00 引言
? 在構建高效、可擴展的網絡應用時,理解HTTP服務器的底層原理是一項必不可少的技能。現代瀏覽器與移動應用大量依賴HTTP協議完成前后端通信,而這一過程的背后,是由網絡套接字驅動的請求解析、響應構建、數據傳輸等一系列機制所支撐。為了深入掌握這些關鍵技術,本項目以“自主實習HTTP服務器”為目標,期望能夠帶你從零實現一個能夠處理基本GET和POST請求的多線程HTTP服務端程序。
? 整個實現過程中,我們不僅會涉及C/C++語言的系統級編程,還將涵蓋網絡套接字、線程管理、CGI通信、單例模式以及HTTP協議本身的各項細節。如果你希望通過實戰方式扎實掌握這些底層知識,那么這個項目將是一次非常適合入門和拓展的實踐機會。
項目源代碼地址:https://github.com/Kutbas/LightHttp#
01 理解網絡協議與HTTP通信機制
01.1 網絡協議棧與數據傳輸流程
? 在網絡通信中,協議棧是實現數據可靠傳輸的關鍵。它采用分層的結構設計,每一層各司其職,共同完成數據的發送與接收。最上層的應用層負責具體業務的數據處理;傳輸層則保證數據的可靠傳輸;網絡層解決數據應發送到哪兒的問題;鏈路層則是數據真正被發送和接收的地方。
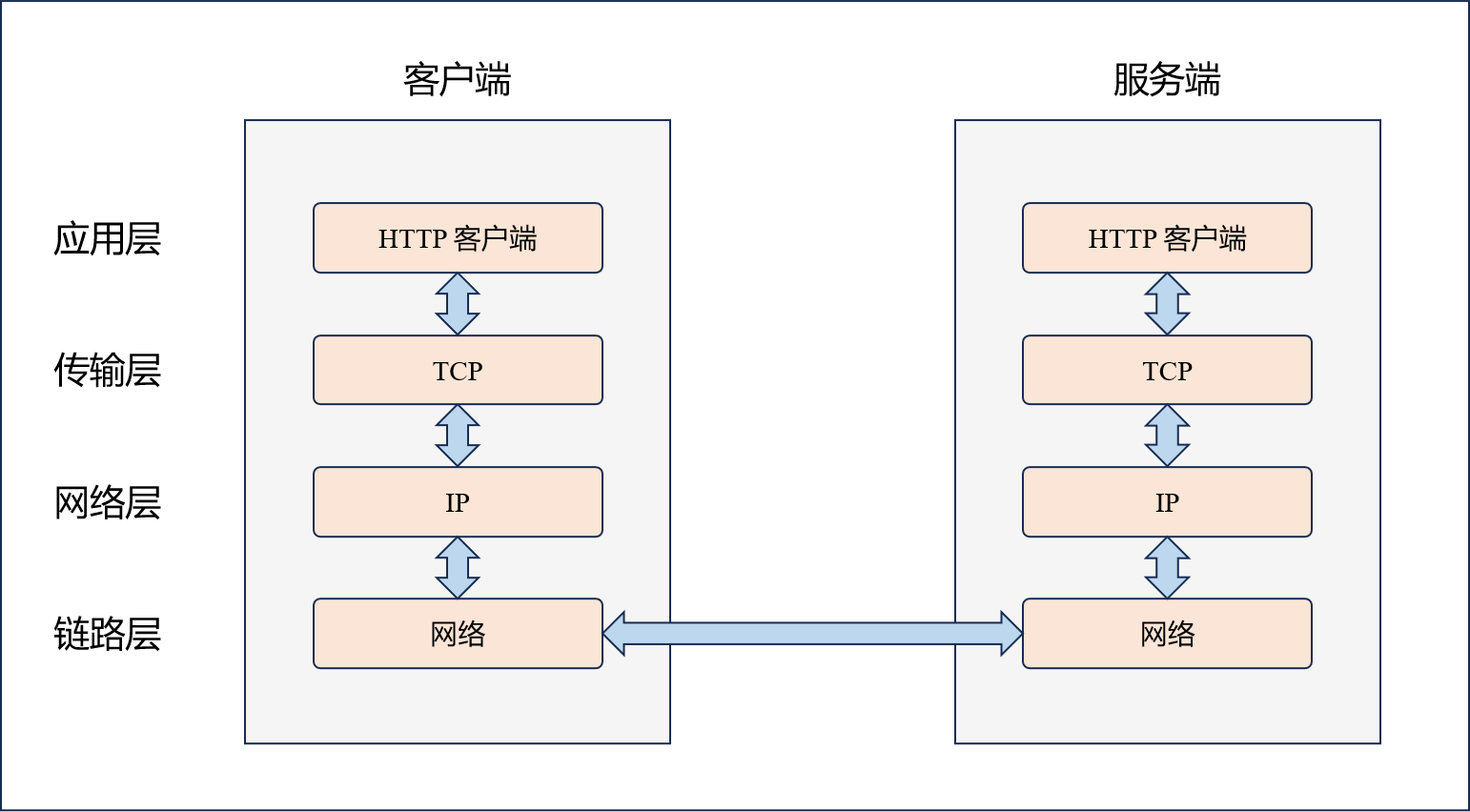
? 當我們發送數據時,它會從應用層開始,逐層向下封裝,每一層都會附加特定的報頭信息,形成完整的數據包。而接收端正好相反,數據自底向上依次被拆解,每一層剝離自己的報頭信息,直到還原出原始數據。這種過程稱為“封裝與分用”。
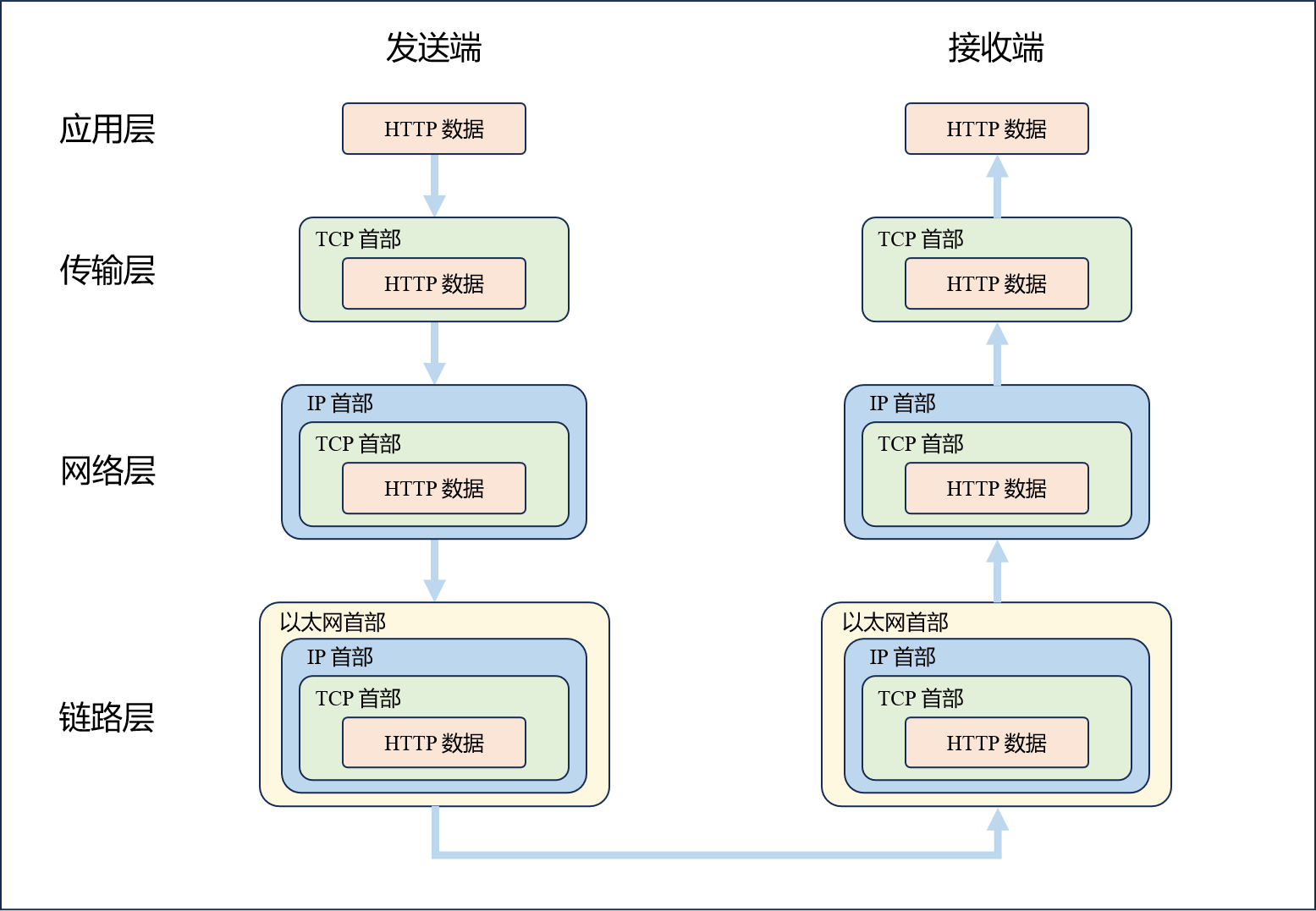
? 在我們的項目中,核心任務是處理客戶端發來的HTTP請求:提取請求中的報頭內容,分析請求數據,處理后再加上響應報頭,返回給客戶端。雖然我們說“接收請求”和“發送響應”,但實際上傳輸過程涉及到協議棧中下三層的配合。我們工作的重點位于應用層,和傳輸層直接進行交互,而數據的真正發送由系統完成。同層之間的通信在邏輯上也可以看作是“直接”的。
01.2 HTTP協議概覽
? 關于HTTP協議,它作為Web通信的基礎,具備幾個重要特點:
- 它遵循客戶端-服務器模式,通信總是一端請求,另一端響應;
- 協議設計簡單,通信快速;
- 靈活性強,可傳輸任意類型的數據,通過Content-Type字段來標識;
- 是無連接的,即每次請求處理完畢后,連接就會關閉;
- 也是無狀態的,服務器不會自動記住前一次請求的狀態。
? 不過,HTTP無狀態的特性也帶來了問題,比如無法識別用戶是否登錄。因此,引入了Cookie技術來維護用戶狀態,再通過Session機制增強安全性。這也是現代網站實現用戶認證的重要基礎。
? 值得一提的是,雖然早期的HTTP/1.0每次請求都斷開連接,但后來HTTP/1.1支持了“長連接”(Keep-Alive),減少了重復連接帶來的資源消耗。不過我們當前項目實現的是1.0版本,因此不涉及這一特性。
? 繼續來看HTTP的相關格式和用法。URL(統一資源定位符)是我們瀏覽網頁時常見的網址,它用于標識和定位互聯網上的資源。URL通常包括協議名(如http://)、服務器地址(如域名)、端口號、資源路徑、參數等多個部分。通常情況下,端口號和部分字段可以省略,瀏覽器會自動補全。

? 更廣義地說,URL只是URI(統一資源標識符)的一種,它不僅標識資源,還能說明如何訪問資源。URN則是通過名字標識資源的另一種URI。例如,mailto:example@example.com 就是一個URN。簡而言之,URL和URN是URI的兩個子集。
? 關于URI,還有“絕對”和“相對”之分。像URL那樣能獨立標識資源的,是絕對URI;而依賴環境的資源路徑(如瀏覽器中的請求路徑),就是相對URI。
? 在通信過程中,HTTP請求和響應的數據格式是規范化的:
- 請求包括請求行(方法+路徑+版本)、請求頭、空行和請求體;
- 響應包括狀態行(版本+狀態碼+描述)、響應頭、空行和響應體。
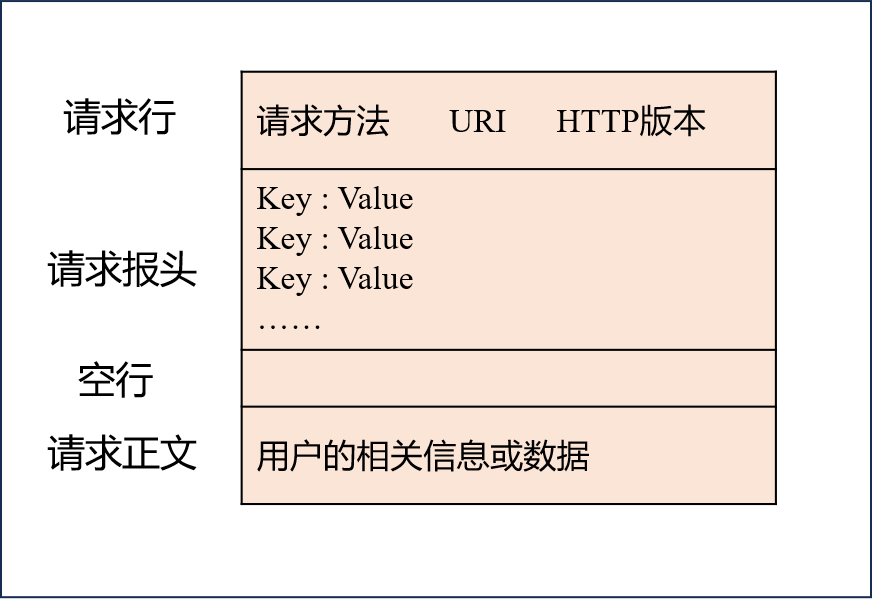
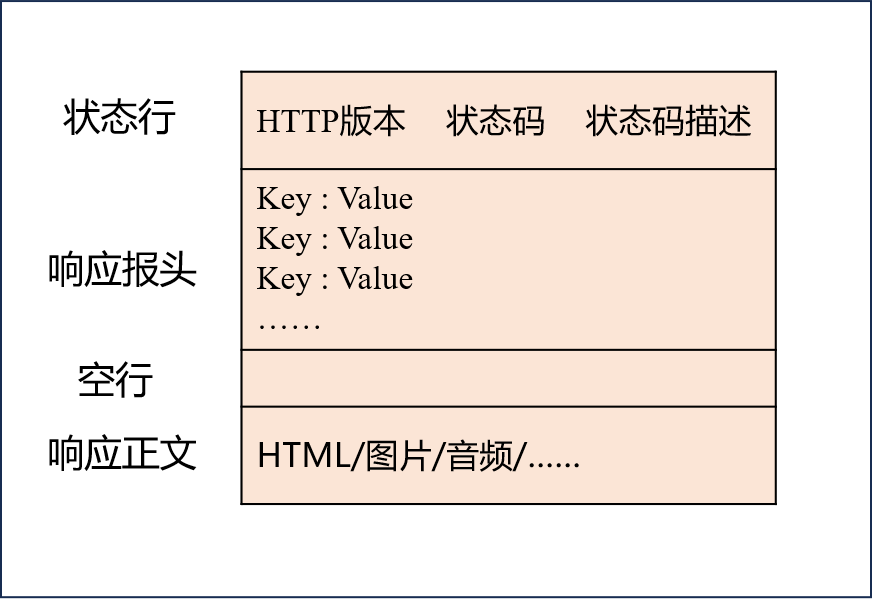
? 常用的HTTP方法有:
- GET:請求資源(常用于查詢);
- POST:提交數據(比如表單);
- PUT/DELETE:對資源進行修改或刪除;
- 還有像HEAD、OPTIONS、TRACE等用于特定場景。
? GET和POST最常見,區別在于參數傳遞方式:GET通過URL,參數長度有限;POST通過請求體,能傳更多數據。
? 狀態碼是HTTP的重要反饋機制,分為五類:
- 1xx:處理中;
- 2xx:成功(如200 OK);
- 3xx:重定向(如301、302);
- 4xx:客戶端錯誤(如404 Not Found);
- 5xx:服務器錯誤(如500 Internal Server Error)。
? 這些狀態碼幫助開發者快速判斷請求處理的結果和原因。
? 最后是HTTP頭部字段,它們承載了請求和響應的各種元信息。常見的包括:
- Content-Type:指明數據類型;
- Content-Length:正文長度;
- Host:請求的主機地址;
- User-Agent:客戶端信息;
- Referer:來源頁面;
- Location:配合重定向使用;
- Cookie:維持客戶端狀態。
? 理解以上內容,是開發Web服務或HTTP應用的基礎,也為我們處理網絡請求、調試響應提供了清晰的結構框架。
02 CGI 機制介紹
02.1 CGI 的概念
? 在了解了網絡協議和HTTP通信機制之后,我們可以進一步探討瀏覽器與服務器之間是如何實現更復雜的數據交互的。日常上網時,我們不僅僅是打開網頁、瀏覽圖片,很多時候還會在網站上登錄、提交表單、上傳文件、搜索信息……這些操作背后,其實都涉及了服務器對用戶數據的接收與處理。
? 這就引出了**CGI(通用網關接口)**機制的作用。CGI就像是服務器和后臺程序之間溝通的橋梁,它定義了一種通用的數據交換方式,使得Web服務器可以將收到的數據轉交給外部程序進行處理,再將結果返回給用戶。特別是在處理用戶提交的信息時,CGI機制發揮著至關重要的作用。
? 所以現在我們需要知道的是,瀏覽器向服務器提交數據后,HTTP協議本身并不對這些數據進行處理,而是將它們交由上層的CGI程序來完成相應操作。CGI程序可以使用任何編程語言編寫,部署在服務器上,專門負責接收數據、處理請求,并將結果交回服務器,由服務器進一步構建響應返回給瀏覽器。
? 比如,用戶提交搜索關鍵詞,服務器接收到請求后會調用相應的CGI程序完成搜索工作,再將搜索結果反饋給瀏覽器,最終展示給用戶。整個過程中,HTTP協議僅作為中介,而實際業務邏輯是由CGI程序處理的。
02.1 服務器調用 CGI 程序的方式
? 為了實現CGI機制,服務器在收到需要處理的請求后,會通過創建子進程的方式調用對應的CGI程序。由于直接使用線程可能會影響主服務器進程的穩定性,因此通常做法是先用 fork 創建一個子進程,再由子進程調用 exec 執行CGI程序。這就要求我們提前建立好用于通信的管道,因為父進程需要向CGI程序發送數據,CGI程序也要把處理結果反饋回來。
? 考慮到 exec 調用會替換子進程的代碼和數據,但不會改變打開的文件描述符,我們可以將通信管道的讀寫端重定向到標準輸入輸出,這樣CGI程序無需感知底層管道的具體文件描述符,只需要通過標準輸入讀取數據,通過標準輸出返回結果。
? 根據不同的請求方法(如GET或POST),數據的傳遞方式也會有所不同。GET方法中的參數通過URL傳遞,通常會在程序替換前被放入環境變量,CGI程序通過讀取環境變量獲取參數。而POST方法的數據包含在請求正文中,需要由父進程寫入管道供CGI程序讀取,同時通過環境變量告知其數據長度和請求方法。
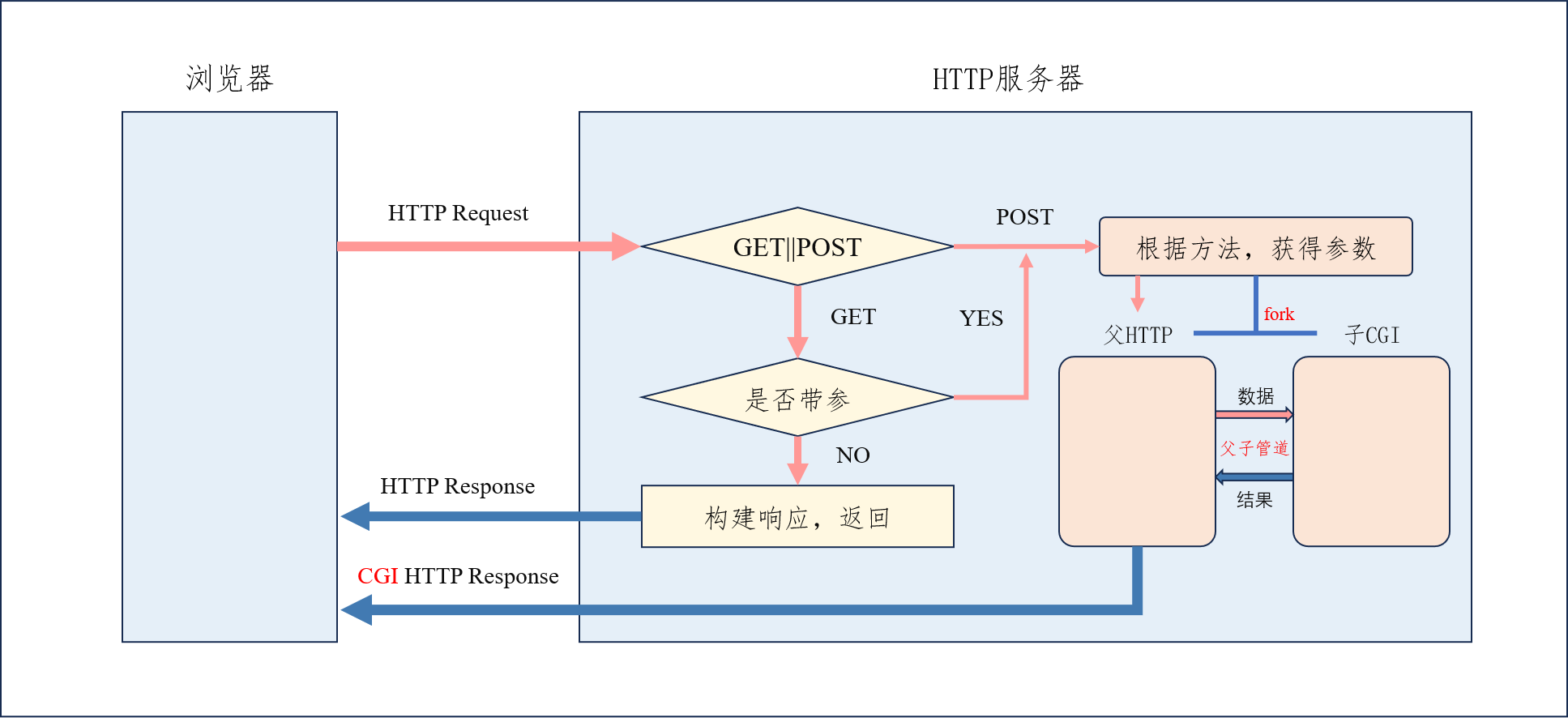
? 因此,CGI程序啟動后會先讀取環境變量確定當前請求的類型,再選擇從標準輸入或環境變量中讀取數據。處理完成后,結果寫入標準輸出返回服務器,再由服務器生成HTTP響應發送給客戶端。
