@浙大疏錦行
對聚類的結果根據具體的特征進行解釋,進而推斷出每個簇的實際含義
兩種思路:
-
你最開始聚類的時候,就選擇了你想最后用來確定簇含義的特征,
-
最開始用全部特征來聚類,把其余特征作為 x,聚類得到的簇類別作為標簽構建監督模型,進而根據重要性篩選特征,來確定要根據哪些特征賦予含義。
下面使用第二種方法,先計算再分析
先分析出和聚類有關的幾個重要特征
再根據不同的簇對應的特征與簇的大小進行分析,從而最后將結果進行總結
進行聚類
# 先運行之前預處理好的代碼
import pandas as pd
import pandas as pd #用于數據處理和分析,可處理表格數據。
import numpy as np #用于數值計算,提供了高效的數組操作。
import matplotlib.pyplot as plt #用于繪制各種類型的圖表
import seaborn as sns #基于matplotlib的高級繪圖庫,能繪制更美觀的統計圖形。
import warnings
warnings.filterwarnings("ignore")# 設置中文字體(解決中文顯示問題)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系統常用黑體字體
plt.rcParams['axes.unicode_minus'] = False # 正常顯示負號
data = pd.read_csv('data.csv') #讀取數據# 先篩選字符串變量
discrete_features = data.select_dtypes(include=['object']).columns.tolist()
# Home Ownership 標簽編碼
home_ownership_mapping = {'Own Home': 1,'Rent': 2,'Have Mortgage': 3,'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)# Years in current job 標簽編碼
years_in_job_mapping = {'< 1 year': 1,'1 year': 2,'2 years': 3,'3 years': 4,'4 years': 5,'5 years': 6,'6 years': 7,'7 years': 8,'8 years': 9,'9 years': 10,'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)# Purpose 獨熱編碼,記得需要將bool類型轉換為數值
