目錄
信號入門
生活角度中的信號
技術應用角度的信號
信號的發送與記錄
?信號處理常見方式概述
產生信號
通過終端按鍵產生?
通過系統函數向進程發信號
由軟件條件產生信號
由硬件異常產生信號
阻塞信號
信號其他相關常見概念
在內核中的表示
sigset_t
信號集操作函數
sigprocmask 修改block表
調用函數sigprocmask可以讀取或更改進程的信號屏蔽字(阻塞信號集)。
sigpending 修改pending表
捕捉信號
內核空間與用戶空間
?內核態與用戶態
內核如何實現信號的捕捉
sigaction
?????????可重入函數
? ? ? ? ? ? ? volatile
信號入門
生活角度中的信號
- 你在網上買了很多件商品,在等待不同商品快遞的到來。但即便快遞還沒有到來,你也知道快遞到了的時候應該怎么處理快遞,也就是你能“識別快遞”。
- 當快遞到達目的地了,你收到了快遞到來的通知,但是你不一定要馬上下樓取快遞,也就是說取快遞的行為并不是一定要立即執行,可以理解成在“在合適的時候去取”。
- 在你收到快遞到達的通知,再到你拿到快遞期間,是有一個時間窗口的,在這段時間內你并沒有拿到快遞,但是你知道快遞已經到了,本質上是你“記住了有一個快遞要去取”。
- 當你時間合適,順利拿到快遞之后,就要開始處理快遞了,而處理快遞的方式有三種:1、執行默認動作(打開快遞,使用商品)2、執行自定義動作(快遞是幫別人買的,你要將快遞交給他)3、忽略(拿到快遞后,放在一邊繼續做自己的事)。
- 快遞到來的整個過程,對你來講是異步的,你不能確定你的快遞什么時候到。
在這個過程描述中,我們得知的信息都是通過某種方法讓我們得到信號,我們才了解當前的情況。
技術應用角度的信號
在用戶輸入命令,在Shell下啟動一個前臺進程。(前臺進程是指當前正在終端(Terminal)中運行并與用戶直接交互的進程。就比如bash)
在用戶按Ctrl + c,這個鍵盤輸入產生一個硬件中斷,被OS獲取,解釋成信號,發送給目標前臺進程。前臺進程因為受到信號,進而引起進程退出。(在規定上在同一時刻僅允許進行一個硬件中斷)
下面我們在XShell下編寫代碼實現一下
編寫以下程序并運行:
#include <stdio.h>
#include <unistd.h>
int main()
{while(1){printf("I am a process, I am waiting signal!\n");sleep(1);}return 0;
}我們知道該程序的運行結果就是死循環地進行打印,而對于死循環來說,最好的方式就是按照前面說的,按下Ctrl +?c,產生硬件中斷,對其進行終止。
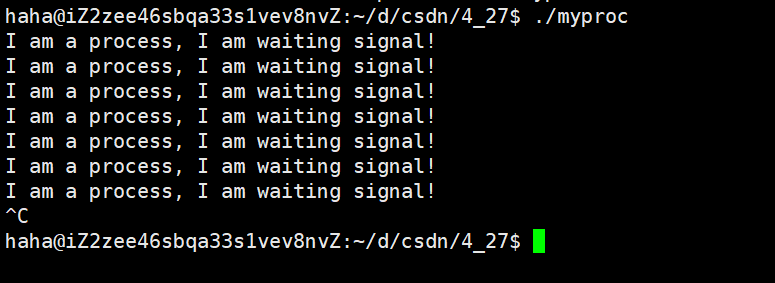
同樣我們剛才說了, 按下Ctrl + c 后,會產生硬件中斷,操作系統會獲取并解釋成信號,然后操作系統將2號信號發送給目標前臺進程,從而使其終止。
那么我們如何驗證呢?其實可以通過使用signal函數對2號信號進行捕捉,證明當我們按Ctrl+C時進程確實是收到了2號信號。使用signal函數時,我們需要傳入兩個參數,第一個是需要捕捉的信號編號,第二個是修改為我們自己的對捕捉信號的處理方法,該處理方法的參數是int,返回值是void。
就比如我們下面的代碼中將2號信號進行了捕捉,當該進程運行起來后,若該進程收到了2號信號就會打印出收到信號的信號編號,而不是進行2號信號的默認操作:終止進程。
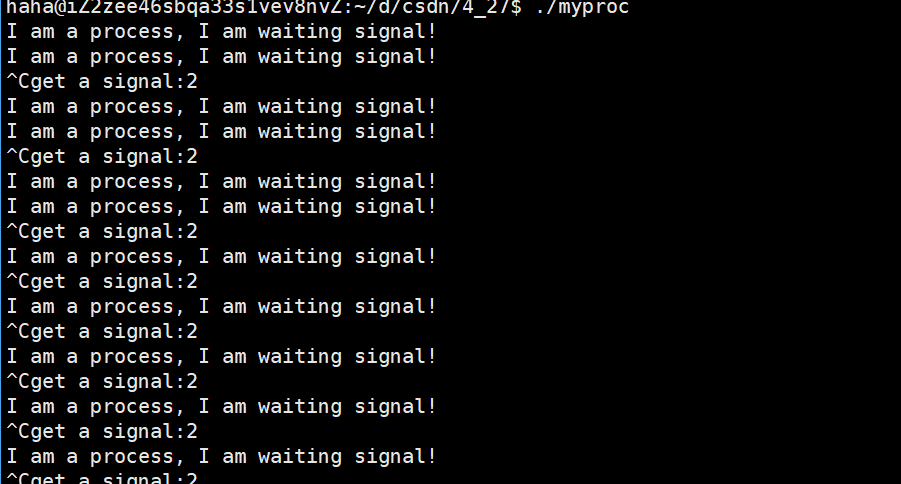
由此也證明了,當我們按Ctrl+C時進程確實是收到了2號信號。
那么此時就會有一個小問題,此時我們如何終止這個一直在終端死循環打印的進程呢?