? CGI機制的核心意義在于實現了業務邏輯與服務器邏輯的解耦。服務器專注于處理請求與響應,而具體的業務交由CGI程序負責。這種分工不僅提高了系統的靈活性,也使得CGI程序開發者無需了解HTTP服務器的內部實現,就可以通過標準輸入輸出與用戶進行數據交互,實現面向用戶的功能。
日志實現
? 在服務器運行過程中,會產生大量日志,用于記錄各類事件,幫助我們了解系統的運行狀態與排查問題。本項目中采用統一的日志格式,包含日志級別、時間戳、日志信息、出錯文件和具體行號。其中日志級別分為四種:INFO 表示系統正常運行;WARNING 意味著出現了風險但不影響繼續運行;ERROR 則說明發生錯誤但服務還能繼續;而 FATAL 是最嚴重的錯誤,通常會導致程序終止。
? 為了便于記錄,我們可以設計一個 Log 函數,它接收日志等級、描述信息、文件名和行號作為參數,并輸出標準格式的日志內容。時間戳使用 time(nullptr) 獲取,因此調用時無需額外傳參。
#pragma once
#include <iostream>
#include <string>
#include <ctime>#define INFO 1
#define WARNING 2
#define ERROR 3
#define FATAL 4void Log(std::string level, std::string message, std::string file_name, int line)
{std::cout << "[" << level << "]" << "[" << time(nullptr) << "]" << "[" << message << ']' << "[" << file_name << "]" << "[" << line << "]" << std::endl;
}
? 為了簡化使用,每次調用時我們不希望手動傳入 __FILE__ 和 __LINE__,于是使用宏來實現自動插入。定義宏 LOG(level, message) 后,預處理器會自動把調用的位置文件名和行號補充進 Log 函數中,使調用更加簡潔:
#define LOG(level, message) Log(#level, message, __FILE__, __LINE__)
? 此外,我們通過將日志級別如 INFO、WARNING 定義為宏,并用 # 操作符將其轉換為字符串,進一步簡化日志的調用方式。這樣,我們只需調用:
LOG(INFO, "This is a log");
? 就能自動輸出帶有時間戳、文件位置和日志級別的標準日志信息,既方便又清晰。需要日志時只管調用 LOG 宏,剩下的交給編譯器和預處理器處理即可。
TcpServer類實現
? 為了構建一個高效、可復用的 TCP 服務端,我們定義一個 TcpServer 類,并采用單例設計模式,從而確保在程序中只存在一個 TcpServer 實例。
頭文件及宏定義
? 首先引入所需頭文件和宏:
#pragma once
#include <iostream>
#include <cstdlib>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <pthread.h>
#include "Log.hpp"#define BACKLOG 5
類定義及構造函數
? 為了避免創建多個服務器實例,TcpServer 采用單例模式。構造函數被設為私有,拷貝構造和賦值操作也被禁止,確保外部無法復制對象。類中維護了一個靜態指針,首次調用 GetInstance 時,創建并初始化唯一的服務器實例。
class TcpServer
{
private:int port;int listen_sock;static TcpServer *svr;TcpServer(int _port): port(_port), listen_sock(-1){}TcpServer(const TcpServer &s) {}
? 為了線程安全,調用 GetInstance 時使用了雙重檢查鎖定機制,從而避免不必要的加鎖開銷。
public:static TcpServer *GetInstance(int port){static pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;if (nullptr == svr){pthread_mutex_lock(&lock);if (nullptr == svr){svr = new TcpServer(port);svr->InitServer();}pthread_mutex_unlock(&lock); }return svr;}? 初始化服務器時,會依次創建套接字、綁定地址和端口,并開始監聽客戶端連接。監聽套接字可通過 Sock() 函數獲取。當服務關閉時,監聽套接字也會被正確關閉以釋放資源。需要注意的是,如果服務器運行在云環境中,綁定 IP 時可直接使用 INADDR_ANY,讓系統自動選擇合適的網卡;由于它本質是0,也無需進行網絡字節序轉換。
void InitServer()
{Socket();Bind();Listen();LOG(INFO, "tcp_server init ... success");
}
// 創建套接字
void Socket()
{listen_sock = socket(AF_INET, SOCK_STREAM, 0);if (listen_sock < 0){LOG(FATAL, "socket error!");exit(1);}int opt = 1;setsockopt(listen_sock, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));LOG(INFO, "create socket ... success");
}
// 綁定端口
void Bind()
{struct sockaddr_in local;memset(&local, 0, sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(port);local.sin_addr.s_addr = INADDR_ANY;if (bind(listen_sock, (struct sockaddr *)&local, sizeof(local)) < 0){LOG(FATAL, "bind error!");exit(2);}LOG(INFO, "bind socket ... success");
}
// 監聽連接
void Listen()
{if (listen(listen_sock, BACKLOG) < 0){LOG(FATAL, "listen socket error!");exit(3);}LOG(INFO, "listen socket ... success");
}
類中的其他方法
// 提供對監聽套接字的訪問方法
int Sock()
{return listen_sock;
}
// 析構函數
~TcpServer()
{if (listen_sock >= 0)close(listen_sock);
}TcpServer *TcpServer::svr = nullptr; // 靜態成員必須在類外初始化
HttpServer及其相關類實現
HTTP服務器主體邏輯
? HTTP服務器的實現建立在 TCP 服務基礎之上。我們可以將其封裝為 HttpServer 類,在構造時指定端口號,調用 Loop() 函數即可啟動服務。運行時,首先從 TcpServer 獲取監聽套接字,然后循環等待新連接,每當有客戶端連入,就創建一個新的線程處理請求。
? 為了避免連接套接字在傳遞過程中被覆蓋,我們可以使用堆空間分配內存保存該套接字,并傳遞給新線程。新線程通過回調函數處理客戶端的 HTTP 請求,主線程繼續等待后續連接。每個線程在創建后立即被分離,這樣主線程無需等待它們結束,確保服務器持續運行。
