目錄
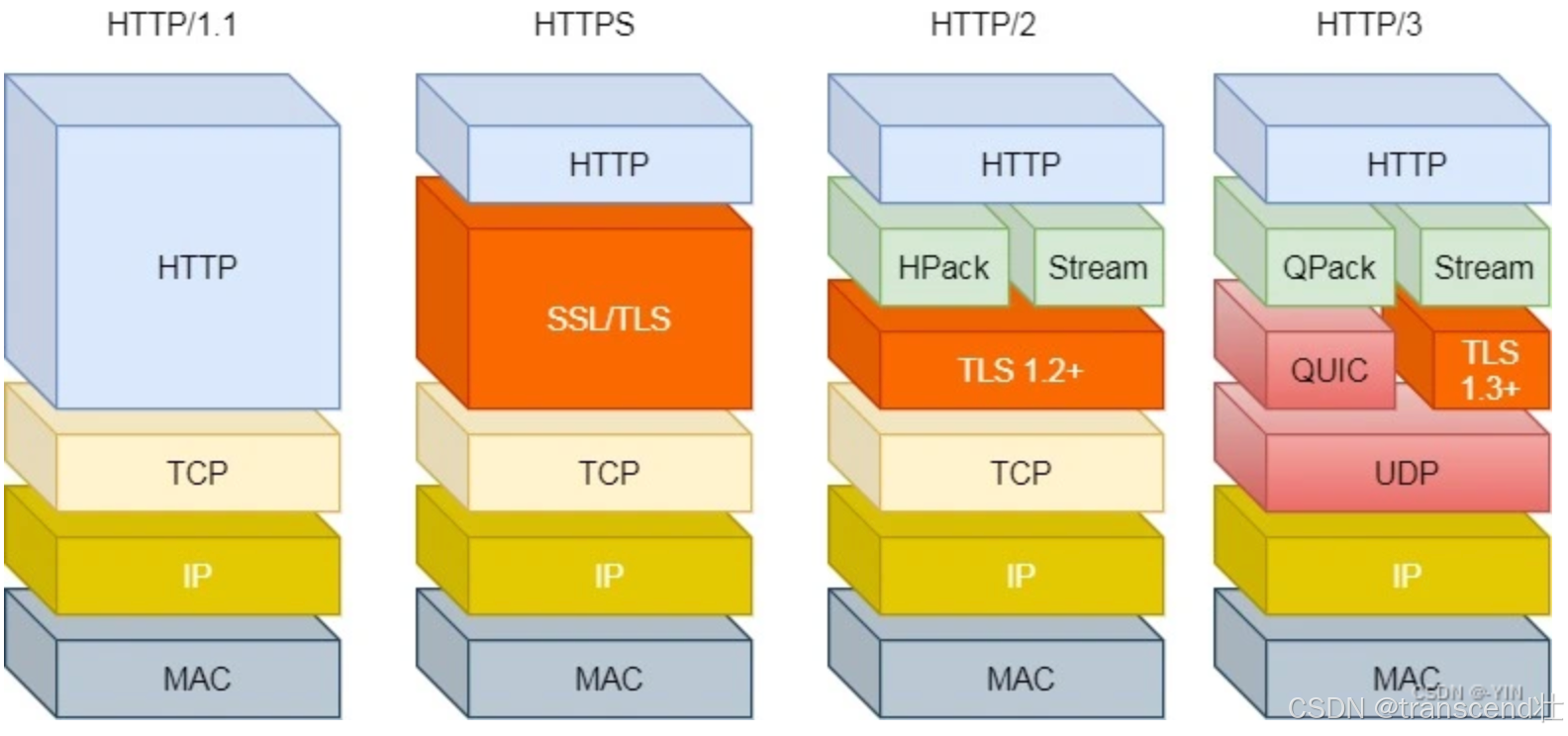
HTTP協議層次圖
HTTP/0.9
例子
HTTP/1.0
Content-Type 字段
Content-Encoding 字段
例子
1.0版本存在的問題:短鏈接、隊頭阻塞
HTTP/1.1
Host字段
Content-Length 字段
分塊傳輸編碼
1.1版本存在的問題
HTTP/2
HTTP/2數據傳輸
2版本存在的問題
HTTP/3
隊頭阻塞問題總結
HTTP1.1斷點續傳
如果服務器支持斷點續傳
如果服務器不支持斷點續傳
斷點續傳的應用
HTTP Keep-Alive 機制
HTTP協議層次圖
HTTP/0.9
例子
GET /index.html響應:
<html><body>Hello World</body>
</html>HTTP/1.0
- 增加POST、HEAD等請求方法。
- 引入頭部信息。除了要傳輸的數據之外,每次通信都包含頭信息,用來描述一些信息。
- 傳輸數據格式不再局限于HTML格式。根據Content-Type可以支持多種數據格式,不僅可以用來傳輸文字,還可以傳輸圖像、音頻、視頻等二進制文件。
- 引入cache緩存機制。
- 引入狀態碼。
Content-Type 字段
關于字符的編碼,1.0版規定,頭信息必須是 ASCII 碼,后面的數據可以是任何格式。因此,服務器回應的時候,必須告訴客戶端,數據是什么格式,這就是Content-Type字段的作用。
下面是一些常見的Content-Type字段的值。
text/plain
text/html
text/css
image/jpeg
image/png
image/svg+xml
audio/mp4
video/mp4
application/javascript
application/pdf
application/zip
application/atom+xml
Content-Encoding 字段
由于發送的數據可以是任何格式,因此可以把數據壓縮后再發送。Content-Encoding字段說明數據的壓縮方法。
Content-Encoding:?gzip
Content-Encoding:?compress
Content-Encoding:?deflate
客戶端在請求時,用Accept-Encoding字段說明自己可以接受哪些壓縮方法:
Accept-Encoding:?gzip,?deflate
例子
請求:
GET / HTTP/1.0
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5)
Accept: */*客戶端請求的時候,可以使用Accept字段聲明自己可以接受哪些數據格式。Accept:?*/*:表明戶端可以接受任何格式的數據。
響應:
HTTP/1.0 200 OK
Content-Type: text/plain
