當前有3個虛擬機節點,每個節點配置的slot節點數量是4,${FLINK_HOME}/conf/flink-conf.yaml 關于slot的配置如下:
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
taskmanager.numberOfTaskSlots: 4state.backend: rocksdb
# checkpoint的時間根據集群性能和數據量確定
execution.checkpointing.interval: 30000
state.checkpoints.dir: hdfs://cdh01:8020/chkpoints
state.backend.incremental: true
其中,${HADOOP_HOME}/etc/hadoop/yarn-site.xml中關于yarn單個容器允許分配的最大內存設置如下:
<!-- yarn單個容器允許分配的最大最小內存 --><property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>4096</value></property><!-- yarn容器允許管理的物理內存大小 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property>
啟動yarn-session以Flink session cluster供FLINK SQL以共享方式運行:
$FLINK_HOME/bin/yarn-session.sh -d
啟動FLINK SQL Client:
$FLINK_HOME/bin/sql-client.sh embedded -i $FLINK_HOME/conf/sql_client_init.sql -s yarn-session
如圖,提交23個 FlinkSQL任務(flink-cdc -> hudi-ods),由于slot數量不夠,將導致12個任務之外的剩余任務處于pending的狀態(黑紫任務)。
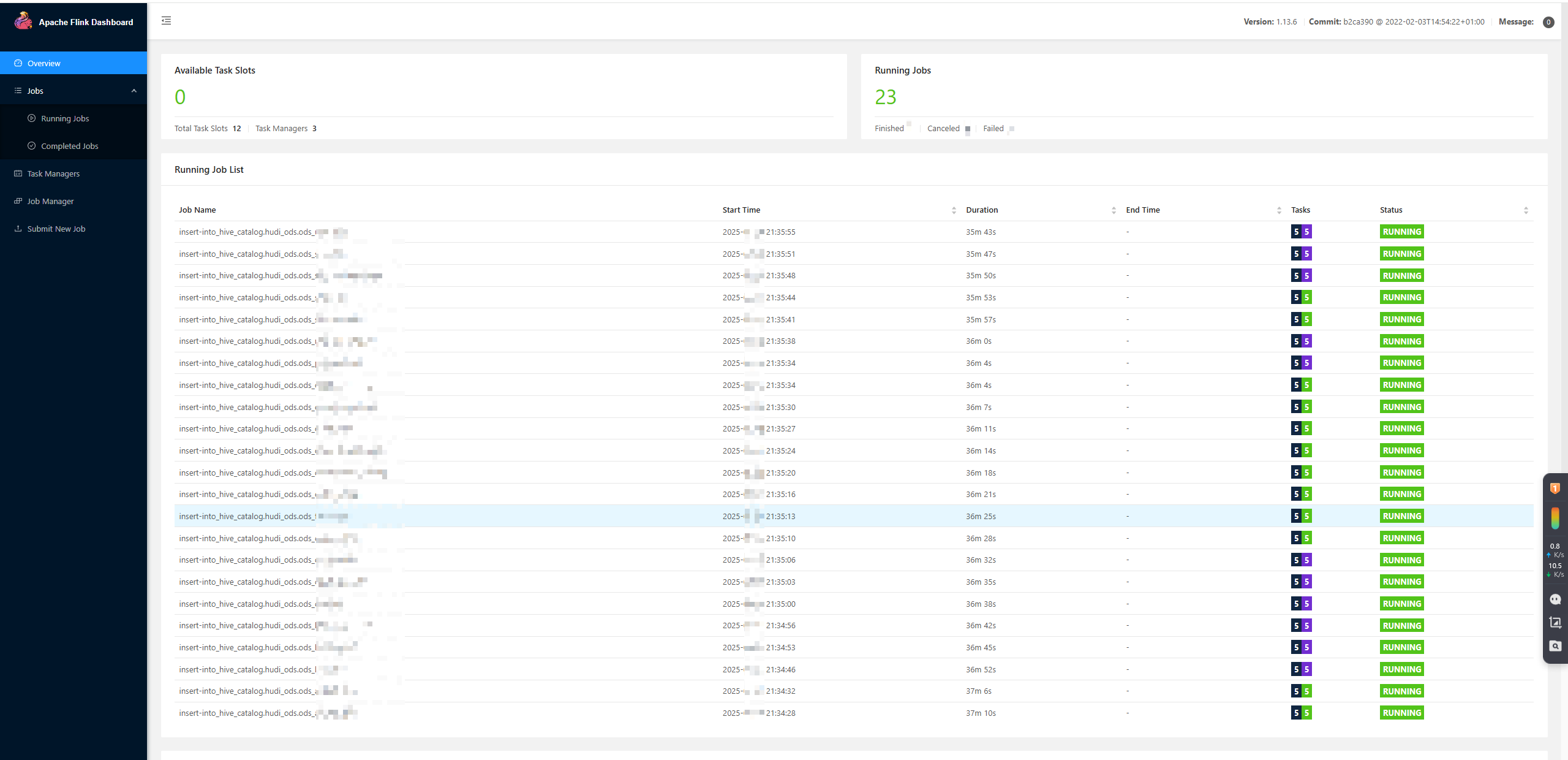
查看某個pending任務的log,看到報錯如下:
2025-xx-xx 21:45:56
java.util.concurrent.CompletionException: org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Slot request bulk is not fulfillable! Could not allocate the required slot within slot request timeoutat java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:292)at java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:308)at java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:593)at java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:577)at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:474)at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1977)at org.apache.flink.runtime.scheduler.SharedSlot.cancelLogicalSlotRequest(SharedSlot.java:222)at org.apache.flink.runtime.scheduler.SlotSharingExecutionSlotAllocator.cancelLogicalSlotRequest(SlotSharingExecutionSlotAllocator.java:164)at org.apache.flink.runtime.scheduler.SharingPhysicalSlotRequestBulk.cancel(SharingPhysicalSlotRequestBulk.java:86)at org.apache.flink.runtime.jobmaster.slotpool.PhysicalSlotRequestBulkWithTimestamp.cancel(PhysicalSlotRequestBulkWithTimestamp.java:66)at org.apache.flink.runtime.jobmaster.slotpool.PhysicalSlotRequestBulkCheckerImpl.lambda$schedulePendingRequestBulkWithTimestampCheck$0(PhysicalSlotRequestBulkCheckerImpl.java:91)at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)at