緩存的合理使用確提升了系統的吞吐量和穩定性,然而這是有代價的,這個代價便是緩存和數據庫的一致性帶來了挑戰。
新增數據時,數據直接寫入數據庫,緩存中不存在對應記錄。首次查詢請求會觸發緩存回填,即從數據庫讀取新數據并寫入緩存,后續請求可直接命中緩存,所以新增數據時不會有數據不一致性問題。
當一條數據同時存在數據庫、緩存,現在你要更新此數據,你會怎么更新?先更新數據庫?還是先更新緩存?
有以下四種更新方式:
- 先更新數據庫后更新緩存
- 先更新緩存后更新數據庫
- 先更新數據庫后刪除緩存
- 先刪除緩存后更新數據
接下來會逐一分析這四種更新方式帶來的數據不一致性問題并解決。
先更新數據庫后更新緩存
一種常見的操作是,設置一個過期時間,讓寫請求以數據庫為準,過期后,讀請求同步數據庫中的最新數據給緩存。那么在加入了過期時間后,是否就不會有問題了呢?并不是這樣。
| 時間 | 線程A(寫請求) | 線程B(寫請求) | 問題 |
|---|---|---|---|
| T1 | 更新數據庫為99 | ||
| T2 | 更新數據庫為88 | ||
| T3 | 更新緩存為88 | ||
| T4 | 更新緩存為99 | ||
| T5 | 此時緩存的值為99,但是實際上數據庫的值為88,數據不一致 |
數據不一致產生的場景:
- 并發寫沖突:就是上面表格中的情況,線程A和線程B同時更新同一數據,線程A先完成數據庫的更新,線程B然后完成數據庫和緩存更新,最后線程A更新緩存,會導致緩存最終存儲線程A的舊數據。
- 緩存更新失敗:若數據庫更新成功但緩存更新失敗,后續請求會讀取到舊緩存數據,直至緩存過期。
先更新緩存后更新數據庫
先更新數據庫后更新緩存會導致數據不一致,那你可能會想,這是否表示,我應該先讓緩存更新,之后再去更新數據庫呢?
| 時間 | 線程A(寫請求) | 線程B(寫請求) | 問題 |
|---|---|---|---|
| T1 | 更新緩存為99 | ||
| T2 | 更新緩存為88 | ||
| T3 | 更新數據庫為88 | ||
| T4 | 更新數據庫為99 | ||
| T5 | 此時緩存的值為88,但是實際上數據庫的值為99,數據不一致 |
數據不一致產生的場景:
- 并發寫沖突:就是上面表格中的情況,線程A和線程B同時更新同一數據,線程A先完成緩存的更新,線程B然后完成緩存和數據庫更新,最后線程A更新數據庫,會導致緩存最終存儲線程B的舊數據。
- 緩存成功但數據庫失敗:緩存存儲新數據,數據庫仍為舊值,后續請求直接命中緩存錯誤數據。
- 主從延遲問題:若數據庫為主從架構,緩存更新后從庫未同步完成,讀請求可能從從庫獲取舊數據并覆蓋緩存。
先刪除緩存后更新數據庫
既然更新數據庫前后更新緩存都會導致數據不一致,那如果采取刪除緩存的策略呢?也就是說我們在更新數據庫的時候失效對應的緩存,讓緩存在下次觸發讀請求時進行更新,是否會更好呢?
