本文目錄:
- 一、從梯度角度入手
- (一)梯度下降算法回顧
- (二)常用優化算法
- 1.SGD(Stochastic Gradient Descent)- 隨機梯度下降
- 2.BGD (Batch Gradient Descent) - 批量梯度下降
- 3.MBGD (Mini-Batch Gradient Descent) - 小批量梯度下降
- (三)梯度優化算法的不足與革新
- 1.指數加權平均
- 2.動量算法(Momentum)
- 3.動量法(Momentum)有效克服 “平緩”、”鞍點”、”峽谷” 的問題
- 二、從自適應學習率角度入手
- (一)自適應梯度算法(AdaGrad)
- 1.概念
- 2.更新過程
- (二)RMSProp優化算法
- 1.概念
- 2.更新過程
- 三、自適應矩估計(Adam)
- (一)概念
- (二)Adam的更新過程
- 附贈:
- 1.BGD/SGD/MBGD三種梯度優化方法對比
- 2.普通SGD與動量法(Momentum)的對比
- 3.AdaGrad、RMSProp、Adam 優缺點對比
前言:前面講述了PyTorch人工神經網絡的激活函數、損失函數等內容,今天講解優化方法。
簡單來說,優化方法主要是從兩個角度來入手,一個是梯度,一個是學習率。
一、從梯度角度入手
(一)梯度下降算法回顧
梯度下降法簡單來說就是一種尋找使損失函數最小化的方法**。
從數學角度來看,梯度的方向是函數增長速度最快的方向,那么梯度的反方向就是函數減少最快的方向,所以有:

其中,η是學習率,如果學習率太小,那么每次訓練之后得到的效果都太小,增大訓練的時間成本。如果,學習率太大,那就有可能直接跳過最優解,進入無限的訓練中。解決的方法就是,學習率也需要隨著訓練的進行而變化。
(二)常用優化算法
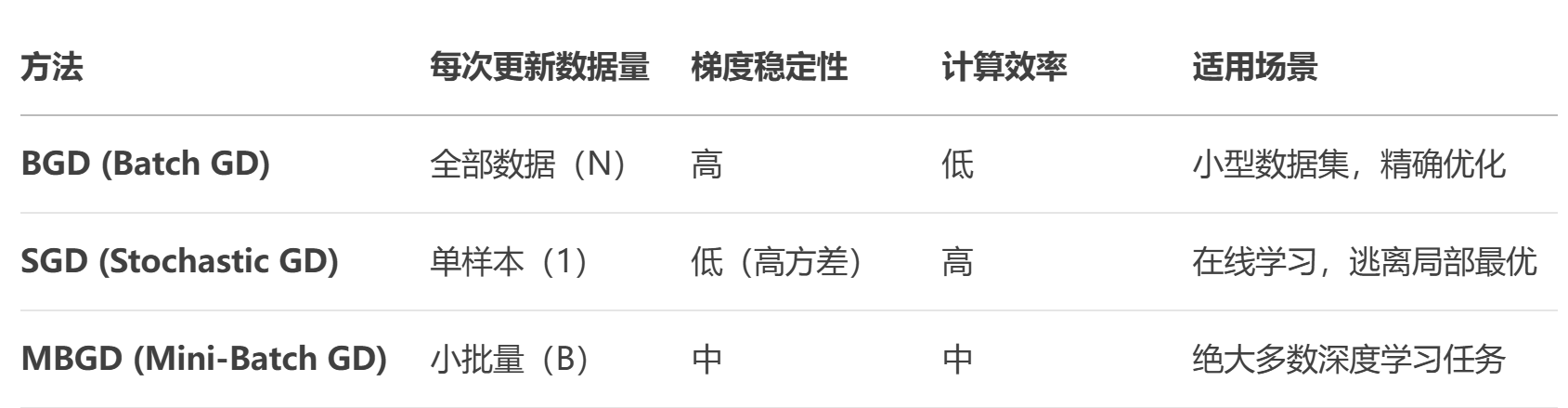
在梯度角度優化算法中,SGD(隨機梯度下降)、BGD(批量梯度下降) 和 SBGD(小批量梯度下降) 是三種基礎但核心的優化方法,而它們的區別主要在于 每次參數更新時使用的數據量。
1.SGD(Stochastic Gradient Descent)- 隨機梯度下降

PyTorch代碼實現:將batch_size設為1:
train_loader = DataLoader(dataset, batch_size=1, shuffle=True) # 逐樣本加載
2.BGD (Batch Gradient Descent) - 批量梯度下降

PyTorch代碼實現:直接對整個數據集計算平均梯度
for epoch in range(epochs):optimizer.zero_grad()outputs = model(train_inputs) # 全量數據loss = criterion(outputs, train_labels)loss.backward() # 計算全量梯度optimizer.step()
3.MBGD (Mini-Batch Gradient Descent) - 小批量梯度下降