java.util.concurrent.FutureTask.run(FutureTask.java:266)at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:440)at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:208)at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:77)at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:158)at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:26)at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:21)at scala.PartialFunction.applyOrElse(PartialFunction.scala:123)at scala.PartialFunction.applyOrElse$(PartialFunction.scala:122)at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:21)at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)at akka.actor.Actor.aroundReceive(Actor.scala:517)at akka.actor.Actor.aroundReceive$(Actor.scala:515)at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:225)at akka.actor.ActorCell.receiveMessage(ActorCell.scala:592)at akka.actor.ActorCell.invoke(ActorCell.scala:561)at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:258)at akka.dispatch.Mailbox.run(Mailbox.scala:225)at akka.dispatch.Mailbox.exec(Mailbox.scala:235)at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)at akka.dispatch.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)at akka.dispatch.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
Caused by: org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Slot request bulk is not fulfillable! Could not allocate the required slot within slot request timeoutat org.apache.flink.runtime.jobmaster.slotpool.PhysicalSlotRequestBulkCheckerImpl.lambda$schedulePendingRequestBulkWithTimestampCheck$0(PhysicalSlotRequestBulkCheckerImpl.java:86)... 26 more
Caused by: java.util.concurrent.TimeoutException: Timeout has occurred: 300000 ms... 27 more
從報錯來看,核心問題是 Flink集群總Slot(12個)不足以支撐23個任務的并發需求,導致11個任務因無法分配Slot而處于Pending狀態,最終觸發超時(300秒后仍未獲取到資源)。解決思路圍繞“增加可用Slot”和“優化資源分配”展開,具體方案如下:
一、核心原因拆解
Flink的Slot是任務執行的最小資源單元(每個Slot對應一個TaskManager的一個CPU核心,默認1個Slot/核心),當前12個Slot最多同時運行12個任務。23個任務并發時,超出的11個任務會進入Pending隊列,若超過slot.request.timeout(默認300秒)仍未獲取到Slot,就會報超時錯誤。
二、解決方案(按優先級排序)
方案1:增加TaskManager節點或每個節點的Slot數量(最直接)
通過擴展Flink集群的Slot總數,滿足23個任務的并發需求(需至少23個Slot)。
1.1 增加每個TaskManager的Slot數量(無需新增虛擬機)
若現有3臺虛擬機的CPU資源充足(如每臺虛擬機有10核CPU,當前僅用4核),可通過修改配置增加單節點的Slot數:
- 停止Flink集群:
./bin/stop-cluster.sh - 修改
flink-conf.yaml配置文件:# 每個TaskManager的Slot數量(默認1,根據CPU核數調整,建議不超過物理核數) taskmanager.numberOfTaskSlots: 10 # 3臺虛擬機 × 10個Slot = 30個Slot,滿足23個任務注意:
