一、引言
定義:有序集合(Zset)是Redis中的一種數據結構,它結合了哈希表和跳躍列表的特性。每個 member 都有一個分數(score),根據這個分數進行排序。
特點:
- member 不能重復,但分數可以相同(理解:一次考試之后,每個人的每個科目都只有一個唯一的分數,但這些不同科目的分數允許相同)
- 通過分數實現有序性。
- 支持范圍查詢、排名計算等功能。
二、Set 命令
象常用命令如下表(點擊命令可查看命令詳細說明)。
| 命令 | 說明 | 時間復雜度 |
|---|---|---|
| BZPOPMAX key [key …] timeout] | 從一個或多個排序集中刪除并返回得分最高的成員,或阻塞,直到其中一個可用為止 | O(log(N)) |
| BZPOPMIN key [key …] timeout] | 從一個或多個排序集中刪除并返回得分最低的成員,或阻塞,直到其中一個可用為止 | O(log(N)) |
| ZADD key [NXXX] [CH] [INCR] score member [score member …] | 添加到有序set的一個或多個成員,或更新的分數,如果它已經存在 | O(log(N)) |
| ZCARD key | 獲取一個排序的集合中的成員數量 | O(1) |
| ZCOUNT key min max | 返回分數范圍內的成員數量 | O(log(N)) |
| ZINCRBY key increment member | 增量的一名成員在排序設置的評分 | O(log(N)) |
| ZINTERSTORE | 相交多個排序集,導致排序的設置存儲在一個新的關鍵 | O(NK)+O(Mlog(M)) |
| ZLEXCOUNT key min max | 返回成員之間的成員數量 | O(log(N)) |
| ZPOPMAX key count | 刪除并返回排序集中得分最高的成員 | O(log(N)*M) |
| ZPOPMIN key count | 刪除并返回排序集中得分最低的成員 | O(log(N)*M) |
| ZRANGE key start stop WITHSCORES | 根據指定的index返回,返回sorted set的成員列表 | O(log(N)+M) |
| ZRANGEBYLEX key min max LIMIT offset count | 返回指定成員區間內的成員,按字典正序排列, 分數必須相同。 | O(log(N)+M) |
| ZREVRANGEBYLEX key max min [LIMIT offset count] | 返回指定成員區間內的成員,按字典倒序排列, 分數必須相同 | O(log(N)+M) |
| ZRANGEBYSCORE key min max [WITHSCORES] | 返回有序集合中指定分數區間內的成員,分數由低到高排序。 | O(log(N)+M) |
| ZRANK key member | 確定在排序集合成員的索引 | O(log(N)) |
| ZREM key member member […] | 從排序的集合中刪除一個或多個成員 | O(M*log(N)) |
| ZREMRANGEBYLEX key min max | 刪除名稱按字典由低到高排序成員之間所有成員。 | O(log(N)+M) |
| ZREMRANGEBYRANK key start stop | 在排序設置的所有成員在給定的索引中刪除 | O(log(N)+M) |
| ZREMRANGEBYSCORE key min max | 刪除一個排序的設置在給定的分數所有成員 | O(log(N)+M) |
| ZREVRANGE key start stop [WITHSCORES] | 在排序的設置返回的成員范圍,通過索引,下令從分數高到低 | O(log(N)+M) |
| ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count] | 返回有序集合中指定分數區間內的成員,分數由高到低排序。 | O(log(N)+M) |
| ZREVRANK key member | 確定指數在排序集的成員,下令從分數高到低 | O(log(N)) |
| ZSCORE key member | 獲取成員在排序設置相關的比分 | O(1) |
| ZUNIONSTORE | 添加多個排序集和導致排序的設置存儲在一個新的關鍵 | O(N)+O(M log(M)) |
| ZSCAN key cursor [MATCH pattern] [COUNT count] | 迭代sorted sets里面的元素 | O(1) |
1. 普通命令🧱
1.1 ZADD & ZINCRBY
① ZADD:添加或者更新指定的元素以及關聯的分數到zset中,分數應該符合double類型,+inf/-inf作為正負極限也是合法的。
語法:
ZADD key [NX | XX] [GT | LT] [CH] [INCR] score member [score member ...]
