目錄
簡介
1. 安裝 Pandas
2.基本數據結構
1.Series
(1.)創建Series
?(2.)Series的屬性
?(3.)Series 的索引和切片
2.DataFrame
(1.)創建 DataFrame
?(2.)DataFrame 的屬性
? (3.)DataFrame 的排序和值替換
?3.pandas的選取與修改
4.pandas的索引
1.?標簽索引(.loc)
2.?位置索引(.iloc)
5.?Pandas 的條件篩選?
6. Pandas 中處理重復值
7.?Pandas 中處理缺失值
簡介
????????在當今這個數據爆炸的時代,數據處理已經成為了各個領域中不可或缺的一環。無論是數據分析、機器學習還是人工智能,都需要對大量的數據進行清洗、轉換和分析。而 Pandas 作為 Python 中最流行的數據處理庫之一,憑借其強大的功能和簡潔的 API,成為了數據科學家們的首選工具。無論你是數據科學的新手還是有一定經驗的從業者,都能從本文中獲得有價值的信息。
????????這篇文章并沒有把pandas所有內容說完,但是為后面機器學習、深度學習已經足夠使用了,學習太多容易混亂
1. 安裝 Pandas
????????Pandas 是一個開源的 Python 庫,專為數據處理和分析而設計。它提供了高性能、易用的數據結構和數據分析工具,使數據處理變得更加簡單和高效。Pandas 的主要數據結構是 Series(一維數組)和 DataFrame(二維表格),它們提供了強大的索引功能和數據操作能力。
????????安裝 Pandas 非常簡單,只需要使用 pip 命令即可:
pip install pandas==1.3.5 -i https://pypi.tuna.tsinghua.edu.cn/simple
2.基本數據結構
????????Pandas 有兩種主要的數據結構:Series 和 DataFrame。
1.Series
(1.)創建Series
????????Series 是一個一維的帶標簽數組,可以容納任何數據類型(整數、字符串、浮點數、Python 對象等)。它由兩部分組成:索引(index)和值(values)。
import pandas as pd# 創建一個Series
s_1 = pd.Series([1, 2, 3, 4, 5])
print(s_1)# 創建自定義索引的 Series
s_2 = pd.Series([1, 2, 3, 4, 5],index=['a', 'b', 'c', 'd', 'e'])
print(s_2)#創建字符串類型的 Series
s_3 = pd.Series(['Lily', "Rose", "Jack"])
print(s_3)輸出結果:
#s_1
0 1
1 2
2 3
3 4
4 5
dtype: int64
#s_2
a 1
b 2
c 3
d 4
e 5
dtype: int64
#s_3
0 Lily
1 Rose
2 Jack
dtype: object?(2.)Series的屬性
.index:獲取索引對象.values:獲取底層 NumPy 數組
print(s_1.index)
print(s_2.index)
print(s_1.values)
print(s_3.values)
# 運行結果:RangeIndex(start=0, stop=5, step=1)
# Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
# [1 2 3 4 5]
# ['Lily' 'Rose' 'Jack']?(3.)Series 的索引和切片
創建 Series 對象
import pandas as pds_1 = pd.Series([1, 2, 3, 4, 5],index=['a', 'b', 'c', 'd', 'e'])s_2 = pd.Series(['lily', 'rose', 'jack'])
# a 1
# b 2
# c 3
# d 4
# e 5
# dtype: int64# 0 lily
# 1 rose
# 2 jack
# dtype: object基于標簽的索引(自定義索引)
# 訪問單個元素(標簽索引)
print(s_1['d']) # 輸出:4# 訪問多個元素(標簽切片)
# print(s_1['a':'d']) # 輸出:a到d的元素(含d)# 訪問不連續的元素
print(s_1[['a', 'd']]) # 輸出:a和d的元素?基于位置的索引(默認索引)
print(s_2[2]) # 輸出:jack(位置2的元素)
print(s_2[0:2]) # 輸出:位置0和1的元素(不含2)
print(s_2[[0, 2]]) # 輸出:位置0和2的元素?混合索引的注意事項