data = pd.get_dummies(data, columns=['Purpose'])
data2 = pd.read_csv("data.csv") # 重新讀取數據,用來做列名對比
list_final = [] # 新建一個空列表,用于存放獨熱編碼后新增的特征名
for i in data.columns:if i not in data2.columns:list_final.append(i) # 這里打印出來的就是獨熱編碼后的特征名
for i in list_final:data[i] = data[i].astype(int) # 這里的i就是獨熱編碼后的特征名# Term 0 - 1 映射
term_mapping = {'Short Term': 0,'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True) # 重命名列
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() #把篩選出來的列名轉換成列表# 連續特征用中位數補全
for feature in continuous_features: mode_value = data[feature].mode()[0] #獲取該列的眾數。data[feature].fillna(mode_value, inplace=True) #用眾數填充該列的缺失值,inplace=True表示直接在原數據上修改。# 最開始也說了 很多調參函數自帶交叉驗證,甚至是必選的參數,你如果想要不交叉反而實現起來會麻煩很多
# 所以這里我們還是只劃分一次數據集
from sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列刪除
y = data['Credit Default'] # 標簽
# # 按照8:2劃分訓練集和測試集
# X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%訓練集,20%測試集
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns# 標準化數據(聚類前通常需要標準化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# X_scaled