ZADD 的相關選項:
- XX:僅僅用于更新已經存在的元素,不會添加新元素。
- NX:僅用于添加新元素,不會更新已經存在的元素。
- LT/GT:這個選項的意思是 less than 和 greater than 的意思,這兩個意思表示的是現在如果要進行更新分數,那么如果當前的分數比之前的分數小,就更新成功,否則就不更新,反之同理
- CH:默認情況下,ZADD返回的是本次添加的元素個數,但指定這個選項之后,就會還包含本次更新的元素的個數。
- INCR:此時命令類似ZINCRBY的效果,將元素的分數加上指定的分數。此時只能指定一個元素和分數。
時間復雜度:O(log(N))
對于 zset 來說,時間復雜度就不一樣了,在 set 中的各項操作基本都是 O(1) 的時間復雜度,而在 zset 中卻被放到了 O(logn),這是因為畢竟是有序結構,要找到合適的位置才能放,所以這里是 logn,那為什么不是 O(n) 呢?其實更多的是借助了跳表這樣的數據結構,可以快速定位到對應的位置,進行元素的插入工作
案例如下:
127.0.0.1:6379> zadd myzset 10 one 20 two
(integer) 2
127.0.0.1:6379> zrange myzset
(error) ERR wrong number of arguments for 'zrange' command
127.0.0.1:6379> zrange myzset 0 -1
1) "one"
2) "two"
127.0.0.1:6379> zrange myzset 0 -1 WITHSCORES
1) "one"
2) "10"
3) "two"
4) "20"
127.0.0.1:6379> zadd myzset CH 100 one
(integer) 1
127.0.0.1:6379> zadd myzset INCR 20 two
"40"127.0.0.1:6379> zrange myzset 0 -1 WITHSCORES
1) "two"
2) "40"
3) "one"
4) "100"
② ZINCRBY:為指定的元素的關聯分數添加指定的分數值
語法
ZINCRBY key increment member
1.2 ZCARD & ZCOUNT & ZSCORE
① ZCARD:獲取一個zset的基數(cardinality),即zset中的元素個數(語法:ZCARD key
② ZCOUNT:計算分數范圍內的元素數量(語法:ZCOUNT key min max
③ ZSCORE:返回指定元素的分數
使用如下
127.0.0.1:6379> ZCARD myzset
(integer) 2
127.0.0.1:6379> zrange myzset 0 -1 WITHSCORES
1) "two"
2) "40"
3) "one"
4) "100"127.0.0.1:6379> ZCOUNT myzset 0 50
(integer) 1
127.0.0.1:6379> ZCOUNT myzset (0 (40 # ( 表示開區間
(integer) 0
127.0.0.1:6379> ZCOUNT myzset -inf inf
(integer) 2127.0.0.1:6379> ZSCORE myzset "one"
"100"
1.3 ZRANGE & ZREVRANGE & ZRANGEBYSCORE
① ZRANGE:升序 獲取指定區間內的元素(語法:ZRANGE key start stop [WITHSCORES],withcores 參數:每個元素的下一行是它的socre