這貌似是個問題,暴力的方法就是直接關閉該終端窗口,高級的方法就是使用下面的命令
kill -9 PID?那么問題又來了如何得該進程得PID呢?畢竟我們也沒有打印出來啊。
其實可以通過另開一個終端窗口使用監視腳本,然后再kill -9 PID就可以了。
ps axj | head -1; ps axj | grep myproc | grep -v grep
補充:
前臺進程就類比Windows中當前最大化/正在交互的窗口(如你正在編輯的Word文檔)。
特點:
獨占輸入焦點:接收鍵盤鼠標輸入(如打字、點擊按鈕)
界面實時更新:窗口內容可見且動態響應(如視頻播放、游戲畫面)
阻塞性:若進程卡死,整個系統可能無法操作其他窗口(如未響應時需強制關閉)
只能有一個
后臺進程就類比:Windows中最小化或隱藏的窗口(如后臺下載的迅雷)。
特點:
無輸入焦點:不直接接收用戶操作(但可通過通知交互)
資源限制:CPU/內存占用可能被系統抑制(避免影響前臺體驗)
持續運行:即使窗口不可見,任務仍在執行(如郵件接收、文件下載)
可以有多個
后臺進程啟動的方式是再后面加一個 &,這是Ctrl + c 就不管用了,因為他不是前臺進程了,不可以用Ctrl + c 進行終止了。
比如如下
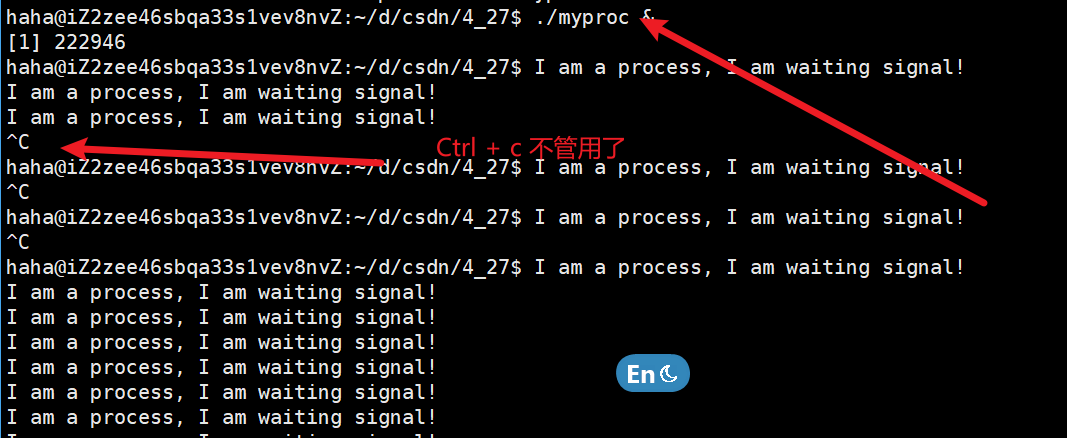
注意:
- Ctrl+C產生的信號只能發送給前臺進程。在一個命令后面加個&就可以將其放到后臺運行,這樣Shell就不必等待進程結束就可以接收新的命令,啟動新的進程。
- Shell可以同時運行一個前臺進程和任意多個后臺進程,但是只有前臺進程才能接到像Ctrl+C這種控制鍵產生的信號。
- 前臺進程在運行過程中,用戶隨時可能按下Ctrl+C而產生一個信號,也就是說該進程的用戶空間代碼執行到任何地方都可能收到SIGINT信號而終止,所以信號相對于進程的控制流程來說是異步的。
- 信號是進程之間事件異步通知的一種方式,屬于軟中斷。
補充:
信號的異步性(Asynchronous)
核心矛盾:
進程的正常代碼流是順序執行的(如函數A→函數B→函數C),但信號可能在任何時刻打斷這一流程(比如執行到函數B時突然觸發SIGINT)。
