UNIKGQA: UNIFIED RETRIEVAL AND REASONING FOR SOLVING MULTI-HOP QUESTION ANSWERING OVER KNOWLEDGE GRAPH(ICLR 2023)
Introduction
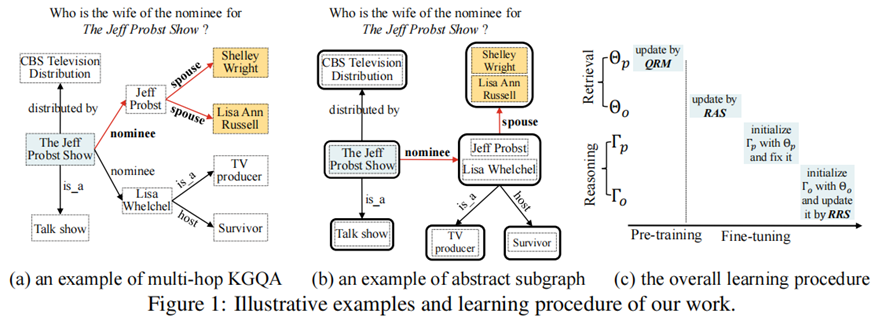
?知識圖上的多跳問題回答(KGQA)的目的是在大規模知識圖譜(KG)上找到自然語言問題中提到的主題實體,然后進行多跳推理得到答案實體。
現有方法局限性
?為了應對龐大的搜索空間,現有的工作通常采用兩階段的方法:首先檢索與問題相關的相對較小的子圖,然后對子圖進行推理,以準確地找到答案實體。雖然這兩個階段是高度相關的,但以前的工作采用了非常不同的技術解決方案來開發檢索和推理模型,而忽略了它們在任務本質上的相關性。
UniKGQA
?在本文中,我們提出了一種新的UniKGQA方法,該方法通過將檢索和推理模型統一在模型架構和參數學習中,使得兩個階段更加緊密相關。具體來說,UniKGQA采用了基于預訓練語言模型的語義匹配模塊和匹配信息傳播模塊,并設計了共享預訓練任務和檢索、推理導向的微調策略。實驗結果表明,UniKGQA在三個基準數據集上表現出了很好的效果。
Methodology
統一模型體系結構
Semantic Matching (SM)
?語義匹配模塊旨在生成問題與知識圖譜中三元組的語義匹配特征。
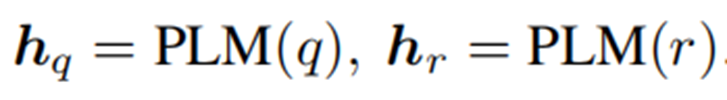
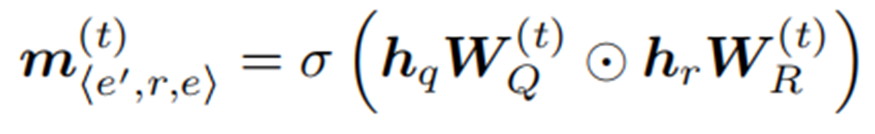
Matching Information Propagation (MIP)
?MIP模塊基于生成的語義匹配特征,首先對其進行聚合,更新實體表示,然后利用其獲得實體匹配得分。
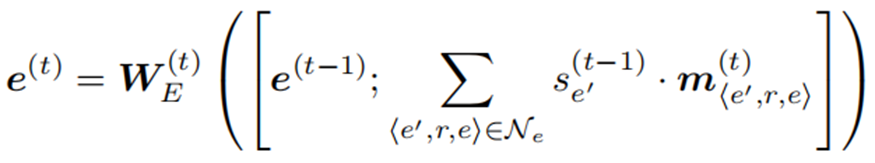
