顛覆傳統!單樣本熵最小化如何重塑大語言模型訓練范式?
大語言模型(LLM)的訓練往往依賴大量標注數據與復雜獎勵設計,但最新研究發現,僅用1條無標注數據和10步優化的熵最小化(EM)方法,竟能在數學推理任務上超越傳統強化學習(RL)。這一突破性成果或將改寫LLM的訓練規則,快來了解這場效率革命!
論文標題
One-shot Entropy Minimization
來源
arXiv:2505.20282v2 [cs.CL] + https://arxiv.org/abs/2505.20282
PS: 整理了LLM、量化投資、機器學習方向的學習資料,關注同名公眾號 「 亞里隨筆」 即刻免費解鎖
文章核心
研究背景
大語言模型(LLM)的訓練后優化(post-training)近年來發展迅猛,DeepSeek-R1、Kimi-K1.5和OpenAI o-series等模型展現出卓越的推理能力。然而,傳統強化學習(RL)方法在應用中面臨顯著挑戰:其不僅需要大量高質量標注數據,還需精心設計規則化獎勵函數以最大化優勢信號,同時防范“獎勵黑客”問題。與之形成鮮明對比的是,熵最小化(EM)作為完全無監督方法,在訓練效率與便捷性上具備潛在優勢。本研究通過訓練13,440個LLM,系統驗證了EM僅用單條無標注數據和10步優化即可超越傳統RL的可能性,為LLM訓練后優化范式提供了全新思路。
研究問題
1. 數據效率低下:RL需數千條標注數據,而無監督方法的潛力尚未充分挖掘。
2. 訓練復雜度高:RL需設計復雜獎勵函數,且易出現“獎勵黑客”(reward hacking)問題。
3. 收斂速度緩慢:RL通常需數千步訓練,而高效優化方法亟待探索。
主要貢獻
1. 單樣本高效優化:提出One-shot Entropy Minimization(單樣本熵最小化)方法,僅用1條無標注數據+10步優化,性能超越傳統RL(如在Qwen2.5-Math-7B模型上,MATH500數據集得分提升25.8分)。
2. 理論機制創新:揭示EM與RL的核心目標一致(釋放預訓練模型潛力),但通過“對數幾率右移”(logits shift)機制驅動模型行為,與RL的左移方向相反,更利于生成高概率正確路徑。
