作者:鈺誠
簡介
傳統的負載均衡算法主要設計用于通用的 Web 服務或微服務架構中,其目標是通過最小化響應時間、最大化吞吐量或保持服務器負載平衡來提高系統的整體效率,常見的負載均衡算法有輪詢、隨機、最小請求數、一致性哈希等。然而,在面對 LLM 服務時,這些傳統方法往往暴露出以下幾個關鍵缺陷:
-
忽略任務復雜度差異:LLM 推理請求的復雜度差異極大。例如,一個長文本生成任務可能需要數十倍于短文本分類任務的計算資源。而傳統負載均衡器無法感知這種差異,容易導致某些節點過載,而其他節點空閑,造成資源浪費和響應延遲。
-
缺乏對 GPU 資源水位的感知:在 LLM 推理服務中,計算瓶頸主要集中在 GPU 上,傳統負載均衡器往往無法感知到這一細粒度的資源消耗情況,導致某些 GPU 節點因顯存不足而拒絕請求或響應緩慢,而其他節點卻處于空閑狀態。
-
缺乏對 KV Cache 的復用能力:在并發請求處理中,如果多個請求具有相似的前綴,則它們的 KV Cache 可能存在重疊部分,可以通過共享或壓縮的方式減少顯存占用并提升生成速度。傳統負載均衡策略并未考慮請求之間的語義相似性或 KV Cache 的可復用性,難以將具有潛在復用價值的請求分配到同一 GPU 實例上,從而錯失優化機會。
