目錄
1.預備知識
2.map的補充知識
2.1map的插入方式
2.2訪問鍵和值
2.3map::operator[]的補充
2.4另外一些map的成員函數的補充
3.map的應用實踐-力扣刷題-前k個高頻單詞
3.1解法1
3.2解法2
3.3解法3
4.map的應用實踐-力扣刷題-隨機鏈表的復制
4.1C語言解法
4.2C++解法
5.總結

1.預備知識
該講需要用到map的知識,可以見我之前的博客:
C++進階-map-CSDN博客文章瀏覽閱讀484次,點贊13次,收藏7次。我們要更深入了解map就要了解一下pair,pair翻譯成中文就是:一對,的意思,我們在C++官網中可以搜索pair來了解一下:翻譯一下就能知道其大概的意思:簡單來說就是將T1和T2存儲在一起,也就是說map相當于set的區別就是能多存儲一個值,相對于原來的只有T適應的情況就更多了,但是也相對更難學了一些。這講的map是一些比較重要的map的成員函數,還有一部分補充的知識點將會在下講繼續進行講解,好了,這講就到這里,喜歡的可以一鍵三連哦,下講再見!https://blog.csdn.net/2401_86446710/article/details/149344636?spm=1011.2415.3001.10575&sharefrom=mp_manage_link
2.map的補充知識
2.1map的插入方式
上講我講解了一個插入方式就是用emplace_hint的方式進行插入,我們實踐中不可能完全用那種方式進行插入,所以這里就有以下的方式:
#include<iostream>
#include<map>
#include<string>
using namespace std;
//map的插入方式
int main()
{map<string, int> m;//C++98//插入方式1//有名對象的插入//比較常用pair<string,int> p("China", 1);m.insert(p);//插入方式2//構造匿名對象插入m.insert(pair<string, int>("Hunan", 2));//插入方式3//自動推導類型進行插入m.insert(make_pair("Zhuzhou", 3));//C++11//插入方式4//最常用m.insert({ "Tianyuan",4 });//插入方式5//原地構造m.emplace("Hut", 5);//插入方式6//建議使用auto c = m.find("China");m.emplace_hint(c, "Base", 6);//插入方式7//建議使用//使用{}進行插入m.insert({ {"Dictroy",7},{"Phone",8} });return 0;
}插入方式還有:
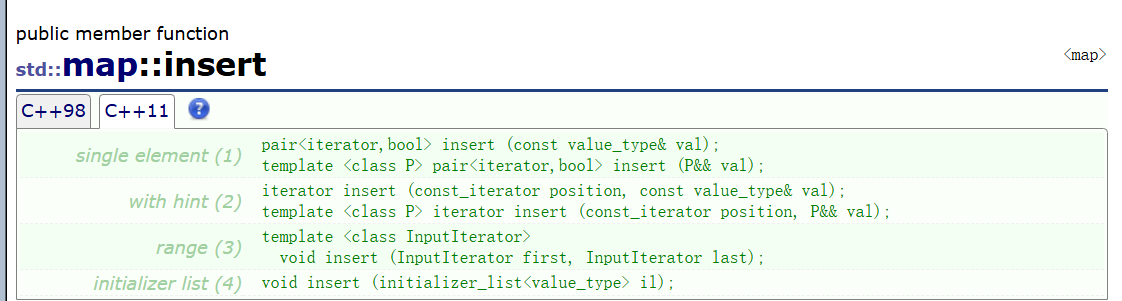
用迭代器區間進行初始化,這種方式用得實在是不多,需要用一段map的迭代器區間來進行初始化,這種方式不太常見,建議用我推薦的三種方式。
注意:initializer_list不是和之前一樣直接進行插入了,還是經過了隱式類型轉化的,在一般的題目中知道initializer_list的插入和insert({})的插入和emplace(……,……)的插入即可。
2.2訪問鍵和值
一般情況下我們是用這種方式來訪問鍵和值的:
#include<iostream>
#include<map>
#include<string>
using namespace std;
//map訪問鍵和值
int main()
{map<string, int> m({ {"Apple",1} });//訪問鍵auto c = m.find("Apple");cout << c->first << ' ';//訪問值cout << c->second << endl;return 0;
}
但是有些人可能就想問了,為什么我們不能用m->first進行訪問?
實際上,這個c指的是一個結點,也就是一個鍵值對,這個c是pair類型的我之前講過pair,這個pair里面有first和second用于訪問我們的鍵和值,所以一般情況下我們訪問一個鍵和一個值在map里面最簡便的方式只有這個,而且這個c->first實際上是c.operator->()->first。
那么我們還有沒有其他方式來訪問鍵和值?
以下這個方式有點難理解,不過也可以用來完成目的:
#include<iostream>
#include<map>
#include<string>
using namespace std;
//map訪問鍵和值
int main()
{map<string, int> m({ {"China",1},{"Hunan",2} });auto it = m.begin();while (it != m.end()){cout << (*it).first << ':' << (*it).second << endl;++it;}cout << endl;return 0;
}這種(*it).first和(*it).second的方式會讓人有點難理解,主要是解引用的問題,我們只要知道如何訪問的即可。
2.3map::operator[]的補充
上講我們講解過:在正常情況下,我們如果傳遞的參數就是key,在這個key存在在map時會返回這個key對應的value(即返回:值),如果不存在就用默認構造,但是這個時候又可以修改,這樣很繞啊。
我在這里可以舉例一下,不然真的很難懂這個函數的行為:
#include<iostream>
#include<map>
#include<string>
using namespace std;
//map::operator[]的行為
int main()
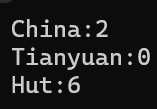
{map<string, int> m({ {"China",2},{"Hunan",3},{"Zhuzhou",4} });//返回:值auto a = m["China"];//插入+默認構造這個鍵的值為0auto b = m["Tianyuan"];//插入+把這個鍵的值置為5m["Hut"] = 6;auto c = m["Hut"];cout << "China:" << a << endl;cout << "Tianyuan:" << b << endl;cout << "Hut:" << c << endl;return 0;
}那么這樣的運行結果為:
還有一些公司在面試的時候要求講解出這個map::operator[]的實現,我在這里簡單寫一下:
#include<iostream>
#include<map>
#include<string>
using namespace std;
//map::operator[]的模擬實現
namespace td
{template<class Key,class T,class Compare=less<T>>class map{T& operator[](const Key& key){pair<map<string, int>::iterator, bool> ret = insert({ key,V() });return ret.first->second;}};
}這個bool是判斷鍵是否已經在map對象里面的,然后最后的ret.first->second,其中ret.first就是map<string,int>,然后ret.first->second就是返回對應的鍵的值,要理解指向還需要更深層次的對底層結構的理解。
2.4另外一些map的成員函數的補充