3. 關鍵因素解析:發現溫度參數(temperature)是訓練與推理的核心變量,EM在推理時溫度趨勢與RL完全相反(EM隨溫度升高性能下降,RL反之)。
3. 范式重新定義:證明EM是“分布塑形工具”而非學習方法,其效果在10步內即可完成,后續訓練 loss 下降與性能提升解耦。
方法論精要
1. 核心算法/框架
熵最小化算法:通過最小化生成token的條件熵 H t H_t Ht?,迫使模型對預測更自信,僅計算生成token(非prompt部分)的熵。

數據選擇策略:基于“方差篩選”選擇最具不確定性的輸入——計算模型在k次采樣中的“pass@k準確率方差”,優先選擇方差最高的prompt(如NuminaMath數據集中的風力壓力計算問題)。


2. 關鍵參數設計原理
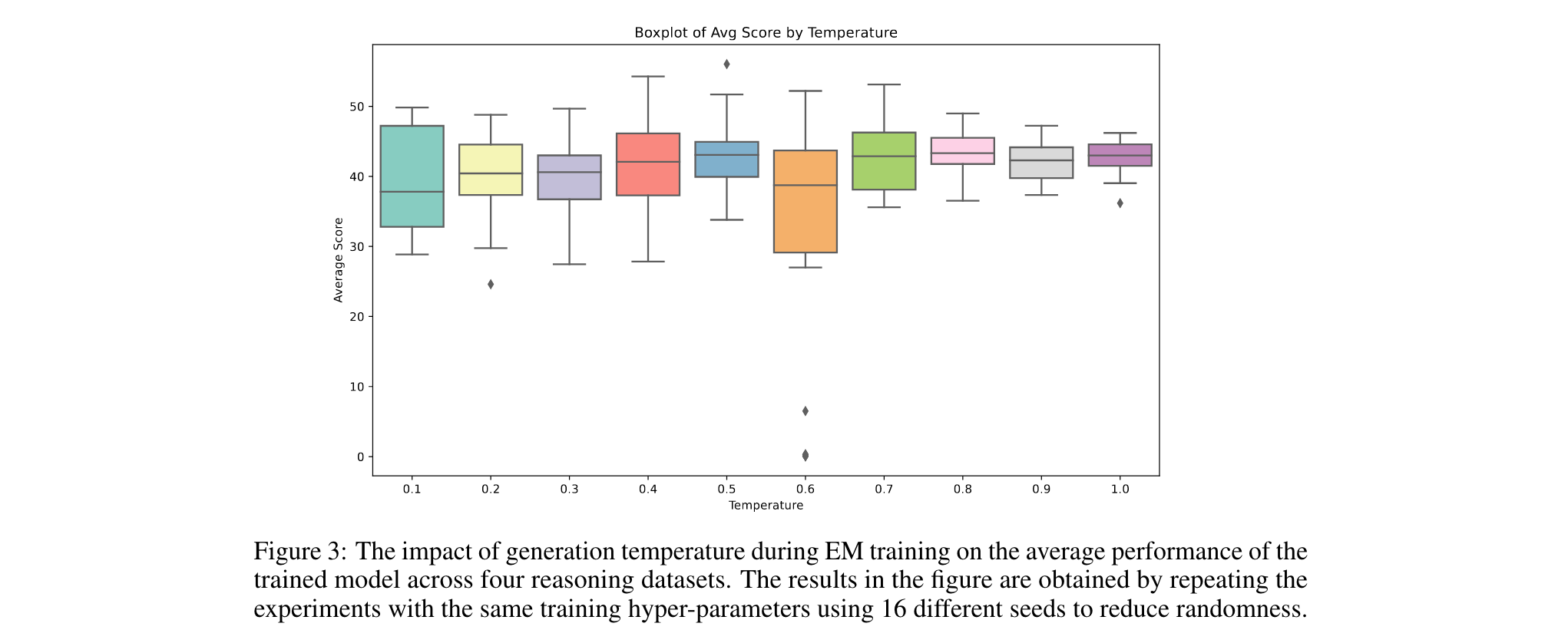
溫度參數0.5:訓練時溫度過低會使分布過窄,過高則增加隨機性,0.5時性能方差最大,易獲峰值表現。
學習率 2 × 10 ? 5 2×10^{-5} 2×10?5:10步快速收斂的最優選擇,過大易導致過自信,過小則收斂緩慢。
3. 創新性技術組合
