一、Introduction
1.目前存在的問題:
(deep)Q-learning:在一些簡單問題上表現不佳,可理解性差
基礎的policy gradient算法:(如REINFORCE)魯棒性差,需要大量數據
TRPO:復雜,在包含噪音(如dropout)或者權重共享機制的問題中不兼容
在擴展性、數據利用率以及魯棒性上還有上升空間
二、背景知識:策略優化
1.策略梯度方法
策略梯度中常用的gradient estimator格式:
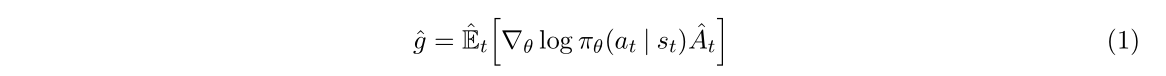
相對應的目標函數:
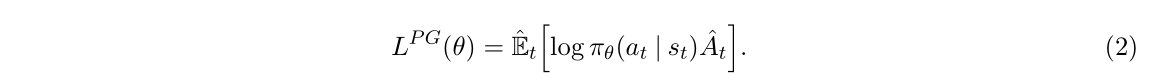
2.Trust Region方法(TRPO)
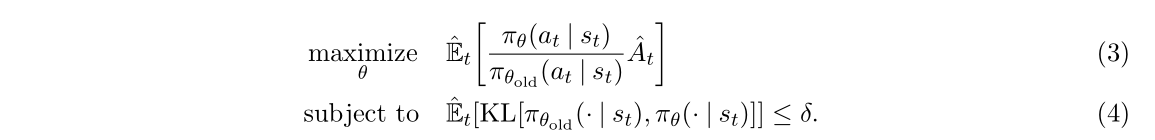
加入拉格朗日因子變成:
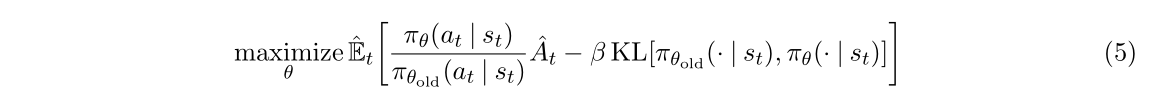
問題:很難選擇一個確定的β在所有問題 甚至某一類問題上都表現的很好。
三、引入Clipped形式
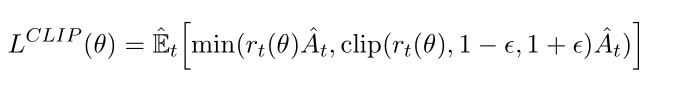
1.限制過度樂觀:
這個式子的形式很巧妙,使用clip來防止結果過于激進:如A>0時如果r超過1+E就進行截斷處理,A<0時如果r小于1-E就進行階段處理。
當新策略試圖對舊策略已經做得不錯(A_t > 0)的地方進行過于激進的改進(r_t >> 1),或者對舊策略做得不好(A_t < 0)的地方進行過于激進的避免(r_t << 1)時,PPO會踩剎車(裁剪),防止策略突然偏離太遠導致崩潰。
2.允許必要的悲觀修正
但是不會阻止悲觀的結果:如果A>0且r<1-E則不進行截斷處理,A<0時r>1+E時不進行截斷處理。這是為了激勵模型積極學習,下面是解釋:
- 情景一?(A_t>0, r_t<<1):
r_t*A_t?是一個很小的正數(甚至可能變負),而?clip(r_t, 1-ε, 1+ε)*A_t ≈ (1-ε)*A_t?是一個較大的正數。所以?min?選擇了很小的?r_t*A_t。 - 情景二 (A_t<0, r_t>>1):
r_t*A_t?是一個很大的負數(因為負的A_t被放大了),而?clip(r_t, 1-ε, 1+ε)*A_t ≈ (1+ε)*A_t?是一個較小的負數(負的A_t被縮小了)。所以?min?選擇了很大的負數?r_t*A_t。 目標函數的含義:?PPO的目標是最大化這個?
min(...)?函數的值。梯度更新的方向:?為了最大化目標函數:
在情景一中,目標函數取了一個很小的值(甚至負值)。為了最大化它,優化器會強烈地推動策略參數 θ 朝著增加?
r_t(θ)(即增加選擇這個好動作的概率)的方向更新。在情景二中,目標函數取了一個很大的負值。為了最大化它(即讓這個負值變得不那么負),優化器會強烈地推動策略參數 θ 朝著減少?
r_t(θ)(即減少選擇這個壞動作的概率)的方向更新。
“積極更新”的體現:?由于目標函數值在錯誤方向上非常差(很小或很負),優化器計算出的梯度(更新方向)的幅度會非常大。這導致參數 θ 會在這個方向上邁出相對較大的一步,迅速糾正這個錯誤。這就是“允許更積極地更新”的數學體現。
想象你在訓練一個機器人走路(策略)。PPO的clip機制就像給機器人腳上裝了帶彈簧的限制器([1-ε, 1+ε])。
當機器人想邁出一個非常大的步子向前沖(樂觀更新,可能跌倒)時,彈簧限制器會拉住它(裁剪),只允許它邁出安全的一步。
但當機器人不小心踩空,即將向后摔倒(嚴重錯誤,性能崩潰)時,彈簧限制器不會阻止它把腳快速收回來重新站穩(不裁剪,允許積極糾錯)。如果這個時候限制器還強行拉住腳不讓它收回來,機器人肯定會重重摔倒。PPO選擇松開限制器,讓機器人能迅速做出挽救動作
說白了就是允許嚴重的錯誤,而模型為了糾正這個錯誤會強烈推動策略參數的更新。
四、Adaptive KL Penalty Coefficient
論文中指出了一個替代或者補充方法,就是增加KL懲罰項,但是這個的表現明顯比clip的糟糕。

五、算法完整過程
最終算法是要梯度上升下面這個式子來實現參數更新:

其中CLIP就是三中的式子,不再介紹。VF表示和target的損失函數,S表示熵獎勵(為了提高模型中的探索性)。

這里解釋一下VF:因為我在學習強化學習的時候感受到的強化學習和監督/無監督學習的主要區別就是解決的問題不同,監督/無監督學習主要是為了優化,是可以有固定的標簽的,只是訓練的時候給不給的問題(或者好不好獲得),但強化學習是關于和環境交互學習策略的,是沒有辦法獲得具體標簽的,所以強化學習的目標是最大化state value而監督/無監督學習是最小化和target之間的loss函數。但是這里的VF感覺像是監督學習了。
答:雖然強化學習整理是“無監督” 的,但是在訓練值函數的時候可以構造一個"偽標簽"。也就是說這里的target不是環境直接給的target,而是我們基于經驗計算的目標。
VF項的展開公式是![]() ,其中Vθ?(st?)是為了估計每個狀態的價值而構建的值函數網絡,訓練時,我們用采樣得到的經驗去構造目標值 Vtarg?,再用 均方誤差(MSE) 來回歸這個目標值。
,其中Vθ?(st?)是為了估計每個狀態的價值而構建的值函數網絡,訓練時,我們用采樣得到的經驗去構造目標值 Vtarg?,再用 均方誤差(MSE) 來回歸這個目標值。





)







——社交網絡分析)





