摘要:
截至2025年,大型語言模型(LLM)已展現出驚人的能力,但其內在的“黑箱”特性和對深層語義理解的局限性也日益凸顯。本報告旨在深入探討一個充滿潛力的前沿交叉領域:借鑒地球上最古老、最精密的語言處理器——人類大腦的運行機制,來指導下一代NLP技術的發展。我們將系統性地分析五個關鍵的交匯點:預測編碼理論、語義角色標注的神經基礎、詞義表征的腦機共鳴、基于效價-喚醒度的情感分析,以及隱喻理解中的具身認知。通過整合最新的神經科學發現與NLP工程實踐,本報告將揭示神經科學為NLP工程師繪制的這張“藏寶圖”,如何引領我們走向更深邃、更類人的機器智能。
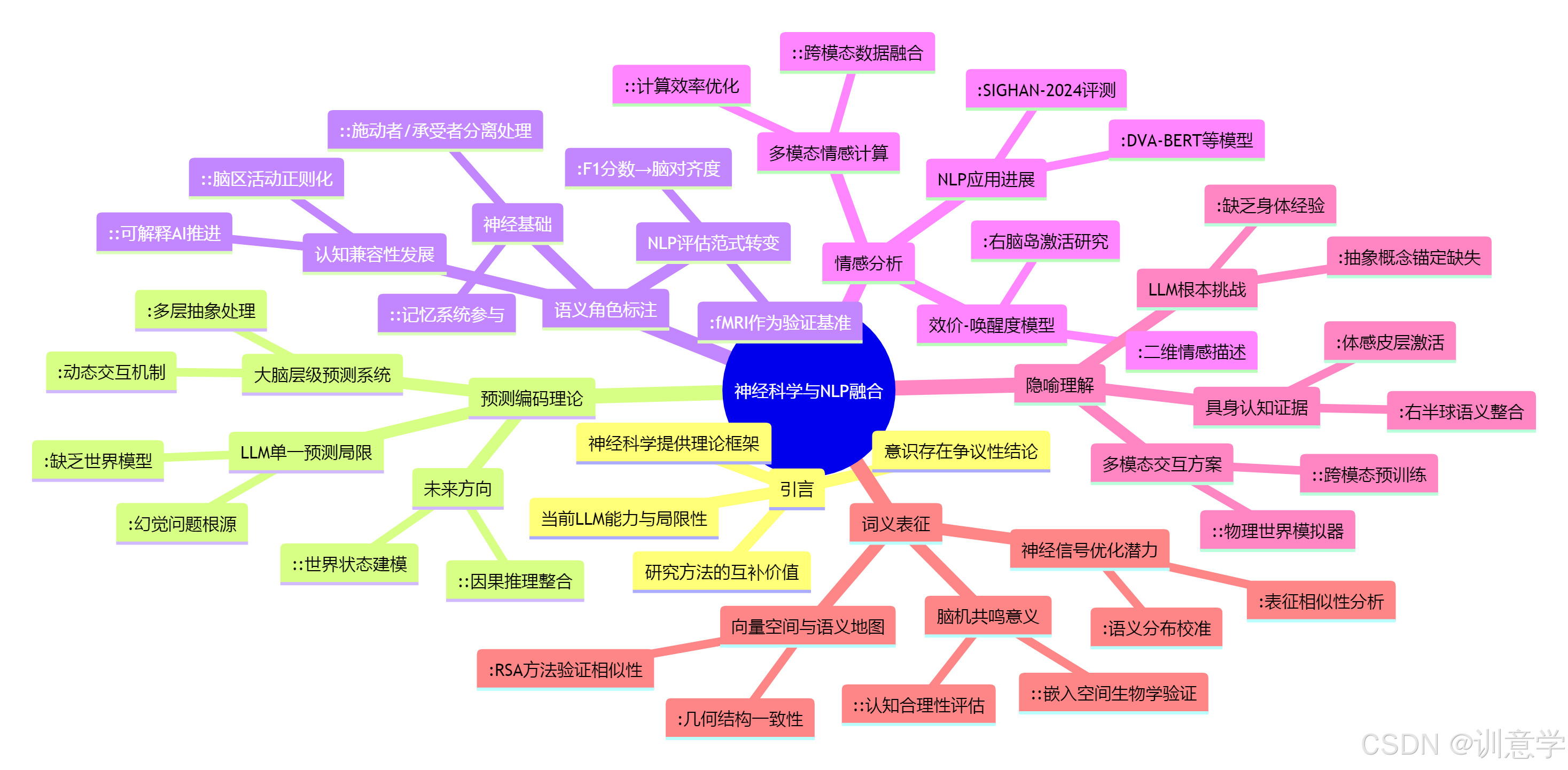
引言:從模仿文本到理解世界
現代NLP,尤其是以Transformer架構為核心的大型語言模型,其根本任務是基于海量文本數據預測序列中的下一個詞?。這一范式無疑是成功的,它催生了GPT-4、BERT等一系列強大的模型?。然而,這種成功也帶來了一個根本性的問題:這種基于統計規律的“模仿”是否等同于真正的“理解”?人類在處理語言時,遠不止于預測下一個詞,我們會構建復雜的意義網絡、理解事件的因果邏輯、感受細膩的情感,并通曉抽象的隱喻。
為了突破當前模型的瓶頸,研究者們將目光投向了神經科學。大腦,這個經過數百萬年進化而成的“黑箱”,為我們提供了一個無與倫比的參照系。通過功能性磁共振成像(fMRI)、腦電圖(EEG)等技術,我們得以窺見大腦在處理語言時的精妙運作。本報告將逐一剖析神經科學在關鍵NLP任務上的啟示,探索如何將這些生物學洞見轉化為可行的計算模型,從而開啟一場從“文本模仿”到“世界理解”的范式革命。
一、 深層語義分析:超越“下一個詞”的預測編碼理論
1.1 理論基礎:大腦中的多層次預測系統
當前LLM的核心機制可以被視為一種預測形式,即預測下一個詞元?。然而,神經科學中的“預測編碼”(Predictive Coding)理論揭示了一個遠為復雜的圖景。該理論認為,大腦是一個主動的預測機器,它不僅在底層預測即將到來的感官信號(如詞語),更在認知的高層不斷生成和修正關于世界狀態的抽象預測(如事件的意義、對話的意圖)。語言理解是一個自上而下(高層意義預測)與自下而上(感官信息輸入)不斷交互、驗證、修正期望的動態過程。這意味著,大腦的語言處理是構建在一個從具體到抽象的意義階梯之上的。
1.2 NLP的現狀與挑戰:從單一預測到層級推理的鴻溝
盡管“預測”是LLM訓練的核心,但其現有的訓練目標,如掩碼語言模型(MLM)或下一句預測(NSP),大多停留在文本表層?。這些模型缺乏一個明確的、類似大腦的預測層級結構來處理抽象意義。