語法:ZRANGE key start stop [WITHSCORES]
-
按 升序 返回
[start, stop]區間內的元素,如果帶上withscores則將score一起返回。 -
此處的
start和stop不是分數,而是元素的排名(下標),從0開始,支持負數
② ZREVRANGE:獲取指定區間內的元素(降序),和 ZRANGE 基本沒啥區別
③ ZRANGEBYSCORE:獲取指定分數范圍內的元素
語法:ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
- 按升序返回
score在[min, max]區間內的元素,如果帶上withscores則將score一起返回。 - 之前的
zrange是通過元素排名返回,zrangebyscore則是通過score區間返回。 - 備注:這個命令可能在6.2.0之后廢棄,并且功能合并到ZRANGE中
時間復雜度均為:O(log(N)+M)
案例如下:
127.0.0.1:6379> zrevrange myzset 0 -1 WITHSCORES
1) "one"
2) "100"
3) "two"
4) "40"127.0.0.1:6379> ZRANGEBYSCORE myzset (1 (100
1) "two"
1.4 ZPOPMAX|MIN & BZPOPMAX|MIN
① ZPOPMAX:刪除并返回分數最高的count個元素
- 如果多個元素的
score相同,那么會按照member的字典序進行比較,字典序高的先刪除
② ZPOPMIN:刪除并返回分數最小的count個元素
③ BZPOPMAX:讀取并刪除zset最大元素,如果沒有元素則陷入阻塞
- 可以設置超時時間
timeout,以秒為單位,如果超過時間了,返回nil。 - 如果超時時間設置為
0,則一直阻塞,不會超時。
④ BZPOPMIN:ZPOPMIN 的阻塞版本
案例如下:
127.0.0.1:6379> zpopmax myzset
1) "one"
2) "100"
127.0.0.1:6379> bzpopmin myset 10
(nil)
(10.03s)127.0.0.1:6379> bzpopmin myzset 10
1) "myzset"
2) "two"
3) "40"
1.5 ZRANK & ZREVRANGE
① ZRANK:獲取成員的下標
- 命令:
ZRANK key member或ZREVRANK key member - 返回指定元素
member的排名,這個排名就是socre從小到大的順序,從0開始排,也可以當作下標
② ZREVRANGE: 返回指定元素member的排名,這個排名就是socre從大到小的順序,從0開始排
1.6 ZREM & ZREMRANGEBYRANK & ZREMRANGEBYSCORE
① ZREM:刪除指定的元素(語法:ZREM key member [member ...]
② ZREMRANGEBYRANK:按照排名刪除元素(語法:ZREMRANGE BYRANK key start stop
③ ZREMRANGEBYSCORE:按照分數刪除元素(語法:ZREMRANGE BYSCORE key min max
2. 集合間操作
2.1 ZINTERSTORE – 交集
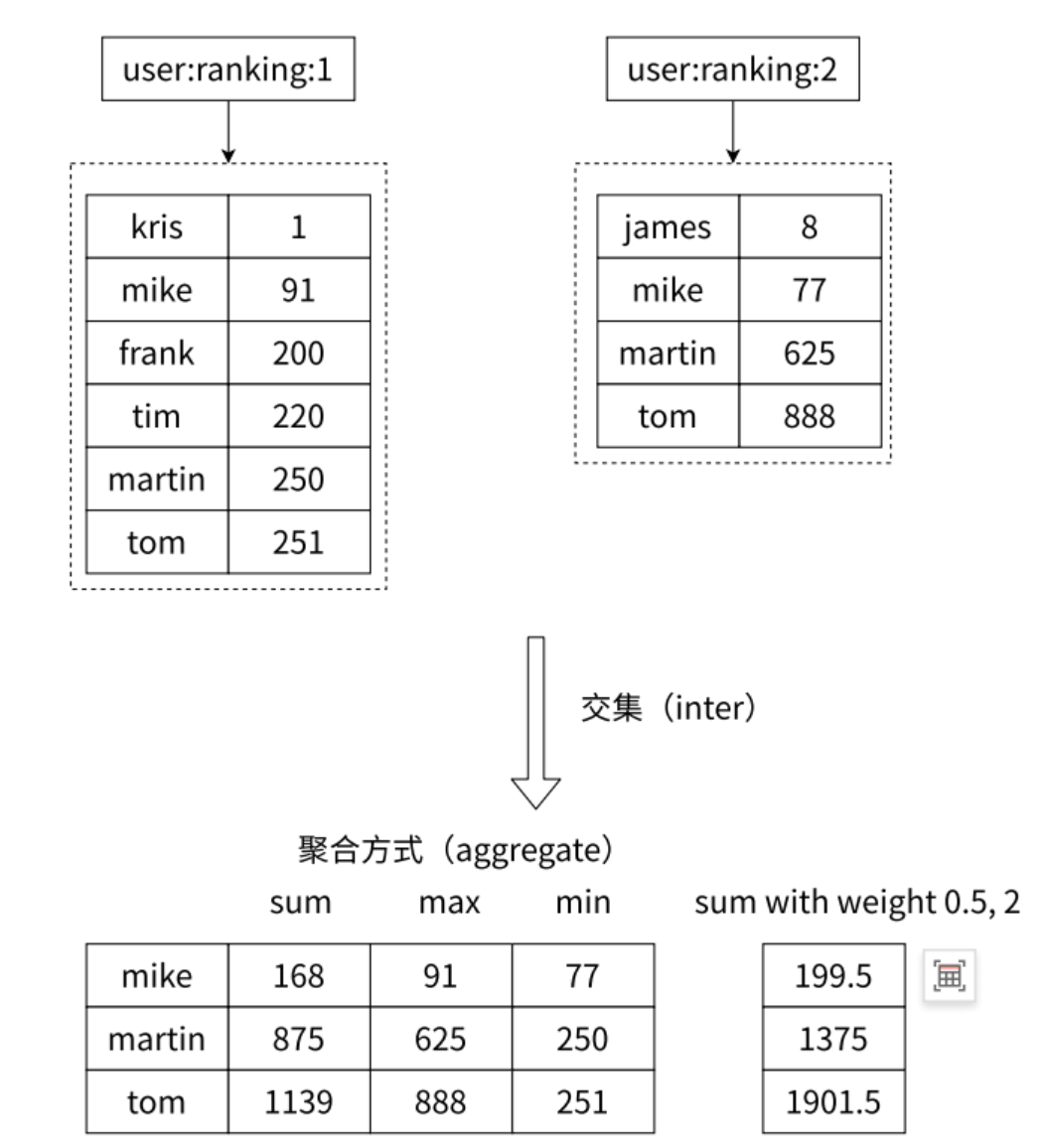
-
功能:求出給定有序集合中元素的交集并保存進?標有序集合中,在合并過程中以元素為單位進?合并,元 素對應的分數按照不同的聚合方式和權重得到新的分數
-
語法:
ZINTERSTORE dest numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE]- 注意:numkeys必須準確填寫,以便后面將參數準確解析
destination:輸出結果到給zset中numkeys:指定后續輸入的key的個數(后面會詳細講解weights:權重,每一個zset都配一個weight,計算時score乘對應的weightaggreate:score的合并方式sum:求和(默認值)min:取最小max:取最大
-
返回值:目標集合中的元素個數
-
時間復雜度:O(N?K)+O(M?log(M))O(N?K)+O(M?log(M))O(N?K)+O(M?log(M)),N是輸?的有序集合中最小的有序集合的元素個數,K是輸入了幾個有序集合,M是最終結果的有序集合的元素個數
這時間復雜度怎么來的?取決于源碼,我們學習的是一種 解決問題 的能力,可以分解為兩部分來理解:
- O(N?K)O(N*K)O(N?K) :這部分表示了在遍歷所有輸入有序集合時所需的時間。對于每個元素,都需要檢查它是否存在于其他所有有序集合中。這里假設最壞情況下,每次查找操作都是線性的,即需要檢查整個集合。因此,如果最小的集合有 N 個元素,而總共有 K 個集合,則總的比較次數大約為 N * K。這解釋了 O(N?K)O(N*K)O(N?K) 的部分。
- O(M?log(M))O(M*log(M))O(M?log(M)): 當確定哪些元素應該被加入到結果集中后,這些元素需要根據它們的分數進行排序以形成一個新的有序集合。即使Redis內部使用了高效的數據結構(如跳表)來保持有序性,將 M 個元素插入這樣一個數據結構并保持其有序通常需要 O(M*log(M)) 的時間。這是因為每插入一個元素可能需要調整數據結構,使得插入操作平均來說接近于 log(M) 的時間復雜度。
ZINTERSTORE操作首先通過遍歷和比較各集合中的元素來找到交集成員,然后對這些成員按分數排序,從而形成了上述的時間復雜度公式。這種設計保證了即使在處理較大規模數據時也能相對高效地完成交集運算。不過,實際性能還會受到具體實現細節、數據分布等因素的影響。
樣例:
127.0.0.1:6379> zadd zset1 20 a 12 b
127.0.0.1:6379> zadd zset2 1 a 5 b127.0.0.1:6379> zinterstore zset3 2 zset1 zset2 weights 1 100 aggregate sum
(integer) 2
127.0.0.1:6379> zrange zset3 0 -1 WITHSCORES
1) "a"
2) "120"
3) "b"
4) "512"
此處創建了兩個zset,通過zinterstore合并,其中zset1的權重是1,zset2的權重是100,以sum方式合并。實現分數計算:最后求出交集a: 1 * 100 + 20,b: 5 * 100 + 12。
思考:關于 numkeys 參數
- 功能:numkeys 參數指定了后續參與交集運算的 key 的數量。
- 重要性:很多命令支持多個 key,如 zadd, mget, mset 等。通過 numkeys 明確指定 key 的個數可以避免選項和 keys 混淆,確保命令解析的準確性。
類比 HTTP 協議, HTTP 首行與請求頭:Content-Length 字段描述了請求體(正文)的長度。
粘包問題:
- 如果缺少 Content-Length 或者數據錯誤,可能會導致粘包問題。
- TCP 特點:基于 TCP 的傳輸是面向字節流的,容易產生粘包問題。
解決粘包問題的方法
- 明確包的長度。
- 明確包的邊界。
有序集合中的元素比較