PyTorch代碼實現:設置合適的batch_size
train_loader = DataLoader(dataset, batch_size=64, shuffle=True) # 小批量加載
(三)梯度優化算法的不足與革新
梯度下降優化算法中,可能會碰到以下情況:
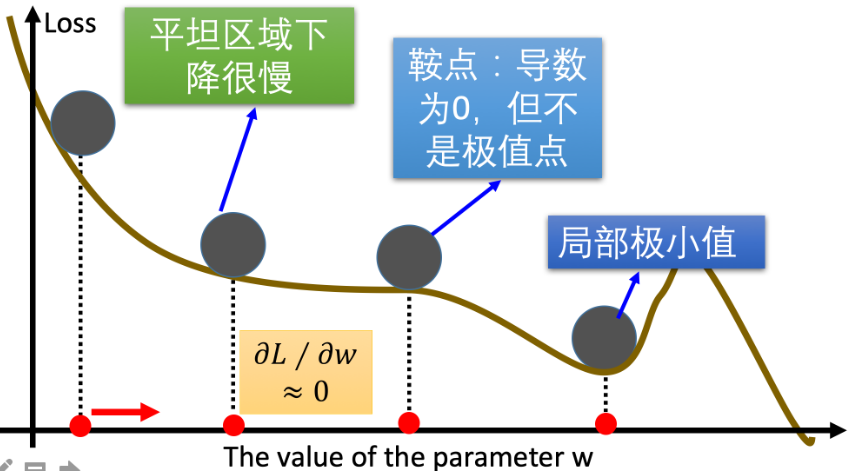
- 碰到平緩區域,梯度值較小,參數優化變慢;
- 碰到 “鞍點” ,梯度為0,參數無法優化;
- 碰到局部最小值,參數不是最優。
對于這些問題, 出現了一些對梯度下降算法的優化方法,例如:動量法
動量法(Momentum)詳解:
簡單來說,動量法是對SGD算法的改進,它運用了指數加權平均思想,最后起到減少震蕩,加速收斂的效果。動量法尤其適用于高曲率、小但一致的梯度或帶噪聲的梯度場景。
1.指數加權平均
一種用于處理序列數據(如時間序列、梯度下降中的參數更新)的平滑方法,廣泛應用于深度學習優化算法(如動量法(Momentum)、Adam、RMSprop等)。其核心思想是對歷史數據賦予指數衰減的權重,從而平衡當前值與歷史值的貢獻。


注意·:通過調整 β,可以靈活平衡近期數據與歷史數據的權重。
指數加權思想代碼實現:
例:
from matplotlib import pyplot as plt
import torchx=torch.arange(1,31)
torch.manual_seed(1)
y=torch.randn(30)*10
y_ewa=[]
beta=0.9
for idx,t in enumerate(y,1):if idx==1:y_ewa.append(t)else:y_ewa.append(beta*y_ewa[idx-2]+(1-beta)*t)plt.scatter(x,y_ewa)
plt.show()2.動量算法(Momentum)
首先,梯度計算公式(指數加權平均): s t = β s t ? 1 + ( 1 ? β ) g t s_t=βs_{t?1}+(1?β)g_t st?=βst?1?+(1?β)gt?
參數更新公式: w t = w t ? 1 ? η s t w_t=w_{t?1}?ηs_t wt?=wt?1??ηst?
公式參數說明:
s t s_t st?是當前時刻指數加權平均梯度值
s t ? 1 s_{t-1} st?1?是歷史指數加權平均梯度值
g t g_t gt?是當前時刻的梯度值
β 是調節權重系數,通常取 0.9 或 0.99
η是學習率
w t w_t wt?是當前時刻模型權重參數
PyTroch中編程實踐如下:
例:
def test01():# 1 初始化權重參數w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)loss = ((w ** 2) / 2.0).sum()# 2 實例化優化方法:SGD 指定參數beta=0.9optimizer = torch.optim.SGD([w], lr=0.01, momentum=0.9)# 3 第1次更新 計算梯度,并對參數進行更新optimizer.zero_grad()loss.backward()optimizer.step()print('第1次: 梯度w.grad: %f, 更新后的權重:%f' % (w.grad.numpy(), w.detach().numpy()))# 4 第2次更新 計算梯度,并對參數進行更新# 使用更新后的參數機選輸出結果loss = ((w ** 2) / 2.0).sum()optimizer.zero_grad()loss.backward()optimizer.step()print('第2次: 梯度w.grad: %f, 更新后的權重:%f' % (w.grad.numpy(), w.detach().numpy()))
3.動量法(Momentum)有效克服 “平緩”、”鞍點”、”峽谷” 的問題

- 當處于鞍點位置時,由于當前的梯度為 0,參數無法更新。但是 Momentum 動量梯度下降算法已經在先前積累了一些梯度值,很有可能使得跨過鞍點;
- mini-batch 每次選取少數的樣本梯度確定前進方向,可能會出現震蕩,使得訓練時間變長,而Momentum 使用指數加權平均,平滑了梯度的變化,使得前進方向更加平緩,有利于加快訓練過程,一定程度上也降低了 “峽谷” 問題的影響。

