

作者: Shaoting Zhu, Linzhan Mou, Derun Li, Baijun Ye, Runhan Huang, Hang Zhao
單位:清華大學交叉信息研究院,上海期智研究院,Galaxea AI,上海交通大學電子信息與電氣工程學院
論文標題:VR-Robo: A Real-to-Sim-to-Real Framework for Visual Robot Navigation and Locomotion
出版信息:IEEE ROBOTICS AND AUTOMATION LETTERS, 2025
論文鏈接:https://arxiv.org/pdf/2502.01536
項目鏈接:https://vr-robo.github.io/
代碼鏈接:https://github.com/zst1406217/VR-Robo
主要貢獻
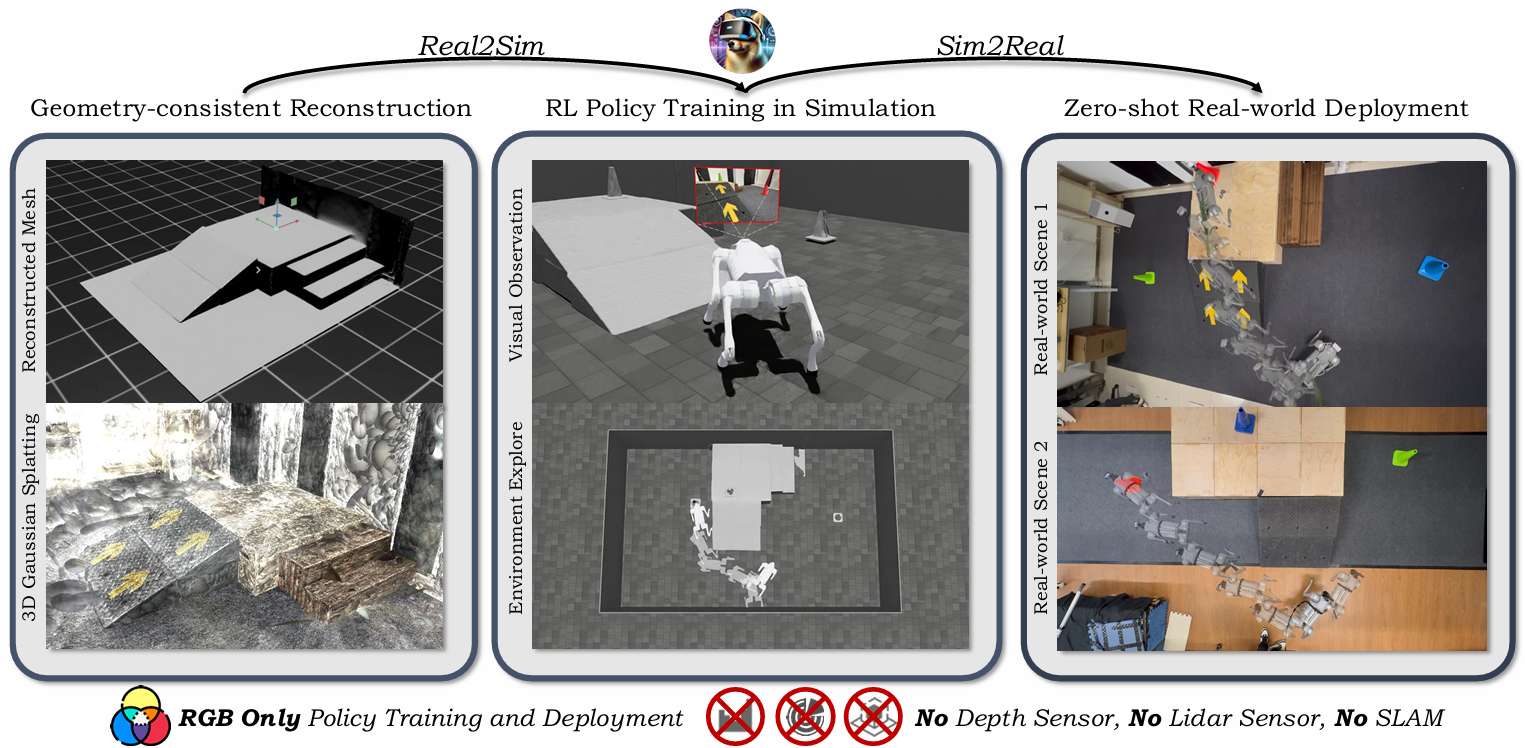
提出“Real-to-Sim-to-Real”訓練框架:從真實環境中僅通過RGB圖像重建逼真且可交互的數字孿生仿真環境,用于機器人視覺導航和運動控制策略的訓練。
引入GS-Mesh混合建模與交互機制:結合3D Gaussian Splatting和Mesh模型,實現同時具備視覺真實感與物理交互能力的仿真環境構建。
實現RGB-only零樣本遷移:所訓練的策略無需深度/LiDAR/SLAM信息,僅依賴RGB視覺即可從仿真環境無縫部署至真實世界,展現出良好的泛化能力與魯棒性。
提出場景隨機化與遮擋感知機制:通過智能體-物體的隨機化布置與遮擋感知場景合成,有效提升策略的探索能力與穩健性。