- 成員 (member):是有序集合中元素的本質。
- 分數 (score):僅作為輔助排序的工具。
- 相同成員的處理:如果不同集合中的成員相同但分數不同,在進行交集合并時,最終分數如何計算取決于具體的聚合方式(如 SUM, MIN, MAX)。
有序集合的存儲與權重
- 結果存儲:需指定一個 key 來存儲交集運算的結果。
- 權重 (weight):在合并過程中,權重作為系數乘以當前分數,用于調整最終分數。
個人見解選擇:客觀因素相對穩定,而主觀因素變化較大。
2.2 ZUNIONSTORE – 并集
這個參數和 zinterstore 完全一致,只是從交集變成并集。
- 功能:求出給定有序集合中元素的 并集 并保存進目標有序集合中,在合并過程中以元素為單位進行合并,元素對應的分數按照不同的聚合方式和權重得到新的分數
- 語法:
ZUNIONSTORE dest numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE ] - 返回值:目標集合中的元素個數
三、內部編碼
有序集合是由 ziplist (壓縮列表) 或 skiplist (跳躍表) 組成的。
1. ziplist – 壓縮鏈表
當數據比較少時,有序集合使用的是 ziplist 存儲的(減少內存使用),有序集合使用 ziplist 格式存儲必須滿足以下兩個條件:
- 有序集合保存的元素個數要小于
zset-max-ziplist-entries配置 (默認128個) ; - 有序集合保存的所有元素成員的長度都必須小于
zset-max-ziplist-value配置(默認64字節) 。
2. skiplist – 跳表
如果不能滿足以上兩個條件中的任意一個,有序集合將會使用 skiplist 結構進行存儲。
- 跳表的定義:跳表是一種特殊的鏈表結構,具有多層次的索引機制,類似于 B+樹 的部分性質。
- 查詢效率:由于采用了多層次索引,跳表在查詢元素時的時間復雜度為 O(logN),這意味著隨著數據量的增長,查詢效率仍然保持較高的水平。
- 適用場景:結合了鏈表和樹的優點,提供了一種高效的范圍查詢解決方案,尤其適合大數據量下的范圍查詢需求。
關于 vs B+
特點:
- 平衡性:B+樹是一種自平衡的多路搜索樹,每個節點可以有多個子節點,這使得樹的高度保持較低。
- 鍵值分布:所有鍵值都出現在葉子節點上,非葉子節點僅作為索引使用。
- 有序性:葉子節點通過指針鏈接起來,形成一個有序鏈表,便于范圍查詢。
- 磁盤友好:B+樹的設計特別適合于磁盤等塊設備的訪問模式,因為它的節點大小通常與磁盤頁大小相匹配,從而減少了I/O操作次數。
優點:
- 高效的范圍查詢:由于葉子節點是相連的,因此可以快速地進行范圍掃描。
- 適用于數據庫和文件系統:非常適合需要頻繁讀取和寫入大量數據的應用場景。
缺點:
- 插入和刪除操作可能較復雜:當節點滿時需要分裂,空閑時需要合并或重新分配。
- 實現較為復雜:涉及到節點分裂、合并等操作,實現起來比跳表更復雜。
四、使用場景
1. 排行榜系統
有序集合比較典型的使用場景就是排行榜系統。例如學生成績的排名。某視頻(博客等)網站的用戶點贊、播放排名、電商系統中商品的銷量排名等。我們以博客點贊為例。
① 添加用戶贊數:例如小編Tom發表了一篇博文,并且獲得了10個贊。
Copyzadd user:ranking arcticle1 10
② 取消用戶贊數:這個時候有一個讀者又覺得Tom寫的不好,又取消了贊,此時需要將文章的贊數從榜單中減去1,可以使用zincrby。
Copyzincrby user:ranking arcticle1 -1
③ 查看某篇文章的贊數
