在深度學習領域,圖像分類任務是一個經典的應用,而CIFAR-10數據集則是圖像分類研究中的重要基準數據集之一。該數據集包含10類不同的圖像,每類有6,000個32x32像素的彩色圖像,共計60,000個圖像。在傳統的集中式學習中,所有數據都被集中到一個服務器上進行訓練。然而,隨著數據隱私問題的日益嚴重以及分布式數據處理需求的增加,聯邦學習(Federated Learning, FL)作為一種分布式學習方法逐漸被廣泛應用于許多實際場景中,尤其是在需要保護用戶隱私的場景。本文將討論如何使用聯邦學習進行CIFAR-10圖像分類任務,并探討其中的挑戰和解決方案。
一、聯邦學習簡介
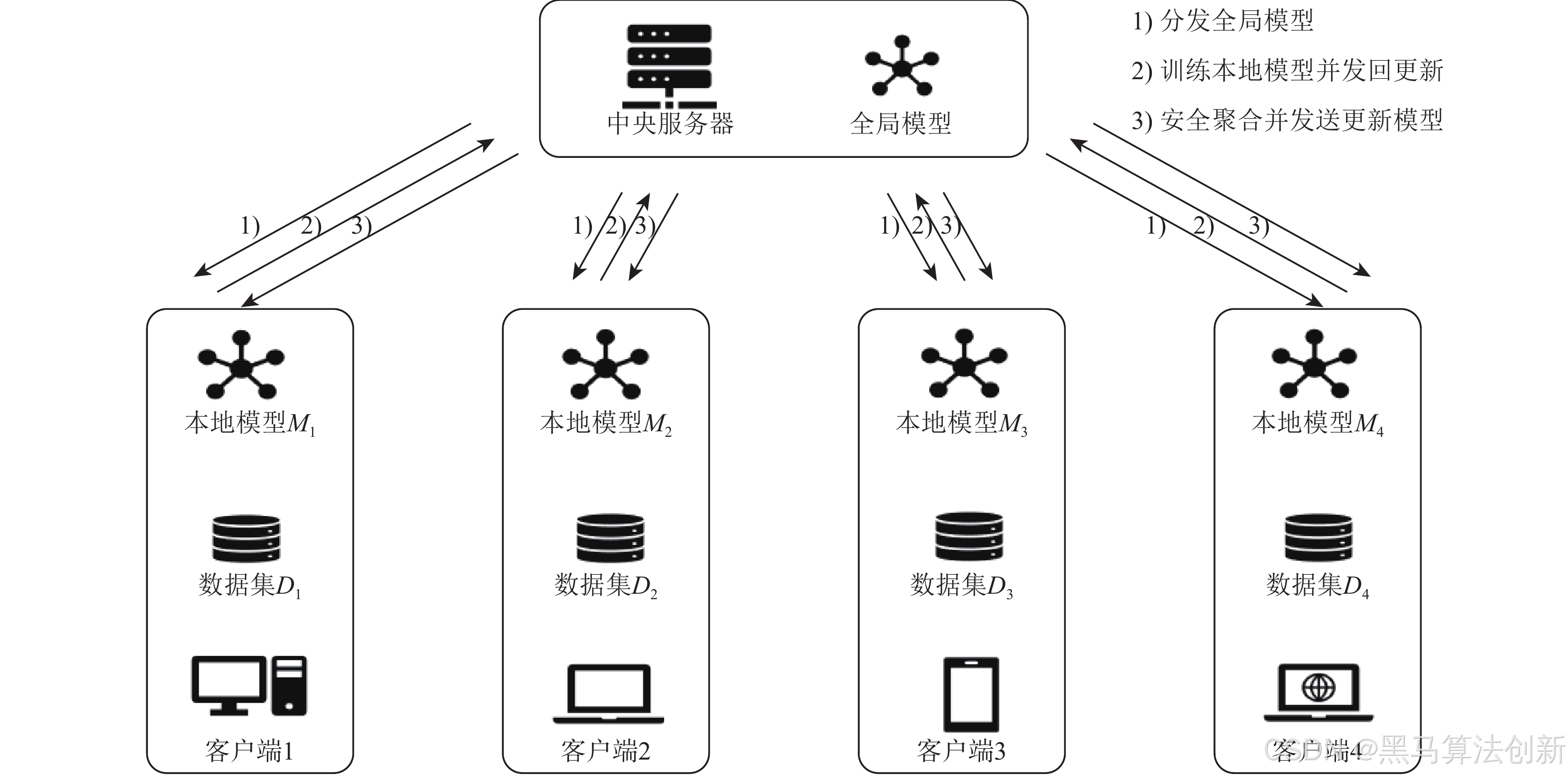
聯邦學習是一種分布式機器學習方法,旨在保護數據隱私。與傳統的集中式學習不同,聯邦學習將模型訓練過程分散到多個客戶端(如智能手機、IoT設備等),每個客戶端本地擁有數據,并在本地進行模型訓練。訓練完成后,客戶端將其模型更新(如梯度或權重)發送到中央服務器,服務器將這些更新聚合形成全局模型。最終,全局模型會回傳給各個客戶端用于進一步的本地訓練。這種方式可以有效避免數據泄露,同時減少了數據傳輸帶來的帶寬壓力。
二、CIFAR-10分類任務的挑戰
CIFAR-10數據集是圖像分類中的標準數據集,但在聯邦學習環境下使用該數據集進行分類任務時,存在一些特有的挑戰:
-
非獨立同分布(Non-IID)問題:在聯邦學習中&


)
)