無監督+方差篩選:無需標注數據,僅通過模型自身預測的不確定性篩選有效輸入,形成“熵敏感”訓練信號。
對數幾率分析:EM使logits分布右偏(skewness提升至1.54),集中概率質量于正確路徑,而RL導致左偏(skewness降至0.02)。
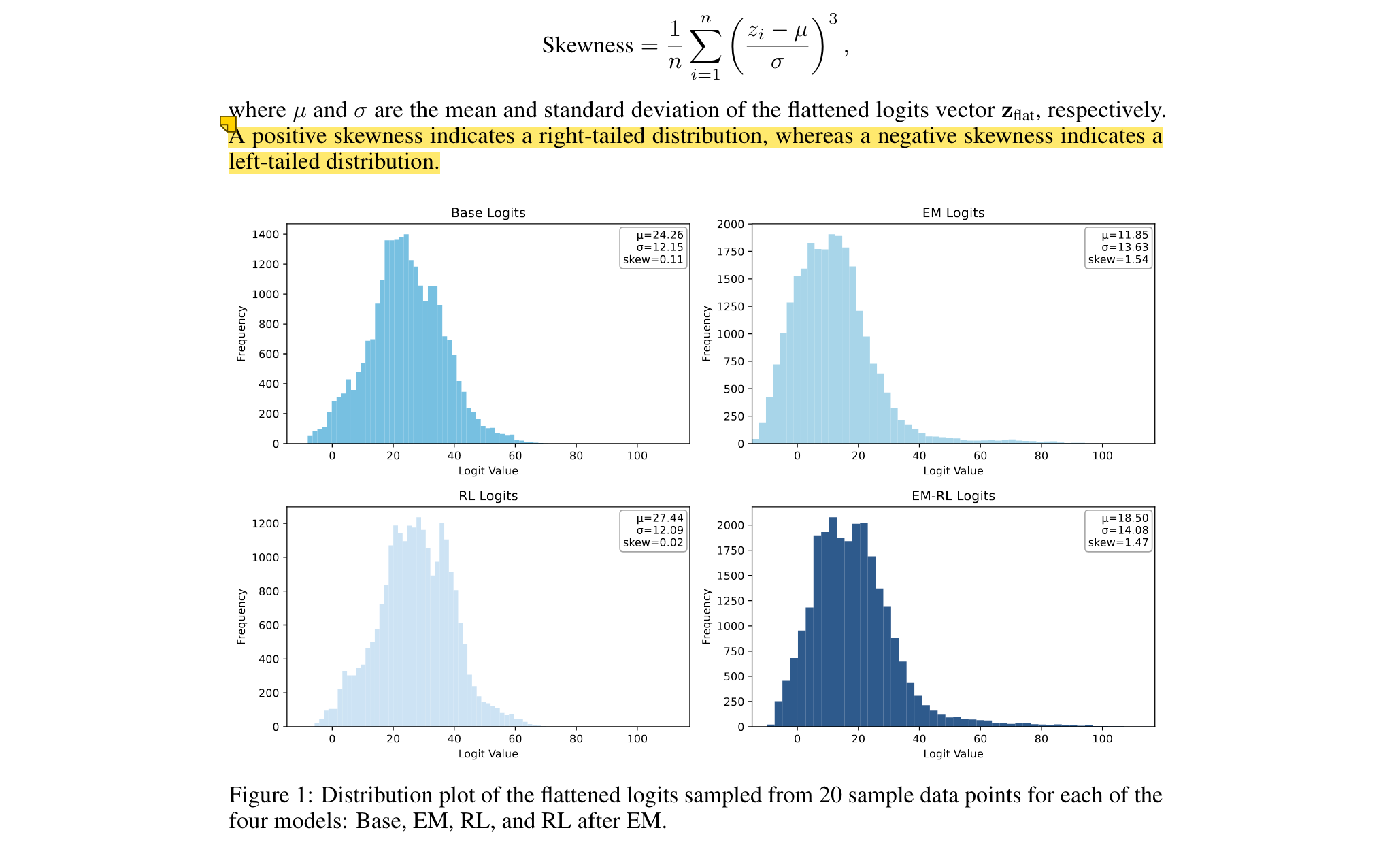
4. 實驗驗證方式
數據集:數學推理基準(MATH500、Minerva Math、Olympiad Bench、AMC23),以及LLaMA-3.1-8B、Qwen2.5系列等多模型測試。
基線方法:OpenReasoner-Zero、SimpleRL-Zoo、Prime-Zero等RL模型,對比其在數據量(129k-230k)與訓練步數(240-4000步)上的劣勢。
實驗洞察
1. 性能優勢
- Qwen2.5-Math-7B模型:EM 1-shot使MATH500從53.0提升至78.8(+25.8),Minerva Math從11.0至35.3(+24.3),平均提升24.7分,接近Prime-Zero-7B等SOTA模型。