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns# 評估不同 k 值下的指標
k_range = range(2, 11) # 測試 k 從 2 到 10
inertia_values = []
silhouette_scores = []
ch_scores = []
db_scores = []for k in k_range:kmeans = KMeans(n_clusters=k, random_state=42)kmeans_labels = kmeans.fit_predict(X_scaled)inertia_values.append(kmeans.inertia_) # 慣性(肘部法則)silhouette = silhouette_score(X_scaled, kmeans_labels) # 輪廓系數silhouette_scores.append(silhouette)ch = calinski_harabasz_score(X_scaled, kmeans_labels) # CH 指數ch_scores.append(ch)db = davies_bouldin_score(X_scaled, kmeans_labels) # DB 指數db_scores.append(db)print(f"k={k}, 慣性: {kmeans.inertia_:.2f}, 輪廓系數: {silhouette:.3f}, CH 指數: {ch:.2f}, DB 指數: {db:.3f}")# # 繪制評估指標圖
# plt.figure(figsize=(15, 10))# # 肘部法則圖(Inertia)
# plt.subplot(2, 2, 1)
# plt.plot(k_range, inertia_values, marker='o')
# plt.title('肘部法則確定最優聚類數 k(慣性,越小越好)')
# plt.xlabel('聚類數 (k)')
# plt.ylabel('慣性')
# plt.grid(True)# # 輪廓系數圖
# plt.subplot(2, 2, 2)
# plt.plot(k_range, silhouette_scores, marker='o', color='orange')
# plt.title('輪廓系數確定最優聚類數 k(越大越好)')
