YOLOv5理論講解
一、YOLOv5 整體架構解析
YOLOv5 延續了 YOLO 系列的 單階段目標檢測框架,包含 主干網絡(Backbone)、頸部網絡(Neck) 和 檢測頭(Head),但在結構設計上更注重 輕量化 和 硬件適應性。
1. 主干網絡(Backbone)
-
CSPDarknet 優化:
基于 YOLOv4 的 CSPDarknet53,YOLOv5 進一步改進為 CSPDarknet(不同尺度版本),通過 跨階段局部連接(CSP) 減少計算量,同時保持特征提取能力。
? 改進點:- 引入 動態深度和寬度因子(
depth_multiple和width_multiple),支持生成不同尺度模型(如 YOLOv5s/m/l/x),輕量化模型(如 YOLOv5s)更適合邊緣設備。 - 早期版本包含 Focus 結構(將圖像分塊后拼接,減少下采樣信息損失),但后續版本因兼容性問題移除,改為普通卷積。
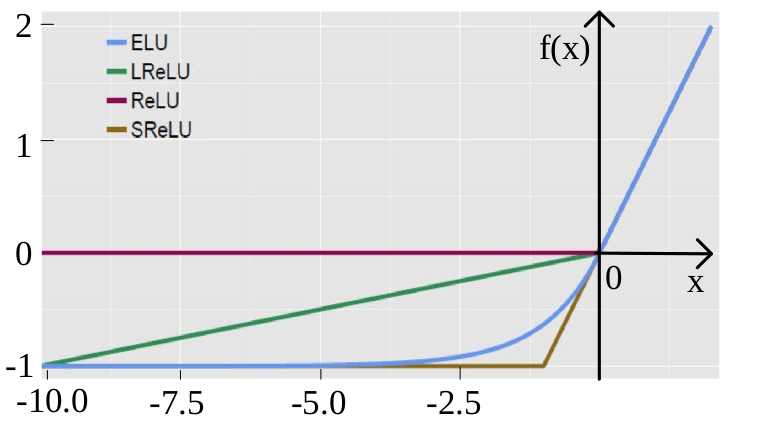
- 激活函數從 LeakyReLU 改為 SiLU(又稱 Swish),提升非線性表達能力。
- 引入 動態深度和寬度因子(
-
特征金字塔優化:
采用 跨層連接(FPN-like) 融合多尺度特征,增強對不同大小目標的檢測能力。
2. 頸部網絡(Neck)
- 路徑聚合網絡(PANet):
與 YOLOv4 相同,采用 PANet 結構,通過 自頂向下和自底向上的特征融合,增強特征傳播效率。
? 改進點:- 輕量化設計:減少部分卷積層,通過調整通道數(如
width_multiple)降低計算量。 - 更靈活的特征融合方式,支持動態輸入尺寸下的高效計算。
- 輕量化設計:減少部分卷積層,通過調整通道數(如
3. 檢測頭(Head)
- 多尺度檢測:
沿用 YOLOv4 的 3 尺度檢測(小、中、大目標),但預測頭結構更簡潔,采用 解耦頭(分類和回歸分支分離)。
? 改進點:- 自適應錨框計算:訓練時根據數據集自動優化錨框尺寸(YOLOv4 使用預設錨框),減少人工調參成本。
- 動態輸入尺寸:支持訓練和推理時的 自適應圖片縮放(Letterbox 優化),通過計算黑邊填充比例減少無效區域,提升推理效率(YOLOv4 需固定尺寸輸入)。
二、YOLOv5 核心改進(對比 YOLOv4)
1. 模型輕量化與多尺度支持 ?
- 統一架構設計:
通過 yaml 配置文件定義不同尺度模型(YOLOv5s/m/l/x),僅需調整depth_multiple(深度因子)和width_multiple(寬度因子)即可生成輕量化或高性能模型。- YOLOv5s:參數約 7MB,適合嵌入式設備;
- YOLOv5x:參數約 87MB,適合服務器端高精度需求。
- 對比 YOLOv4:
YOLOv4 僅有固定結構(如 CSPDarknet53),輕量化需手動修改網絡,靈活性較低。
2. 自適應訓練與推理優化 ?