研究背景
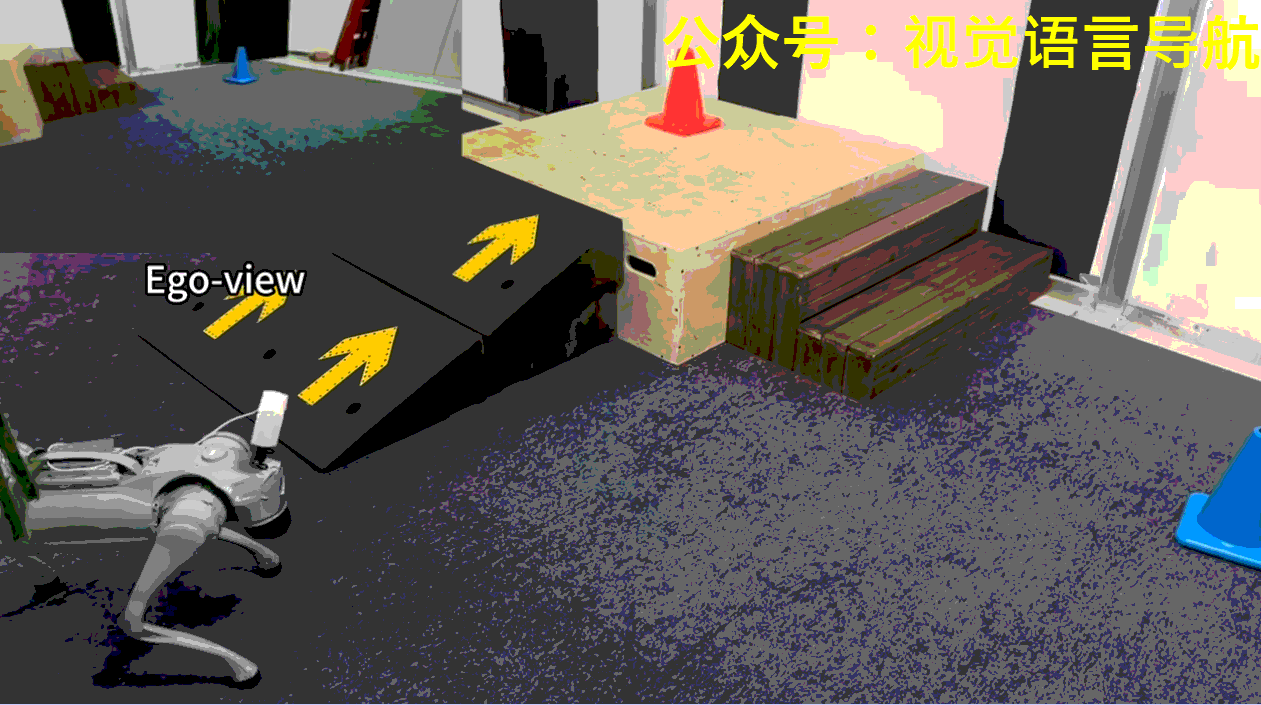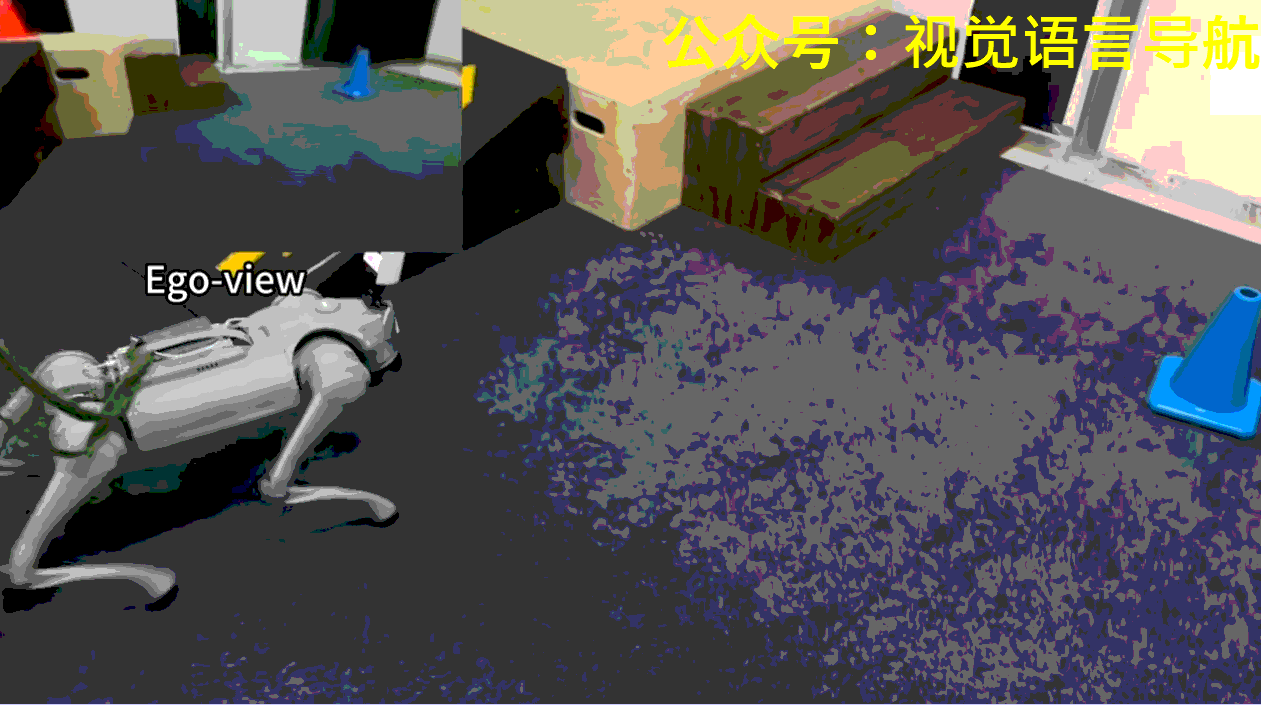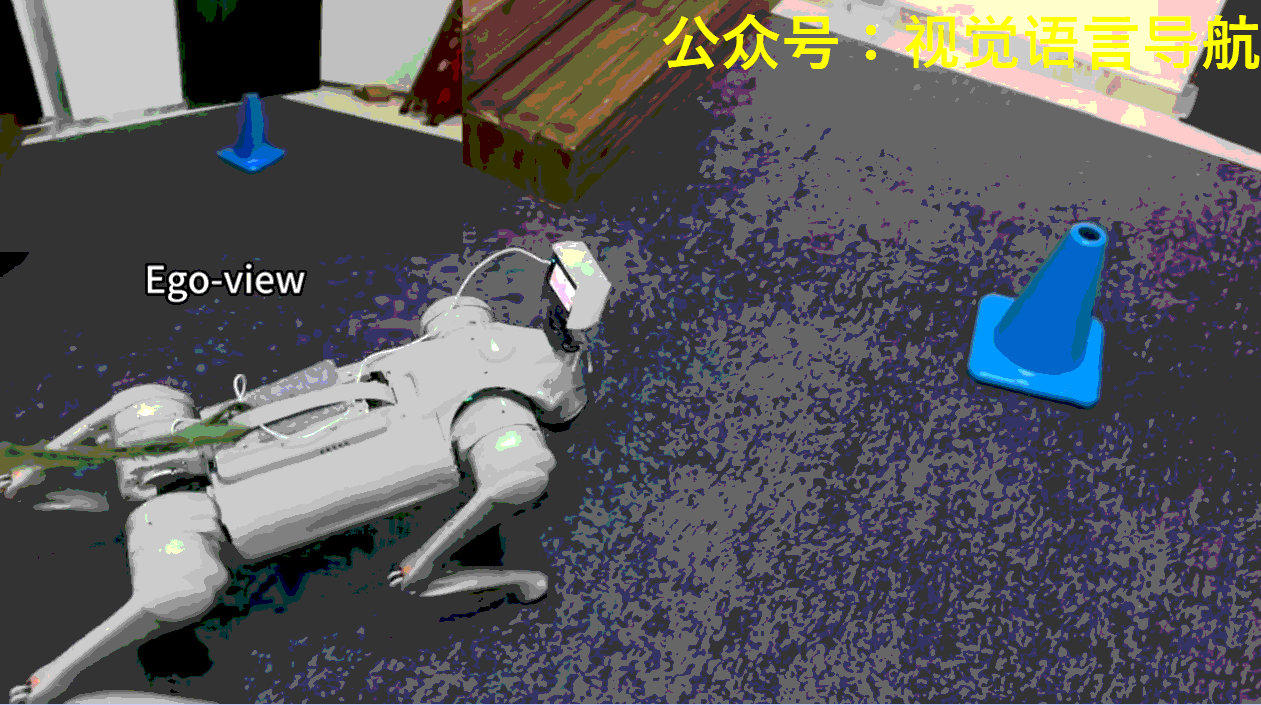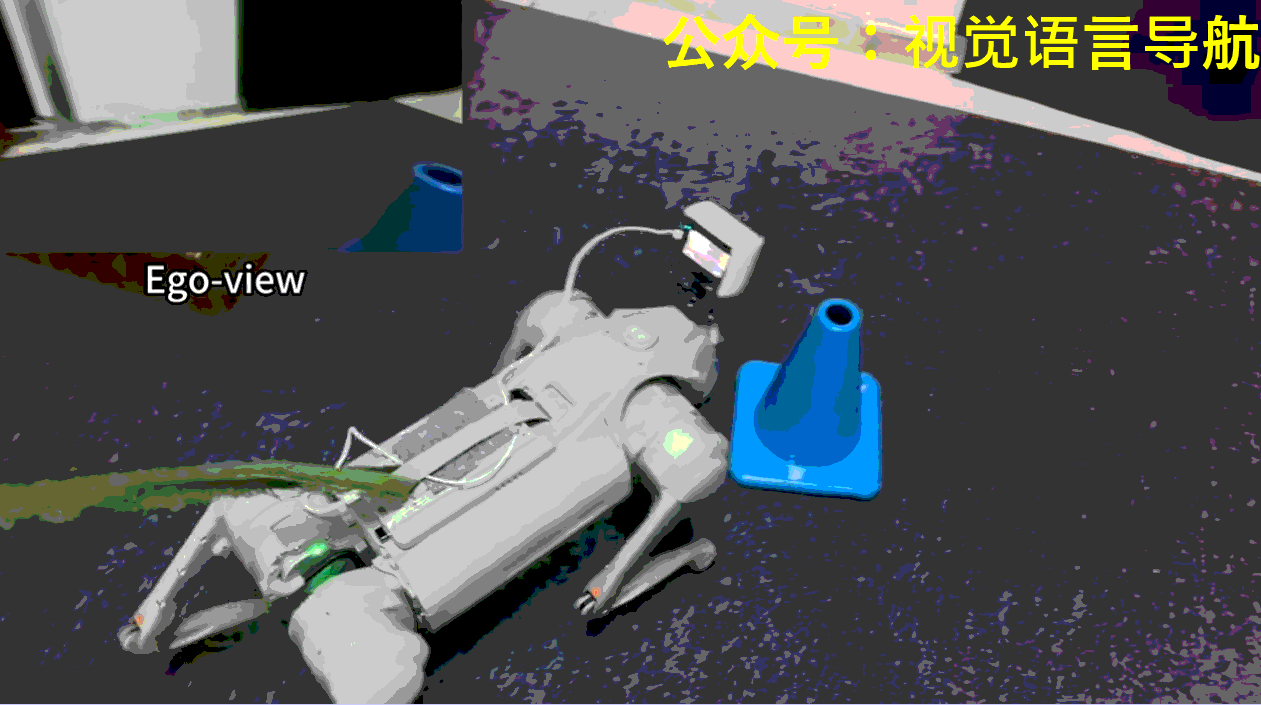
機器人導航和運動的重要性:機器人在物理世界中探索、感知和交互對于家庭服務和工業自動化等應用至關重要。
模擬訓練的優勢和挑戰:模擬訓練允許機器人在安全的環境中體驗多樣化的環境條件和失敗案例,但將模擬中學習到的策略遷移到現實世界中仍然是一個挑戰,因為模擬器通常無法復制視覺真實感和復雜的現實世界幾何形狀。
現有方法的局限性:以往的研究嘗試通過跨域深度圖像訓練代理,但這些方法主要局限于低級運動任務,因為標準模擬器難以復制現實世界的視覺保真度和復雜幾何形狀。

任務定義
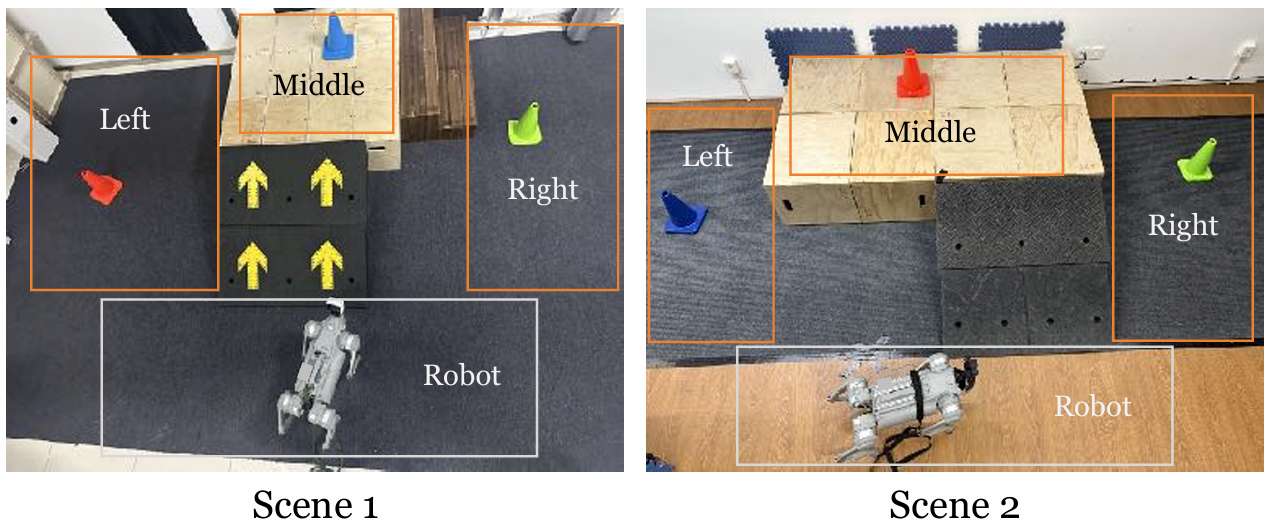
- 任務描述:
機器人需要在場景中找到并到達指定顏色的目標錐體。每個場景中央都有一個由高臺和連接地面與平臺的斜坡或樓梯組成的地形。在每次試驗開始時,機器人的初始位置和朝向是隨機的,目標錐體則放置在左、中、右三個指定區域中的一個,位置也是隨機的。
機器人可能一開始并不能看到目標錐體,因此需要探索環境以找到并定位正確的錐體。此外,如果目標錐體放置在高臺上,機器人還需要導航至斜坡以到達平臺。
- 任務難度:
任務的難度在于機器人需要在復雜的環境中進行導航和運動控制,同時還需要識別和定位目標錐體。