針對 LLM 服務的特點,Higress AI 網關以插件形式提供了面向 LLM 服務的負載均衡算法,包括全局最小請求數負載均衡、前綴匹配負載均衡以及 GPU 感知負載均衡,能夠在不增加硬件成本的前提下,提升系統的吞吐能力、降低響應延遲,并實現更公平、高效的任務調度。
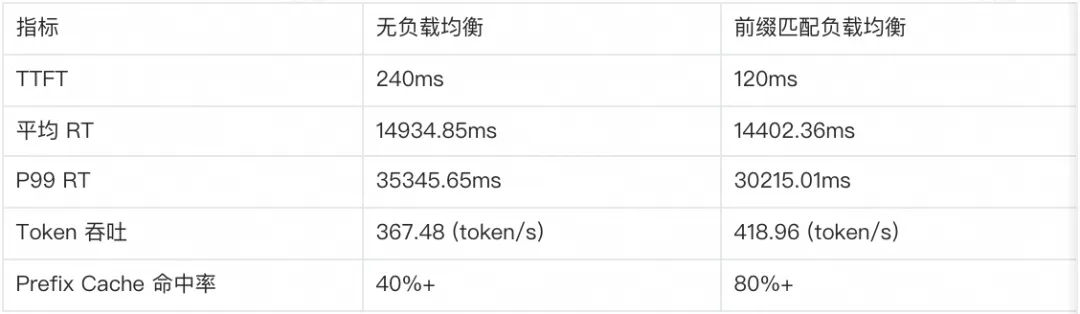
以前綴匹配負載均衡為例,壓測工具使用 NVIDIA GenAI-Perf,設置每輪輸入平均為 200 token,輸出平均為 800 token,并發為 20,每個會話包含 5 輪對話,共計 60 個會話,性能指標前后對比如下:
技術選型
目前已經有很多優秀的開源項目,例如 Envoy AI Gateway、AIBrix 等,基于 Envoy External Processing 機制外接一個負載均衡器實現面向 LLM 的負載均衡,負載均衡器以 sidecar 或者 K8s 服務形式部署。
Higress AI 網關以 wasm 插件形式提供了面向 LLM 服務的核心負載均衡能力,具有如下特點:
- 免運維:以 wasm 形式提供負載均衡能力,不需要用戶額外維護 sidecar,只需要在 Higress 控制臺開啟插件即可,部署運維成本大大降低。
- 熱插拔:即插即用,用戶僅需要在控制臺進行策略配置即可,開啟插件時采用面向 LLM 服務的專屬負載均衡策略,關掉插件后自動切換為服務基礎的負載均衡策略(輪詢、最小請求數、隨機、一致性哈希)。