print(s_1[4]) # 輸出:5(位置4的元素,即索引'e'對應的值)- 當自定義索引是標簽時,
s_1[4]會被解釋為位置索引 - 但這種用法容易混淆,建議明確使用
.loc(標簽)或.iloc(位置)
2.DataFrame
????????DataFrame 是一個二維的帶標簽數據結構,類似于 Excel 表格或 SQL 表。它可以被看作是由多個 Series 組成的字典,每個 Series 共享相同的索引。
(1.)創建 DataFrame
創建帶自定義索引的 DataFrame
df_1 = pd.DataFrame({'age': [10, 11, 12],'name': ['tim', 'tom', 'rose'],'income': [100, 200, 300]},index=['person1', 'person2', 'person3'])
print(df_1)- 使用字典創建 DataFrame,鍵為列名,值為列數據
- 通過
index參數指定行索引
age name income
person1 10 tim 100
person2 11 tom 200
person3 12 rose 300?創建帶默認索引的 DataFrame
df_1 = pd.DataFrame({'age': [10, 11, 12],'name': ['tim', 'tom', 'rose'],'income': [100, 200, 300]})
print(df_1)- 不指定索引時,默認生成整數索引(0 到 2)
age name income
0 10 tim 100
1 11 tom 200
2 12 rose 300?(2.)DataFrame 的屬性
# 行索引
df_1.index # 輸出:Index(['person1', 'person2', 'person3'], dtype='object')# 列名
df_1.columns # 輸出:Index(['age', 'name', 'income'], dtype='object')# 值(NumPy數組)
df_1.values # 輸出:
# array([[10, 'tim', 100],
# [11, 'tom', 200],
# [12, 'rose', 300]], dtype=object)訪問DataFrame 的列(Series)
print(df_1.name)- 通過屬性訪問
name列,返回 Series 對象 - 輸出結果:
0 tim
1 tom
2 rose
Name: name, dtype: object? (3.)DataFrame 的排序和值替換
創建 DataFrame
dic = {'name': ['kiti', 'beta', 'peter', 'tom'],'age': [20, 18, 35, 21],'gender': ['f', 'f', 'm', 'm']}
df = pd.DataFrame(dic)
print(df)- 使用字典創建 DataFrame,默認索引為 0 到 3
name age gender
0 kiti 20 f
1 beta 18 f
2 peter 35 m
3 tom 21 m按照年齡列排序
# 升序排序(默認)
df = df.sort_values(by=['age'])# 降序排序
df = df.sort_values(by=['age'], ascending=False)- 最終結果(降序):
name age gender
2 peter 35 m
3 tom 21 m
0 kiti 20 f
1 beta 18 f值替換
df['gender'] = df['gender'].replace(['m', 'f'], ['male', 'female'])replace()方法替換 Series 中的值['m', 'f']:要替換的值['male', 'female']:替換后的值
name age gender
2 peter 35 male
3 tom 21 male
0 kiti 20 female
1 beta 18 female?3.pandas的選取與修改
創建 DataFrame
df = pd.DataFrame({'age': [10, 11, 12],'name': ['tim', 'tom', 'rose'],'income': [100, 200, 300]},index=['person1', 'person2', 'person3']) age name income
person1 10 tim 100
person2 11 tom 200
person3 12 rose 300?添加列
df['pay'] = [20, 30, 40]- 在末尾添加