截至2025年,盡管預測編碼的理論在神經科學界和認知科學界對語言的解釋力越來越強?但在主流NLP模型中,我們尚未看到其具體的、成型的架構設計或實現 (Query: What are the specific architectural designs for NLP models implementing predictive coding theory in 2025?)。相關的搜索查詢顯示,目前還沒有名為“預測編碼模型”并能在標準NLP基準(如GLUE, SuperGLUE)上取得優異性能的具體模型被廣泛報道?; Query: What are the names of specific NLP models that have successfully integrated predictive coding as of 2025...?)。這表明,將這一精妙的神經理論轉化為高效的計算架構,仍然是NLP領域面臨的重大挑戰和未來重要的研究方向。
1.3 未來展望:構建具備世界模型的NLP
預測編碼理論對NLP的終極啟示在于,未來的模型需要超越單純的文本序列預測,構建一個能夠預測抽象概念和世界狀態的內部模型。這意味著模型不僅要學習語言的統計規律,更要學習語言所描述的世界的因果、物理和社會常識。這可能是通往解決LLM“幻覺”問題?和實現真正推理能力的關鍵路徑。
二、 語義角色標注(SRL):解碼大腦中的“事件劇場”
2.1 神經基礎:“誰對誰做了什么”的生物學證據
語義角色標注(SRL)是NLP的一項核心任務,旨在識別句子中的謂詞-論元結構,即“誰(施動者)對誰(承受者)做了什么”?。這看似是一個純粹的語言學任務,但fMRI研究發現,它在大腦中有著清晰的生物學對應。當人們處理“施動者”(Agent)和“承受者”(Patient)時,被激活的神經區域存在顯著差異。特別是處理事件的承受者時,大腦會調動更廣泛的認知和記憶相關腦區,仿佛在大腦中為不同的語義角色分配了不同的“演員”和“舞臺”。
2.2 NLP的實踐:從驗證到評估的新范式
在NLP領域,基于神經網絡,特別是深度學習模型(如RNN、LSTM和Transformer)的SRL方法已經成為主流,并取得了顯著的性能?。這些模型能夠自動學習復雜的句法和語義特征,極大地提升了標注的準確性。
然而,神經科學的洞見為SRL研究開辟了一個新的維度。截至2025年,我們尚未發現有研究成功地將fMRI數據作為直接輸入來“整合”進SRL模型以提升其在傳統NLP指標(如F1分數)上的性能 (Query: How is fMRI data integrated into semantic role labeling models to improve performance in NLP?; Query: 2025年基于fMRI的語義角色標注模型在NLP任務中的準確率提升百分比是多少?)。相反,研究的焦點轉向了一個更深刻的問題:NLP模型的內部表征與大腦的神經活動模式有多相似?