- 易擴展:插件本身提供了多種負載均衡算法,并且在不斷豐富完善中,采用 go 1.24 編寫,代碼開源,如果有特殊需求,用戶可以基于現有插件進行定制。
- 全局視野:借助 Redis,網關的多個節點具有全局視野,負載均衡更加公平、高效。
- 細粒度控制:插件可以在實例級、域名級、路由級、服務級等不同粒度進行生效,方便用戶做細粒度的控制。
負載均衡算法介紹
接下來,本文會介紹 Higress AI 網關提供的三種負載均衡算法:全局最小請求數負載均衡、前綴匹配負載均衡、GPU 感知負載均衡。
全局最小請求數負載均衡
在分布式環境中,網關實例往往具有多個節點,傳統的負載均衡策略是每個節點做局部的負載均衡,缺乏全局視野。在 Higress AI 網關中,我們借助 Redis 實現了全局最小請求數負載均衡算法,根據每個 LLM Pod 上正在處理的請求數進行負載均衡。
選取 Pod 的大致流程如下:
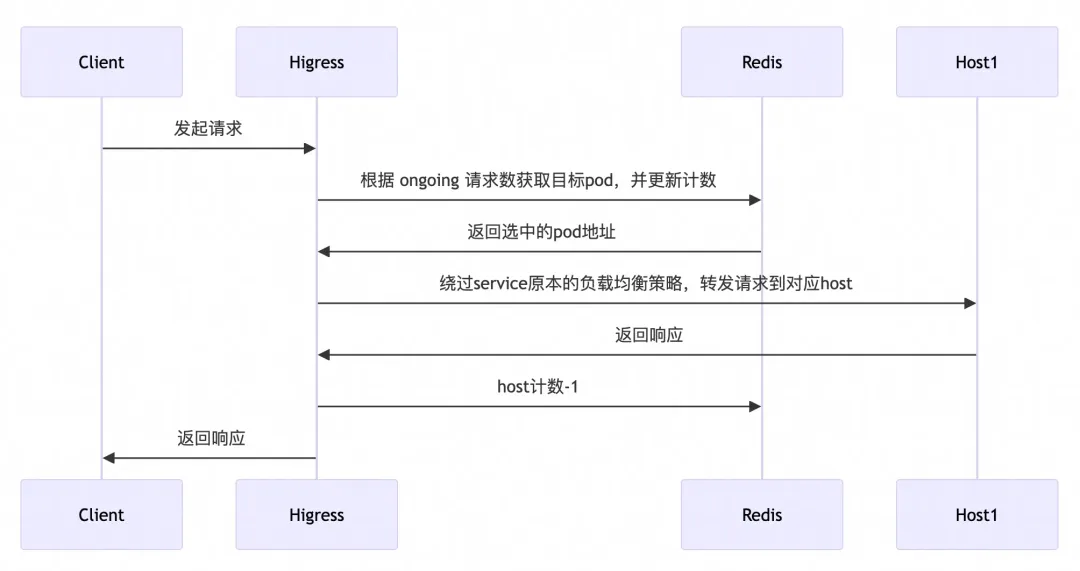
在全局最小請求數負載均衡中我們重點關注了請求異常(例如后端服務不可訪問、客戶端斷連、服務端斷連等)情況下的處理,通過在 HttpStreamDone 階段統一進行計數的變更可以保證異常中斷的請求也能夠得到計數的更新,避免因請求異常導致服務計數異常情況。
前綴匹配負載均衡