二、從自適應學習率角度入手
(一)自適應梯度算法(AdaGrad)
1.概念
一種梯度下降算法,通過自適應調整每個參數的學習率。
其核心思想是:對頻繁更新的參數降低學習率,對不頻繁更新的參數保持較大的學習率。
AdaGrad主要用于稀疏矩陣:對于稀疏特征(如NLP中的one-hot編碼),其對應的參數更新頻率低,梯度多為零或極小值,因此 G t,ii增長緩慢,使得自適應學習率 保持較大。而密集特征的參數因頻繁更新導致 G t,ii快速增大,學習率顯著下降。

2.更新過程


PyTroch中編程實踐如下:
例:
def test02():# 1 初始化權重參數w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)loss = ((w ** 2) / 2.0).sum()# 2 實例化優化方法:adagrad優化方法optimizer = torch.optim.Adagrad([w], lr=0.01)# 3 第1次更新 計算梯度,并對參數進行更新optimizer.zero_grad()loss.backward()optimizer.step()print('第1次: 梯度w.grad: %f, 更新后的權重:%f' % (w.grad.numpy(), w.detach().numpy()))# 4 第2次更新 計算梯度,并對參數進行更新# 使用更新后的參數機選輸出結果loss = ((w ** 2) / 2.0).sum()optimizer.zero_grad()loss.backward()optimizer.step()print('第2次: 梯度w.grad: %f, 更新后的權重:%f' % (w.grad.numpy(), w.detach().numpy()))
結果顯示:
第1次: 梯度w.grad: 1.000000, 更新后的權重:0.990000
第2次: 梯度w.grad: 0.990000, 更新后的權重:0.982965
(二)RMSProp優化算法
1.概念
**RMSProp 優化算法由Geoffrey Hinton提出,是對 AdaGrad 的優化:緩解AdaGrad的平方算法可能會使得學習率過早、過量的降低,導致模型訓練后期學習率太小,較難找到最優解的情況。
其使用指數加權平均梯度替換歷史梯度的平方和。
相比AdaGrad有如下優勢:1.因使得梯度平方和不再無限增長,從而避免了學習率持續下降;2.因近期梯度對學習率的影響更大,避免了快速適應最新梯度。
2.更新過程


RMSProp特點:

PyTroch中編程實踐如下:
例:
def test03():# 1 初始化權重參數w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)loss = ((w ** 2) / 2.0).sum()# 2 實例化優化方法:RMSprop算法,其中alpha對應betaoptimizer = torch.optim.RMSprop([w], lr=0.01, alpha=0.9)# 3 第1次更新 計算梯度,并對參數進行更新optimizer.zero_grad()loss.backward()optimizer.step()print('第1次: 梯度w.grad: %f, 更新后的權重:%f' % (w.grad.numpy(), w.detach().numpy()))# 4 第2次更新 計算梯度,并對參數進行更新# 使用更新后的參數機選輸出結果loss = ((w ** 2) / 2.0).sum()optimizer.zero_grad()loss.backward()optimizer.step()print('第2次: 梯度w.grad: %f, 更新后的權重:%f' % (w.grad.numpy(), w.detach().numpy()))
結果顯示:
第1次: 梯度w.grad: 1.000000, 更新后的權重:0.968377
第2次: 梯度w.grad: 0.968377, 更新后的權重:0.945788
三、自適應矩估計(Adam)
(一)概念
深度學習中最常用的優化算法之一,它結合了動量法(Momentum)和RMSProp的優點,通過自適應調整每個參數的學習率,并利用梯度的一階矩(均值)和二階矩(方差)估計,實現了高效、穩定的參數更新。
主要有以下特點:

(二)Adam的更新過程



PyTroch中編程實踐如下:
def test04():# 1 初始化權重參數w = torch.tensor([1.0], requires_grad=True)loss = ((w ** 2) / 2.0).sum()# 2 實例化優化方法:Adam算法,其中betas是指數加權的系數optimizer = torch.optim.Adam([w], lr=0.01, betas=[0.9, 0.99])# 3 第1次更新 計算梯度,并對參數進行更新optimizer.zero_grad()loss.backward()optimizer.step()print('第1次: 梯度w.grad: %f, 更新后的權重:%f' % (w.grad.numpy(), w.detach().numpy()))# 4 第2次更新 計算梯度,并對參數進行更新# 使用更新后的參數機選輸出結果loss = ((w ** 2) / 2.0).sum()optimizer.zero_grad()loss.backward()optimizer.step()print('第2次: 梯度w.grad: %f, 更新后的權重:%f' % (w.grad.numpy(), w.detach().numpy()))
結果顯示:
第1次: 梯度w.grad: 1.000000, 更新后的權重:0.990000
第2次: 梯度w.grad: 0.990000, 更新后的權重:0.980003
附贈:
1.BGD/SGD/MBGD三種梯度優化方法對比
2.普通SGD與動量法(Momentum)的對比

3.AdaGrad、RMSProp、Adam 優缺點對比

今日的分享到此結束,下篇文章繼續分享優化方法,敬請期待。
yolov5——模型訓練)
 —— make、Makefile、git和gdb)


)




)









![[ctfshow web入門] web92 `==`特性與intval特性](http://pic.xiahunao.cn/[ctfshow web入門] web92 `==`特性與intval特性)