- 跨模型泛化:在Qwen2.5-7B-Instruct模型上,EM將平均準確率從43.12%提升至44.5%,且對弱模型(LLaMA-3.1-8B)也有29.6%→42.2%的提升。
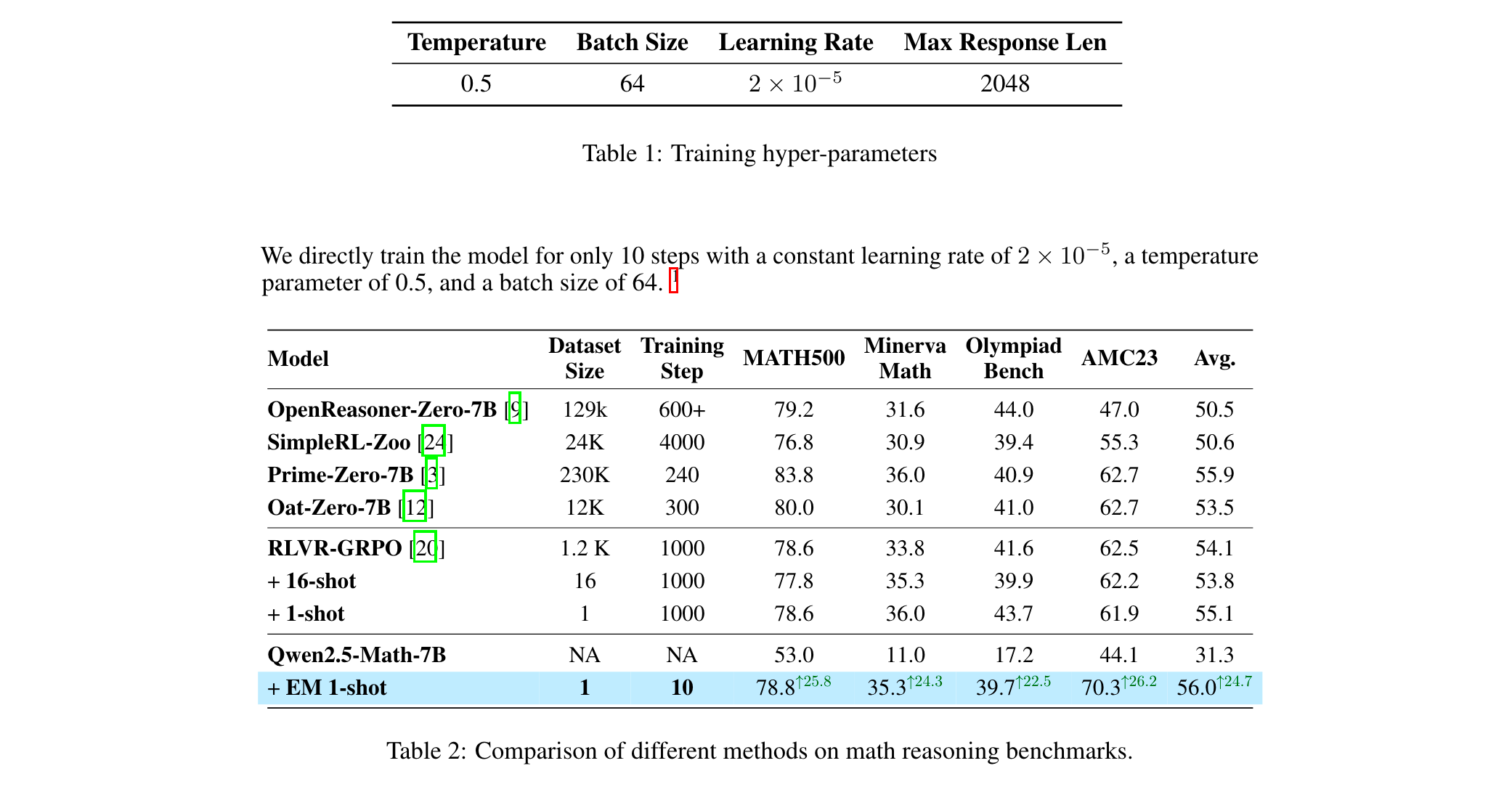
2. 效率突破
- 訓練步數:僅10步收斂,較RL的數千步提升數百倍;單樣本訓練速度比RL快3個數量級。
- 數據效率:1條數據效果超過RL的數千條,如EM 1-shot在AMC23上得分70.3,超越SimpleRL-Zoo(24k數據+4000步)的55.3分。
3. 消融研究
- 溫度影響:訓練時溫度0.5性能最佳,推理時溫度與性能負相關(溫度1.0時EM平均得分下降5%,RL上升3%)。
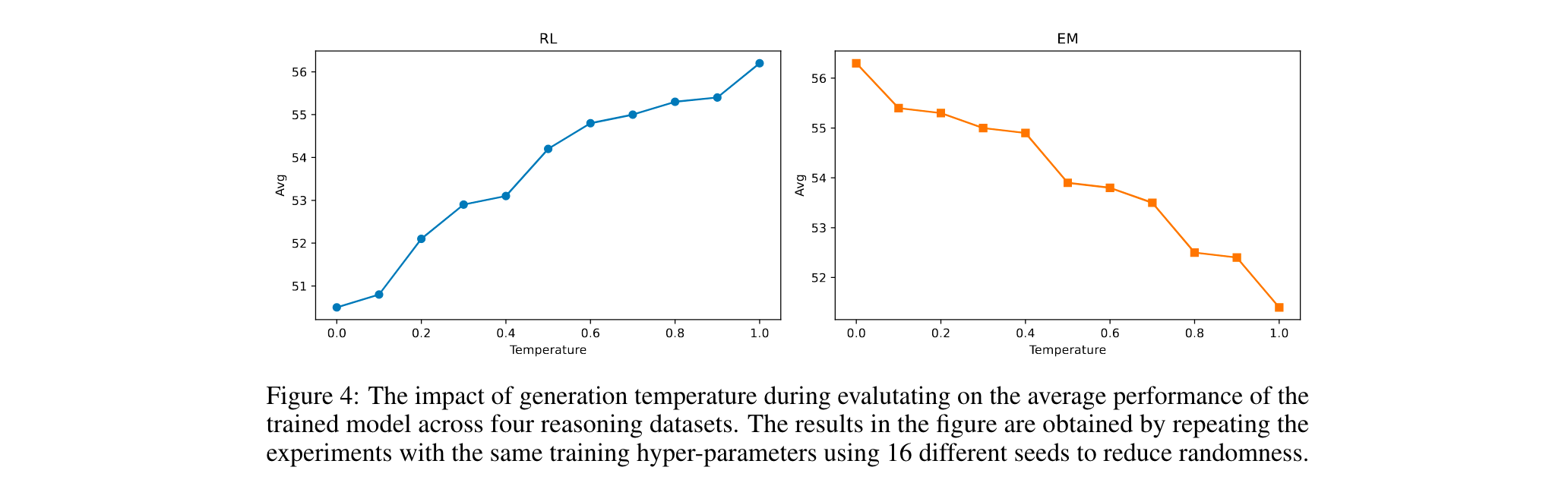
- 訓練順序:EM先于RL可提升性能(如Qwen2.5-Math-7B+EM+RL在AMC23得70.3),而RL后接EM會導致性能下降(如SimpleRL-Zoo+EM得分降低5.9分)。
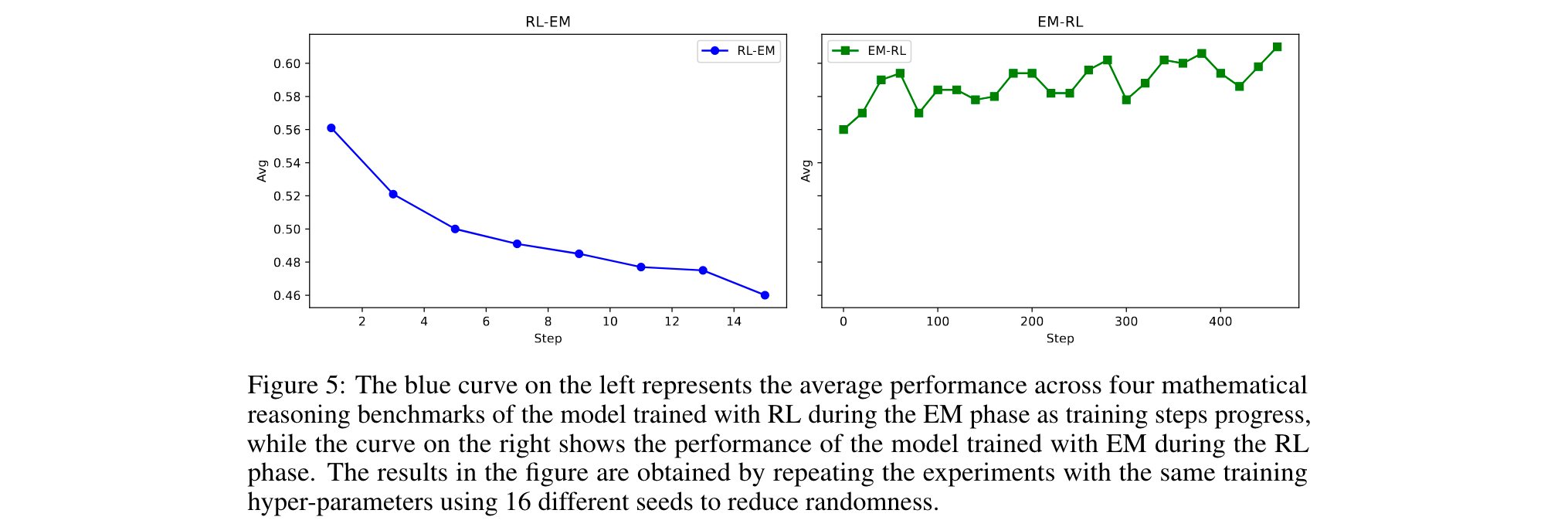