機器人需要具備高級別的理解能力,以識別目標錐體的顏色和位置,還需要具備低級別的運動控制能力,以在復雜的地形上進行導航和運動。
VR-Robo框架
本節介紹了VR-Robo框架,這是一個從現實到模擬再到現實的系統,用于視覺導航和運動控制。
該框架通過從現實世界中的多視圖圖像重建出逼真且可物理交互的“數字孿生”模擬環境,支持以自我為中心的視覺感知和基于網格的物理交互。
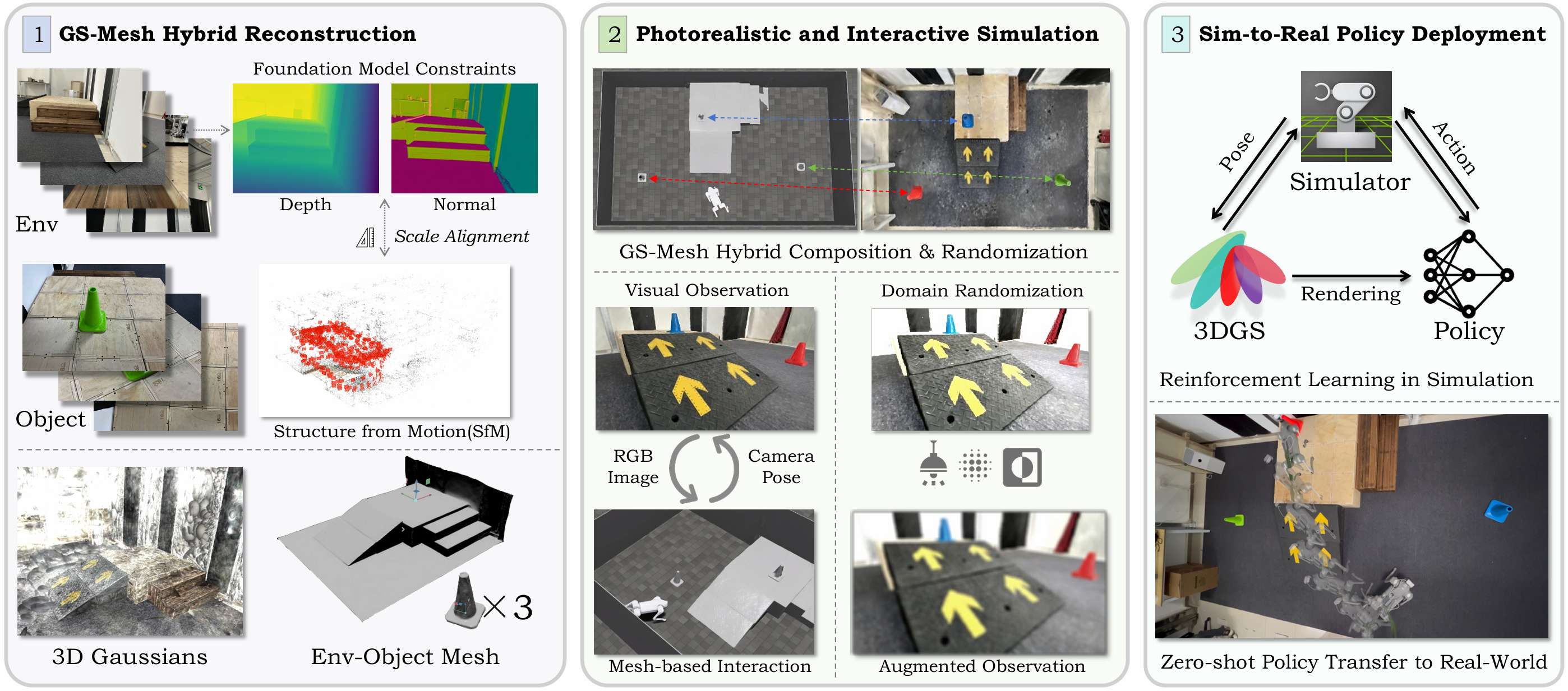
幾何一致性重建
3D Gaussian Splatting (3DGS) 介紹:3DGS通過將場景表示為一組高斯原語來實現。在優化過程中,高斯原語的協方差矩陣通過縮放矩陣和旋轉矩陣進行參數化。像素的顏色值通過體積alpha混合過程渲染得到,其中alpha值表示高斯原語在空間中的透明度。
幾何建模:通過將3D高斯橢球體展平為2D平面,增強場景的幾何建模。通過最小化其最短軸的尺度來實現這一點。利用平面表示渲染平面到相機的距離圖和法線圖,然后通過與相應平面相交的射線將它們轉換為無偏深度圖。
幾何先驗約束:在紋理較少的區域(如地面和墻壁),光度損失往往不足。因此,使用現成的單目深度估計器提供密集的深度先驗,并通過與稀疏結構運動(SfM)點的比較來解決估計深度和實際場景幾何之間的固有尺度模糊問題。同樣,采用現成的單目法線估計器為渲染的法線圖提供密集的法線正則化,以實現準確的幾何建模。
多視圖一致性約束:應用基于補丁的歸一化交叉相關(NCC)損失,以強制執行多視圖光度一致性。這通過比較兩個灰度渲染圖像之間的相似性來實現,從而確保從不同視角觀察到的場景具有一致性。