pay列
age name income pay
person1 10 tim 100 20
person2 11 tom 200 30
person3 12 rose 300 40?添加行
df.loc['person4', ['age', 'name', 'income']] = [20, 'kitty', 200]- 使用
.loc在person4位置添加新行
age name income pay
person1 10 tim 100 20
person2 11 tom 200 30
person3 12 rose 300 40
person4 20 kitty 200 NaN?數據訪問
# 訪問列
print(df.name) # 通過屬性訪問# 訪問多列
print(df[['age', 'name']])# 訪問行(位置切片)
print(df[0:2]) # 位置0到1(不含2)# 訪問行(標簽索引)
print(df.loc[['person1', 'person3']])# 訪問單個值
print(df.loc['person1', 'name']) # 輸出:tim?刪除操作
# 直接刪除列(原地操作)
del df['age']# 刪除列(返回新DataFrame)
data = df.drop('name', axis=1, inplace=False)# 刪除行(原地操作)
df.drop('person3', axis=0, inplace=True)?時間序列 DataFrame
datas = pd.date_range('20180101', periods=5)
df1 = pd.DataFrame(np.arange(30).reshape(5, 6), index=datas, columns=['A', 'B', 'C', 'D', 'E', 'F']) A B C D E F
2018-01-01 0 1 2 3 4 5
2018-01-02 6 7 8 9 10 11
2018-01-03 12 13 14 15 16 17
2018-01-04 18 19 20 21 22 23
2018-01-05 24 25 26 27 28 294.pandas的索引
創建 DataFrame
df = pd.DataFrame(np.arange(30).reshape(5, 6),index=['20180101', '20180102', '20180103', '20180104', '20180105'],columns=['A', 'B', 'C', 'D', 'E', 'F']
)- 使用 NumPy 數組創建 DataFrame
- 行索引為日期字符串,列索引為字母
A B C D E F
20180101 0 1 2 3 4 5
20180102 6 7 8 9 10 11
20180103 12 13 14 15 16 17
20180104 18 19 20 21 22 23
20180105 24 25 26 27 28 291.?標簽索引(.loc)
# 獲取某列(全部行的B列)
print(df.loc[:, 'B'])
# 輸出:
# 20180101 1
# 20180102 7
# 20180103 13
# 20180104 19
# 20180105 25
# Name: B, dtype: int64# 獲取單個值(20180103行的B列)
print(df.loc['20180103', 'B']) # 輸出:13# 獲取某行的多列(20180103行的B列和D列)
print(df.loc['20180103', ['B', 'D']])
# 輸出:
# B 13
# D 15
# Name: 20180103, dtype: int64# 獲取整行(20180101行的所有列)
print(df.loc['20180101', :])
# 輸出:
# A 0
# B 1
# C 2
# D 3
# E 4
# F 5
# Name: 20180101, dtype: int642.?位置索引(.iloc)
# 獲取單個值(第2行第3列,索引從0開始)
print(df.iloc[1, 2]) # 輸出:8# 獲取某列(所有行的第3列)
print(df.iloc[:, 2])
# 輸出:
# 20180101 2
# 20180102 8
# 20180103 14
# 20180104 20
# 20180105 26
# Name: C, dtype: int64# 獲取整行(第2行的所有列)
print(df.iloc[1, :])
# 輸出:
# A 6
# B 7
# C 8
# D 9
# E 10
# F 11
# Name: 20180102, dtype: int645.?Pandas 的條件篩選?
讀取數據