? 這樣一來,主函數只需從命令行讀取端口號,創建 HttpServer 對象并調用 Loop() 即可啟動服務。
? 基于以上設計思路,下面是 HttpServer 類的完整實現:
#pragma once
#include <iostream>
#include <pthread.h>
#include <signal.h>
#include "TcpServer.hpp"
#include "Protocol.hpp"
#include "Log.hpp"
#include "Task.hpp"
#include "ThreadPool.hpp"#define PORT 8081class HttpServer
{
private:int port;bool stop;public:HttpServer(int _port = PORT): port(_port), stop(false){}void InitServer(){signal(SIGPIPE, SIG_IGN); // 信號 SIGPIPE 需要忽略,如果不忽略,在寫入時可能直接崩潰}void Loop(){TcpServer *tsvr = TcpServer::GetInstance(port);LOG(INFO, "loop begin");// int listen_sock = tcp_server->Sock();while (!stop){struct sockaddr_in peer;socklen_t len = sizeof(peer);int sock = accept(tsvr->Sock(), (struct sockaddr *)&peer, &len);if (sock < 0){continue;}LOG(INFO, "get a new link");Task task(sock);ThreadPool::GetInstance()->PushTask(task);}}~HttpServer(){}
};
HTTP 請求結構設計
? 在處理 HTTP 請求時,我們設計一個 HttpRequest 類用于封裝客戶端發送的請求。這個類包含請求的各個組成部分:請求行、請求頭、請求正文以及解析后的內容,如請求方法、資源路徑、參數等。還包含一個標志位,用于標識該請求是否需要 CGI 處理。
class HttpRequest
{
public:std::string request_line;std::vector<std::string> request_header;std::string blank;std::string request_body;// 解析完畢之后的結果std::string method;std::string uri;std::string version;std::unordered_map<std::string, std::string> header_kv;int content_length;std::string path;std::string suffix;std::string query_string;bool cgi;int size;public:HttpRequest(): content_length(0), cgi(false){}~HttpRequest(){}
};
HTTP 響應結構設計
? 與請求類似,HTTP 響應也封裝為一個 HttpResponse 類,分別記錄要發送的響應內容(狀態行、響應頭、空行、正文)以及生成這些內容所需的數據(如狀態碼、文件描述符、文件大小和后綴等)。
class HttpResponse
{
public:std::string status_line;std::vector<std::string> response_header;std::string blank;std::string response_body;int status_code;int fd;public:HttpResponse(): blank(LINE_END), status_code(OK), fd(-1){}~HttpResponse(){}
};
EndPoint類實現
EndPoint類結構設計
? 在處理客戶端請求時,我們通常將每一個“通信端”稱為一個 EndPoint。在這里,我們可以設計一個 EndPoint 類來表示服務端與客戶端建立連接后,對該連接的完整處理流程。這個類主要負責從客戶端讀取請求內容,處理請求并生成響應,最后將響應結果發送回客戶端。
? EndPoint 對象內部維護了三個核心成員:與客戶端通信的套接字 sock,用于封裝和存儲請求信息的 http_request 對象,以及構造響應所需的 http_response 對象。此外,還有一個布爾值 stop,用來標志在處理請求時是否中止流程。
? 在功能設計上,EndPoint 提供了一系列私有成員函數來分階段地完成整個請求處理流程。包括接收請求行 (RecvHttpRequestLine) 和請求頭 (RecvHttpRequestHeader),解析這些信息 (ParseHttpRequestLine, ParseHttpRequestHeader),如果請求包含正文,還會通過 IsNeedRecvHttpRequestBody 和 RecvHttpRequestBody 來讀取正文內容。之后根據請求類型判斷是否需要使用 CGI 腳本處理(ProcessCgi)還是處理靜態資源(ProcessNonCgi),同時也預留了錯誤處理接口(HandlerError)。構建響應則交由 BuildOkResponse 和 BuildHttpResponseHelper 實現。
? 類的公共接口主要包括三個方法:RecvHttpRequest() 負責發起請求的接收,BuildHttpResponse() 用于生成響應內容,SendHttpResponse() 則將結果返回給客戶端。當請求處理完畢后,在析構函數中會關閉通信套接字,釋放資源。
class EndPoint
{
private:int sock;HttpRequest http_request;HttpResponse http_response;bool stop;private:bool RecvHttpRequestLine();bool RecvHttpRequestHeader();void ParseHttpRequestLine();void ParseHttpRequestHeader();bool IsNeedRecvHttpRequestBody();bool RecvHttpRequestBody();int ProcessCgi();void HandlerError(std::string page);int ProcessNonCgi();void BuildOkResponse();void BuildHttpResponseHelper();public:EndPoint(int _sock): sock(_sock), stop(false){}bool IsStop();void RecvHttpRequest();void BuildHttpResponse();void SendHttpResponse();~EndPoint(){}
};
? EndPoint 的具體結構如上所示,相關函數的實現后續介紹。
CallBack類設計
? 為了配合服務器多線程模型,我們可以設計一個 CallBack 類,用作線程的回調處理邏輯。每當服務器收到一個新的連接,就會創建一個新線程來處理這個連接的請求。在這個線程中,我們會創建一個 EndPoint 實例,通過它依次完成接收請求、構建響應和發送響應的完整流程。
? 如果在調試模式下,線程也可以直接打印收到的原始HTTP請求內容,以便分析調試。而在正常運行模式中,則采用標準流程處理請求并記錄日志。請求處理完后,EndPoint 對象會被銷毀,自動關閉對應的客戶端連接,整個過程實現了高效且結構清晰的請求響應機制。
