的距離,鼓勵手保持與物體表面的接觸,以實現穩固的抓握。目標獎勵 r_gT 懲罰物體與目標之間的距離,成功獎勵 rT 在物體成功到達目標時給予獎勵。此外,負 affordance 獎勵 r_nT 懲罰靈巧手接近預測的負affordance。
基于視覺的學生策略。對于基于視覺的策略,僅允許其訪問現實世界中可用的信息,包括機器人狀態 R_t、場景點云 P_t 和預測的負 affordance N_t。然后,用 DAgger (Ross, Gordon, and Bagnell 2011) 將教師策略 πT 蒸餾為基于視覺的學生策略 πS。
實驗情況如下。
數據集
UniDexGrasp (Xu et al. 2023)。該數據集包含 3165 個不同的物體實例,涵蓋 133 個類別。評估基于這 3,200 個可見物體,以及來自見過類別的 140 個未見過物體和來自未見過的 100 個未可見物體。每個環境都隨機初始化一個物體及其初始姿態,該環境由固定攝像頭捕捉的全景 3D 點云 P_t 組成,用于基于視覺的策略學習。
OakInk2 (Zhan et al. 2024)。該數據集記錄人體上半身和物體的姿態和形狀的操作過程。用其中約 2,200 個右手操作序列對 πT 進行預訓練。還使用 OakInk2 中的物體來評估其在抓取方面的泛化能力。
指標
參照前人的研究(Xu et al. 2023; Wan et al. 2023; Wang et al. 2025),每個物體被隨機旋轉并落到桌面上,以增強其初始姿勢的多樣性。結果報告所有物體和抓取嘗試的抓取成功率 Succ、人像評分 HLS 和 affordance 評分 AS。如果物體在模擬器中 200 步內達到目標,則認為抓取成功。人像評分 HLS 評估抓取的擬人化質量,該質量是通過提示 Gemini 2.5 Pro(Comanici et al. 2025)分析??抓取執行的視覺序列獲得的。該指標專門用于評估靈巧手運動與典型人類運動的相似性,從而定量衡量自然度。相比之下,affordance 評分 (AS) 通過懲罰與不適當物體部位的接觸來評估抓握的功能正確性。該指標使用從 NAA 中采樣的 100 個“負 affordance”點云計算得出。具體來說,每指尖與負 affordance 點集中的任何點保持 2 厘米以上的距離,分數就會加 1,從而獎勵功能良好的抓握。
實施細節
在 Issac Gym (Makoviychuk,2021) 模擬器中進行實驗。訓練期間,在 NVIDIA RTX 4090 GPU 上并行模擬 4096 個環境。對于網絡架構,在基于狀態的設置中使用具有 4 個隱藏層(1024,1024,512,512)的多層感知器 (MLP) 作為策略網絡和價值網絡;在基于視覺的設置中,用一個額外的 PointNet+Transformer(Mu,2021)來編碼 3D 場景點云輸入。
靈巧手配置。用 Shadow Hand,它具有 24 個主動自由度 (DOF)。手腕具有 6 個由力和扭矩控制的自由度,而手指具有 18 個由關節角度控制的主動自由度。具體來說,拇指有 5 個 DOF,小指有 4 個,其余三個手指各有 3 個。此外,除拇指外,每個手指都包括一個被動的、不受控制的 DOF。
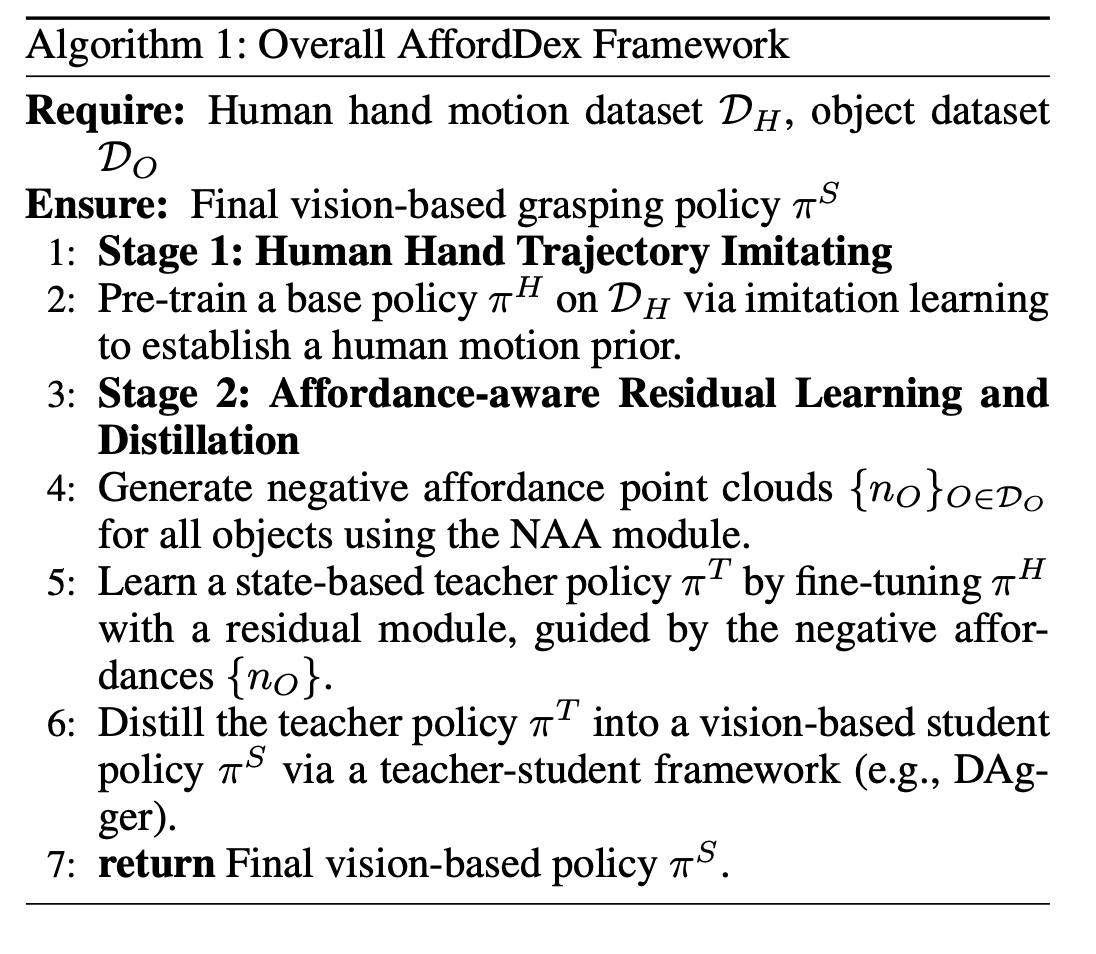
最后,AffordDex 算法總結如下:

![[光學原理與應用-338]:ZEMAX - Documents\Zemax\Samples](http://pic.xiahunao.cn/[光學原理與應用-338]:ZEMAX - Documents\Zemax\Samples)


:Android安全架構深度剖析 - 從內核到應用的全棧防護)

】系統工程與信息系統基礎上:系統工程基礎概念)
![[p2p-Magnet] 隊列與處理器 | DHT路由表](http://pic.xiahunao.cn/[p2p-Magnet] 隊列與處理器 | DHT路由表)