CopyZSCORE user:ranking arcticle1
④ 展示獲取贊數最多的十篇文章:此功能使用zrevrange命令實現:
Copyzrevrangebyrank user:ranking 0 9
2. 電話號碼(姓名)排序
使用有序集合的 ZRANGEBYLEX 或 ZREVRANGEBYLEX 可以幫助我們實現電話號碼或姓名的排序,我們以ZRANGEBYLEX為例
注意:不要在分數不一致的SortSet集合中去使用 ZRANGEBYLEX和 ZREVRANGEBYLEX 指令,因為獲取的結果會不準確。
① 電話號碼排序:我們可以將電話號碼存儲到SortSet中,然后根據需要來獲取號段:
Copyredis> zadd phone 0 13100111100 0 13110114300 0 13132110901
(integer) 3
redis> zadd phone 0 13200111100 0 13210414300 0 13252110901
(integer) 3
redis> zadd phone 0 13300111100 0 13310414300 0 13352110901
(integer) 3
② 獲取所有號碼:
Copyredis> ZRANGEBYLEX phone - +
1) "13100111100"
2) "13110114300"
3) "13132110901"
4) "13200111100"
5) "13210414300"
6) "13252110901"
7) "13300111100"
8) "13310414300"
9) "13352110901"
③ 獲取132號段:
Copyredis> ZRANGEBYLEX phone [132 (133
1) "13200111100"
2) "13210414300"
3) "13252110901"
④ 獲取132、133號段:
Copyredis> ZRANGEBYLEX phone [132 (134
1) "13200111100"
2) "13210414300"
3) "13252110901"
4) "13300111100"
5) "13310414300"
6) "13352110901"
⑤ 姓名排序:將名稱存儲到SortSet中:
Copyredis> zadd names 0 Toumas 0 Jake 0 Bluetuo 0 Gaodeng 0 Aimini 0 Aidehua
(integer) 6
⑥ 獲取所有人的名字:
Copyredis> ZRANGEBYLEX names - +
1) "Aidehua"
2) "Aimini"
3) "Bluetuo"
4) "Gaodeng"
5) "Jake"
6) "Toumas"
⑦ 獲取名字中大寫字母A開頭的所有人:
Copyredis> ZRANGEBYLEX names [A (B
1) "Aidehua"
2) "Aimini"
⑧ 獲取名字中大寫字母C到Z的所有人:
Copyredis> ZRANGEBYLEX names [C [Z
1) "Gaodeng"
2) "Jake"
3) "Toumas"
小結
本篇文章我們總結了Redis 有序集合對象的內部實現、常用命令以及常用的一些場景,有序集合提供了獲取指定分數和元素范圍查詢、計算成員排名等功能,合理的利用有序集合,能幫助我們在實際開發中解決很多問題。那么大家在項目中對Redis有序集合對象的使用都有哪些場景呢,歡迎在評論區給我留言和分享,我會第一時間反饋!我們共同學習與進步!



——判斷推理(聽課后強化訓練))





)




指南)



:文法+單詞第7回3)
)