“Neural Language Taskonomy”等前沿研究項目發現,不同的NLP任務在預測大腦活動方面的能力各不相同,而SRL恰恰是其中與大腦語言處理區域活動高度相關的任務之一?。這意味著,一個在SRL任務上表現優異的模型,其內部形成的對事件結構的表征,在某種程度上模擬了大腦的處理方式。因此,fMRI數據正在從一個潛在的“訓練特征”轉變為一種全新的“評估基準”?。我們可以通過比較模型在處理相同句子時產生的內部激活模式與fMRI記錄的人腦活動模式的相似度,來評估該模型“理解”語義角色的生物學合理性?。
2.3 未來展望:邁向認知兼容的SRL
這一轉變意義重大。它意味著未來的SRL模型設計,除了追求更高的F1分數外,還將追求更高的“大腦對齊度”(Brain Alignment)。通過將神經科學數據作為模型評估乃至正則化的一部分,我們有望開發出不僅準確,而且其決策過程更符合人類認知習慣的SRL系統,這對于構建可解釋、可信賴的AI至關重要。
三、 情感分析:構建更細膩的二維情感羅盤
3.1 神經基礎:超越褒貶的效價-喚醒度模型
傳統的情感分析通常將情感劃分為“積極”、“消極”、“中性”等離散類別?。然而,人類的情感體驗遠比這豐富。“狂喜”和“寧靜”同為積極情緒,但其生理和心理狀態截然不同。神經科學研究普遍采用“效價-喚醒度”(Valence-Arousal, VA)二維模型來更精確地描述情感?。其中,“效價”衡量情感的愉悅程度(從積極到消極),“喚醒度”衡量情感的強度(從平靜到激動)。fMRI研究進一步揭示,大腦在處理這兩個維度時調用了不同的神經回路,例如右側腦島在處理效價和喚醒度沖突的情感(如高喚醒度的積極情緒)時會表現出特殊激活。
3.2 NLP的進展:維度情感分析的興起
受此啟發,NLP領域近年來大力發展“維度情感分析”(Dimensional Sentiment Analysis),直接預測文本所表達情感的效價和喚醒度數值?。這一領域在2025年已取得長足進步。研究者們利用BERT等大型預訓練模型作為基礎,開發出專門用于VA預測的模型,如DVA-BERT?,并在專門標注了VA值的語料庫(如Chinese EmoBank)上進行訓練和評估?。SIGHAN-2024等學術評測也設立了相關的任務,推動了技術的發展?。
3.3 工具、挑戰與效率
目前,已有多種工具和框架可用于實現VA情感分析。雖然VADER(其名稱本身即意為“效價感知詞典和情感推理器”)等傳統工具提供了基礎?但基于深度學習的方法正成為主流?。
然而,這一方向也面臨著挑戰。首先是高質量VA標注數據的稀缺性和主觀性問題?。其次是計算成本。與傳統的分類模型相比,基于大型模型的VA回歸模型通常計算成本更高。有研究提出,可以采用傳統機器學習與VA模型結合的兩階段分層系統,在保持較好性能的同時降低對計算資源的需求,這為資源受限場景提供了解決方案?。
3.4 未來展望:通往精細化情感智能
基于VA模型的維度情感分析,使機器能夠更細膩地捕捉和理解文本背后復雜的人類情感,這在人機交互、心理健康監測、輿情分析等領域具有巨大的應用價值。未來的研究將聚焦于構建更大規模、更高質量的VA語料庫,并探索更高效、更魯棒的多模態(結合文本、語音、視覺)情感分析模型。
四、 隱喻理解:為機器注入“具身認知”
4.1 神經基礎:根植于身體經驗的抽象概念
隱喻是人類語言創造力和抽象思維的核心。當我們說“抓住一個概念”或“度過了艱難的一天”時,我們并非在進行字面描述。神經科學的“具身認知”(Embodied Cognition)理論為理解這一現象提供了革命性的視角。fMRI研究驚人地發現,當人們理解與觸覺相關的隱喻(如“艱難的/rough的一天”)時,大腦中負責處理真實觸覺的體感皮層會被激活。這有力地證明了我們的抽象概念并非憑空存在,而是深深地根植于我們的身體感知和運動經驗之中。此外,大腦右半球在處理新奇隱喻時扮演著關鍵角色,它負責激活更廣泛的語義網絡,幫助我們在看似不相關的概念間建立聯系。