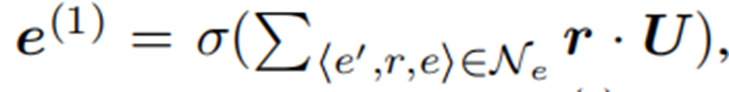
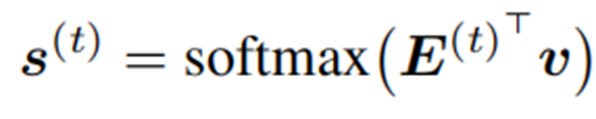
訓練
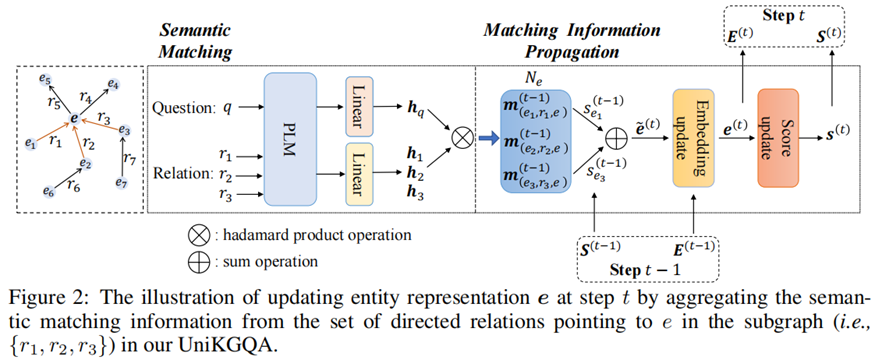
?多跳KGQA的兩個階段有檢索模型和推理模型。由于這兩個模型采用相同的架構,我們引入Θ和Γ來分別表示用于檢索和推理階段的模型參數。
?模型體系結構包含兩組參數,即底層的PLM和其他用于匹配和傳播的參數。因此,Θ和Γ可以分解為: Θ = {Θp,Θo}和Γ = {Γp,Γo},其中下標p和o分別表示PLM參數和我們的架構中的其他參數。為了學習這些參數,我們設計了基于統一體系結構的預訓練(即問題-關系匹配)和微調(即面向檢索和推理的學習)策略。
Pre-training with Question-Relation Matching(QRM)
?給定一個問題q,主題實體Tq和答案實體Aq,從整個KG中提取所有從Tq到Aq的最短路徑,這些最短路徑所包含的關系可以認為是與q相關的,將其集合表示為R+。在訓練前,對于每個問題q,我們隨機抽取一個相關的關系r+∈R+,利用對比學習損失進行預訓練:
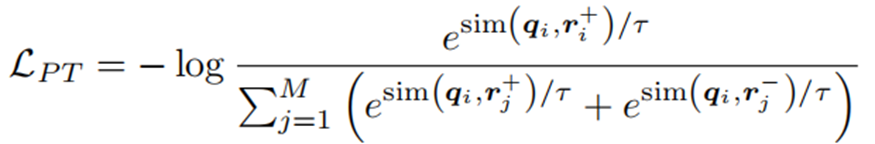
Fine-tuning for Retrieval on Abstract Subgraphs (RAS)
?SA為抽象子圖中的抽象結點的得分,如果抽象結點包括答案實體,將S*A=1賦給抽象節點。
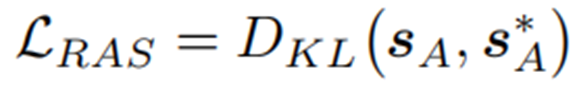
?在對RAS損失進行微調后,可以有效地學習檢索模型。進一步利用它來檢索給定問題q的子圖,根據匹配分數選擇排名前k的節點。只有與主題實體保持合理距離內的節點才會被選擇到子圖中。
