MYSQL 索引與數據結構筆記
文章目錄
- MYSQL 索引與數據結構筆記
- 1. B-Tree 與 B+ Tree 基礎對比
- 一、B 樹的優勢
- 二、B 樹的進一步優化
- 三、綜合對比
- 結論
- 2. MySQL 為何選擇 B+ Tree
- 3. 索引使用示例與性能分析
- 3.1 整數字段索引查詢
- 3.2 字符字段索引查詢
- 4. 索引失效與類型轉換陷阱
- 5. 小結
1. B-Tree 與 B+ Tree 基礎對比
- B-Tree(平衡樹)
- 每個節點既存儲 鍵(Key),也存儲 實際數據(Data)。
- 查找時從根節點(Root)開始,沿著指針遍歷至葉節點(Leaf),每次節點訪問都可能觸發一次磁盤 I/O。
- 特點:小的鍵在左,大的鍵在右,定位單條記錄的最壞深度與樹高成正比。
- B+ Tree(平衡樹加強版)
- 非葉子節點 只存儲 鍵,不存儲數據;所有數據集中存放于 葉子節點。
- 葉子節點之間通過雙向鏈表相連,支持范圍查詢時從起始葉節點依次遍歷,無需回到根節點重復搜索。
- 由于非葉子節點僅存鍵,可在同頁面存儲更多索引,樹更“寬”、高度更淺,減少索引查找的磁盤 I/O 次數。
以上圖示直觀對比了兩者的結構差異:
- B-Tree 左側,內外節點均存數據;
- B+ Tree 右側,內部節點只有鍵,葉子通過鏈表橫向連接。
B 樹相比其他數據結構為何更快?B 樹又如何進一步提升性能?
一、B 樹的優勢
- 高扇出(Fan-out)、低高度
- B 樹的每個節點(頁面)可以包含 m 個子指針和 m–1 個關鍵字,通常 m 很大(幾百到上千),因為頁面大小(如 16 KB)可容納大量記錄指針。
- 相比二叉搜索樹(每節點僅 2 個子指針),B 樹樹高明顯更低:
高度 ≈ log ? m N ? log ? 2 N \text{高度} \approx \log_{m}N \ll \log_{2}N 高度≈logm?N?log2?N - 結果:每次查詢只需少量層次的磁盤 I/O。
- 磁盤友好:“頁面+批量讀寫”
- 節點大小與磁盤塊(頁面)大小匹配,一次 I/O 就能讀取或寫入一個完整節點。
- 大量連續指針和鍵值在同一頁面中,最大化單次 I/O 的有效數據利用率。
- 動態平衡
- B 樹在插入/刪除時始終保持平衡,無需昂貴的旋轉操作(區別于 AVL、紅黑樹)。
- 分裂/合并操作較少,且都局限在少數相鄰節點,引發的頁面寫回有限。
- 支持范圍查詢(部分)
- 雖非鏈表連接,B 樹也能通過中序遍歷葉子節點進行范圍掃描,復雜度 O ( log ? m N + K ) O(\log_m N + K) O(logm?N+K),其中 K 是返回行數。
二、B 樹的進一步優化
在 B 樹基礎上,B+ 樹對 I/O 和范圍查詢做了兩點關鍵改進:
- 非葉子節點只存“路由鍵”
- B 樹:每個節點都存鍵+數據指針。
- B+ 樹:
- 內部節點:僅存 鍵 和子指針,頁內可容納更多分支,進一步提升扇出 m m m。
- 葉子節點:存所有 鍵 + 數據指針。
- 好處:更寬的樹 → 更淺的樹 → 更少層級 I/O。
- 葉子節點雙向鏈表
- 所有葉子通過指針串聯,形成線性鏈表。
- 范圍查詢:
- 定位首條記錄( log ? m N \log_m N logm?N 次 I/O)。
- 順鏈遍歷后續葉子頁,每頁一次 I/O,即可連續獲取大量記錄,無需再回到根節點。
- 預取優化:操作系統或 InnoDB 可預測地提前讀取下幾頁,減少讀取延遲。