| 時間 | 線程A(寫請求) | 線程B(讀請求) | 問題 |
|---|---|---|---|
| T1 | 刪除緩存 | ||
| T2 | 從數據庫中讀取值為100,設置緩存中的值為100 | ||
| T3 | 更新數據庫為99 | ||
| T4 | 此時緩存的值為100,但是實際上數據庫的值為99,數據不一致 |
數據不一致產生的場景:
- 讀寫并發沖突:就是上面表格中的情況,線程A先刪除緩存,線程B然后從數據庫讀取舊的值并更新緩存,最后線程A更新數據庫,會導致緩存最終存儲數據庫的舊數據。
針對這種場景,有個做法是所謂的“延遲雙刪策略”,就是說,既然可能因為讀請求把一個舊的值又寫回去,那么我在寫請求處理完之后,等到差不多的時間延遲再重新刪除這個緩存值。
| 時間 | 線程A(寫請求) | 線程B(讀請求) | 線程C(讀請求) | 問題 |
|---|---|---|---|---|
| T1 | 刪除緩存 | |||
| T2 | 從數據庫中讀取值為100,設置緩存中的值為100 | 讀到臟數據 | ||
| T3 | 更新數據庫為99 | 讀到臟數據 | ||
| T4 | sleep(N) | 讀到臟數據 | ||
| T5 | 刪除緩存 | |||
| T6 | 從數據庫中讀取值為99,設置緩存中的值為99 |
這種解決思路的關鍵在于對N的時間的判斷,如果N時間太短,線程A第二次刪除緩存的時間依舊早于線程B把臟數據寫回緩存的時間,那么相當于做了無用功。而N如果設置得太長,那么在觸發雙刪之前,新請求看到的都是臟數據。
先更新數據庫后刪除緩存
那如果我們把更新數據庫放在刪除緩存之前呢,問題是否解決?我們繼續從讀寫并發的場景看下去,有沒有類似的問題。
| 時間 | 線程A(寫請求) | 線程B(讀請求) | 線程C(讀請求) | 問題 |
|---|---|---|---|---|
| T1 | 更新數據庫為99 | |||
| T2 | 從數據庫中讀取值為100,設置緩存中的值為100 | 讀到臟數據 | ||
| T3 | 刪除緩存 | |||
| T4 | 從數據庫中讀取值為99,設置緩存中的值為99 |
可以看到,大體上,采取先更新數據庫再刪除緩存的策略是沒有問題的,僅在更新數據庫成功到緩存刪除之間的時間差內——[T2,T3)的窗口,可能會被別的線程讀取到老值,但是這個時間窗口非常的短
但是真實場景下,還是會有一個情況存在不一致的可能性,這個場景是讀線程發現緩存不存在,于是讀寫并發時,讀線程回寫進去老值。并發情況如下:
| 時間 | 線程A(寫請求) | 線程B(讀請求) | 問題 |
|---|---|---|---|
| T1 | 查詢緩存,緩存缺失,查詢數據庫得到當前值100 | ||
| T2 | 更新數據庫為99 | ||
| T3 | 刪除緩存 | ||
| T4 | 將100寫入緩存 | ||
| T5 | 此時緩存的值為100,但是實際上數據庫的值為99,數據不一致 |
總的來說,這個不一致場景出現條件非常嚴格,因為并發量很大時,緩存不太可能不存在;如果并發很大,而緩存真的不存在,那么很可能是這時的寫場景很多,因為寫場景會刪除緩存。
數據不一致性的根本原因
為什么我們幾乎沒辦法做到緩存和數據庫之間的強一致呢?
理想情況下,我們需要在數據庫更新完后把對應的最新數據同步到緩存中,以便在讀請求的時候能讀到新的數據而不是舊的數據(臟數據)。但是很可惜,由于數據庫和Redis之間是沒有事務保證的,更新數據庫和更新(刪除)緩存不是一個原子操作,所以我們無法確保寫入數據庫成功后,寫入Redis也是一定成功的;即便Redis寫入能成功,在數據庫寫入成功后到Redis寫入成功前的這段時間里,Redis數據也肯定是和MySQL不一致的。
所以說這個時間窗口是沒辦法完全消滅的,除非我們付出極大的代價,使用分布式事務等各種手段去維持強一致,但是這樣會使得系統的整體性能大幅度下降,甚至比不用緩存還慢,這樣不就與我們使用緩存的目標背道而馳了嗎?
不過雖然無法做到強一致,但是我們能做到的是緩存與數據庫達到最終一致,而且不一致的時間窗口我們能做到盡可能短,要是數據庫更新完畢后,刪除緩存失敗了咋辦?