4.2 NLP的根本性挑戰:無“身”之“心”的局限
這一發現對當前主流的NLP模型提出了一個根本性的挑戰。LLM通過學習海量文本數據中的詞語共現關系來處理語言,它們沒有“身體”,沒有與物理世界交互的感知經驗。因此,它們對隱喻的“理解”可能只是一種基于上下文的淺層模仿,而非真正把握其背后基于身體經驗的深層含義。在我們的搜索查詢中,幾乎沒有找到關于在NLP模型中成功實現具身認知以進行隱喻分析的具體研究或應用。這表明,截至2025年,該領域仍處于非常初期的探索階段。
4.3 未來展望:構建多模態、世界交互的AI
神經科學的啟示是明確的:要讓機器真正理解隱喻,乃至更廣泛的抽象概念,僅靠文本學習是遠遠不夠的。未來的研究方向必須走向多模態學習,將語言模型與視覺、聽覺、觸覺等信息相結合。更進一步,需要為AI構建一個能夠與物理世界或高質量模擬環境進行交互的“身體”模型。通過這種方式,AI可以在與世界的互動中,將語言符號與其所指代的感知運動經驗“錨定”在一起,從而為抽象概念建立起堅實的“地基”。這不僅是攻克隱喻理解的必由之路,也是通向通用人工智能(AGI)的關鍵一步。
五、 詞義表征:從向量空間到大腦語義地圖的映射
最后,我們回到NLP中最基礎也最成功的領域之一:詞嵌入(Word Embeddings)。該技術將詞語映射到高維向量空間,使得意義相近的詞語在空間中也彼此靠近?。這種思想與人腦組織語義知識的方式驚人地相似。
神經科學中的“表征相似性分析”(Representational Similarity Analysis, RSA)等方法,可以直接比較不同“系統”(如人腦不同區域、人腦與AI模型)中概念表征的幾何結構。多項研究通過這種方法比較了NLP詞向量模型中的詞間關系矩陣和人腦在處理這些詞語時產生的神經活動模式矩陣。結果令人振奮:兩者之間存在顯著的相關性?。
這意味著,盡管實現機制(硅基芯片 vs. 碳基神經元)天差地別,但為了高效地組織和處理海量的語言信息,人工神經網絡“進化”出的語義表征結構,在某種程度上復現了生物大腦的解決方案。這不僅從生物學角度驗證了當前詞嵌入方法的有效性,也為未來的優化提供了方向。我們可以設想,利用神經信號作為一種“監督”或“校準”信號,直接優化詞向量的分布,從而創造出更精準、更符合人類認知的“語義地圖”。
結論:一場雙向奔赴的智慧探索
從預測編碼的理論前沿,到語義角色的認知評估;從情感分析的維度深化,到隱喻理解的具身挑戰;再到詞義表征的腦機共鳴——神經科學正在為自然語言處理的未來發展提供一張日益清晰的“藏寶圖”。
截至2025年,這條探索之路呈現出不均衡的發展態勢:
- 較為成熟的共鳴區:?詞義表征和維度情感分析,神經科學的洞見已經轉化為具體的模型和應用,并取得了顯著進展。
- 新興的評估與驗證區:?語義角色標注,神經科學數據更多地被用作評估模型認知合理性的新基準,而非直接提升性能的工具。
- 亟待開墾的前沿區:?預測編碼和具身認知(隱喻),相關的神經理論極具啟發性,但如何將其轉化為可計算、可擴展的NLP模型架構,仍是該領域最艱巨也最激動人心的挑戰。
這場神經科學與自然語言處理的交匯,是一場雙向奔赴的智慧探索。我們不僅在用大腦的奧秘點亮人工智能的未來,也在用人工智能的工具和模型來反思和驗證關于大腦和心智的理論。前路漫漫,道阻且長,但我們有理由相信,沿著這張“藏寶圖”前進的每一步,都將讓我們離“理解”這一智能的終極本質更近一點。
?
)


 RDB和AOF有什么區別?)



)


![Linux應用軟件編程---網絡編程(TCP并發服務器構建:[ 多進程、多線程、select ])](http://pic.xiahunao.cn/Linux應用軟件編程---網絡編程(TCP并發服務器構建:[ 多進程、多線程、select ]))

)


)