異步體現:信號的到來與進程當前執行位置無關,就像你在看書時突然被電話打斷,電話的來電時機與你看書的進度無關。
技術細節:
當用戶按下Ctrl+C時:
終端驅動檢測到按鍵,生成
SIGINT信號。內核強制將信號插入目標進程的待處理信號隊列。
無論進程正在執行什么代碼(除非阻塞信號),內核都會在下一次返回用戶態前讓進程處理信號。
軟中斷的本質:
信號是內核通過模擬中斷機制實現的軟件層事件通知。當信號到達時,內核會暫時打斷進程的正常執行流,轉而執行信號處理函數(類似硬中斷(也叫硬件中斷)服務例程),之后再恢復原流程。
信號的發送與記錄
我們可以用kill -l??命令可以查看Linux當中的信號列表。
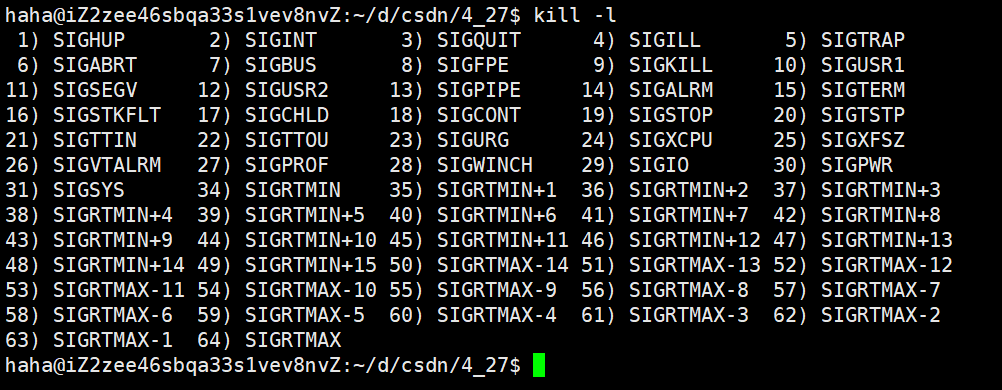
其中1~31號信號是普通信號,34~64號信號是實時信號,普通信號和實時信號各自都有31個,每個信號都有一個編號和一個宏定義名稱:
這個文件沒有找到,偷了一下別人的圖。。。
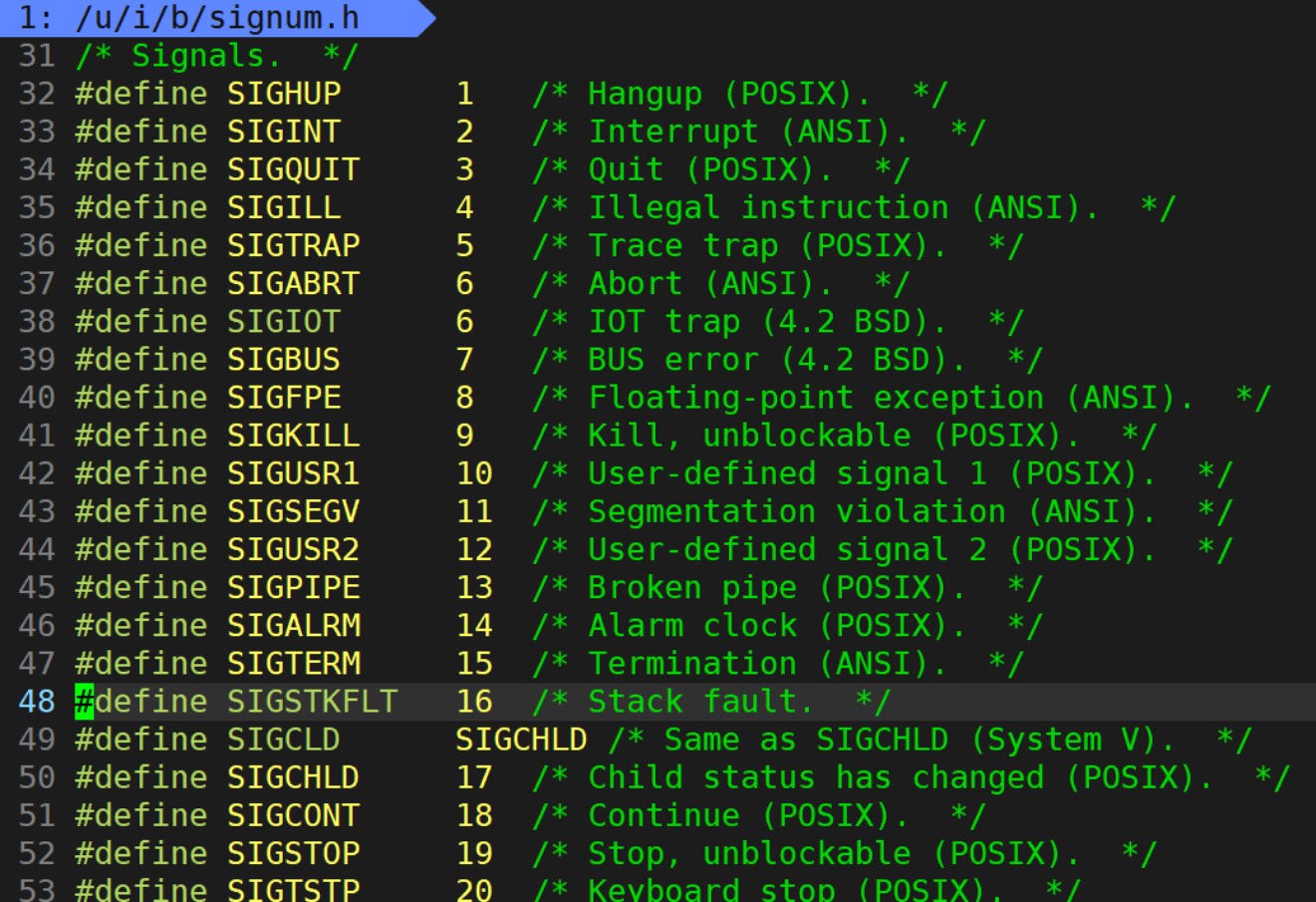
信號是如何記錄的?
實際上,當一個進程接收到某種信號后,該信號是被記錄在該進程的進程控制塊當中的。我們都知道進程控制塊本質上就是一個結構體變量,而對于信號來說我們主要就是記錄某種信號是否產生,因此,我們可以用一個32位的位圖來記錄信號是否產生。
其中比特位的位置代表信號的編號,而比特位的內容就代表是否收到對應信號,比如第6個比特位是1就表明收到了6號信號。?
信號是如何產生的?
一個進程收到信號,本質就是該進程內的信號位圖被修改了,也就是該進程的數據被修改了,而只有操作系統才有資格修改進程的數據,因為操作系統是進程的管理者。也就是說,信號的產生本質上就是操作系統直接去修改目標進程的task_struct中的信號位圖。
注意: 信號只能由操作系統發送,但信號發送的方式有多種。
?信號處理常見方式概述
- 執行該信號的默認處理動作。
- 提供一個信號處理函數,要求內核在處理該信號時切換到用戶態執行這個處理函數,這種方式稱為捕捉(Catch)一個信號。
- 忽略該信號
在Linux當中,我們可以通過man手冊查看各個信號默認的處理動作。