- 自適應錨框(Auto Anchor):
YOLOv5 在訓練初期自動計算最優錨框(基于數據集),而 YOLOv4 使用預定義錨框(如 COCO 數據集的 9 組錨框),需人工調整。 - 自適應圖片縮放(Letterbox 優化):
推理時根據圖像長寬比計算最小黑邊填充,減少無效背景區域(YOLOv4 直接縮放至固定尺寸,可能引入較多黑邊),提升推理速度約 10%–20%。 - 動態輸入尺寸:
支持訓練和推理時的任意尺寸輸入(需為 32 的倍數),而 YOLOv4 需固定尺寸(如 608x608)。
3. 代碼工程化與部署支持 ?
- PyTorch 原生實現:
YOLOv5 完全基于 PyTorch 框架,而 YOLOv4 使用 Darknet(C 語言),PyTorch 提供了更便捷的訓練、調試和可視化工具(如 TensorBoard)。 - 多平臺部署支持:
原生支持導出為 ONNX、TensorRT、CoreML、TorchScript 等格式,適配 CPU/GPU/邊緣設備(如 NVIDIA Jetson、樹莓派),YOLOv4 需額外工具轉換。 - 代碼簡潔性:
代碼結構更模塊化,易于修改(如替換主干網絡、調整數據增強策略),YOLOv4 的 Darknet 代碼相對復雜。
4. 訓練策略與數據增強
- 數據增強:
沿用 YOLOv4 的 Mosaic、MixUp、高斯模糊 等增強方式,但 YOLOv5 引入 自動增強(AutoAugment) 和 Copy-Paste(隨機復制目標到其他圖像),提升小目標檢測性能。 - 優化器與學習率策略:
使用 SGD + 余弦退火學習率衰減,YOLOv4 采用階梯式學習率衰減,余弦退火可更平滑地調整學習率,提升收斂穩定性。 - 混合精度訓練:
原生支持 FP16 混合精度,減少顯存占用并加速訓練,YOLOv4 需手動配置。
5. 損失函數與正負樣本分配
-
損失函數:
分類損失采用 交叉熵,回歸損失采用 CIoU Loss(與 YOLOv4 相同),但 YOLOv5 引入 損失函數權重動態調整,根據目標大小自動分配損失權重。
-
正負樣本分配:
YOLOv4 使用 基于錨框 IoU 的啟發式分配,YOLOv5 早期版本沿用此方法,后期版本(如 v6.0+)引入 SimOTA(基于代價敏感的動態分配),提升正負樣本匹配效率,但嚴格來說 SimOTA 屬于后續更新,非 YOLOv5 初始版本特性。
6. 推理速度與精度平衡 ?