對于這種情況,一種常見的解決方案就是使用消息中間件來實現刪除的重試。大家知道,MQ一般都自帶消費失敗重試的機制,當我們要刪除緩存的時候,就往MQ中扔一條消息,緩存服務讀取該消息并嘗試刪除緩存,刪除失敗了就會自動重試。
異步延遲雙刪
延遲雙刪:先執行緩存清除操作,再執行數據庫更新操作,延遲N秒之后再執行一次緩存清除操作,這樣就不用擔心緩存中的數據和數據庫中的數據不一致了。
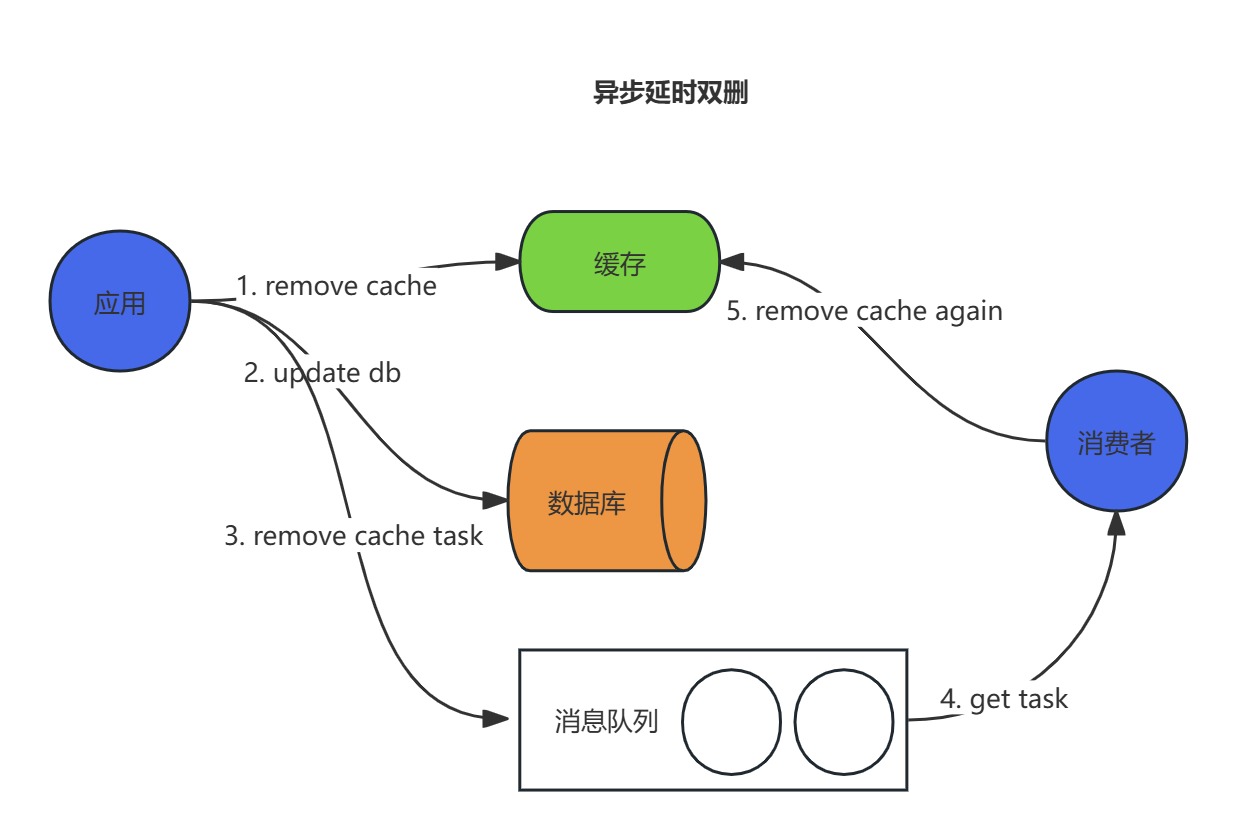
那么這個延遲N秒,N是多大比較合適呢?