man 7 signal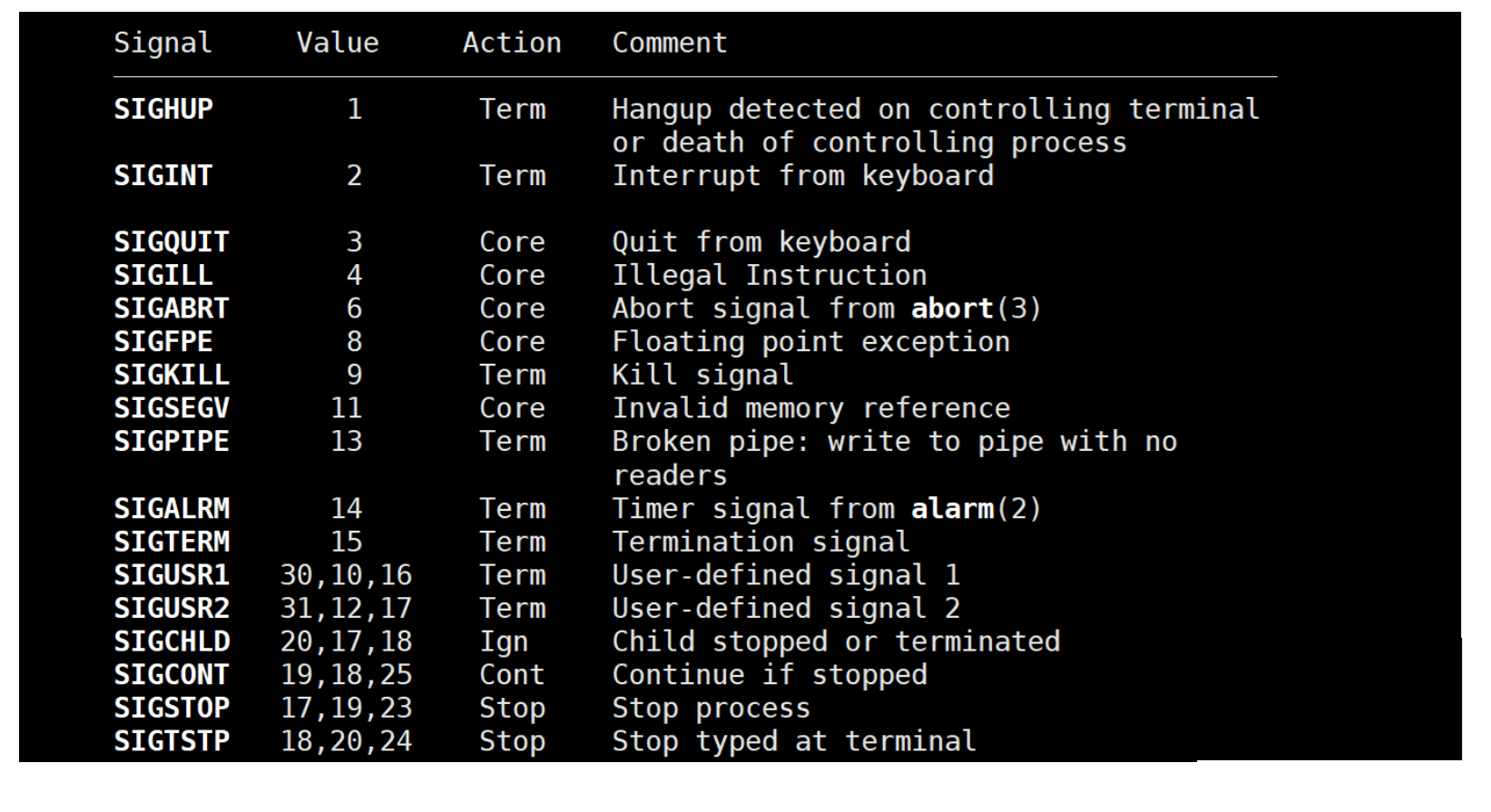
產生信號
通過終端按鍵產生?
通過終端按鍵(如 Ctrl + C)終止剛才的死循環程序,實際上是利用了 Linux/Unix 系統的信號機制。當我們按下 Ctrl + C 時,終端會向當前前臺進程發送一個?SIGINT(中斷信號),默認情況下這會終止該進程的執行。
但實際上我們還可以通過按Ctrl+\也可以終止該進程。
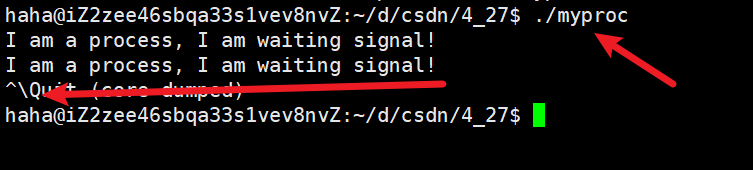
那么按Ctrl+C終止進程和按Ctrl+\終止進程,有什么區別??
按Ctrl+C實際上是向進程發送2號信號SIGINT,而按Ctrl+\實際上是向進程發送3號信號SIGQUIT。查看這兩個信號的默認處理動作,可以看到這兩個信號的Action是不一樣的,2號信號是Term,而3號信號是Core。
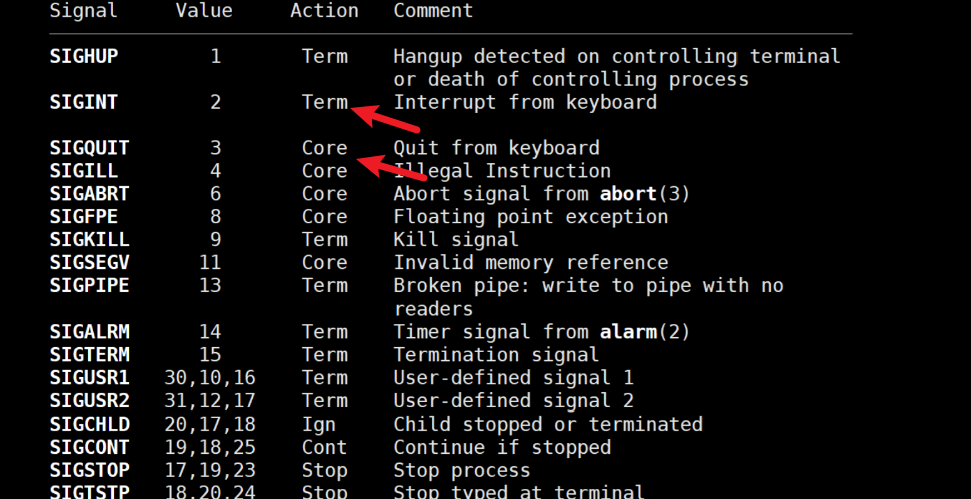 ?Term和Core都代表著終止進程,但是Core在終止進程的時候會進行一個動作,那就是核心轉儲,也就是Core Dump。
?Term和Core都代表著終止進程,但是Core在終止進程的時候會進行一個動作,那就是核心轉儲,也就是Core Dump。
Core Dump
首先解釋一下什么是Core Dump。當一個進程要異常終止時,可以選擇把這個進程的用戶空間內存數據全部保存到磁盤上,文件名通常時core,這個做Core Dump。進程異常終止通常時因為有Bug,比如非法內存訪問導致段錯誤,事后可以用調試器檢測core文件以查清錯誤原因,這叫做Post-mortem Debug(事后調試)。一個進程允許產生多大的core文件取決于進程的Resource Limit(這個信息保存在PCB中)。默認是不允許產生core文件的,因為core文件中可能包含用戶密碼等敏感信息,不安全。在開發調試階段可以用ulimit命令改變這個限制,允許產生core文件。首先用ulimit命令改變Shell進程的?Resource Limit,允許core文件最大為1024K:ulimit -c 1024