Content-Length: 137582
Expires: Thu, 05 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 5 August 1996 15:55:28 GMT
Server: Apache 0.84
<html><body>Hello World</body>
</html>1.0版本存在的問題:短鏈接、隊頭阻塞
- 短鏈接:每個TCP連接只能發送一個請求,當服務器響應后就會關閉這個TCP連接,下一次請求需要再次建立TCP連接。每次建立、釋放TCP連接需要三次握手四次揮手,所以當網頁需要發送多個HTTP請求時,就會造成性能問題。
- 隊頭阻塞:下一個請求必須在前一個請求響應到達之前才能發送,若前一個請求響應一直不到達,那下一個請求就不發送,同樣后面的請求也被阻塞了。
HTTP/1.1
- 新增了請求方式PUT、PATCH、OPTIONS、DELETE等。
- 增強緩存策略:如Etag、If-Unmodified-Since、If-Match、If-None-Match等可供選擇的了緩存頭來控制緩存策略。
- 客戶端請求的頭信息新增了Host字段,用來指定服務器的域名。
- 引入持久連接(即長連接) :可以通過設置connection: keep-alive來保持HTTP連接不斷開,避免頻繁的建立、釋放連接。如果客戶端和服務器端發現對方一段時間沒有活動,就可以主動關閉連接。不過,規范的做法是,客戶端在最后一個請求是,發送connection: false來明確要求服務器關閉TCP連接。(1.1默認有長鏈接,1.0需要手動的添加connection: keep-alive才能保持長鏈接)
- 加入管道機制:基于HTTP/1.1的長鏈接,在同一個TCP連接里,允許多個請求同時發送。但是還是有問題:假設客戶端需要請求兩個資源。以前的做法是,在同一個TCP連接里,先發送A請求,然后等待服務做出響應,收到后再發出B請求。管道機制允許瀏覽器同時發出A請求和B請求,但服務器還是按照請求順序,先響應A請求,再響應B請求,所以這并不是真正意義上的并行傳輸。現階段的瀏覽器廠商實現并行傳輸,采用的做法是允許打開多個TCP會話,這就是我們所熟悉的瀏覽器對同一個域下能夠并行加載6~8個資源的限制。(所以說HTTP/1.1 管道解決了請求的隊頭阻塞,但是沒有解決響應的隊頭阻塞)
- HTTP/1.1支持文件斷點續傳:RANGE:bytes,HTTP/1.0每次傳送文件都是從文件頭開始,即0字節處開始。RANGE:bytes=XXXX表示要求服務器從文件XXXX字節處開始傳送,斷點續傳。返回碼是206(Partial Content)
- Content-length字段:聲明本次回應的數據長度。