這些就是需要注意的成員函數,首先find,這個是傳入一個key(即鍵),找到對應的鍵所對應的迭代器,否則返回map::end,即返回為nullptr。這個函數日常生活用得也比較多,只是需要注意:如果沒找到的行為是什么。
第二個是count,它接收一個鍵,然后找這個鍵在map對象的數量,在map里面當然是只能取0或1,但是在multimap里面就可以取非負整數,這個也要注意;
后面三個:lower_bound,這個是返回一個迭代器,該迭代器指向鍵不小于?k?的第一個元素;而upper_bound,這個也是返回一個迭代器,該迭代器指向鍵大于?k?的第一個元素;equal_range則是返回一個范圍的邊界,該范圍包括容器中具有等效鍵?k?的所有元素。

這三個函數用得也不是很多,所以這里就不做演示了。
3.map的應用實踐-力扣刷題-前k個高頻單詞
題目鏈接:
692. 前K個高頻單詞 - 力扣(LeetCode)
題目描述:

3.1解法1
這個題目的綜合難度比較高,但是我們可以用map和multimap的性質完成該題:
首先,map可以先實例化為<string,int>類型,之后就直接進行插入,但是插入之前要先判斷是否插入成功,如果沒插入成功還要判斷,但是我們很容易發現如果這種形式,那么解決就很麻煩,直接用operator[]就可以完成上述操作了啊!因為它會判斷是否有,有的話就返回值,沒有的話就插入,插入后還會默認構造,這個時候我們遇到一個就++即可,然后再構造一個multimap對象,這個對象實例化為:<int,string,greater<int>>類型,因為我們需要排升序,所以需要這樣,最后再一個while循環輸出前k個高頻詞即可。
所以最終代碼如下:
//前k個高頻詞解法1
class Solution
{
public:vector<string> topKFrequent(vector<string>& words, int k){map<string, int> countMap;for (auto& str : words){countMap[str]++;}multimap<int, string, greater<int>> sortMap;for (auto& kv : countMap){sortMap.insert({ kv.second,kv.first });}vector<string> v;auto it = sortMap.begin();while (k--){v.push_back(it->second);++it;}return v;}
};這個解法循環次數太多了,主要是我們無法同時進行兩個map的同時完成,要遍歷兩次所有數據,很麻煩。
3.2解法2
有些人可能會覺得:如果用一個vector<string>進行排序不就可以了。
這個想法確實沒問題,但是主要是我們要知道:算法庫里面的快速排序的原理是進行交換的,所以如果這樣的話,那么就會導致相對次序發生改變,所以我們需要用一個比較穩定的排序算法進行排序,在算法課里面有一個stable_sort:即穩定排序,這個排序剛好可以,但是又出現了新的問題:

如果我們直接用vector<string>的話,沒有vector<string>的比較函數,如果自己寫比較函數就很麻煩,所以我們不能直接在vecor<string>上進行操作,因為無法進行排序,所以我們最好還是用另外一個結構:vector<pair<string,int>>進行排序操作,但是這樣的那個仿函數怎么寫?
我們都知道:這個只要比較每個pair的值就可以了,只是看起來很麻煩而已,所以我們可以這樣寫:
class kvCompare
{
public:bool operator()(const pair<string, int>& kv1, const pair<string, int>& kv2){return kv1.second > kv2.second;}
};最后拷貝這個v[i].first到最后的返回的那個vector<string>對象即可,所以最終代碼如下:
//前k個高頻詞解法2
class kvCompare
{
public:bool operator()(const pair<string, int>& kv1, const pair<string, int>& kv2){return kv1.second > kv2.second;}
};
class Solution
{
public:vector<string> topKFrequent(vector<string>& words, int k){map<string, int> m;for (auto& a : words){m[a]++;}vector<pair<string, int>> v(m.begin(), m.end());stable_sort(v.begin(), v.end(), kvCompare());vector<string> r;for (int i = 0; i < k; i++){r.push_back(v[i].first);}return r;}
};這個代碼的運行時間很快,但是有沒有另外一種不用stable_sort的寫法呢?
當然有!
3.3解法3
我們可以在寫仿函數的時候多判斷一個條件,因為string在定義的時候其實是有重載<的運算符的,也就是我們可以在原來的繼承上加以限制,當kv1.first<kv2.first并且kv1.second==kv1.second的時候再加上||(kv1.second>kv2.second)即可,這樣就能穩定的輸出結果,而且我們只要用sort函數即可:
//前k個高頻詞解法3
class kvCompare
{
public:bool operator()(const pair<string, int>& kv1, const pair<string, int>& kv2){return (kv1.second > kv2.second) || (kv1.second == kv2.second && kv1.first < kv2.first);}
};
class Solution
{
public:vector<string> topKFrequent(vector<string>& words, int k){map<string, int> m;for (auto& a : words){m[a]++;}vector<pair<string, int>> v(m.begin(), m.end());sort(v.begin(), v.end(), kvCompare());vector<string> r;for (int i = 0; i < k; i++){r.push_back(v[i].first);}return r;}
};解法三的運行時間和解法1差不多,但是消耗內存小了很多,喜歡哪個就用哪個吧!
4.map的應用實踐-力扣刷題-隨機鏈表的復制
題目鏈接:
138. 隨機鏈表的復制 - 力扣(LeetCode)
題目描述:
4.1C語言解法
在C語言階段,我講解過這個題目,當時代碼很長,代碼如下:
typedef struct Node Node;
//申請新結點空間
Node* buyNode(int x)
{Node* node = (Node*)malloc(sizeof(Node));node->val = x;node->next = node->random = NULL;return node;
}
//在原鏈表上進行新結點的連接
void AddNode(Node* head)
{Node* pcur = head;while (pcur){//先把原鏈表下一個結點存儲到一個臨時變量里Node* next = pcur->next;Node* newnode = buyNode(pcur->val);//改變鏈表的結點指向newnode->next = next;pcur->next = newnode;pcur = next;}
}
//置random指針
void setRandom(Node* head)
{Node* pcur = head;while (pcur){Node* copy = pcur->next;if (pcur->random)//如果random指針指向為空,我們不需要賦值{copy->random = pcur->random->next;//這個的意思是原結點的random指針指向的結點的地址}//我們需要把pcur一直在原鏈表上pcur = copy->next;}