? 具體代碼如下所示:
class CallBack
{
public:CallBack() {}~CallBack() {}void operator()(int sock){HandlerRequest(sock);}void HandlerRequest(int sock){LOG(INFO, "handler request begin");// std::cout << "get a new link ..." << std::endl;#ifdef DEBUGchar buffer[4096];recv(sock, buffer, sizeof(buffer), 0);std::cout << "-----begin-----" << std::endl;std::cout << buffer << std::endl;std::cout << "-----end-----" << std::endl;
#elseEndPoint *ep = new EndPoint(sock);ep->RecvHttpRequest();if (!ep->IsStop()){LOG(INFO, "recv no error, start build and send");ep->BuildHttpResponse();ep->SendHttpResponse();}else{LOG(WARNING, "recv error, stop build and send!");}delete ep;
#endifLOG(INFO, "handler request end");}
};
讀取HTTP請求
? 在處理 HTTP 請求的過程中,我們通常將其拆解為若干個步驟來完成解析工作。前面我們提到,在服務端 EndPoint 類中,我們通過 RecvHttpRequest() 函數來整體控制請求的接收流程,依次完成請求行、請求報頭與空行的讀取,以及請求行和報頭的解析,最后根據情況讀取請求正文。
void RecvHttpRequest()
{if ((!RecvHttpRequestLine()) && (!RecvHttpRequestHeader())){ParseHttpRequestLine();ParseHttpRequestHeader();RecvHttpRequestBody();}
}
? 請求行的讀取通過 RecvHttpRequestLine() 方法實現,該方法從套接字中讀取一整行數據,并存入請求對象中的 request_line 字段。由于不同操作系統下行分隔符可能為 \r、\n 或 \r\n,因此不能使用標準的 getline() 或 gets(),而是通過自定義的 ReadLine 工具函數來逐字符讀取并判斷行尾符號,從而兼容所有常見的行分隔格式。該函數會將整行(包括換行符)存入用戶提供的字符串中,因此調用者需根據需要手動去除末尾換行符。
bool RecvHttpRequestLine()
{auto &line = http_request.request_line;if (Util::ReadLine(sock, line) > 0){line.resize(line.size() - 1);LOG(INFO, http_request.request_line);}else{stop = true;}return stop;
}
? 在讀取請求報頭和空行時,系統會不斷調用 ReadLine() 讀取每一行內容,直到遇到一個僅包含換行符的空行為止。讀取到的每行數據會先去除末尾的換行符,再存入請求對象中的 request_header 列表中,用于后續解析。
static int ReadLine(int sock, std::string &out)
{char ch = 'X';while (ch != '\n'){ssize_t s = recv(sock, &ch, 1, 0);if (s > 0){if (ch == '\r'){recv(sock, &ch, 1, MSG_PEEK);if (ch == '\n'){// 窺探成功,把 '\r\n' 轉換為 '\n'recv(sock, &ch, 1, 0);}elsech = '\n';}// 走到這里 ch 要么是普通字符要么是 \nout.push_back(ch);}else if (s == 0){return 0;}elsereturn -1;}return out.size();
}
? 接下來解析請求行。其主要任務是將請求行中用空格分隔的三個字段:請求方法、URI 和 HTTP 版本,依次提取出來并存入對應的字段中。解析時借助 std::stringstream 進行分割,同時通過 std::transform 將請求方法轉換為大寫,以便后續邏輯統一處理。
void ParseHttpRequestLine()
{auto &line = http_request.request_line;std::stringstream ss(line);ss >> http_request.method >> http_request.uri >> http_request.version;auto &method = http_request.method;std::transform(method.begin(), method.end(), method.begin(), ::toupper);
}
? 對于請求報頭的解析,程序逐行處理之前保存的報頭字符串,將每一行用 ": " 作為分隔符切割成鍵值對,存入 header_kv 哈希表中。為了提高代碼復用性,字符串切割邏輯被封裝在一個名為 CutString 的工具函數中,其利用 find 和 substr 方法實現。
#define SEP ": "void ParseHttpRequestHeader()
{std::string key, value;for (auto &iter : http_request.request_header){if (Util::CutString(iter, key, value, SEP)){http_request.header_kv.insert({key, value});}}
}static bool CutString(std::string &target, std::string &sub1_out, std::string &sub2_out, std::string sep)
{size_t pos = target.find(sep);if (pos != std::string::npos){sub1_out = target.substr(0, pos);sub2_out = target.substr(pos + sep.size());return true;}return false;
}
? 在讀取請求正文前,需要判斷當前請求是否包含正文。只有 POST 方法可能附帶正文,而且必須要在請求報頭中找到 Content-Length 字段,明確說明正文長度。如果滿足條件,則通過 recv 循環讀取指定長度的正文內容并存入 request_body。正文的長度會在之前解析過程中轉換為整型,并存入請求對象的 content_length 字段中。
bool IsNeedRecvHttpRequestBody()
{auto &method = http_request.method;if (method == "POST"){auto &header_kv = http_request.header_kv;auto iter = header_kv.find("Content-Length");if (iter != header_kv.end()){http_request.content_length = atoi(iter->second.c_str());return true;}}return false;
}bool RecvHttpRequestBody()