- 分塊傳輸編碼:使用Content-Length字段的前提條件是服務器發送響應之前,必須知道響應的數據長度。對于一些很耗時的動態操作來說,這意味著,服務器要等到所有操作完成才能發送數據,顯然這樣的效率不高。更好的處理方法是,產生一塊數據,就發送一塊,采用“流模式”(stream),取代“緩存模式”(buffer)。因此,1.1版本規定可以不使用Content-Length字段,而使用“分塊傳輸編碼”,只要請求或回應的頭信息有Transfer-Encoding字段,就表明響應將由數量未定的數據塊組成。
Host字段
- HTTP/1.0 的問題:在 HTTP/1.0 中,請求只包含路徑(如?GET /index.html),不包含域名信息。如果一臺服務器托管了?example.com?和?test.com,服務器無法區分請求是發給哪個域名的。
- HTTP/1.1 的解決方案:強制要求客戶端在請求頭中添加?Host?字段,明確指定目標域名:服務器會根據?Host?字段將請求路由到對應的網站。如下:
GET /index.html HTTP/1.1
Host: example.comContent-Length 字段
一個TCP連接現在可以傳送多個回應,勢必就要有一種機制,區分數據包是屬于哪一個回應的。這就是Content-length字段的作用,聲明本次回應的數據長度。
Content-Length: 3495上面代碼告訴瀏覽器,本次回應的長度是3495個字節,后面的字節就屬于下一個回應了。
在1.0版中,Content-Length字段不是必需的,因為瀏覽器發現服務器關閉了TCP連接,就表明收到的數據包已經全了
分塊傳輸編碼
Transfer-Encoding: chunked // 分塊傳輸每一個非空的數據塊之前,會有一個16進制的數值,表示這個塊的長度。最后是一個大小為0的塊,就表示本次回應的數據發送完畢:
HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked25
This is the data in the first chunk1C
and this is the second one3
con8
sequence01.1版本存在的問題
HTTP/2
- 二進制分幀:HTTP/1.1版本的頭信息必須是文本(ASCII編碼),數據體可以是文本,也可以是二進制,HTTP/2則是一個徹底的二進制協議,頭信息和數據體都是二進制,并且統稱為“幀”(frame):頭信息幀和數據幀。如下圖:
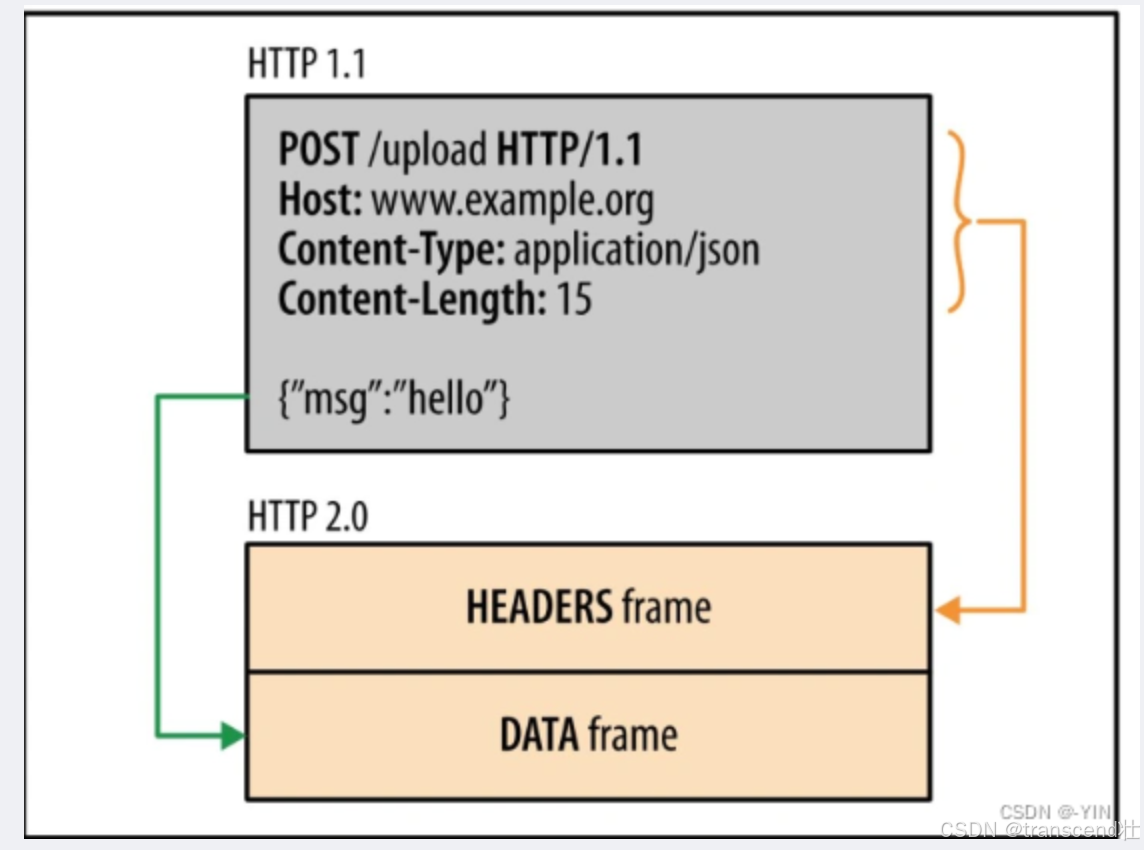
- 多路復用:HTTP/2版本會復用TCP連接。在一個連接里,客戶端和服務器端都可以同時發送多個請求或響應,而且不用按照順序一一對應,這樣就避免了“隊頭阻塞”。(多路復用是通過?流Streams和?二進制幀Frames實現的,而非直接復用原始 HTTP 消息)