Fine-tuning for Reasoning on Retrieved Subgraphs (RRS)
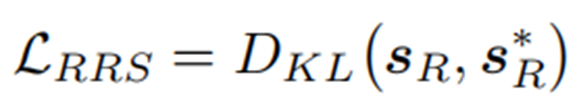
?在對RRS損失進行微調后,可以利用學習到的推理模型,根據匹配分數選擇排名前n位的實體作為答案列表。
Experiments
數據集

評價指標
子圖提取評估標準:answer coverage rate (%)
推理評估標準:Hits@1,F1
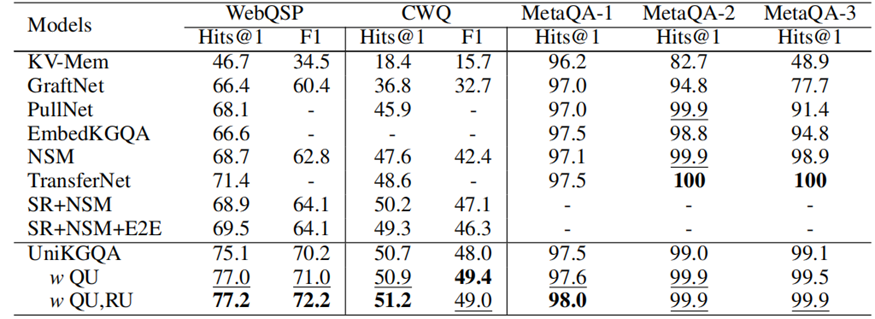
結果
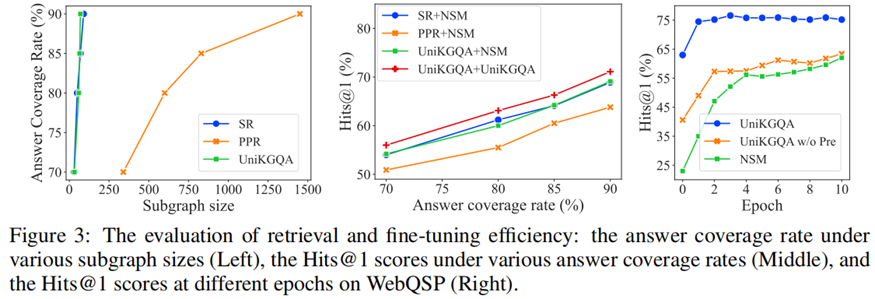
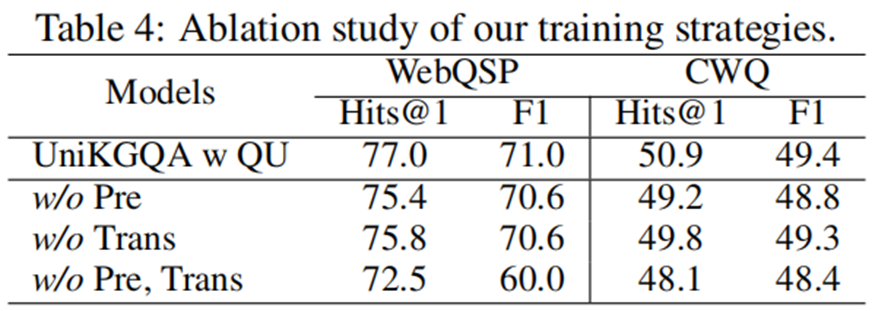
消融實驗
Conclusion
?提出了一種新的統一模型架構,可以同時處理多跳KGQA任務中的檢索和推理階段。使用抽象子圖來減少檢索階段中節點的數量,從而提高效率。設計了有效的學習方法,包括預訓練和微調策略,以利用兩個階段之間的共享信息,并提高了性能。在三個基準數據集上進行了廣泛的實驗,并取得了比現有最佳基線更好的結果。
方法創新點
?創新地提出了一個統一的模型架構,將KGQA任務的檢索和推理階段緊密聯系起來,以便更好地共享和傳遞相關信息。引入了抽象子圖的概念,通過合并具有相同前綴(即相同的頭部實體和關系)的尾部實體來減少檢索階段中節點的數量,從而提高了效率。設計了有效的學習方法,包括預訓練和微調策略,以利用兩個階段之間的共享信息,并提高了性能。
未來展望
?該研究為多跳KGQA提供了一個更加統一和簡化的方法,但仍需要進一步探索如何更好地處理不同規模的數據分布以及如何更有效地分享和轉移信息。可以考慮使用更多的預訓練技術來進一步提高模型的性能。未來的研究還可以探索如何將這種方法擴展到其他類型的自然語言問答任務中。














——Python賽道)
:子進程隔離實戰)
)