構建逼真且可交互的模擬
GS-mesh混合表示:將高斯表示與網格表示相結合,以實現逼真的視覺觀察和物理交互。高斯表示從機器人的自我中心視角生成逼真的視覺觀察,而網格表示則便于物理交互和精確的碰撞檢測。通過校準機器人相機的焦距和畸變參數,以及從Isaac Sim中獲取自我視角位置和基于四元數的方向,實現Sim和Real之間的內在參數對齊。
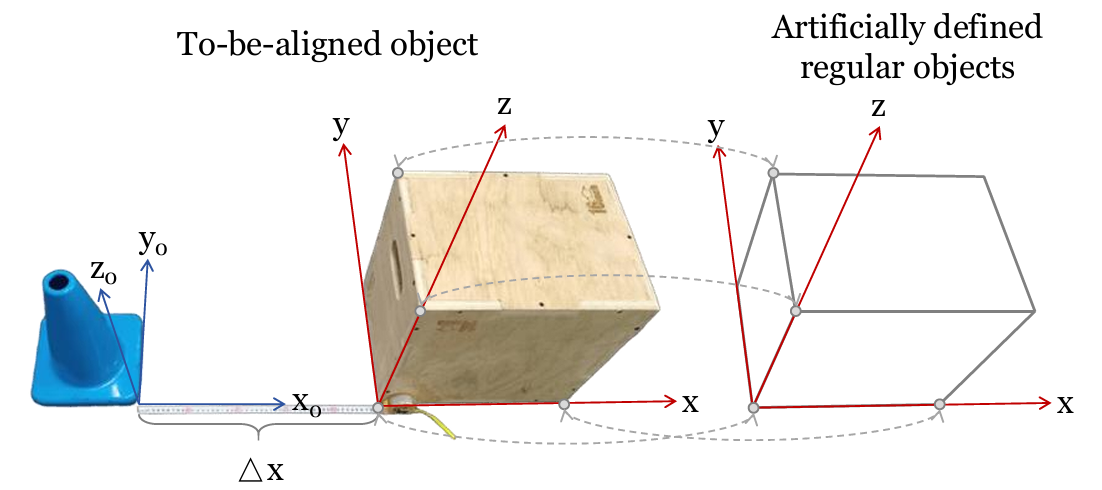
坐標對齊:通過手動匹配四個非共面點,計算齊次變換矩陣,將COLMAP坐標系統與Isaac Sim環境對齊。這種方法允許將從COLMAP重建的場景與Isaac Sim中的模擬環境精確對齊,從而確保機器人在模擬中的行為與現實世界中的行為一致。
高斯屬性調整:對齊后的高斯點的均值、縮放和旋轉進行調整,以適應新的坐標系統。這包括對高斯點的均值進行平移和旋轉,以及對縮放矩陣和旋轉矩陣進行相應的調整。此外,由于高斯點的球諧系數存儲在世界空間中,當高斯點旋轉時,需要通過Wigner D矩陣來旋轉這些系數,以確保在不同視角下顏色的正確表示。
遮擋感知組合和隨機化:使用交互式網格編輯器獲取對象的3D邊界框及其對應的變換矩陣。通過合并對象的高斯表示和網格表示,實現遮擋感知的場景組合。這種組合方式可以確保在模擬環境中正確地表示對象的可見性,從而提高機器人對環境的理解和交互能力。
在重建模擬環境中進行強化學習
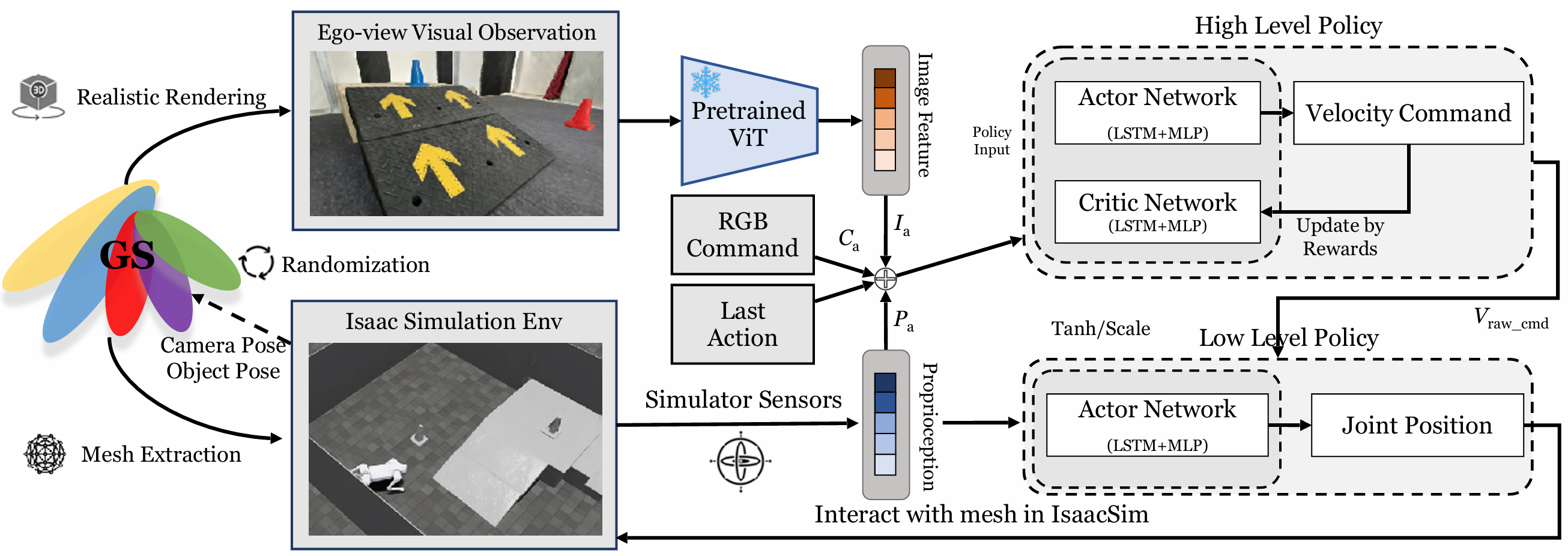