df = pd.read_csv("data2.csv", encoding='gbk', engine='python')
?數值條件篩選
# 篩選好評數>17000的記錄
df_1 = df[df['好評數'] > 17000]# 篩選好評數在15000-17000之間的記錄
df_2 = df[df['好評數'].between(15000, 17000)]df['好評數'] > 17000:生成布爾 Seriesbetween(a, b):等效于(x >= a) & (x <= b)
?字符串條件篩選
# 篩選品牌包含"蘋果"且非空的記錄
df_3 = df[df['品牌'].str.contains('蘋果', na=False)]# 篩選品牌包含"蘋果"或為空值的記錄
df_4 = df[df['品牌'].str.contains('蘋果', na=True)]str.contains('蘋果'):判斷字符串是否包含子串na=False:將 NaN 視為 False(排除空值)na=True:將 NaN 視為 True(包含空值)
?多條件組合篩選
# 篩選價格<7000且好評數>16000的記錄
df_5 = df[(df['價格'] < 7000) & (df['好評數'] > 16000)]# 篩選價格<6000或好評數>18000的記錄
df_6 = df[(df['價格'] < 6000) | (df['好評數'] > 18000)]- 使用
&(邏輯與)和|(邏輯或)組合條件 - 每個條件必須用括號
()包裹 - 最終結果
df_6包含所有滿足任一條件的記錄
6. Pandas 中處理重復值
讀取數據
df = pd.read_csv(r"data1.csv", encoding='gbk', engine='python')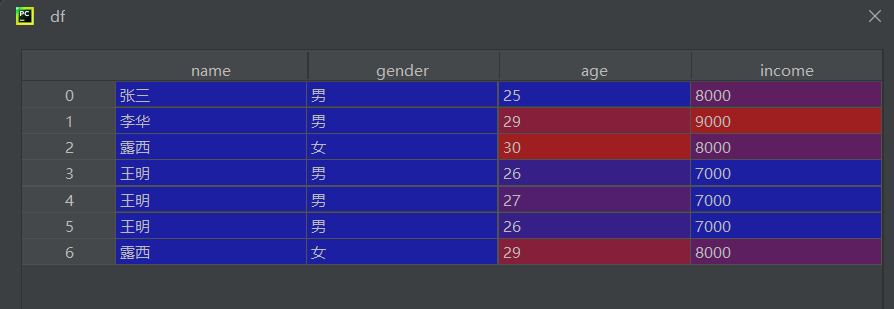
??????判斷重復值
# 判斷全量重復行(所有列值相同)
result1 = df.duplicated()# 判斷基于單列的重復行
result2 = df.duplicated('gender')# 判斷基于多列組合的重復行
result3 = df.duplicated(['gender', 'name'])duplicated()返回布爾 Series,標記每行是否為重復行keep='first'(默認):首次出現的行標記為 False,后續重復行標記為 True- 多列判斷時,只有所有指定列的值都相同才算重復
?提取重復行
a = df[result1] # 全量重復行
b = df[result2] # gender列重復的行
c = df[result3] # gender和name都重復的行# 手動布爾索引(示例)
d = df[[True, False, False, True, True, False, False]]- 通過布爾索引提取對應行
- 手動指定布爾列表時,長度必須與 DataFrame 行數一致
?刪除重復行
# 刪除全量重復行(保留首次出現的行)
new_df1 = df.drop_duplicates()# 刪除基于多列組合的重復行
new_df2 = df.drop_duplicates(['name', 'gender'])7.?Pandas 中處理缺失值
讀取數據
df = pd.read_csv(r"data.csv", encoding='gbk', engine='python')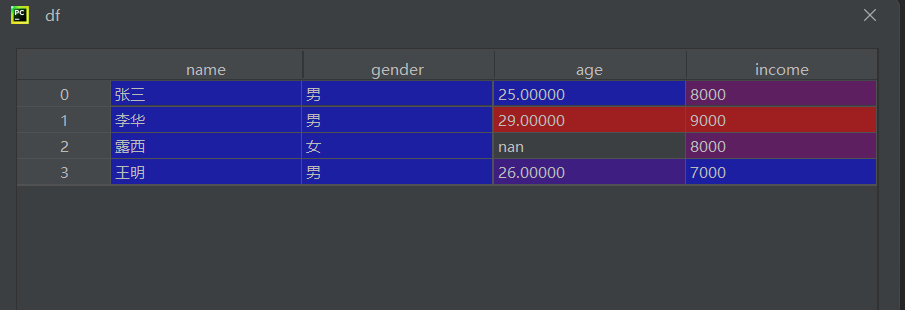 ?
?
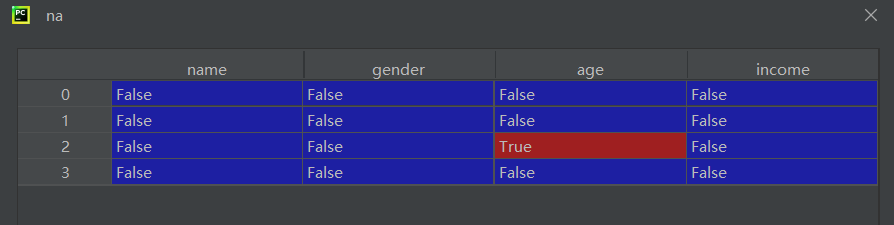
?檢測缺失值
na = df.isnull()isnull()返回布爾 DataFrame- 每個元素標記是否為缺失值(
NaN或None)
 ?
?
填充缺失值
df1 = df.fillna('1')fillna('1'):用字符串'1'填充所有缺失值- 其他常用填充方式:
df.fillna(0) # 用0填充
df.fillna(method='ffill') # 用前一個有效值填充
df.fillna({'col1': 0, 'col2': 100}) # 按列指定填充值?刪除缺失值
df2 = df.dropna()dropna()默認刪除包含任何缺失值的行- 參數說明
df.dropna(axis=0) # 刪除行(默認)
df.dropna(axis=1) # 刪除列
df.dropna(how='all') # 只刪除全為缺失值的行
df.dropna(thresh=2) # 保留至少有2個非缺失值的行






處理教程)

)




)