在多輪對話場景下,一次會話會涉及多次 LLM 的調用,多次調用時請求攜帶了相同的上下文信息,如果能夠感知上下文信息并將同屬一個會話的多次請求路由到相同的 LLM Pod 中,將能夠充分利用 LLM Pod 的 KV Cache,從而大幅提高請求的 RT、Token 吞吐等性能指標。
在 Higress AI 網關中,我們借助 Redis 實現了全局的前綴匹配負載均衡算法,能夠充分適應分布式環境,在請求到達網關時,會根據當前的前綴樹信息進行前綴匹配,如果能夠匹配成功,則會路由至對應 LLM Pod,如果匹配不到前綴,則會根據全局最小請求數負載均衡方法選出當前處理請求最小的 LLM Pod。
選取 Pod 的大致流程如下:
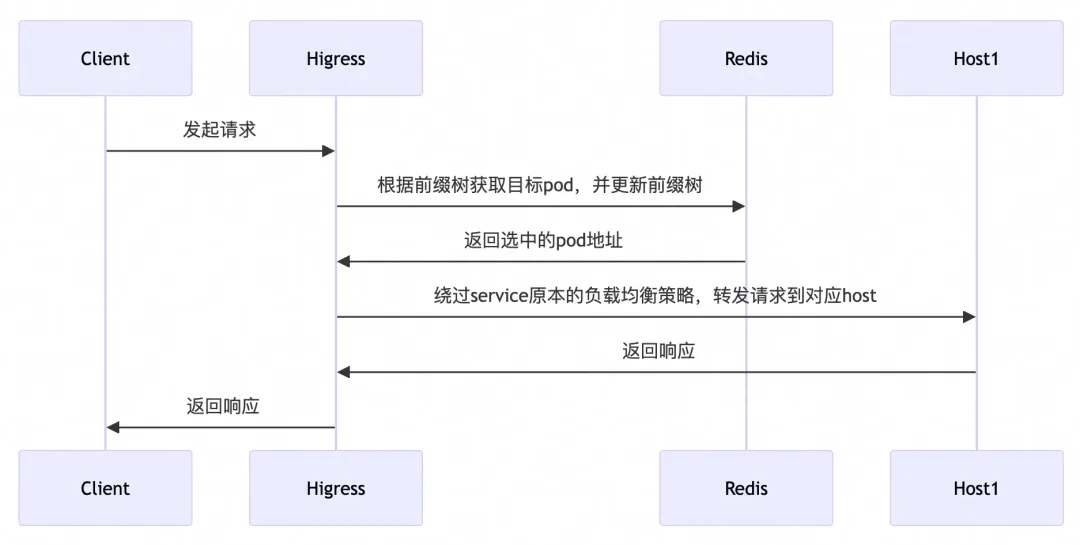
接下來簡單介紹如何在 Redis 中構建前綴樹。
首先將 LLM 請求的 messages 以 user 為界限劃分為不同的 block,并通過哈希獲得一個 16 進制字符串,如下圖所示,messages 被劃分為兩個 block,并且計算了每個 block 的 sha-1 值:

假設有一個請求被劃分成了 n 個 block,在進行前綴匹配時:
1)在 redis 中查詢?sha-1(block 1)?是否存在
- 如果不存在,前綴匹配失敗,采用全局最小請求數選擇 pod,pod 選取結束,根據當前請求內容更新前綴樹
- 如果存在,前綴匹配成功,記錄當前的 pod,轉步驟 2