剛才上面也說了,默認設計不允許產生core文件的,那么在我們服務器中Core Dump是默認關閉的,但是我們可以通過使用ulimit命令進行改變。
ulimit -a命令查看當前資源限制的設定。
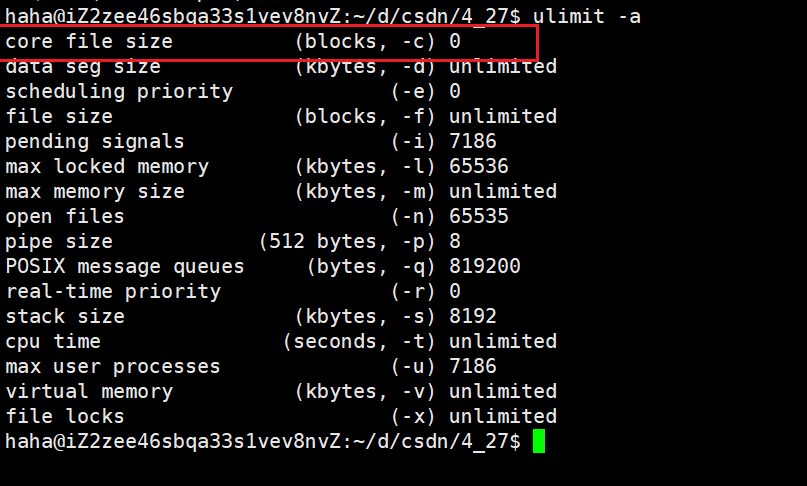
圖中,第一行顯示core文件的大小為0,也在表示Core Dump是被關閉的,不允許常見core文件。
?ulimit -c size命令來設置core文件的大小。
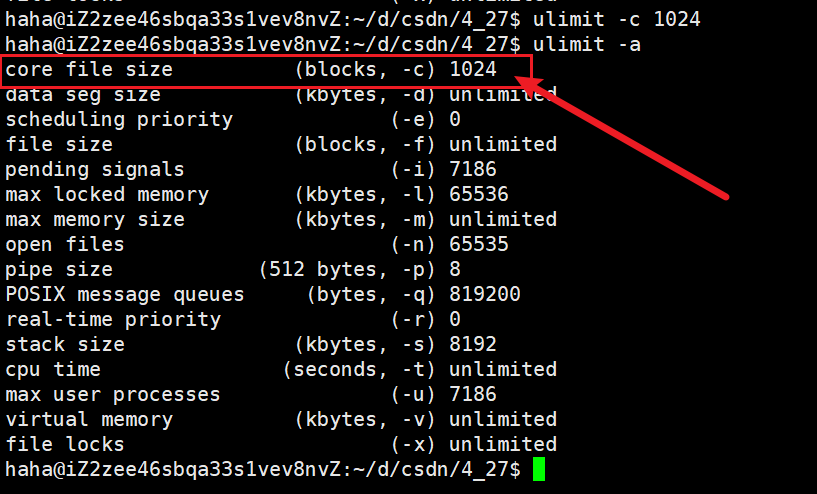
core文件的大小設置完畢后,就相當于將核心轉儲功能打開了。此時如果我們再使用Ctrl+\對進程進行終止,就會發現終止進程后會顯示core dumped。?
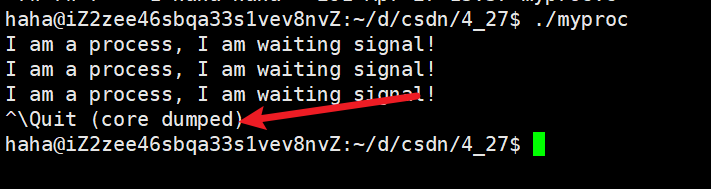
并且會在當前路徑下生成一個core文件,該文件以一串數字為后綴,而這一串數字實際上就是發生這一次核心轉儲的進程的PID。
使用gdb對當前可執行程序進行調試,使用core-file core文件命令加載core文件,即可判斷出該程序在終止時收到了具體信號,借此可以準確找到錯誤。
core dump標志?
在學習進程等待的時候,進程等待函數waitpid函數的第二個參數是status么?
pid_t waitpid(pid_t pid, int *status, int options);waitpid函數的第二個參數status是一個輸出型參數,其類型是一個int*,占4字節,但我們不把status看為簡單的整型,而是將status的不同比特位代表不同的信息,具體細節如下(只關注status低16位比特位):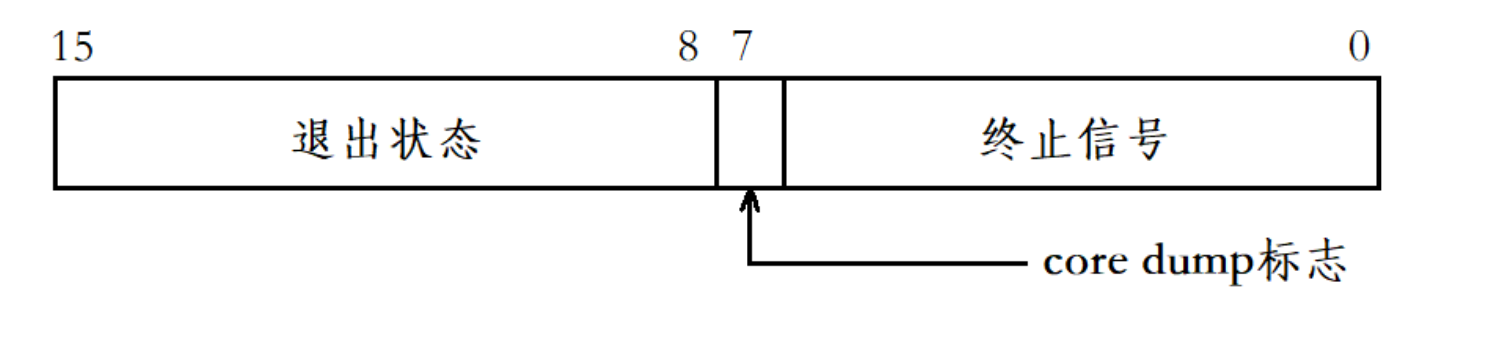
如果一個進程是正常終止的,那么status的次低8位就表示進程的退出狀態,也就是常說的退出碼,最常見的是0。若進程是被信號所殺,也就是異常終止,那么status的低7位表示終止信號,而第8位比特位是core dump標志,即進程終止時是否進行了Core Dump。?