- 數據流:因為 HTTP/2 的數據包是不按順序發送的,同一個連接里面連續的數據包,可能屬于不同的回應。因此,必須要對數據包做標記,指出它屬于哪個回應。
HTTP/2 將每個請求或回應的所有數據包,稱為一個數據流(stream)。每個數據流都有一個獨一無二的編號。數據包發送的時候,都必須標記數據流ID,用來區分它屬于哪個數據流。另外還規定,客戶端發出的數據流,ID一律為奇數,服務器發出的,ID為偶數。數據流發送到一半的時候,客戶端和服務器都可以發送信號(RST_STREAM幀),取消這個數據流。1.1版取消數據流的唯一方法,就是關閉TCP連接。這就是說,HTTP/2 可以取消某一次請求,同時保證TCP連接還打開著,可以被其他請求使用。客戶端還可以指定數據流的優先級。優先級越高,服務器就會越早回應。
- 頭信息壓縮:HTTP 協議不帶有狀態,每次請求都必須附上所有信息。所以,請求的很多字段都是重復的,比如Cookie和User Agent,一模一樣的內容,每次請求都必須附帶,這會浪費很多帶寬,也影響速度。HTTP/2 對這一點做了優化,引入了頭信息壓縮機制(header compression)。一方面,頭信息使用gzip或compress壓縮后再發送;另一方面,客戶端和服務器同時維護一張頭信息表,所有字段都會存入這個表,生成一個索引號,以后就不發送同樣字段了,只發送索引號,這樣就提高速度了。
- 服務器推送:HTTP/2允許服務器不需要客戶端的請求就可以主動向客戶端發送資源。
常見場景是客戶端請求一個網頁,這個網頁里面包含很多靜態資源。正常情況下,客戶端必須收到網頁后,解析HTML源碼,發現有靜態資源,再發出靜態資源請求。其實,服務器可以預期到客戶端請求網頁后,很可能會再請求靜態資源,所以就主動把這些靜態資源隨著網頁一起發給客戶端了。
- 流量控制: HTTP/2不同于HTTP/1.1的只要客戶端可以處理,服務端就會盡可能快地發送數據。HTTP/2提供了客戶端調整傳輸速度的能力(服務端也可以),在每一個數據幀中告訴對方,發送方想要接受多少字節的數據。
HTTP/2數據傳輸
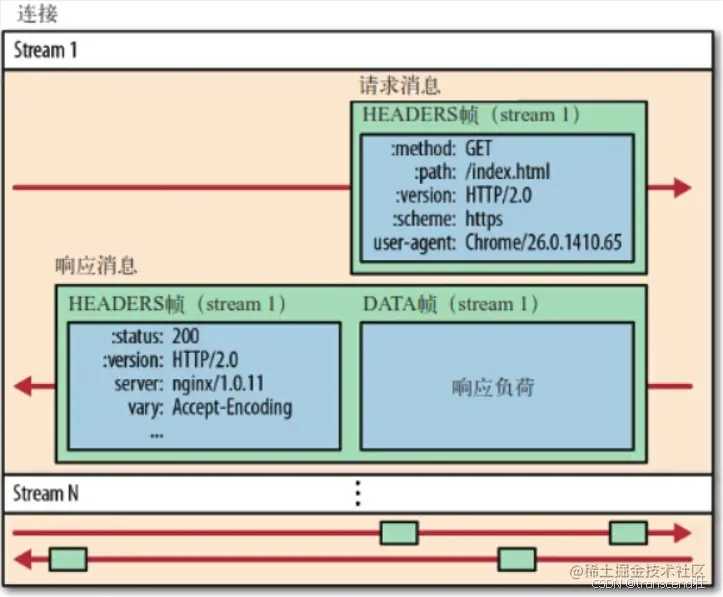
從圖中可見,所有的HTTP/2通信都在一個TCP連接上完成,這個連接可以承載任意數量的雙向數據流。
每個數據流以消息的形式發送,而消息由一個或多個幀組成。這些幀可以亂序發送,然后再根據每個幀頭部的stream id標識符來重新組裝。
舉個例子,每個請求是一個數據流,數據流以消息的方式發送,而消息又分為多個幀,幀頭部記錄著stream id用來標識當前幀所屬的數據流,不同屬的幀可以在連接中混雜在一起。接收方可以根據stream id將幀再歸屬到各自不同的請求中去。
另外,多路復用(連接共享)可能會導致關鍵請求被阻塞。HTTP/2里每個數據流都可以設置優先級和依賴,優先級高的數據流會被服務器優先處理和返回給客戶端,數據流還可以依賴其他的子數據流。
2版本存在的問題
隊頭阻塞:
HTTP/2 的多路復用依賴于一條 TCP 連接,而 TCP 是面向字節流的協議,要求數據按順序到達,如果某個TCP 包丟失,那么整個連接會等待重傳,導致所有流被阻塞。
HTTP/3
- TCP 隊頭阻塞:HTTP/2 的?多路復用?在 TCP 上運行時,若一個包丟失,所有流(Stream)都會被阻塞。HTTP/3 使用?QUIC(基于 UDP),每個流獨立傳輸,丟包只影響當前流,其他流不受影響。
HTTP/3?只使用一個 UDP 連接,但在這個連接內部通過?QUIC 協議?實現了多路復用,而不是建立多個 UDP 連接。在單個 UDP 連接內創建多個Streams流,每個 HTTP 請求/響應對應一個獨立的 QUIC 流(使用Stream ID標識),這些流共享同一個 UDP 連接,但彼此獨立,所以一個流丟包不會阻塞其他流傳輸消息。
- 減少握手延遲HTTP/2 需要?TCP 三次握手 + TLS 握手(1~2 RTT),而 HTTP/3 的 QUIC?直接內置 TLS 1.3,支持:
- 1-RTT 首次連接(比 HTTP/2 更快)。
- 0-RTT 恢復連接(對之前訪問過的服務器可立即發送數據)。

隊頭阻塞問題總結
- 持久連接(Keep-Alive):默認復用同一個 TCP 連接,避免了頻繁建立連接的開銷。
- 管道化(Pipelining):允許客戶端在未收到響應時發送多個請求(理論上的優化)。(響應必須按請求順序返回:如果第一個請求的響應延遲(例如服務器處理慢或網絡延遲),后續已發送的請求響應會被阻塞,即使它們已經準備就緒。)
- HTTP/2:通過多路復用(Multiplexing)在單個連接上并行傳輸多個請求/響應,徹底解決了應用層的隊頭阻塞。但若底層 TCP 丟包,仍會因重傳導致所有流阻塞(TCP 層隊頭阻塞)。
- HTTP/3:基于 QUIC 協議(UDP 實現),解決了 TCP 層的隊頭阻塞,每個流獨立傳輸,丟包不影響其他流。
HTTP1.1斷點續傳
如果服務器支持斷點續傳
客戶端發起帶 Range 頭的請求:客戶端在請求中指定需要下載的字節范圍(如從第 1000 字節開始)。
GET /large-file.zip HTTP/1.1
Host: example.com
Range: bytes=1000-2000- Range: bytes=start-end:請求文件的特定字節范圍(end 可省略,表示直到文件末尾)。
- 例如:
- Range: bytes=0-499 → 請求前 500 字節
- Range: bytes=500- → 請求從第 500 字節到文件末尾
- Range: bytes=500-999,2000-2499 → 請求多個范圍(較少使用)
如果服務器支持斷點續傳,會返回 206 狀態碼,并標明返回的數據范圍:
HTTP/1.1 206 Partial Content
Content-Range: bytes 1000-2000/5000