一般來說,N要大于一次寫操作的時間,如果延遲時間小于寫入緩存的時間,會導致請求A 已經延遲清除了緩存,但是此時請求B緩存還未寫入,具體是多少,就要結合自己的業務來統計這個數值了。
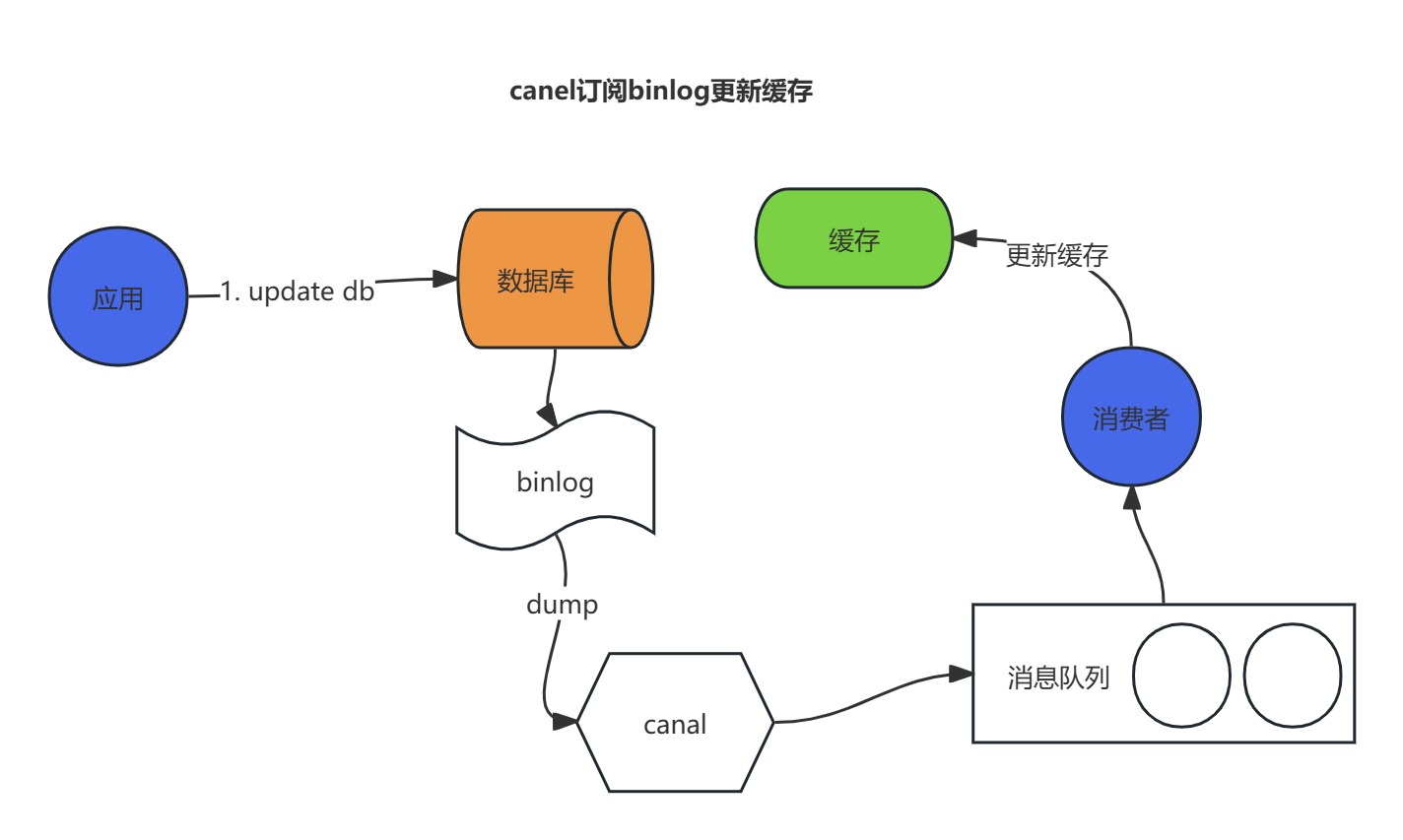
通過訂閱MySQL binlog的方式處理緩存
上面講到的MQ處理方式需要業務代碼里面顯式地發送MQ消息。還有一種優雅的方式便是訂閱MySQL的binlog,監聽數據的真實變化情況以處理相關的緩存。
目前業界類似的產品有Canal,具體的操作圖如下:



)



:創業移情階段的核心要點與實踐方法)