兩級異步控制策略:由于真實機器人上的計算資源有限,采用了兩級異步控制策略。高級策略以5Hz運行,低級策略以50Hz運行。高級策略通過速度命令與低級策略通信。
低級策略:低級策略接收速度命令和機器人本體感知作為輸入,并輸出期望的關節位置。該策略使四足機器人能夠攀登高達15厘米的斜坡和樓梯。然而,該策略不允許機器人直接攀登超過30厘米的地形。相反,該策略教導機器人識別和利用斜坡或樓梯到達高平臺,這在現實世界場景中非常有用。
高級策略:凍結訓練好的低級策略,獨立訓練高級策略。高級策略的輸入包括RGB圖像特征、RGB命令、上一個動作和本體感知。輸出是原始速度命令,該命令通過tanh層和速度范圍縮放以確保安全。高級策略的訓練使用強化學習(PPO)在GS-mesh混合模擬環境中進行。
獎勵設計:總獎勵包括任務獎勵和正則化獎勵。任務獎勵包括到達目標、目標距離變化、目標垂直距離變化和目標航向。正則化獎勵包括在目標處停止、跟蹤線速度、跟蹤角速度和動作L2范數。這些獎勵設計旨在鼓勵機器人有效地到達目標,并確保其行為的穩定性和效率。
訓練過程:在每個訓練周期開始時,隨機采樣機器人和錐體的位置和朝向。機器人從Isaac Sim中獲取相機姿態和錐體姿態,并發送給對齊和可編輯的3D高斯表示以渲染逼真的圖像。然后,策略根據該圖像輸出動作,該動作在Isaac Sim中應用以與網格交互。
實驗
實驗設置
- 現實到模擬重建:
論文重建了6個不同的室內房間環境,每個環境都有特定的地形,并通過放置三個不同顏色(紅、綠、藍)的錐體來隨機化環境。使用iPad或iPhone拍攝照片,這些設備易于獲取。
- 模擬中的運動訓練:
在Isaac Sim中使用單個NVIDIA 4090D GPU進行策略訓練。低級策略訓練了80,000次迭代,使用4,096個四足機器人代理進行并行訓練;高級策略訓練了8,000次迭代,使用64個四足機器人代理。
整個訓練過程大約需要三天時間。對于視覺編碼,使用了“vit tiny patch16 224”模型,去掉了其最終分類頭。Isaac Sim模擬器和基于3DGS光柵化的渲染器通過TCP網絡通信。
- 從模擬到現實部署:
在Unitree Go2四足機器人上部署策略,該機器人配備了NVIDIA Jetson Orin Nano(40 TOPS)作為機載計算機。
使用ROS2進行高級策略、低級策略和機器人之間的通信。兩種策略都在機載運行。機器人從低級策略接收期望的關節位置,用于PD控制。
使用Insta360 Ace相機捕獲RGB圖像,分辨率為320×180。校準后,相機的水平視場(FOVX)為1.5701弧度,垂直視場(FOVY)為1.0260弧度。
模擬實驗
比較實驗
模仿學習:通過遙操作收集60個不同的真實世界軌跡,并通過監督學習使用回歸優化訓練策略。
隨機背景:重新實現了LucidSim的方法,使用來自ImageNet的隨機圖像作為背景,同時保持目標對象不變。
消融實驗
紋理網格:使用SuGaR重建紋理網格,并在Isaac Sim中直接支持網格渲染作為視覺觀察。
CNN編碼器:將ViT替換為CNN編碼器,并移除了最后一層分類層。
實驗結果
- 評估指標:
在“紅色錐體到達”任務中,通過成功率達到(SR)和平均到達時間(ART)來衡量性能。如果機器人在15秒內到達距離紅色錐體0.25米以內的位置,則認為該事件成功。