Content-Length: 1001
Content-Type: application/zip[文件數據...]- Content-Range: bytes start-end/total:
- start-end:實際返回的字節范圍
- total:文件的完整大小(如果未知,可以用 * 代替)
- Content-Length:返回的數據長度(這里是 2000 - 1000 + 1 = 1001 字節)
客戶端繼續下載剩余部分:客戶端可以繼續發送新的 Range 請求,直到文件下載完成。
注意:如果客戶端請求的字節范圍不合法,比如超出了請求文件的大小,那么服務端就會返回416狀態碼。StatusRequestedRangeNotSatisfiable(請求的狀態范圍不滿足) = 416
如果服務器不支持斷點續傳
如果服務器不支持 Range 請求,會直接返回 200 OK 和整個文件:
HTTP/1.1 200 OK
Content-Length: 5000
Content-Type: application/zip[完整的文件數據...]客戶端需要檢查狀態碼是 206 還是 200 來判斷是否支持斷點續傳。
StatusPartialContent(狀態部分內容)= 206
斷點續傳的應用
- 大文件下載(如 ISO 鏡像、視頻文件):下載工具(如迅雷、IDM)可以分塊下載,提高速度。如果下載中斷,可以從中斷的位置繼續下載,而不是重新開始。
- 視頻/音頻流(HTTP Streaming):播放器可以只請求視頻的某一段(如 Range: bytes=0-1023),實現邊下邊播。
- 斷網恢復:瀏覽器或下載管理器可以記錄已下載的字節位置,恢復時發送 Range 請求繼續下載。
HTTP Keep-Alive 機制
- 傳統HTTP(無Keep-Alive):每個HTTP請求完成后立即關閉TCP連接,下次請求需重新建立連接(三次握手)。
請求1 → 響應1 → 關閉連接
請求2 → 響應2 → 關閉連接- 啟用Keep-Alive后:多個HTTP請求復用同一個TCP連接,減少握手和揮手次數。
請求1 → 響應1 → 請求2 → 響應2 → ... → 關閉連接- HTTP/1.1:默認啟用Keep-Alive(無需顯式聲明),除非請求頭包含 Connection: close。
- HTTP/1.0:需顯式在請求頭中添加 Connection: keep-alive。
GET /index.html HTTP/1.1
Host: example.com
Connection: keep-alive # 顯式啟用(HTTP/1.0需此字段,HTTP/1.1可省略)參考:
HTTP 協議的歷史演變和設計思路?
稀土掘金:HTTP協議各個版本之間的區別
身份提供方(IdP)、iam選型)

)












流)
(完整實現流程))