2)在 redis 中查詢?sha-1(block 1) XOR sha-1(block 2)?是否存在
- 如果不存在,前綴匹配失敗,步驟1中選出來的 pod 即為目標 pod,根據當前請求內容更新前綴樹,pod 選取結束
- 如果存在,前綴匹配成功,轉步驟 3
3)在 redis 中查詢?sha-1(block 1) XOR sha-1(block 2) XOR … XOR sha-1(block n)?是否存在
- 如果不存在,前綴匹配失敗,步驟 2 中選出來的 pod 即為目標 pod,根據當前請求內容更新前綴樹,pod 選取結束
- 如果存在,前綴匹配成功,pod 選取結束
通過以上過程,能夠將同一個會話的多次請求路由至同一個 pod,從而提高 KV Cache 的復用。
GPU 感知負載均衡
一些 LLM Server 框架(如 vllm、sglang 等)自身會暴露一些監控指標,這些指標能夠實時反應 GPU 負載信息,基于這些監控指標可以實現 GPU 感知的負載均衡算法,使流量調度更加適合 LLM 服務。
目前已經有一些開源項目基于 envoy ext-proc 機制實現了 GPU 感知的負載均衡算法,但 ext-proc 機制需要借助一個外部進程,部署與維護較為復雜,Higress AI 網關實現了后臺定期拉取 metrics 的機制(目前支持 vllm),以熱插拔的插件形式提供了 GPU 感知的負載均衡能力,并且場景不局限于 K8s 環境,任何 Higress AI 網關支持的服務來源均可使用此能力。