對于成功的事件,記錄到達錐體所需的時間;否則,分配最大時間15秒。然后計算所有試驗的平均到達時間。
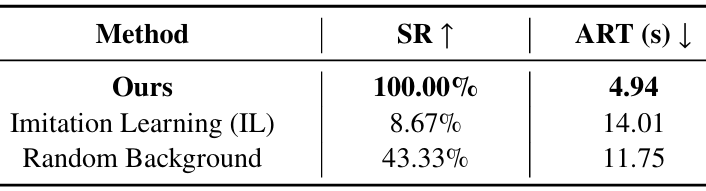
- 結果對比:
該方法在所有評估指標上均優于其他方法。模仿學習(IL)基線由于數據樣本不足和缺乏策略探索而表現不佳。CNN編碼器難以從圖像中提取精確的特征。僅從RGB圖像進行重建,紋理網格在紋理較少的區域(如地面和墻壁)會出現明顯的紋理膨脹。
這些偽影會降低渲染質量,甚至可能阻礙機器人的運動。相比之下,該方法裁剪并僅使用中心地形的網格,并從GS渲染觀察結果,有效地避免了這些問題。隨機背景設置丟失了原始場景的特定特征。這些特定于場景的特征對于機器人有效探索環境至關重要。
現實世界實驗
定性實驗
在不同的條件下進行定性實驗,包括6種不同的場景、不同的目標錐體顏色、光照條件的變化、隨機干擾、背景變化以及在不同的機器人上進行訓練。補充材料中提供了詳細的演示。這些實驗突出了該方法的魯棒性,展示了其適應各種環境和條件的能力。
定量實驗
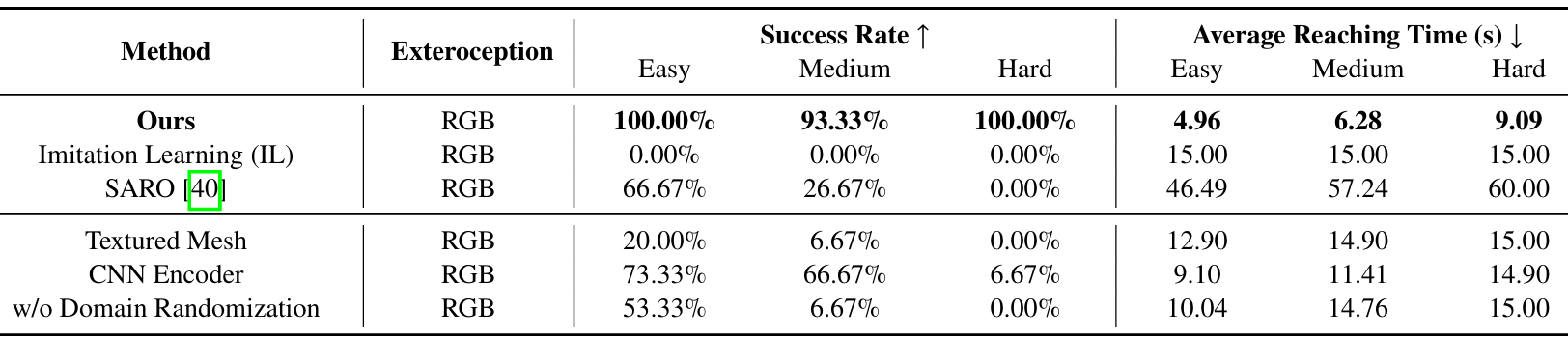
- 實驗設置:除了上述方法外,還進行了兩項專門針對現實世界環境設計的基線方法的實驗,這些方法不能直接與模擬環境中的實驗進行比較:
SARO:SARO使機器人能夠利用視覺語言模型(VLM)跨越三維地形進行導航。
無領域隨機化:排除了第IV-C節中描述的領域隨機化。
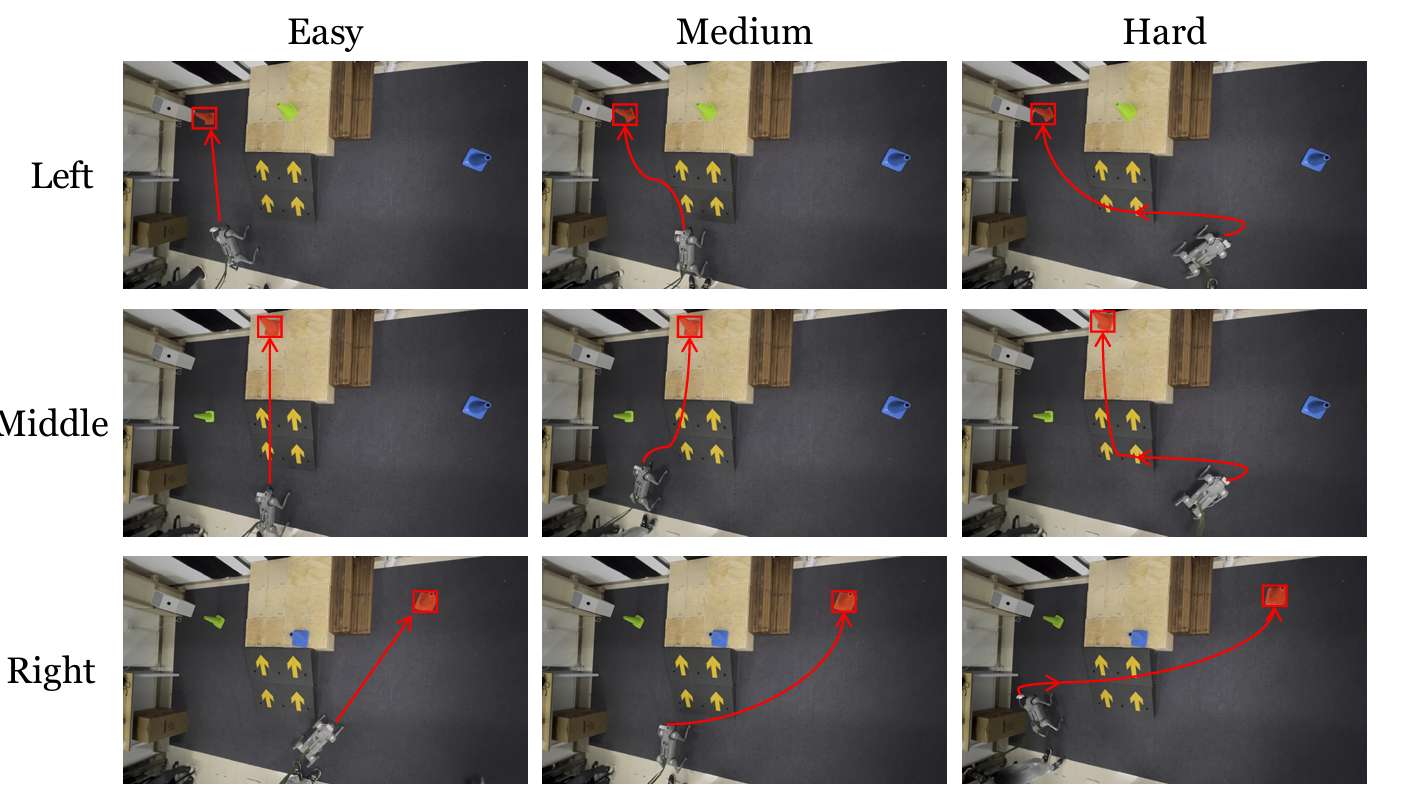
- 任務難度分類:
所有現實世界的定量實驗均在場景1中的“紅色錐體到達”任務設置中進行。根據機器人的起始位置,將任務分為三個難度級別:簡單、中等和困難。
對于簡單任務,目標錐體直接可見;對于中等任務,機器人需要轉動一定角度才能看到目標錐體;對于困難任務,機器人從錐體很遠的地方開始,并且幾乎背對目標錐體。
隨機選擇3組錐體位置,每組包含一個簡單任務、一個中等任務和一個困難任務。對于每個任務,重復實驗5次。然后計算成功率(SR)和平均到達時間(ART)。
對于SARO,由于視覺語言模型(VLM)所需的長推理時間,最大時間延長至60秒。在真實機器人實驗中,如果機器人接觸到目標錐體,則認為任務成功。

- 實驗結果:
該方法在所有難度級別上均實現了最高的成功率,并且始終記錄了最短的平均到達時間,證明了其效率和魯棒性。由于現實世界設置中的固有隨機性,在中等任務中存在一個失敗案例,盡管在困難任務中所有試驗都成功了。
在其他方法中,SARO在簡單任務上取得了中等的成功率(66.67%),但在中等和困難任務上表現不佳。這種表現不佳主要是由于缺乏歷史上下文和在復雜場景中有限的探索能力。如果機器人最初看不到目標,則不太可能成功。
結論與未來工作
- 結論:
VR-Robo框架能夠在逼真且可交互的模擬環境中訓練視覺運動策略,并成功地將這些策略零樣本部署到多樣化的真實世界場景中。
大量的實驗結果表明,該框架的智能體能夠成功學習到魯棒且有效的策略,用于應對具有挑戰性的高級任務,并且可以零樣本部署到各種現實世界場景。
- 未來工作:
擴展框架以適應更大規模和更復雜的環境,并將生成模型納入場景重建中,以實現更通用的策略學習。







)











)