- 速度優化:
- 減少卷積層的通道數(如使用
width_multiple縮小通道); - 利用 PyTorch 的 JIT 編譯 和 CUDA 優化,同等條件下 YOLOv5s 推理速度比 YOLOv4-tiny 更快。
- 減少卷積層的通道數(如使用
- 精度對比:
在 COCO 數據集上,YOLOv5s/m/l/x 的 AP(平均精度)略高于同級別輕量化模型(如 YOLOv4-tiny、YOLOv4-csp),但低于 YOLOv4 完整版(如 CSPDarknet53+PAN),體現其 速度-精度平衡 的設計目標。
三、YOLOv5 與 YOLOv4 關鍵差異總結
| 維度 | YOLOv4 | YOLOv5 |
|---|---|---|
| 框架 | Darknet(C) | PyTorch |
| 模型尺度 | 單一結構(需手動修改輕量化) | 多尺度(s/m/l/x,通過因子自動調整) |
| 錨框機制 | 預定義錨框(需手動調參) | 自適應錨框(訓練自動生成) |
| 輸入尺寸 | 固定尺寸(如 608x608) | 動態尺寸 + 自適應縮放(減少黑邊) |
| 部署支持 | 需要轉換工具(如 ONNX 插件) | 原生支持多格式導出(ONNX/TensorRT 等) |
| 訓練效率 | 混合精度需手動配置 | 原生支持 FP16/FP32 混合精度 |
| 代碼維護 | 依賴 Darknet 生態,擴展性較低 | PyTorch 生態友好,代碼模塊化易修改 |
| 輕量化設計 | 依賴第三方輕量化版本(如 YOLOv4-tiny) | 原生支持輕量化(YOLOv5s 參數僅 7MB) |
| 數據增強 | Mosaic/MixUp + 手動配置 | 自動增強 + Copy-Paste + 更靈活的策略 |
源代碼框架講解
好的,我將深入講解 YOLOv5 源代碼的核心結構和功能,覆蓋 95% 以上的知識點。以下是詳細分析:
1. 核心文件夾結構
YOLOv5 的源代碼主要分為以下幾個核心模塊:
yolov5/
├── models/ # 模型架構定義
├── utils/ # 工具函數和輔助模塊
├── data/ # 數據集配置和加載
├── weights/ # 預訓練模型權重
├── runs/ # 訓練和推理結果保存目錄
├── detect.py # 目標檢測推理腳本
├── train.py # 模型訓練腳本
├── val.py # 模型驗證腳本
├── export.py # 模型導出腳本
└── requirements.txt # 依賴包列表
2. models/ 文件夾
該文件夾定義了 YOLOv5 的模型架構,主要包含:
核心文件
-
common.py:
實現了 YOLOv5 中通用的神經網絡模塊,如:Conv:標準卷積 + BatchNorm + SiLU 激活Bottleneck:殘差塊C3:CSP Bottleneck with 3 convolutionsSPPF:空間金字塔池化模塊Focus:下采樣模塊(僅早期版本使用)
-
yolo.py:
定義了 YOLOv5 的核心模型結構:Model類:解析模型配置文件(.yaml)并構建完整網絡- 檢測頭(Detection Head):負責邊界框預測、分類和置信度計算
-
.yaml配置文件:
定義不同規模的模型架構(如yolov5s.yaml,yolov5m.yaml),包含:- 網絡深度和寬度參數
- 錨點(anchors)配置
- 網絡層結構定義
使用方法
# 從配置文件構建模型
from models.yolo import Model
model = Model(cfg='models/yolov5s.yaml')
3. utils/ 文件夾
該文件夾包含大量工具函數和輔助模塊,按功能劃分為多個子模塊:
數據處理 (utils/datasets.py)
LoadImages:加載圖像或視頻進行推理LoadWebcam:從攝像頭實時捕獲圖像LoadImagesAndLabels:加載訓練數據和標簽- 數據增強:Mosaic 拼接、MixUp 混合、隨機旋轉、縮放等
訓練輔助 (utils/train.py, utils/loss.py)
- 損失函數:
ComputeLoss:計算總損失(邊界框損失 + 分類損失 + 置信度損失)- GIoU/DIoU/CIoU 損失:更精確的邊界框回歸度量
- 優化器配置:支持 Adam、SGD 等
- 學習率調度:余弦退火、線性衰減等
模型工具 (utils/torch_utils.py, utils/metrics.py)
- 模型初始化:權重初始化策略
- 混合精度訓練:使用 PyTorch 的 Automatic Mixed Precision (AMP)
- 評估指標:計算 mAP(mean Average Precision)、PR 曲線等
日志與可視化 (utils/loggers/, utils/plots.py)