{if (IsNeedRecvHttpRequestBody()){int content_length = http_request.content_length;auto &body = http_request.request_body;char ch = 0;while (content_length){ssize_t s = recv(sock, &ch, 1, 0);if (s > 0){body.push_back(ch);content_length--;}else{stop = true;break;}}LOG(INFO, body);}return stop;
}
? 至此,從接收請求到解析完畢的整體流程就完成了,每一步都圍繞著數據結構的逐步填充和協議格式的嚴格解析展開,確保后續業務邏輯可以基于準確的請求信息進行處理。
處理HTTP請求
? 在處理HTTP請求時,服務器可能因為請求方式不合法、資源不存在或內部出錯等原因中斷操作。為了讓客戶端了解請求的處理結果,服務器通常會返回一個HTTP狀態碼。比如,請求成功時返回 200 OK,請求格式有誤時返回 400 Bad Request,資源未找到時返回 404 Not Found,服務器內部出錯時返回 500 Internal Server Error。
? 本項目中定義的狀態碼如下:
#define OK 200
#define NOT_FOUND 404
#define BAD_REQUEST 400
#define SERVER_ERROR 500
? 服務器處理HTTP請求時,首先會檢查請求方法是否合法。如果方法不是GET或POST,則視為無效請求,設置狀態碼為BAD_REQUEST并終止處理。
? 當請求方法是GET時,服務器會判斷URI中是否帶有查詢參數。如果URI包含?,說明用戶在URL中附帶了參數,此時需拆分URI,將?左邊作為請求路徑,右邊作為參數,同時標記當前請求需以CGI模式處理。如果沒有攜帶參數,直接將URI作為資源路徑。如果是POST請求,雖然URI直接表示資源路徑,但由于請求參數包含在請求體中,因此也需要以CGI方式處理。
? 接下來,服務器會將請求的路徑拼接到Web根目錄(項目中為wwwroot)后面。如果路徑以/結尾,說明客戶端請求的是某個目錄,這時默認返回該目錄下的首頁文件index.html。然后,通過stat系統調用檢查拼接后的路徑是否指向一個存在的資源。如果資源是一個目錄但URI沒有以/結尾,服務器會自動補全并嘗試加載目錄下的index.html。如果資源具有可執行權限,則視為CGI程序,設置cgi=true。同時,獲取的資源文件大小也會被保存下來,用于后續響應構建。
? 服務器還會根據文件名后綴判斷響應的內容類型。如果找不到后綴,默認使用.html。
? 最終,服務器根據cgi標志選擇執行普通靜態頁面處理(ProcessNonCgi())或CGI動態處理(ProcessCgi())。無論哪種方式,處理完成后都會調用BuildHttpResponseHelper()生成響應頭等信息。
? 下面是關鍵函數實現:
#define WEB_ROOT "wwwroot"
#define HOME_PAGE "index.html"void BuildHttpResponse()
{std::string _path;struct stat st;std::size_t found = 0;auto &code = http_response.status_code;if (http_request.method != "GET" && http_request.method != "POST") {LOG(WARNING, "method is not right");code = BAD_REQUEST;goto END;}if (http_request.method == "GET") {size_t pos = http_request.uri.find("?");if (pos != std::string::npos) {Util::CutString(http_request.uri, http_request.path, http_request.query_string, "?");http_request.cgi = true;} else {http_request.path = http_request.uri;}} else if (http_request.method == "POST") {http_request.cgi = true;http_request.path = http_request.uri;}_path = http_request.path;http_request.path = WEB_ROOT + _path;if (http_request.path.back() == '/') {http_request.path += HOME_PAGE;}if (stat(http_request.path.c_str(), &st) == 0) {if (S_ISDIR(st.st_mode)) {http_request.path += "/";http_request.path += HOME_PAGE;stat(http_request.path.c_str(), &st);}if ((st.st_mode & S_IXUSR) || (st.st_mode & S_IXGRP) || (st.st_mode & S_IXOTH)) {http_request.cgi = true;}http_request.size = st.st_size;} else {LOG(WARNING, http_request.path + " not found!");code = NOT_FOUND;goto END;}found = http_request.path.rfind(".");http_request.suffix = (found == std::string::npos) ? ".html" : http_request.path.substr(found);code = http_request.cgi ? ProcessCgi() : ProcessNonCgi();END:BuildHttpResponseHelper();
}
? 當請求需要CGI處理時,服務器會創建兩個匿名管道用于父子進程間通信:一個用于父進程讀取子進程的輸出(input管道),另一個用于父進程向子進程寫入數據(output管道)。接著,服務器創建子進程。父進程關閉不需要的管道端口,只保留用于通信的部分。子進程也會關閉無關端口,并將標準輸入輸出重定向到對應的管道上,使得后續替換為CGI程序后能夠從標準輸入讀取數據、向標準輸出寫入響應。
? CGI執行前,服務器會通過環境變量將請求信息傳遞給CGI程序,比如方法名、參數內容等。如果是POST請求,還會將請求正文寫入管道。CGI程序處理完畢后,父進程負責從管道中讀取其輸出,并將內容保存到HTTP響應體中。最后,等待子進程退出并清理資源。
? ProcessCgi()函數如下:
int ProcessCgi()