# plt.xlabel('聚類數 (k)')
# plt.ylabel('輪廓系數')
# plt.grid(True)# # CH 指數圖
# plt.subplot(2, 2, 3)
# plt.plot(k_range, ch_scores, marker='o', color='green')
# plt.title('Calinski-Harabasz 指數確定最優聚類數 k(越大越好)')
# plt.xlabel('聚類數 (k)')
# plt.ylabel('CH 指數')
# plt.grid(True)# # DB 指數圖
# plt.subplot(2, 2, 4)
# plt.plot(k_range, db_scores, marker='o', color='red')
# plt.title('Davies-Bouldin 指數確定最優聚類數 k(越小越好)')
# plt.xlabel('聚類數 (k)')
# plt.ylabel('DB 指數')
# plt.grid(True)# plt.tight_layout()
# plt.show()# 提示用戶選擇 k 值
selected_k = 3 # 這里選擇3后面好分析,也可以根據圖選擇最佳的k值# 使用選擇的 k 值進行 KMeans 聚類
kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labels# 使用 PCA 降維到 2D 進行可視化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# KMeans 聚類結果可視化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=kmeans_labels, palette='viridis')
plt.title(f'KMeans Clustering with k={selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 KMeans 聚類標簽的前幾行
print(f"KMeans Cluster labels (k={selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts())
shap分析特征
x1= X.drop('KMeans_Cluster',axis=1) # 刪除聚類標簽列