三、綜合對比
| 特性 | 二叉樹 / AVL / 紅黑樹 | B 樹 | B+ 樹 |
|---|---|---|---|
| 樹高 | Θ ( log ? 2 N ) \Theta(\log_2 N) Θ(log2?N) | Θ ( log ? m N ) \Theta(\log_m N) Θ(logm?N) | Θ ( log ? m N ) \Theta(\log_m N) Θ(logm?N)(更小) |
| 每層 I/O | 1 個節點(小) | 1 個大頁面 | 1 個更大分支數大頁面 |
| 插入/刪除 | 旋轉、重染色開銷大 | 分裂/合并局部節點 | 同 B 樹,節點更少分裂 |
| 范圍查詢 | 需要中序多次回溯 | 葉子遍歷可中序,但無鏈表需回根 | 首查后鏈表順序遍歷,高效順序讀取 |
| 磁盤利用率 | 無頁面概念,非批量 I/O | 每頁批量 | 同 B 樹,更多指針→更高頁面利用率 |
結論
- B 樹 相比純內存二叉結構,更貼合磁盤 I/O 模型:高扇出、低樹高、少 I/O。
- B+ 樹 在此基礎上:
- 更高扇出(節點更“瘦”),進一步壓低樹高;
- 鏈表化葉子,極大優化范圍掃描和預取,減少隨即 I/O。
這種設計正好契合數據庫對“大量數據+高并發讀寫+范圍查詢”場景的需求,因而被廣泛采用,MySQL InnoDB 默認索引即基于 B+ 樹。
2. MySQL 為何選擇 B+ Tree
-
更少的磁盤 I/O
- 葉子節點更集中,樹高度更低。
- 訪問任意數據最多經過 ? log ? m N ? \lceil \log_{m}N\rceil ?logm?N?層,且每層頁面能存更多指針。
-
高效的范圍查詢
- 雙向鏈表鏈通所有葉節點。
- 查詢
[low, high]時,從根定位low,再順鏈查到high,無需多次回根。
-
頁面利用更高
- 非葉子節點僅存鍵,單頁指針更多。
- 更少分裂、重平衡次數,維護成本更低。
3. 索引使用示例與性能分析
假設有如下測試表:
CREATE TABLE t_demo (id_int INT NOT NULL PRIMARY KEY,id_char CHAR(10),INDEX idx_char (id_char)
);
INDEX / KEY
- 在 SQL 標準中,
INDEX用于指示“給某列建立額外的索引結構”;MySQL 中INDEX和KEY同義。 - 作用:加速基于該列的查找(
=、IN)、排序(ORDER BY)、范圍掃描(BETWEEN、>、<)等操作。 - 類型:
- 普通索引(Secondary Index):如上例
idx_char,只存列值 + 聚簇主鍵,用于輔助查找。 - 唯一索引(UNIQUE INDEX):加上
UNIQUE關鍵字,保證列值不重復。 - 全文索引(FULLTEXT):用于自然語言全文檢索。
- 空間索引(SPATIAL):針對 GIS 數據。
- 普通索引(Secondary Index):如上例
idx_char
-
這是索引的名字,必須在同表內唯一。
-
建議命名習慣:
idx_<列名>或idx_<表名>_<列名>,便于維護和閱讀。 -
用途示例:
SHOW INDEX FROM t_demo; -- 你會看到一個名為 idx_char 的索引,Column_name: id_char DROP INDEX idx_char ON t_demo;
聚簇索引 vs 輔助索引