{LOG(INFO, "process cgi method");int code = OK;auto &method = http_request.method;auto &query_string = http_request.query_string;auto &body_text = http_request.request_body;auto &bin = http_request.path;int content_length = http_request.content_length;auto &response_body = http_response.response_body;std::string method_env = "METHOD=" + method;std::string query_string_env, content_length_env;int input[2], output[2];if (pipe(input) < 0 || pipe(output) < 0) {LOG(ERROR, "pipe error!");return SERVER_ERROR;}pid_t pid = fork();if (pid == 0) {close(input[0]);close(output[1]);putenv((char *)method_env.c_str());if (method == "GET") {query_string_env = "QUERY_STRING=" + query_string;putenv((char *)query_string_env.c_str());} else if (method == "POST") {content_length_env = "CONTENT_LENGTH=" + std::to_string(content_length);putenv((char *)content_length_env.c_str());}dup2(output[0], 0); // stdindup2(input[1], 1); // stdoutexecl(bin.c_str(), bin.c_str(), nullptr);exit(1);} else {close(input[1]);close(output[0]);if (method == "POST") {write(output[1], body_text.c_str(), body_text.size());}char ch = 0;while (read(input[0], &ch, 1) > 0) {response_body.push_back(ch);}waitpid(pid, nullptr, 0);close(input[0]);close(output[1]);}return code;
}
構建HTTP響應
? 構建 HTTP 響應的過程主要圍繞三個部分展開:狀態行、響應報頭和響應正文。首先,狀態行由 HTTP 版本、狀態碼以及對應的描述組成,并使用空格分隔。例如 "HTTP/1.0 200 OK\r\n"。在代碼中,這一行最終被保存到 http_response.status_line 中。接下來是響應報頭的構建,其內容將根據請求是否被正常處理而有所不同。
? 構建響應的核心函數 BuildHttpResponse 會判斷當前請求的類型是否為支持的 GET 或 POST 方法。如果請求非法(即不是 GET 或 POST),將返回 400 狀態碼。對于 GET 請求,還需檢查 URI 中是否帶有查詢字符串(是否包含 ?),以判斷是否為 CGI 請求。而 POST 請求則默認作為 CGI 處理。
void BuildHttpResponse()
{std::string _path;struct stat st;std::size_t found = 0;auto &code = http_response.status_code;if (http_request.method != "GET" && http_request.method != "POST"){// 非法請求LOG(WARNING, "method is not right");code = BAD_REQUEST;goto END;}if (http_request.method == "GET"){// GETsize_t pos = http_request.uri.find("?");if (pos != std::string::npos){Util::CutString(http_request.uri, http_request.path, http_request.query_string, "?");http_request.cgi = true;}else{http_request.path = http_request.uri;}}else if (http_request.method == "POST"){// POSThttp_request.cgi = true;http_request.path = http_request.uri;}else{// Nothing}// 拼接 Web 根目錄_path = http_request.path;http_request.path = WEB_ROOT;http_request.path += _path;// std::cout << "debug:" << http_request.path << std::endl;if (http_request.path[http_request.path.size() - 1] == '/'){// 如果請求的是根目錄,則返回首頁http_request.path += HOME_PAGE;}// std::cout << "debug:" << http_request.path << std::endl;// 檢查資源是否存在if (stat(http_request.path.c_str(), &st) == 0){// 資源存在if (S_ISDIR(st.st_mode)){// 請求的資源是個目錄,不允許http_request.path += "/";http_request.path += HOME_PAGE;stat(http_request.path.c_str(), &st);}if ((st.st_mode & S_IXUSR) || (st.st_mode & S_IXGRP) || (st.st_mode & S_IXOTH)){// 請求的資源是個可執行文件http_request.cgi = true;}http_request.size = st.st_size;}else{// 資源不存在LOG(WARNING, http_request.path + " not found!");code = NOT_FOUND;goto END;}found = http_request.path.rfind(".");if (found == std::string::npos)http_request.suffix = ".html";elsehttp_request.suffix = http_request.path.substr(found);// 構建響應if (http_request.cgi){code = ProcessCgi();}else{// 簡單的網頁返回code = ProcessNonCgi();}END:BuildHttpResponseHelper(); // 狀態行填充
}
? 無論是哪種請求,都會將 URI 拼接上服務器的 Web 根目錄,最終生成實際請求資源的完整路徑。如果路徑以 / 結尾,則默認返回首頁(如 index.html)。隨后通過 stat 判斷該資源是否存在,并據此設定響應的處理方式:如果是目錄,則自動拼接首頁;如果文件具備執行權限(可執行腳本),則按 CGI 請求處理;否則視為普通文件返回。
? 當資源存在時,代碼會根據文件擴展名來確定返回內容的類型(如 .html、.css 等),并設置 http_request.suffix。若找不到擴展名,則默認使用 .html。在此基礎上,如果為 CGI 請求,則調用 ProcessCgi() 處理動態生成內容;否則調用 ProcessNonCgi() 處理靜態文件。之后,統一調用 BuildHttpResponseHelper() 來構造狀態行。
? 狀態碼描述通過 Code2Desc 函數獲得,例如 200 對應 “OK”,404 對應 “Not Found”。這一部分也會被添加到狀態行中。
//根據狀態碼獲取狀態碼描述
static std::string Code2Desc(int code)