}
//斷開連接
struct Node* copyRandomList(struct Node* head)
{if (head == NULL){return head;}Node* pcur = head;AddNode(head);setRandom(head);Node* newHead, * newTail;newHead = newTail = pcur->next;while (newTail->next){pcur = newTail->next;newTail->next = pcur->next;newTail = newTail->next;}return newHead;
}
4.2C++解法
這個題目我們也可以用map進行解答,先實例化出一個map<Node*,Node*> c對象,之后我們可以先把原鏈表拷貝一份,就是把每個結點的所有指針和val都拷貝到新鏈表去,要完成這個步驟,我們需要用一個指針為cur,在原鏈表遍歷;在新鏈表上有兩個指針,一個指針是指向尾結點的copytail指針,另外一個指針是新指向的鏈表的頭結點copyhead,然后只要存儲一下每個copytail的地址到c里面,這就完成了第一個步驟:
class Solution
{
public:Node* copyRandomList(Node* head) {map<Node*, Node*> c;Node* copyhead = nullptr;Node* copytail = nullptr;Node* cur = head;while (cur){if (copytail == nullptr){copyhead = copytail = new Node(cur->val);}else{copytail->next = new Node(cur->val);copytail = copytail->next;}c[cur] = copytail;cur = cur->next;}}
};后面我們還要處理random指針,我們需要先把cur重新置為head,這個時候我們再讓Node* copy = copyhead;這個時候我們直接再次遍歷,我們需要這樣寫:copy->random=c[cur->random]這樣就解決了,如果cur->random是nullptr,那么這個時候我們就不能copy->random=c[cur->random];了,因為這個傳入nullptr會報錯,所以這個時候就要直接用copy->random=nullptr即可,最后再讓cur=cur->next;copy=copy->next;即可完成。
我們要注意的一點是一定要理解這個:copy->random=c[cur->random];
我們用這題的例子來說明一下:
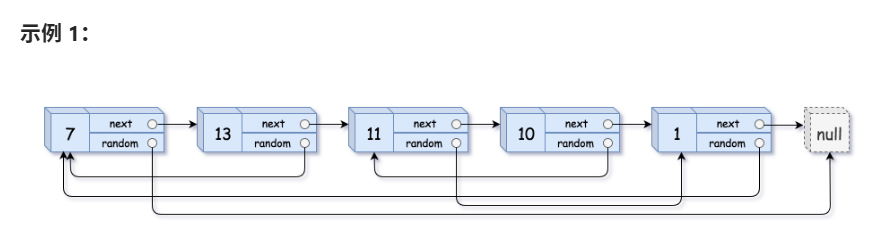
這里我們的第一步是:c[cur]=copytail;,假設這個時候cur在第一個結點,那么這個時候我們的第一個結點所對應的value就是7這個結點,也就是說把<cur,cur>這種鍵值對存放起來了。(也就相當于把另外一個新鏈表的結點指針作為cur存放起來了)
第二步是copy->random=c[cur->random];這一步相對于之前就好理解多了,直接相當于拷貝一下,把原有結點的random指針再次存放到新的對應的結點上去,所以這個思路就是先拷貝過去,再拷貝回來這種,相對于之前C語言的解法簡單很多,所以最終代碼如下:
class Solution
{
public:Node* copyRandomList(Node* head) {map<Node*, Node*> c;Node* copyhead = nullptr;Node* copytail = nullptr;Node* cur = head;while (cur){if (copytail == nullptr){copyhead = copytail = new Node(cur->val);}else{copytail->next = new Node(cur->val);copytail = copytail->next;}c[cur] = copytail;cur = cur->next;}cur = head;Node* copy = copyhead;while (cur){if (cur->random == nullptr){copy->random = nullptr;}else{copy->random = c[cur->random];}cur = cur->next;copy = copy->next;}return copyhead;}
};5.總結
這講內容主要是補充map的使用和定義等等,日后的手動模擬實現map和set都基本上要用到這兩個容器的相關知識,所以學會map和set,之后的很多題目也會變簡單一些。
好了,這講內容就到這里,下講的內容:C++-AVL(平衡二叉查找樹)(難度較高),AVL樹和后面學到的紅黑樹難度會非常之高,也是面試中常考的兩個樹,建議好好的聽(可能我自己也有一些地方不能完全的用口述出來,所以下講內容的圖片會非常多!),喜歡的可以一鍵三連哦,下講再見!










)
)


與freeRTOS)



)

窗口過渡動畫層級圖分析)