y1 = X['KMeans_Cluster']
# 構建隨機森林,用shap重要性來篩選重要性
import shap
import numpy as np
from sklearn.ensemble import RandomForestClassifier # 隨機森林分類器
model = RandomForestClassifier(n_estimators=100, random_state=42) # 隨機森林模型
model.fit(x1, y1) # 訓練模型,此時無需在意準確率 直接全部數據用來訓練了
shap.initjs()
# 初始化 SHAP 解釋器
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(x1) # 這個計算耗時
shap_values.shape # 第一維是樣本數,第二維是特征數,第三維是類別數
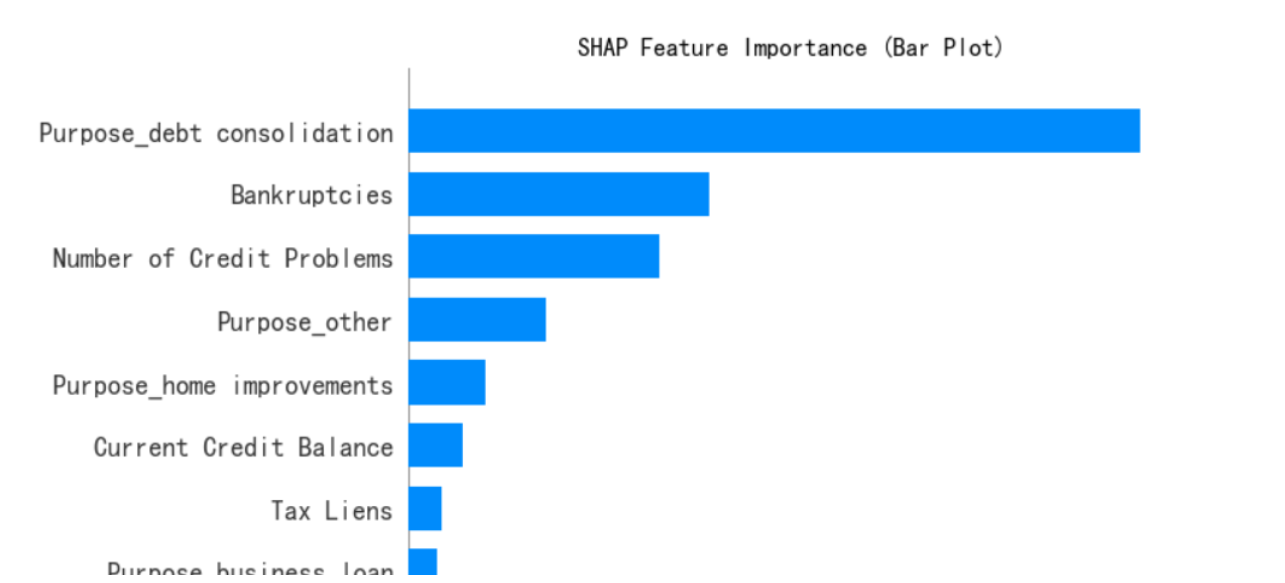
# --- 1. SHAP 特征重要性條形圖 (Summary Plot - Bar) ---
print("--- 1. SHAP 特征重要性條形圖 ---")
shap.summary_plot(shap_values[:, :, 0], x1, plot_type="bar",show=False) # 這里的show=False表示不直接顯示圖形,這樣可以繼續用plt來修改元素,不然就直接輸出了
plt.title("SHAP Feature Importance (Bar Plot)")
plt.show()
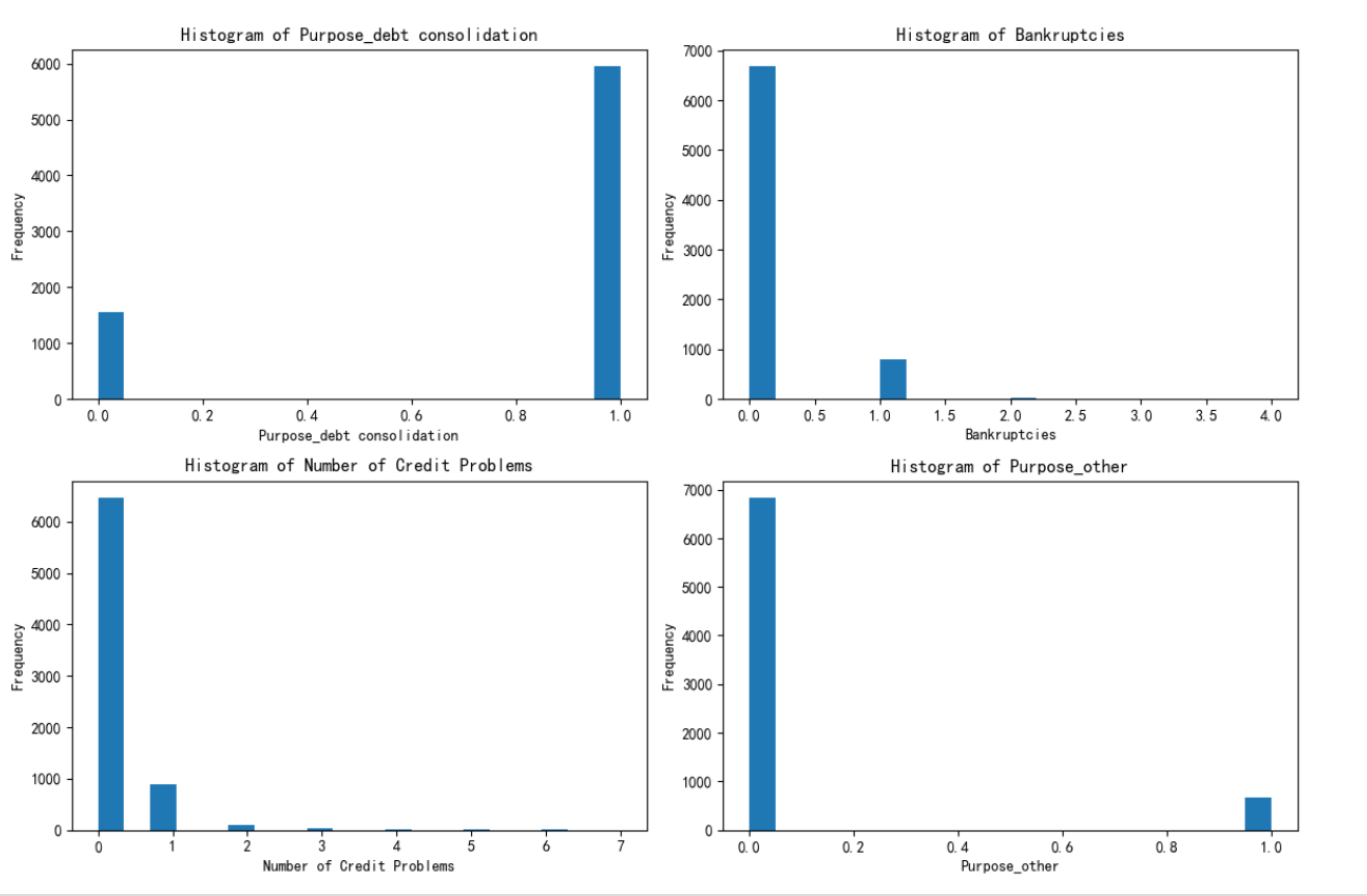
繪制總樣本中的前四個重要性的特征分布圖
# X["Purpose_debt consolidation"].value_counts() # 統計每個唯一值的出現次數
import matplotlib.pyplot as plt# 總樣本中的前四個重要性的特征分布圖
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()
繪制出每個簇對應的這四個特征的分布圖
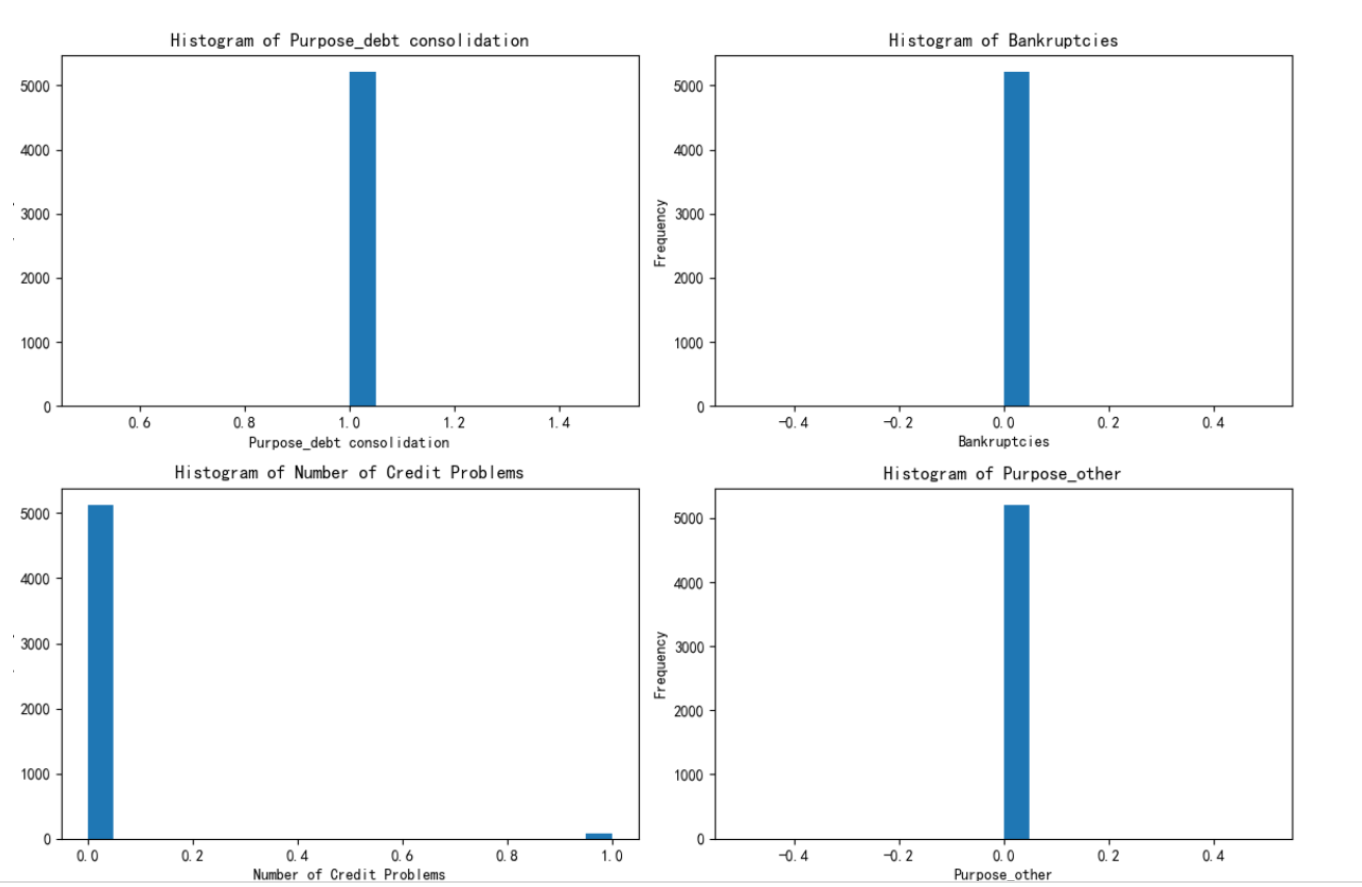
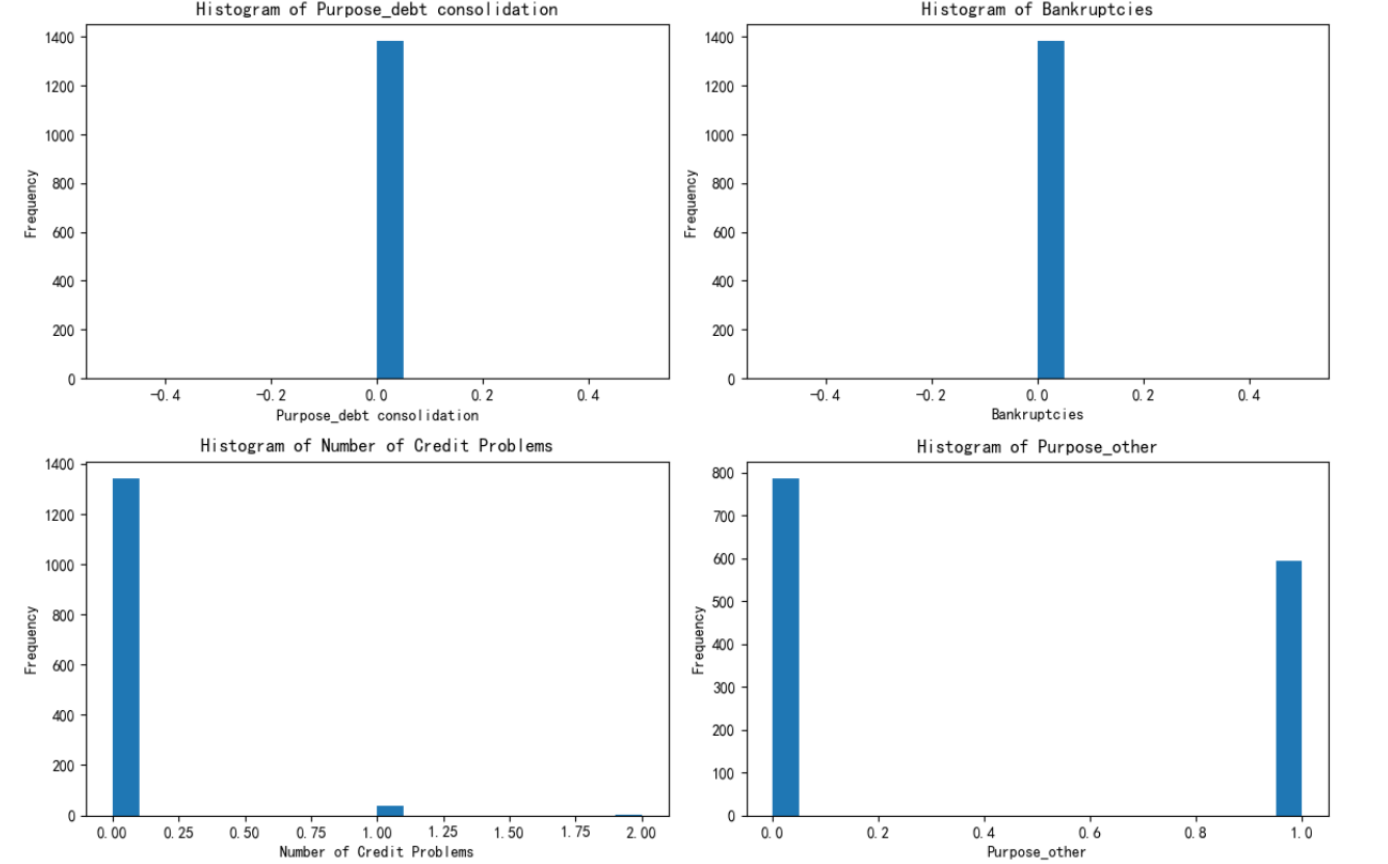
根據繪制的圖進行解釋





)
vue3中的pinia狀態管理、組件通信)