{std::string desc;switch (code){case 200:desc = "OK";break;case 404:desc = "Not Found";break;// 根據需要逐步添加default:break;}return desc;
}
? 當請求成功處理后,響應報頭中至少包含 Content-Type 和 Content-Length 兩項。前者由 Suffix2Desc 函數根據文件后綴確定 MIME 類型,后者則依據處理方式設定內容長度:若為 CGI,請求內容來自內存中的字符串;否則來自磁盤上的靜態文件,其長度已通過 stat 獲得。
//根據后綴獲取資源類型
static std::string Suffix2Desc(const std::string &suffix)
{static std::unordered_map<std::string, std::string> suffix2desc = {{".html", "text/html"},{".css", "text/css"},{".js", "application/javascript"},{".jpg", "application/x-jpg"},{".xml", "application/xml"},};auto iter = suffix2desc.find(suffix);if (iter != suffix2desc.end()){return iter->second;}return "text/html";
}
? 如果處理過程中發生錯誤(如資源不存在),則調用 HandlerError() 處理函數,為客戶端返回一個錯誤頁面。此時,響應類型統一為 text/html,文件大小通過 stat 獲取。同時需注意將 http_request.cgi 設置為 false,確保后續按非 CGI 模式處理響應正文。
void HandlerError(std::string page)
{http_request.cgi = false;// 返回錯誤碼對應的頁面http_response.fd = open(page.c_str(), O_RDONLY);if (http_response.fd > 0){struct stat st;stat(page.c_str(), &st);http_request.size = st.st_size;std::string line = "Content-Type: text/html";line += LINE_END;http_response.response_header.push_back(line);line = "Content-Length: ";line += std::to_string(st.st_size);line += LINE_END;http_response.response_header.push_back(line);}
}
發送HTTP響應
? 在實際發送 HTTP 響應時,首先通過 send 發送狀態行、所有響應報頭和空行。隨后,根據處理模式決定如何發送響應正文:如果是 CGI 請求,正文內容保存在內存中,直接使用 send 發送字符串;若為非 CGI 或錯誤處理情況,則響應文件已打開,使用 sendfile 直接從文件描述符發送文件內容,并在發送完畢后關閉該文件描述符。
void SendHttpResponse()
{send(sock, http_response.status_line.c_str(), http_response.status_line.size(), 0);for (auto iter : http_response.response_header)send(sock, iter.c_str(), iter.size(), 0);send(sock, http_response.blank.c_str(), http_response.blank.size(), 0);if (http_request.cgi){auto &response_body = http_response.response_body;size_t size = 0;size_t total = 0;const char *start = response_body.c_str();while (total < response_body.size() && (size = send(sock, start + total, response_body.size() - total, 0)) > 0)total += size;}else{sendfile(sock, http_response.fd, nullptr, http_request.size);close(http_response.fd);}
}
錯誤處理
? 為了讓服務器更加健壯,我們還需要完善其在處理請求過程中的差錯應對機制。盡管目前的服務器整體邏輯已基本跑通,但在運行過程中仍可能發生莫名崩潰。這些問題的根源在于對各種錯誤的處理還不夠完善,尤其是在請求的讀取、處理和響應發送這幾個關鍵階段。
邏輯錯誤
? 首先來看邏輯錯誤,這是服務器在解析和處理HTTP請求時可能遇到的問題,比如請求方法不合法、資源不存在或處理時發生內部錯誤等。對于這類錯誤,我們已經實現了相應機制,當檢測到這些問題時,服務器會向客戶端返回一個對應的錯誤頁面,提示用戶出現了問題。
讀取錯誤
? 而在邏輯錯誤之前,服務器首先要完成對請求的讀取,如果這個階段出現問題,比如 recv 讀取失敗或客戶端提前關閉了連接,我們稱之為讀取錯誤。一旦發生讀取錯誤,就意味著服務器連完整的HTTP請求都沒有獲取到,自然無法繼續處理或響應。我們可以在 EndPoint 類中增加一個布爾變量 stop,用于標記是否應中止當前處理流程。在讀取請求行、請求頭或請求正文的過程中,一旦發生錯誤,就將 stop 設為 true,后續流程會根據這個標志決定是否繼續執行。
bool RecvHttpRequestLine()
{auto &line = http_request.request_line;if (Util::ReadLine(sock, line) > 0){line.resize(line.size() - 1);LOG(INFO, http_request.request_line);}else{stop = true;}return stop;
}
? 為了配合 stop 的使用,讀取請求的每個子步驟,如 RecvHttpRequestLine、RecvHttpRequestHeader 和 RecvHttpRequestBody 函數都被設計成返回 bool 類型,表示是否出現錯誤。整個讀取過程采用邏輯與(&&)的短路策略,確保只有在前一個步驟成功的前提下才會繼續執行下一個步驟。此外,還提供了 IsStop() 接口,使外部線程可以判斷是否應該終止處理。
? 在調用 RecvHttpRequest() 后,工作線程會通過 IsStop() 檢查是否繼續執行后續流程。如果沒有讀取錯誤,則繼續調用 HandlerHttpRequest() 處理請求,調用 BuildHttpResponse() 構建響應,然后使用 SendHttpResponse() 發送響應。否則,服務器會直接跳過這些操作,關閉與客戶端的連接并清理資源。
寫入錯誤
? 除了讀取錯誤,寫入響應時也可能遇到問題。為了防止因寫入錯誤導致進程崩潰的問題,還需要處理 SIGPIPE 信號。當服務器向一個已關閉連接的客戶端發送數據時,會觸發該信號,而默認行為是終止進程。為避免這種情況,在 HTTP 服務器初始化時,通過 signal(SIGPIPE, SIG_IGN) 忽略這個信號,從而保障服務器的穩定性。
void InitServer()
{signal(SIGPIPE, SIG_IGN); // 信號 SIGPIPE 需要忽略,如果不忽略,在寫入時可能直接崩潰
}
引入線程池