選取 Pod 的大致流程如下:
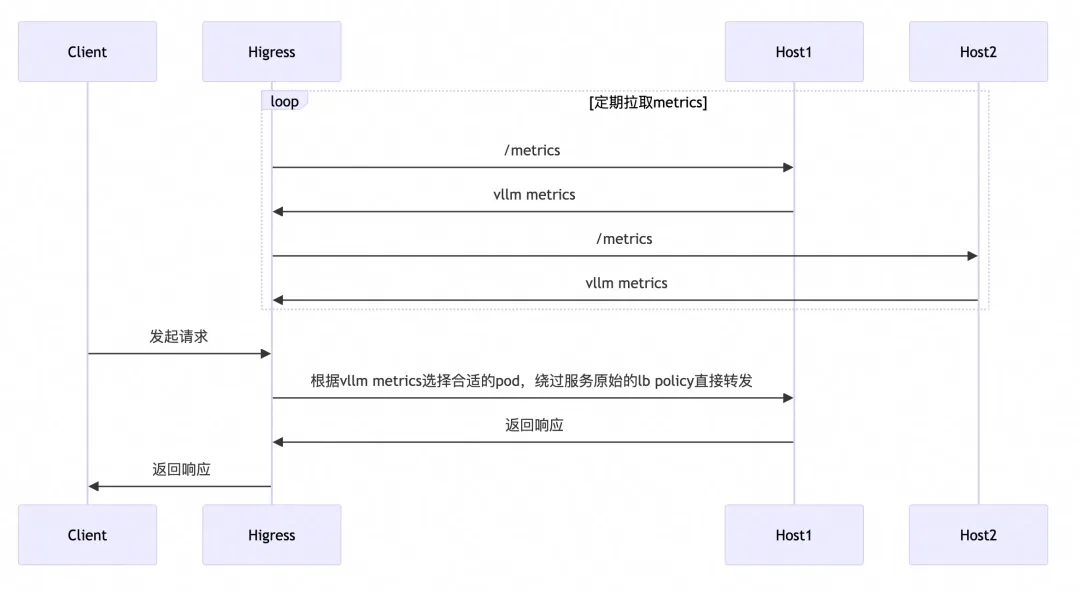
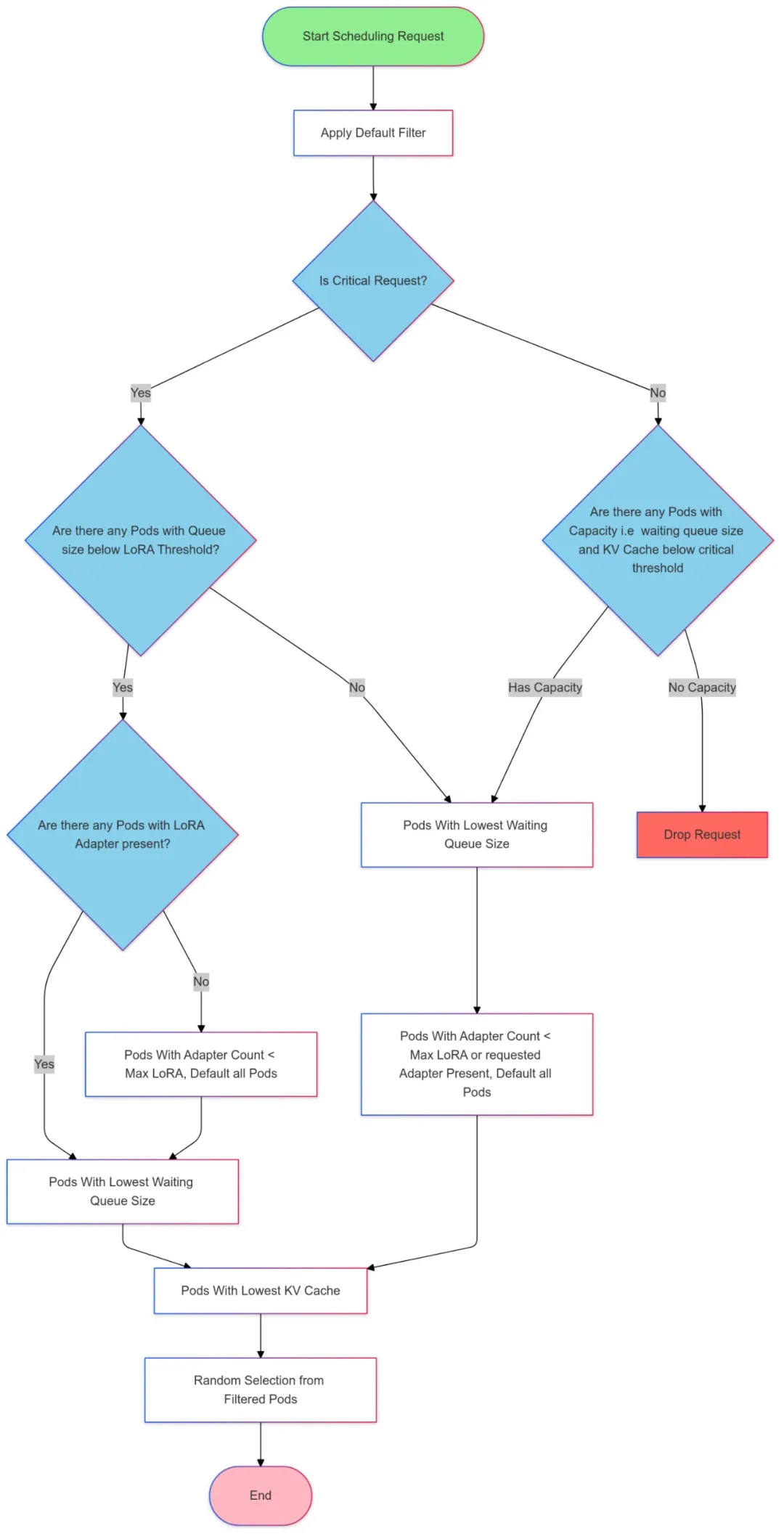
目前基于 metrics 的負載均衡策略遵循了?gateway-api-inference-extension【1】?的 pod 選取算法,根據 LoRA Adaotor 親和、隊列長度、KV Cache 使用率進行負載均衡,選取過程如下圖所示:
使用方法
以前綴匹配負載均衡為例:
- 準備 Redis 資源:登錄阿里云 Redis 控制臺【2】,創建Redis實例,并設置連接密碼。具體操作,請參見?Redis 快速入門概覽【3】。
- 準備 LLM 服務:以 ECS 形式基于 vllm 框架部署 llama3 模型,共 3 個節點。
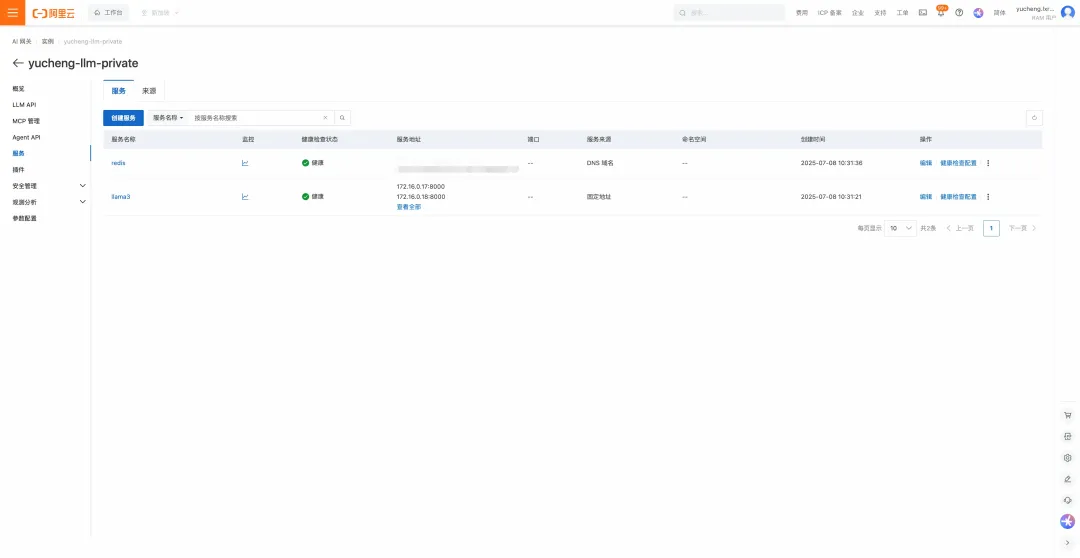
- 在網關配置服務:在網關實例中導入 Redis 服務以及 LLM 服務,其中 redis 為DNS類型服務,llama3 為固定地址類型服務。
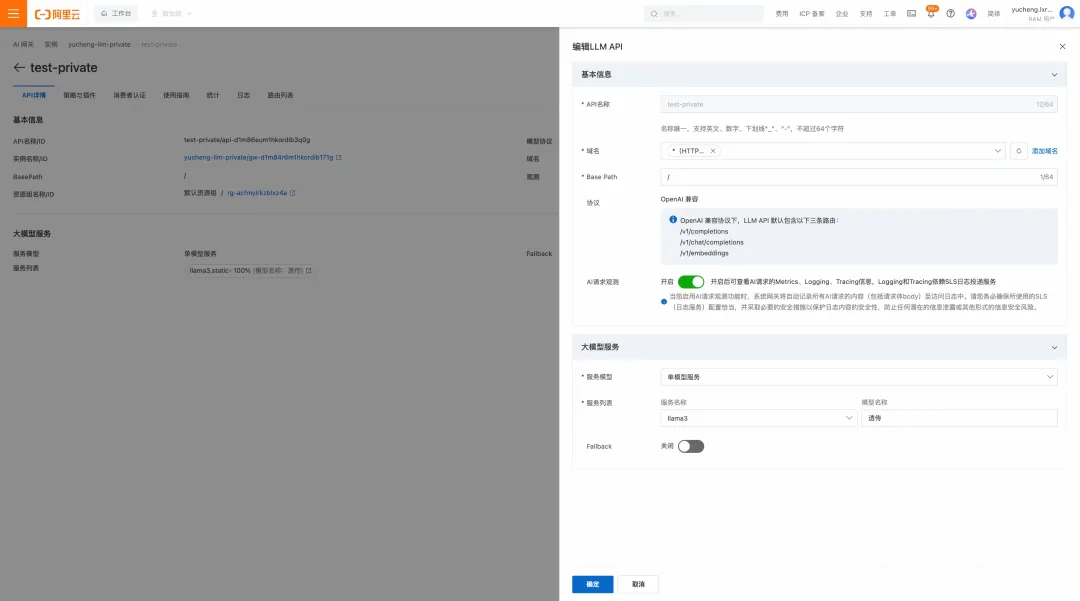
- 在網關配置 API:在網關中創建一個 LLM API,后端服務指向 llama3.