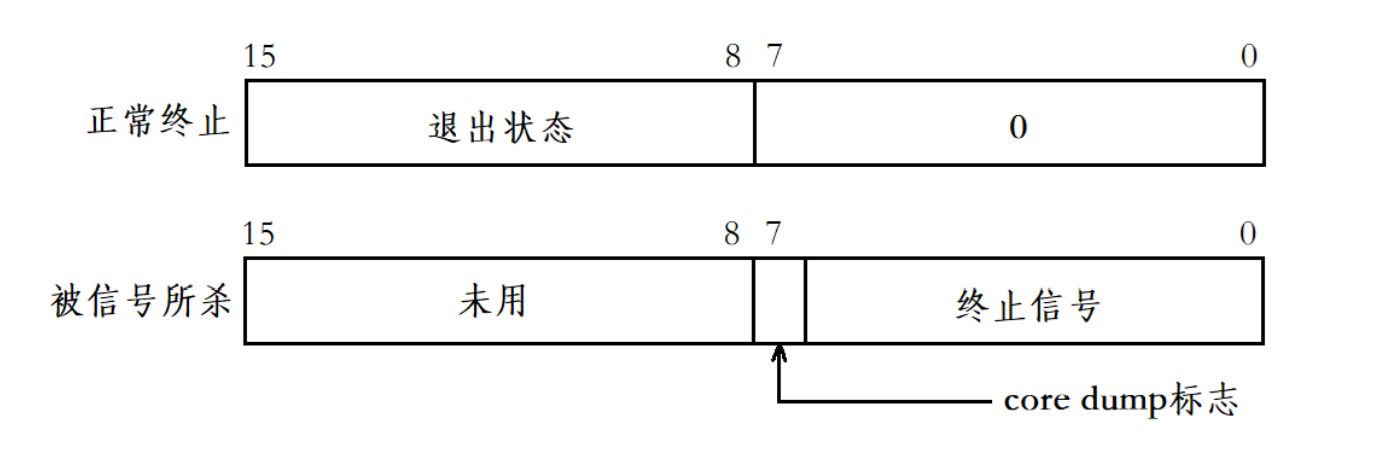
按照前面的步驟,打開Linux的Core Dump功能,并編寫下列代碼。代碼中父進程使用fork函數創建了一個子進程,子進程所執行的代碼當中存在野指針問題,當子進程執行到野指針問題時,必然會被操作系統所終止并在終止時進行Core Dump。此時父進程使用waitpid函數便可獲取到子進程退出時的狀態,根據status的第7個比特位便可得知子進程在被終止時是否進行了Core Dump。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>int main()
{if (fork() == 0){//childprintf("I am running...\n");int *p = NULL;*p = 1; // 野指針問題exit(0);}//fatherint status = 0;waitpid(-1, &status, 0);printf("exitCode:%d, core dump:%d, signal:%d\n",(status >> 8) & 0xff, (status >> 7) & 1, status & 0x7f);return 0;
}
可以看到core dump的標志位為1,是被第11號信號所終止。

因此,core dump標志實際上就是用于表示程序崩潰的時候是否進行了Core Dump。?
總結:
進程一旦異常,OS會將進程在內存中的信息給dump(轉儲)到進程當前的目錄下,從而形成core.PID文件,用于記錄進程崩潰時的內存狀態、寄存器值、調用棧等信息,方便開發者進行事后調試。這一操作叫為:核心存儲(Core Dump)。
補充:
鍵盤是基于硬件終端進行工作的,某些信號是可以用組合鍵通過終端按鍵產生,比如Ctrl+C(2號信號)、Ctrl+\(3號信號)、Ctrl+Z(20號信號),這類信號可以通過signal捕捉到。但并不是所有的信號都可以被signal捕捉到的,比如在前31號信號中,19號信號(暫停),9號信號(殺死指定進程)都不能捕捉到。
如果允許捕獲它們,可能會導致系統管理失控(如僵尸進程無法被殺死),即便是操作系統也為無法終止。
通過系統函數向進程發信號
首先我們在后臺執行死循環程序,然后用kill命令給它發SIGSEGV信號

- 226481是myproc進程的PID。之所以要再次回車才顯示Segmentation fault,是因為在226481進程終止掉之前已經回到了Shell提示符等待用戶輸入下一條命令,Shell不希望Segmentation fault信息和用戶的輸入交錯在一起,所以等用戶輸入命令之后才顯示。
- 指定發送某種信號的kill命令可以有多種寫法,上面的命令還可以寫成kill -SIGSEGV??226481或kill -11?226481,11是信號SIGSEGV的編號。以往遇到的段錯誤都是由非法內存訪問產生的,而這個程序本身沒錯,給它發SIGSEGV也能產生段錯誤。
?kill命令是調用kill函數實現的。kill函數可以給一個指定的進程發送指定的信號。raise函數可以給當前的進程發送指定的信號(自己給自己發信號)。
下面詳細介紹下kill函數與raise函數
kill函數
kill函數的原型 :
int kill(pid_t pid, int sig);?如果信號發送成功,則返回0,否則返回-1。
我們可以用kill函數模擬實現一個kill命令,同樣還用死循環代碼進行展示效果,實現邏輯如下:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <signal.h>
void Usage(char* proc)
{printf("Usage: %s error\n", proc);
}
int main(int argc, char* argv[])
{if(argc != 3){Usage(argv[0]);return 1;}int signo = atoi(argv[2]);pid_t pid = atoi(argv[1]);if(kill(pid, signo) == -1) printf("error\n");return 0;
}raise函數
raise函數的函數原型如下:?