Future Works
1. 穩定化訓練機制開發:針對EM訓練中存在的隨機性問題(相同設置下不同種子得分差異可達2倍),探索自適應早停策略或正則化方法,如基于損失-性能解耦點的動態終止準則,降低溫度參數敏感性,構建更魯棒的訓練框架。
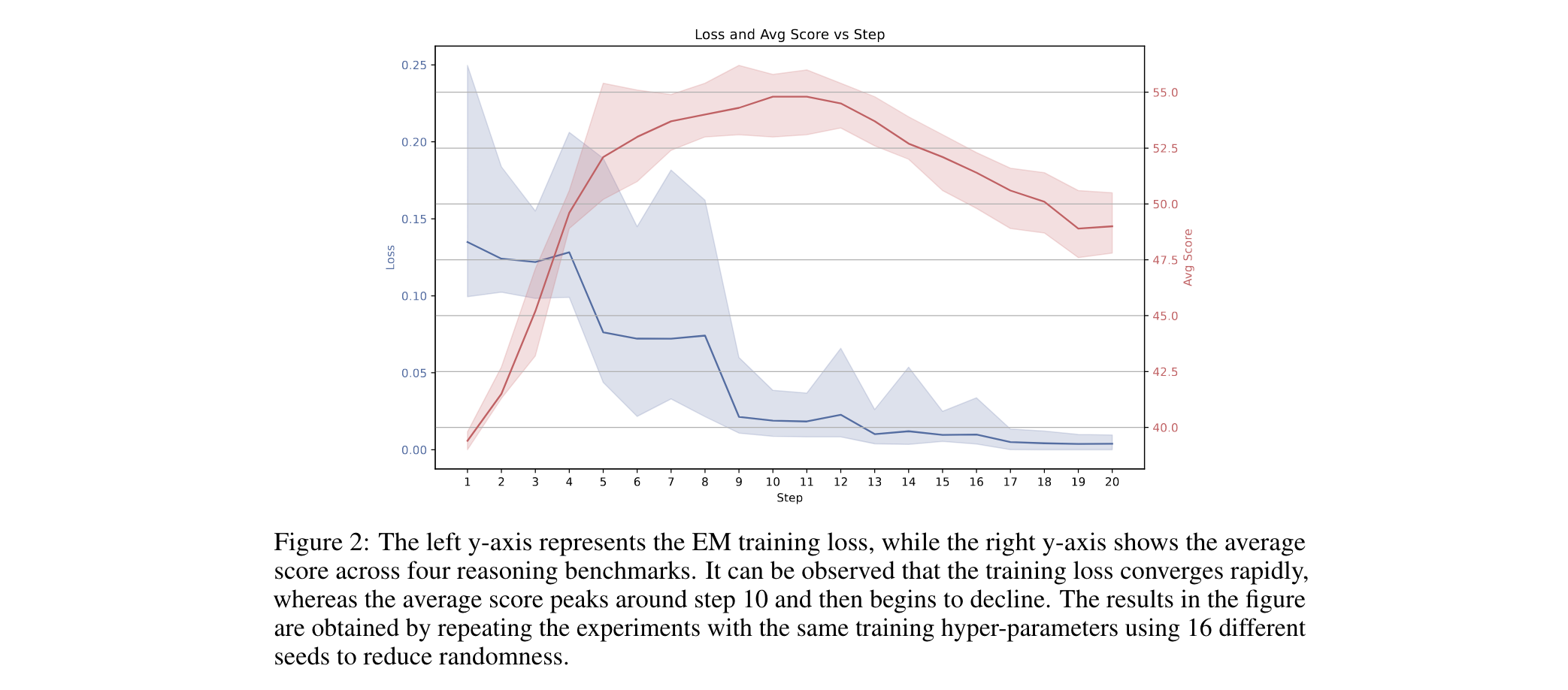
2. 跨領域泛化探索:當前EM主要驗證于數學推理任務,未來將拓展至對話生成、代碼補全、科學文獻總結等多模態場景,研究序列級熵優化(如全句語義熵)與任務特定先驗融合技術,驗證其作為通用分布塑形工具的普適性。
3. 混合優化范式構建:探索EM與監督微調(SFT)、RL的協同機制,例如設計“EM預塑形→SFT精調→RL校準”的流水線,或開發動態熵-獎勵聯合優化目標,平衡模型自信度與外部對齊要求,解決RL后接EM導致的“對齊稅”問題。





,簡單嘗試一下。)



)

)


)

)

![[Protobuf]常見數據類型以及使用注意事項](http://pic.xiahunao.cn/[Protobuf]常見數據類型以及使用注意事項)