? 為了提升服務器處理并發連接的效率,我們引入線程池機制,用以優化當前多線程模型中的諸多性能瓶頸。在傳統多線程服務器中,每當有客戶端連接時,服務器主線程就會新建一個線程負責該連接的處理,任務完成后再銷毀這個線程。這種方式簡單直觀,但隨著連接數的增加,會迅速消耗系統資源,線程數量一旦激增,不僅加重CPU線程調度的壓力,還會導致響應延遲顯著增加。
? 引入線程池后,我們不再為每個客戶端臨時創建線程,而是在服務器啟動時預先創建好一批工作線程,并維護一個任務隊列。服務器主線程在接收到客戶端連接后,只需將其封裝成一個任務對象并加入隊列即可,具體的處理由線程池中的空閑線程來執行。如果沒有任務,這些線程會進入休眠狀態,直到有新任務到來再被喚醒,從而大大減少了線程的頻繁創建與銷毀,提高了資源利用率和系統響應能力。
任務類設計
? 每一個客戶端請求被封裝為一個 Task 對象,其中包含一個套接字 sock 和一個回調函數 handler。當線程池中的線程從任務隊列中取出任務后,會通過 ProcessOn() 方法執行該回調函數,從而處理具體業務邏輯。
class Task {
private:int sock;CallBack handler;public:Task() {}Task(int _sock) : sock(_sock) {}void ProcessOn() {handler(sock);}
};
? 此處 CallBack 是一個可調用對象(仿函數),之前我們已經介紹過了。它重載了 () 運算符,實際內部調用的是 HandlerRequest 方法,這一方法完成了 HTTP 請求的接收、解析、響應等完整流程。
線程池實現
? 線程池采用單例設計模式,確保整個服務器生命周期內只有一個線程池實例。其核心組件包括任務隊列、線程數量、互斥鎖、條件變量等。線程池在初始化時便會創建多個線程,這些線程不斷循環執行 ThreadRoutine,從任務隊列中取任務處理。
? 說明幾個關鍵點:
ThreadRoutine是線程的主函數,它必須是靜態成員函數,因為pthread_create不支持普通成員函數指針。- 每個線程啟動后會不斷嘗試從任務隊列中取任務,如果隊列為空就進入等待狀態,直到被新任務喚醒。
- 所有對任務隊列的讀寫都需要加鎖,保證線程安全。
- 線程使用
pthread_detach分離,避免資源回收時產生阻塞。
class ThreadPool {
private:int num;bool stop;std::queue<Task> task_queue;pthread_mutex_t lock;pthread_cond_t cond;static ThreadPool* single_instance;ThreadPool(int _num = 6) : num(_num), stop(false) {pthread_mutex_init(&lock, nullptr);pthread_cond_init(&cond, nullptr);}ThreadPool(const ThreadPool&) = delete;public:static ThreadPool* GetInstance() {static pthread_mutex_t _mutex = PTHREAD_MUTEX_INITIALIZER;if (single_instance == nullptr) {pthread_mutex_lock(&_mutex);if (single_instance == nullptr) {single_instance = new ThreadPool();single_instance->InitThreadPool();}pthread_mutex_unlock(&_mutex);}return single_instance;}void PushTask(const Task& task) {pthread_mutex_lock(&lock);task_queue.push(task);pthread_mutex_unlock(&lock);pthread_cond_signal(&cond);}void PopTask(Task& task) {task = task_queue.front();task_queue.pop();}static void* ThreadRoutine(void* args) {ThreadPool* tp = static_cast<ThreadPool*>(args);while (true) {Task t;pthread_mutex_lock(&tp->lock);while (tp->task_queue.empty()) {pthread_cond_wait(&tp->cond, &tp->lock);}tp->PopTask(t);pthread_mutex_unlock(&tp->lock);t.ProcessOn();}return nullptr;}bool InitThreadPool() {for (int i = 0; i < num; ++i) {pthread_t tid;if (pthread_create(&tid, nullptr, ThreadRoutine, this) != 0) {LOG(FATAL, "create thread pool error!");return false;}pthread_detach(tid);LOG(INFO, "create thread pool success");}return true;}~ThreadPool() {pthread_mutex_destroy(&lock);pthread_cond_destroy(&cond);}
};ThreadPool* ThreadPool::single_instance = nullptr;
在服務器中使用線程池
? 在主服務器邏輯中,每當接收到一個新的連接,只需要將該連接封裝成一個 Task 對象,并調用線程池的 PushTask 方法即可,無需再手動創建線程。
class HttpServer {
private:int _port;public:void Loop() {TcpServer* tsvr = TcpServer::GetInstance(_port);int listen_sock = tsvr->Sock();while (true) {struct sockaddr_in peer;socklen_t len = sizeof(peer);int sock = accept(listen_sock, (struct sockaddr*)&peer, &len);if (sock < 0) continue;std::string client_ip = inet_ntoa(peer.sin_addr);int client_port = ntohs(peer.sin_port);LOG(INFO, "new client: " + client_ip + ":" + std::to_string(client_port));Task task(sock);ThreadPool::GetInstance()->PushTask(task);}}
};
測試
? 至此,我們的 HTTP 服務器核心功能已經全部實現。為了方便測試和展示,需要將所有可供訪問的資源文件集中放在一個名為 wwwroot 的目錄中。與此同時,將編譯生成的服務器可執行文件與該目錄放在同一級路徑下即可。由于當前服務器尚未對接任何實際的業務邏輯,所以 wwwroot 目錄下的頁面來自網上找的模板。
首頁展示與測試
? 
錯誤請求測試
? 可以看到網頁展示還有些問題,這可能源于模板內部的素材鏈接失效登原因導致,將來我們自己設計頁面的時候可以直接把資源放在服務器上避免這類情況的出現。
? 以上便是整個項目的所有內容,從底層的TCP通信支持到對HTTP協議的響應處理,再到CGI程序的數據處理與動態響應生成,均有所闡述。限于篇幅,一些細節沒有表達到位的地方,還請見諒。如果感興趣,可以去我的倉庫查看源碼,謝謝!
)






)




)