int raise(int sig);raise函數用于給當前進程發送sig號信號,如果信號發送成功,則返回0,否則返回一個非零值。
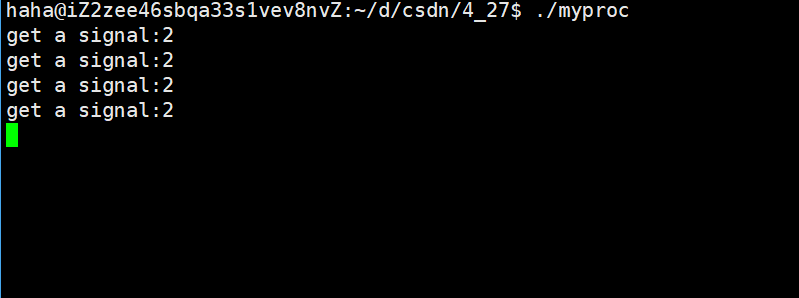
例如每個兩秒給自己發送2號信號?
#include <stdio.h>
#include <unistd.h>
#include <signal.h>
void handler(int sig)
{printf("get a signal:%d\n", sig);
}
int main()
{signal(2, handler); // 捕捉2號信號while(1){sleep(1);raise(2);sleep(1);}return 0;
}
abort函數使當前進程接受到信號而異常終止
?函數原型如下:
#include <stdio.h>
void abort(void);
就像exit函數一樣,abort函數總會成功的,所以沒有返回值。就按上面的代碼進行修改,添加上abort函數。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>
void handler(int sig)
{printf("get a signal:%d\n", sig);
}
int main()
{signal(2, handler); // 捕捉2號信號while(1){sleep(1);raise(2);abort();sleep(1);}return 0;
}與之前不同的是,雖然我們對二號信號進行了捕捉,并且在捕捉后還對其行為進行了自定義方法,但當接受到二號信號后,還是會被終止。?

說明一下:?abort函數的作用是異常終止進程,exit函數的作用是正常終止進程,而abort本質是通過向當前進程發送SIGABRT信號而終止進程的,因此其與exit函數一樣,總是會成功。
由軟件條件產生信號
SIGPIPE信號
SIGPIPE信號實際上就是一種由軟件條件產生的信號,當進程在使用管道進行通信時,讀端進程將讀端關閉,而寫端進程還在一直向管道寫入數據,那么此時寫端進程就會收到SIGPIPE信號進而被操作系統終止。
alarm函數與SIGALRM信號?
調用alarm函數可以設定一個鬧鐘,也就是告訴操作系統在若干時間后發送SIGALRM信號給當前進程,alarm函數的函數原型如下:
#include <unistd.h>
unsigned int alarm(unsigned int seconds);?調用alarm函數可以設定一個鬧鐘,也就是告訴內核在seconds秒后給當前進程發送SIGALRM信號,該信號的默認處理動作是終止當前進程。
alarm函數的返回值是0或者是以前設定的鬧鐘時間還剩余下的秒數。打個比方,某人要小睡一覺,設定鬧鐘為30分鐘之后響,20分鐘后被吵醒了,但還想多睡一會,于是重新設定了一個鬧鐘為15分鐘后響起,以前設定的鬧鐘時間還剩余下的時間就是10分鐘。
如果seconds的值是0,表示取消以前設定的鬧鐘,函數的返回值是以前設定的鬧鐘時間還余下的秒數。
在上面的操作中被吵醒后
可能看完還有疑惑,不妨,我們實驗一下。
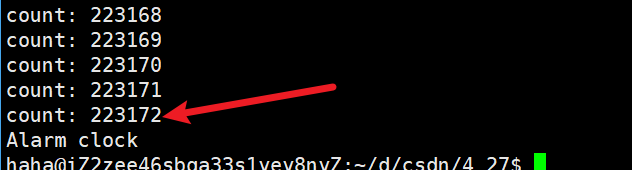
1:我們可以用下面的代碼,測試自己的云服務器一秒時間內可以將一個變量累加到多大。
#include <stdio.h>
#include <signal.h>
#include <unistd.h>
int main()
{int count = 0;alarm(1);while (1){count++;printf("count: %d\n", count);}return 0;
}運行代碼后,可以發現我當前的云服務器在一秒內可以將一個變量累加到20萬左右。
補充:
但實際上我當前的云服務器在一秒內可以執行的累加次數遠大于20萬,那為什么上述代碼運行結果比實際結果要小呢?
主要原因有兩個,首先,由于我們每進行一次累加就進行了一次打印操作,而與外設之間的IO操作所需的時間要比累加操作的時間更長,其次,由于我當前使用的是云服務器,因此在累加操作后還需要將累加結果通過網絡傳輸將服務器上的數據發送過來,因此最終顯示的結果要比實際一秒內可累加的次數小得多。
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>int count = 0;
void handler(int signo)
{printf("get a signal: %d\n", signo);printf("count: %d\n", count);exit(1);
}
int main()
{signal(SIGALRM, handler);alarm(1);while (1){count++;}return 0;
}
此時可以看到,count變量在一秒內被累加的次數變成了五億多,由此也證明了,與計算機單純的計算相比較,計算機與外設進行IO時的速度是非常慢的。?