numberOfTaskSlots不能超過虛擬機的物理CPU核心數(如虛擬機是10核,最大設為10,留1核給系統)。 - 重啟Flink集群:
./bin/start-cluster.sh - 驗證Slot總數:
- 訪問Flink Web UI(如
http://hadoop103:8081),在左側“Cluster Overview”中查看“Total Slots”是否為30(3×10)。
- 訪問Flink Web UI(如
1.2 新增TaskManager節點(現有節點資源不足時)
若3臺虛擬機的CPU已達上限,需新增1臺虛擬機作為TaskManager節點:
- 在新虛擬機上安裝Flink(與現有集群版本一致),并配置
flink-conf.yaml:# 指向現有JobManager的地址(如hadoop103) jobmanager.rpc.address: hadoop103 # 新節點的Slot數量(如8個,3臺舊節點×4 + 1臺新節點×8 = 20,仍不夠可設為11) taskmanager.numberOfTaskSlots: 11 - 在新節點上啟動TaskManager:
./bin/taskmanager.sh start - 驗證:Web UI中“Total Slots”是否達到23+。
方案2:優化任務資源分配(避免資源浪費)
若無法增加Slot總數,可通過優化任務的資源配置,減少單個任務的Slot占用,提升Slot利用率。
2.1 降低單個任務的并行度(Parallelism)
Flink任務的并行度默認等于Slot數量,若部分任務無需高并行(如簡單查詢),可手動降低并行度,減少Slot占用:
-- 執行任務時指定并行度(如設為1,僅占用1個Slot)
Flink SQL> set execution.parallelism = 1;
-- 再執行任務(如查詢)
Flink SQL> select * from order_info_cdc;
說明:默認情況下,每個任務的并行度 =
parallelism.default(flink-conf.yaml配置,默認1),若之前設為更高值(如2),會導致單個任務占用多個Slot。
2.2 合并小任務(減少任務總數)
若20個任務中有多個相似的輕量任務(如多個簡單查詢),可合并為1個任務,減少Slot需求:
- 例:將多個
select * from table where ...合并為union all查詢:
合并后1個任務僅占用1個Slot,替代原來的2個任務。select * from table1 where type=1 union all select * from table1 where type=2;
方案3:配置Slot共享組(Share Group)
Flink支持“Slot共享組”,允許不同任務共享同一個Slot(僅適用于非密集型任務),提升Slot利用率。
- 在創建表或執行任務時,指定共享組名稱:
-- 執行任務時指定共享組(如所有查詢共享“query_group”) Flink SQL> set execution.share-group = query_group; -- 執行多個任務,會共享同一個Slot(需確保任務非CPU密集型) Flink SQL> select * from table1; Flink SQL> select * from table2; - 注意:共享組僅適合輕量任務(如簡單查詢),若任務是CPU/內存密集型(如大表聚合),共享會導致性能下降。
方案4:延長Slot請求超時時間(臨時規避)
若任務可接受等待(如非實時任務),可延長slot.request.timeout,給Pending任務更多時間等待釋放的Slot:
- 修改
flink-conf.yaml:# Slot請求超時時間(單位:毫秒,設為10分鐘=600000ms) slot.request.timeout: 600000 - 重啟Flink集群生效。
注意:這只是臨時方案,若Slot總數始終不足,任務仍會最終失敗,需配合方案1/2徹底解決。
三、驗證與監控
- 查看任務狀態:
- 訪問Flink Web UI,在“Jobs”頁面查看Pending任務是否已分配Slot(狀態從“Pending”變為“Running”)。
- 監控Slot使用:
- 在Web UI“Cluster Overview”中查看“Used Slots”和“Available Slots”,確保Available Slots ≥ 0(無任務Pending)。
四、生產環境建議
- 優先方案1:生產環境中,核心任務需保證資源充足,建議Slot總數預留20%-30%冗余(如20個任務,配置28個Slot),避免突發任務導致Pending。
- 規范并行度配置:根據任務復雜度設置并行度(如大表處理設為4-8,簡單查詢設為1-2),避免盲目使用高并行度浪費資源。
- 使用YARN/K8s動態資源:若Flink部署在YARN/K8s上,可開啟動態資源分配(
yarn.containers.dynamic/K8s的Pod動態擴縮容),自動根據任務需求增減Slot,無需手動配置。
通過以上方案,可徹底解決Slot不足導致的任務Pending問題,確保所有任務正常運行。


使用 vConsole調試console)



)