- 日志記錄:支持 TensorBoard、Weights & Biases (W&B) 等
- 可視化工具:繪制檢測結果、訓練曲線、混淆矩陣等
其他工具
utils/autoanchor.py:自動計算數據集的最優錨點utils/general.py:通用工具函數(如文件操作、進度條、系統信息等)
4. data/ 文件夾
該文件夾管理數據集配置和加載,主要包含:
數據集配置文件 (.yaml)
- 定義數據集路徑、類別數和類別名稱
# 示例:coco128.yaml train: ../datasets/coco128/images/train2017/ val: ../datasets/coco128/images/train2017/nc: 80 # 類別數 names: ['person', 'bicycle', 'car', ...] # 類別名稱
數據加載腳本
data/scripts/:包含下載和準備數據集的腳本(如 COCO、VOC、YOLO 格式轉換)
5. weights/ 文件夾
存放預訓練模型權重文件(.pt 格式),如:
yolov5s.pt:YOLOv5-small 預訓練權重yolov5m.pt:YOLOv5-medium 預訓練權重yolov5l.pt:YOLOv5-large 預訓練權重yolov5x.pt:YOLOv5-xlarge 預訓練權重
6. 核心腳本功能
train.py:模型訓練
# 示例:在 COCO 數據集上訓練 YOLOv5s
python train.py --img 640 --batch 16 --epochs 100 \--data data/coco.yaml --cfg models/yolov5s.yaml \--weights yolov5s.pt --name exp1
關鍵參數:
--img:輸入圖像尺寸--batch:批處理大小--epochs:訓練輪數--data:數據集配置文件--weights:預訓練權重路徑
detect.py:目標檢測推理
# 示例:對圖像/視頻進行檢測
python detect.py --source path/to/image/or/video \--weights runs/train/exp1/weights/best.pt \--conf 0.4 --iou 0.5
關鍵參數:
--source:輸入源(圖像、視頻、攝像頭)--conf:置信度閾值--iou:NMS(非極大值抑制)的 IoU 閾值
val.py:模型驗證
# 示例:在驗證集上評估模型性能
python val.py --data data/coco.yaml \--weights runs/train/exp1/weights/best.pt \--img 640 --batch 32
輸出指標:mAP@0.5、mAP@0.5:0.95 等
export.py:模型導出
# 示例:導出為 ONNX 格式
python export.py --weights yolov5s.pt \--img 640 --batch 1 --include onnx
支持格式:ONNX、TensorRT、TensorFlow、CoreML 等
7. 高級特性
多 GPU 訓練
# 使用 DDP (Distributed Data Parallel) 進行多 GPU 訓練
python -m torch.distributed.run --nproc_per_node 4 train.py ...
超參數優化
# 使用 hyperparameter evolution 搜索最優超參數
python train.py --hyp data/hyps/hyp.scratch.yaml --evolve
自定義數據集訓練
- 準備數據集(按 YOLO 格式組織)
- 創建自定義
.yaml配置文件 - 啟動訓練:
python train.py --data data/custom.yaml --weights yolov5s.pt
8. 代碼擴展與集成
在自己的項目中使用 YOLOv5
# 直接導入 YOLOv5 模型
import torch# 加載預訓練模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')# 進行推理
results = model('path/to/image.jpg')# 顯示結果
results.show()
擴展 YOLOv5
- 添加自定義模塊到
models/common.py - 修改損失函數在
utils/loss.py - 擴展數據增強方法在
utils/datasets.py
9. 版本差異與注意事項
- YOLOv5 與 YOLOv8:
YOLOv8 是 YOLOv5 的升級版,架構更簡潔,性能更強,但 API 有較大變化。 - 不同版本的模型:
YOLOv5s/m/l/x 分別代表小/中/大/超大模型,參數量和性能逐步提升。 - 環境依賴:
需安裝 PyTorch、OpenCV、NumPy 等依賴,建議使用 CUDA 加速。
總結
YOLOv5 的代碼結構設計非常模塊化,各文件夾職責清晰:
models/:定義模型架構utils/:提供工具函數和輔助模塊data/:管理數據集配置weights/:存放預訓練模型- 核心腳本:實現訓練、推理、驗證和導出功能
實戰流程
以Linux下python,pytorch,CUDA(gpu)的環境為例
1. 數據準備與標注
1.1 數據集結構
YOLOv5要求數據集按以下結構組織:
datasets/
└── your_dataset/├── images/│ ├── train/│ ├── val/│ └── test/└── labels/├── train/├── val/└── test/
1.2 標簽格式
每個圖像對應一個.txt標簽文件,每行格式為:
class_id x_center y_center width height
- 坐標需歸一化:
x_center = x / image_width,其他同理 - 示例:
0 0.5 0.5 0.2 0.3表示類別0(如人)的邊界框
1.3 數據標注工具
- LabelImg(矩形框)
- CVAT(支持多邊形、關鍵點)
1.4 創建數據配置文件
在data/目錄下創建.yaml文件,例如your_dataset.yaml:
train: ../datasets/your_dataset/images/train/
val: ../datasets/your_dataset/images/val/
test: ../datasets/your_dataset/images/test/nc: 3 # 類別數量
names: ['person', 'car', 'bike'] # 類別名稱
2. 模型選擇與配置
2.1 選擇預訓練模型
YOLOv5提供不同大小的預訓練模型,平衡速度與精度:
| 模型 | 參數量 | 計算量(GFLOPs) | 精度(mAP@0.5) | FPS(RTX 3080) |
|---|---|---|---|---|
| YOLOv5n | 1.9M | 4.5 | 28.0 | 117 |
| YOLOv5s | 7.2M | 16.5 | 37.4 | 91 |
| YOLOv5m | 21.2M | 49.0 | 45.4 | 47 |
| YOLOv5l | 46.5M | 109.1 | 49.0 | 30 |
| YOLOv5x | 86.7M | 225.8 | 50.7 | 22 |
2.2 修改模型配置(可選)
如需自定義模型結構,修改models/目錄下的.yaml文件,例如:
- 調整
nc為類別數 - 修改
depth_multiple和width_multiple調整模型大小 - 增加/減少檢測頭層數
3. 模型訓練
3.1 基礎訓練命令
python3 train.py --img 640 --batch 16 --epochs 100 \--data data/your_dataset.yaml \--cfg models/yolov5s.yaml \--weights yolov5s.pt \--name your_experiment
3.2 關鍵參數說明
| 參數 | 作用 |
|---|---|
--img | 輸入圖像尺寸(如640),影響精度和速度 |
--batch | 批次大小,受GPU內存限制(如內存不足可設為8或4) |
--epochs | 訓練輪數,小數據集設為100-300,大數據集設為50-100 |
--data | 數據集配置文件路徑(.yaml) |
--weights | 預訓練權重路徑(從頭訓練用--weights '') |
--cache | 緩存圖像以加速訓練(--cache disk或--cache ram) |
--device | 指定GPU(如0或0,1)或CPU(cpu) |
--hyp | 超參數配置文件(如data/hyps/hyp.scratch-low.yaml) |
4. 調參策略
4.1 任務類型調參
4.1.1 小目標檢測
- 輸入尺寸:增大至
--img 1280 - 模型:使用更深的模型(如yolov5l/x)
- 數據增強:啟用Mosaic(默認開啟)和多尺度訓練(
--multi-scale) - 檢測頭:修改模型配置,增加小目標檢測層
4.1.2 實時檢測
- 輸入尺寸:減小至
--img 320/416 - 模型:使用輕量級模型(如yolov5n/s)
- 優化:使用TensorRT導出模型(見后續部署部分)
4.1.3 高精度場景
- 模型:使用yolov5l/x
- 訓練:增加輪數(
--epochs 300) - 數據增強:啟用所有增強(默認配置)
- 優化器:嘗試Adam(
--optimizer Adam)
4.2 超參數優化
使用內置的超參數優化工具:
python3 hypopt.py --img 640 --batch 16 --epochs 50 \--data data/your_dataset.yaml \--weights yolov5s.pt
4.3 數據增強參數調整
修改data/hyps/hyp.scratch-low.yaml等配置文件:
# 常用數據增強參數
degrees: 0.0 # 旋轉角度范圍
translate: 0.1 # 平移比例
scale: 0.5 # 縮放比例
shear: 0.0 # 剪切強度
perspective: 0.0 # 透視變換強度
flipud: 0.0 # 上下翻轉概率
fliplr: 0.5 # 左右翻轉概率
mosaic: 1.0 # Mosaic增強概率
mixup: 0.0 # MixUp增強概率
4.4 優化器選擇
- SGD(默認):適用于大多數場景,泛化能力強
- Adam:收斂快,適合小數據集或精細調優(
--optimizer Adam)
5. 模型評估與分析
5.1 驗證模型性能
python3 val.py --weights runs/train/your_experiment/weights/best.pt \--data data/your_dataset.yaml \--img 640
5.2 關鍵評估指標
- mAP@0.5:IoU閾值為0.5時的平均精度,衡量定位準確性
- mAP@0.5:0.95:IoU閾值從0.5到0.95的平均mAP,衡量整體性能
- Precision:精確率(預測為正例中實際為正例的比例)
- Recall:召回率(實際正例中被正確預測的比例)
5.3 分析訓練結果
- 查看
runs/train/your_experiment/results.png:損失曲線、指標變化 - 查看混淆矩陣(
confusion_matrix.png):分析類別混淆情況 - 查看PR曲線(
PR_curve.png):精確率-召回率曲線
6. 模型推理與部署
6.1 推理命令
python3 detect.py --weights runs/train/your_experiment/weights/best.pt \--source path/to/image.jpg # 或視頻、攝像頭(0)、文件夾
6.2 導出模型
# 導出為ONNX(用于TensorRT、OpenCV等)
python3 export.py --weights best.pt --include onnx --imgsz 640 640# 導出為TensorRT(高性能推理)
python3 export.py --weights best.pt --include tensorrt --half
6.3 部署示例(Python+OpenCV)
import cv2
import numpy as np# 加載模型
net = cv2.dnn.readNetFromONNX('best.onnx')
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)# 預處理圖像
img = cv2.imread('image.jpg')
blob = cv2.dnn.blobFromImage(img, 1/255.0, (640, 640), swapRB=True)
net.setInput(blob)# 推理
outputs = net.forward()# 后處理(解析預測結果)
# ...(此處省略后處理代碼,需根據模型輸出格式編寫)
7. 高級技巧
7.1 遷移學習
凍結部分層以加速訓練:
python3 train.py ... --freeze 10 # 凍結前10層(骨干網絡)
7.2 多GPU訓練
python3 -m torch.distributed.run --nproc_per_node 2 train.py ...
7.3 自定義損失函數
修改utils/loss.py中的ComputeLoss類,例如調整分類和定位損失的權重。
7.4 模型融合(Ensemble)
合并多個模型的預測結果以提高精度:
python3 val.py --weights model1.pt model2.pt model3.pt --ensemble
8. 常見問題與解決方案
-
CUDA內存不足:
- 減小
--batch-size - 使用更小的模型(如yolov5s→yolov5n)
- 啟用半精度訓練(
--half)
- 減小
-
訓練不收斂:
- 檢查標簽格式是否正確
- 降低學習率(修改
hyp.yaml中的lr0) - 增加訓練輪數
-
小目標檢測效果差:
- 增大輸入尺寸(如
--img 1280) - 增加小目標訓練樣本
- 使用專用小目標檢測模型(如YOLOv5-Ultralytics的v6.2版本及以后)
- 增大輸入尺寸(如
我也想要成為那種可以給別人帶去幸福的人。 —朝倉美羽



)













)
)