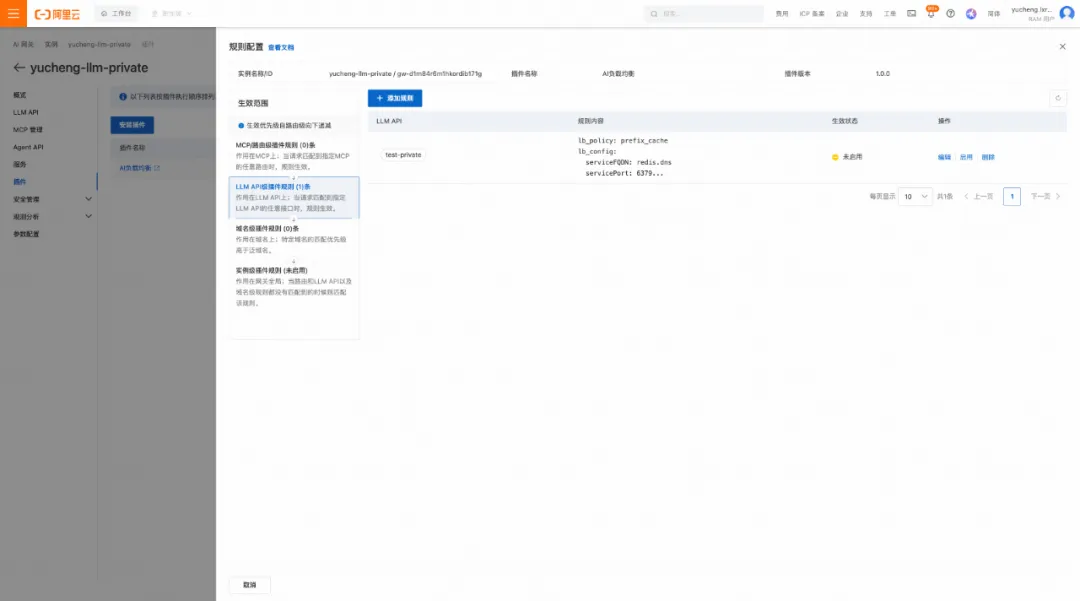
- 在網關配置插件:在插件市場找到 ai-load-balancer 插件進行安裝,然后在 LLM API 粒度下給剛才創建的 LLM API 配置負載均衡策略。
插件配置示例如下:
lb_policy: prefix_cache
lb_config:serviceFQDN: redis.dnsservicePort:?6379username: defaultpassword: xxxxxxxxxxxxredisKeyTTL:?60
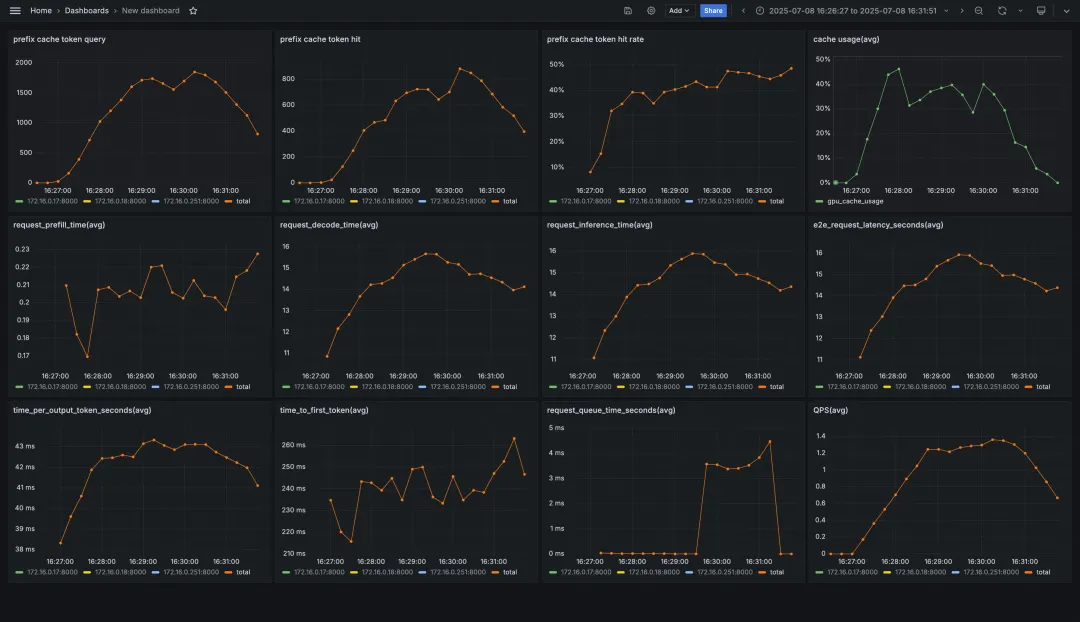
附錄:壓測結果與 vllm 監控大盤
無負載均衡
GenAI-Perf 統計結果如下:

vllm 監控如下:
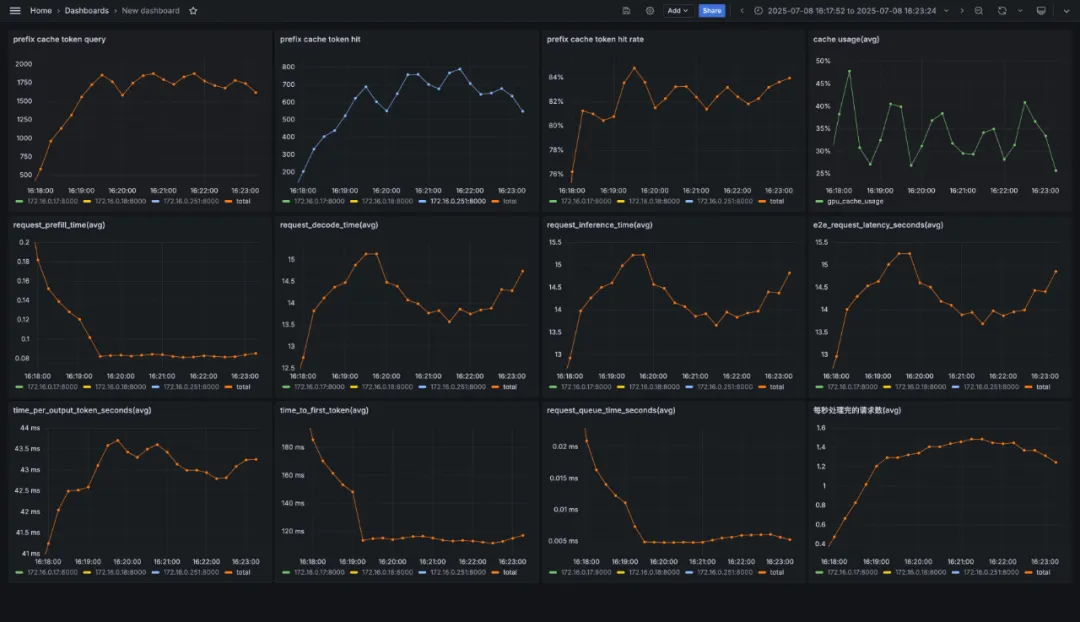
前綴匹配負載均衡
GenAI-Perf 統計結果如下:

vllm 監控如下:
相關鏈接:
【1】gateway-api-inference-extension
https://github.com/kubernetes-sigs/gateway-api-inference-extension/tree/main
【2】阿里云 Redis 控制臺
https://kvstore.console.aliyun.com/Redis/instance/cn-hangzhou
【3】Redis 快速入門概覽
https://help.aliyun.com/zh/redis/getting-started/overview
🔥🔥擁抱 AI 原生!
8月29日深圳,企業實踐工作坊火熱報名中!
阿里云誠摯邀請您參加【AI 原生,智構未來——AI 原生架構與企業實踐】工作坊,從開發范式到工程化實踐,全鏈路解析AI原生架構奧秘,與AI先行者共探增長新機遇。
???點擊此處,立即了解完整議程!






-- 模型構建與神經網絡)


調試——如何做到 適配軟件定義汽車(SDV)?(上))




![[身份驗證腳手架] 前端認證與個人資料界面](http://pic.xiahunao.cn/[身份驗證腳手架] 前端認證與個人資料界面)


)