- 聚簇索引(Clustered Index)
- 由 InnoDB 強制由主鍵構建。
- 葉子節點直接存放整行數據(行記錄)。
- 輔助索引(Secondary Index)
- 葉子節點只存「索引列值 + 主鍵列值」。
- 查到主鍵后,再回聚簇索引查整行。
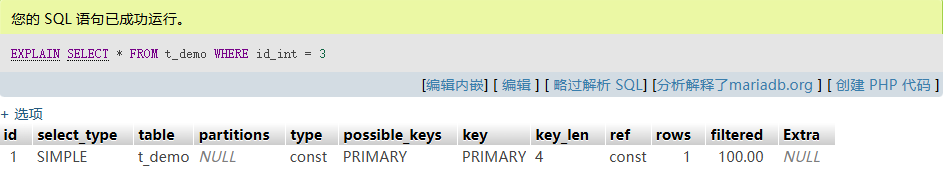
3.1 整數字段索引查詢
EXPLAIN SELECT * FROM t_demo WHERE id_int = 3;
- Output:
key: PRIMARY, rows: 1 - 利用聚簇索引,直接定位葉節點,一個 I/O 即可返回數據。
EXPLAIN用于讓 MySQL 優化器輸出該查詢的“執行計劃”,常見字段:
| 列名 | 含義 |
|---|---|
id | 查詢標識,表示第幾條子查詢或聯合查詢 |
select_type | 查詢類型,如 SIMPLE(簡單查詢)、PRIMARY、SUBQUERY 等 |
table | 本行描述的是哪張表 |
type | 訪問類型,從好到差:system / const / eq_ref / ref / range / ALL |
possible_keys | 優化器認為可用的索引列表 |
key | 實際使用的索引 |
key_len | 使用索引的字節長度 |
ref | 哪個列或常量與索引列比較 |
rows | 估算需要掃描的行數 |
filtered | 估算有多少百分比的行會被 WHERE 過濾 |
Extra | 額外信息,如 Using index(覆蓋索引)、Using filesort、Using temporary 等 |
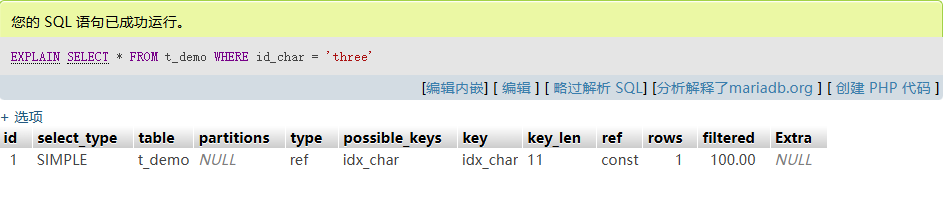
3.2 字符字段索引查詢
EXPLAIN SELECT * FROM t_demo WHERE id_char = 'three';
- Output:
key: idx_char, rows: 1 - 較整型略慢,但依然通過二分定位葉節點和鏈表讀取。
4. 索引失效與類型轉換陷阱
當對 索引字段 應用函數或運算時,會導致 MySQL 無法利用索引,轉而全表掃描,示例如下:
EXPLAIN SELECT * FROM t_demo WHERE id_int + 0 = 1;
-- key: NULL, rows: 全表掃描

原因:
- 聚簇索引的頁內順序被打亂,MySQL 無法在葉節點上直接比較。
- 索引失效后,每行先轉換再比較,磁盤 I/O 和 CPU 轉換開銷劇增。
最佳實踐
-
避免在 WHERE 條件中對索引列進行任何運算或類型轉換。
-
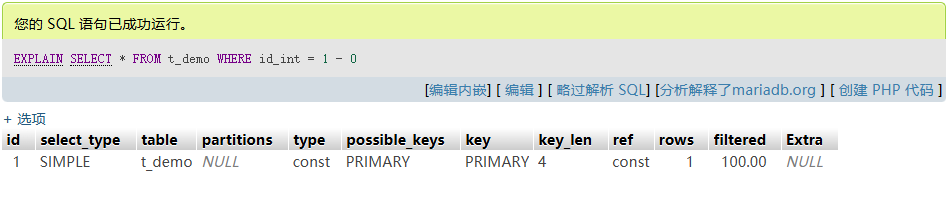
如需偏移量查詢,可將常量移至列右側:
-- 建議 SELECT * FROM t_demo WHERE id_int = 1 - 0; -- 避免 SELECT * FROM t_demo WHERE id_int + 0 = 1; -
對于范圍查詢(如
BETWEEN、>、<),只要不對字段本身改動,即可走范圍索引。
5. 小結
- B+ Tree:MySQL 默認索引結構,專為大規模數據檢索優化。
- 范圍查詢:鏈表加速,極大提升大數據下的連續掃描性能。
- 索引失效:對索引列的任何計算或類型轉換都會導致全表掃描,嚴重影響性能。

,MMC)












)


)