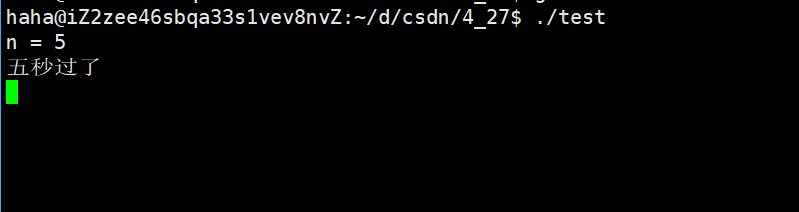
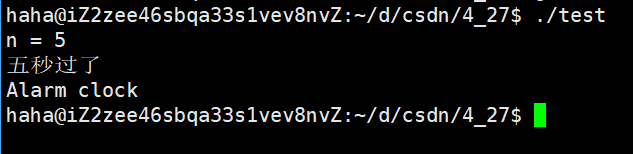
2: 先設定一個10秒鬧鐘,后設定一個7秒鬧鐘
#include <stdio.h>
#include <signal.h>
#include <unistd.h>int main()
{alarm(10); // 先設定一個10s的鬧鐘sleep(5); //還剩五秒unsigned int n = alarm(7);printf("n = %d\n", n);sleep(5);printf("五秒過了\n");sleep(10);return 0;
}可以看到返回值為5是第一個鬧鐘還剩余的時間,但是過了5秒,第一次設定的鬧鐘并沒有響,而是過了7秒后第二個鬧鐘響了,這就說明了,后面設定的鬧鐘會覆蓋前面的鬧鐘。
由硬件異常產生信號
硬件異常是指被硬件以某種方式被硬件檢測到并通知內核,然后內核向當前進程發送適當的信號。例如當前進程執行了除以0的指令,CPU的運算單元會產生異常,內核將這個異常解釋為SIGFPE信號發送給進程。在比如當前進程訪問了非法內存地址,MMU(內存管理單元)會產生異常,內核將這個異常解釋為SIGSEGV信號發送給進程。
總結一下:
C/C++程序會崩潰,是因為程序當中出現的各種錯誤最終一定會在硬件層面上有所表現,進而會被操作系統識別到,然后操作系統就會發送相應的信號將當前的進程終止。
下面模擬一下野指針的異常
比如以下代碼
#include <stdio.h>
#include <signal.h>
#include <unistd.h>
int main()
{sleep(1);int *p = NULL;*p = 100;while(1);return 0;
}運行起來后效果如下:

可見,進程會因為野指針會被異常終止。在這個過程中,我們先定義了一個定義了一個指針。但在訪問這個指針的時候,他會先通過頁表映射,將虛擬地址轉換成物理地址,然后才可以進行接下來的訪問操作。
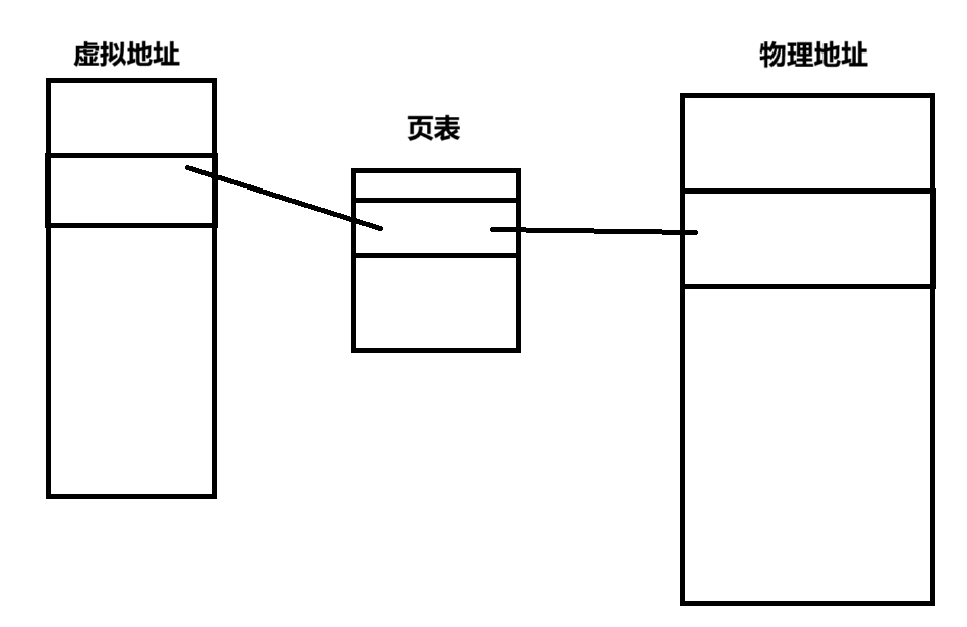
其中頁表屬于一種軟件映射關系,我們拿著虛擬地址去頁表找對應的虛擬地址,然后映射找到對應的物理地址,但實際上從虛擬地址到物理地址映射的時候還有一個硬件叫做MMU,它是計算機硬件中的一個關鍵組件,負責處理CPU的內存訪問請求,并實現操作系統的虛擬內存管理機制。因此映射工作不是由CPU做的,而是由MMU做的,但現在的計算機已經將MMU歸并為了CPU的一個子系統。
當需要進行虛擬地址到物理地址的映射時,需要先將左側的虛擬地址給MMU,然后MMU會計算出對應的物理地址,我們再通過這個物理地址進行相應的訪問。
而MMU既然是硬件單元,那么它當然也有相應的狀態信息,當我們要訪問不屬于我們的虛擬地址時,MMU在進行虛擬地址到物理地址的轉換時就會出現錯誤,然后將對應的錯誤寫入到自己的狀態信息當中,這時硬件上面的信息也會立馬被操作系統識別到,進而將對應進程發送SIGSEGV信號。
總結:
C/C++程序崩潰,是因為程序當中出現的各種錯誤最終一定會在硬件層面上有所表現,進而會被操作系統識別到,然后操作系統就會發送相應的信號將當前的進程終止。
阻塞信號
信號其他相關常見概念
- 實際執行信號的處理動作,稱為信號遞達(Delivery)。
- 信號從產生到遞達之間的狀態,稱為信號未決(pending)。
- 進程可以選擇阻塞(Block)某個信號。
- 被阻塞的信號產生時將保持在未決狀態,直到進程解除對此信號的阻塞,才執行遞達的動作。
- 注意,阻塞和忽略是不同的,只要信號被阻塞就不會遞達,而忽略是在遞達之后的一種處理動作。
對于此的理解,如果我們把信號遞達比作為寫作業,那么信號未決就類似于將老師布置的作業記下來。進程可以阻塞某個信號就可以類似比作為屏蔽某科布置的作業,但屏蔽歸屏蔽,但還是知道是什么作業的,這就好比已讀不回。而忽略則可以比作為未讀。
在內核中的表示
信號在內核中的表示示意圖如下:
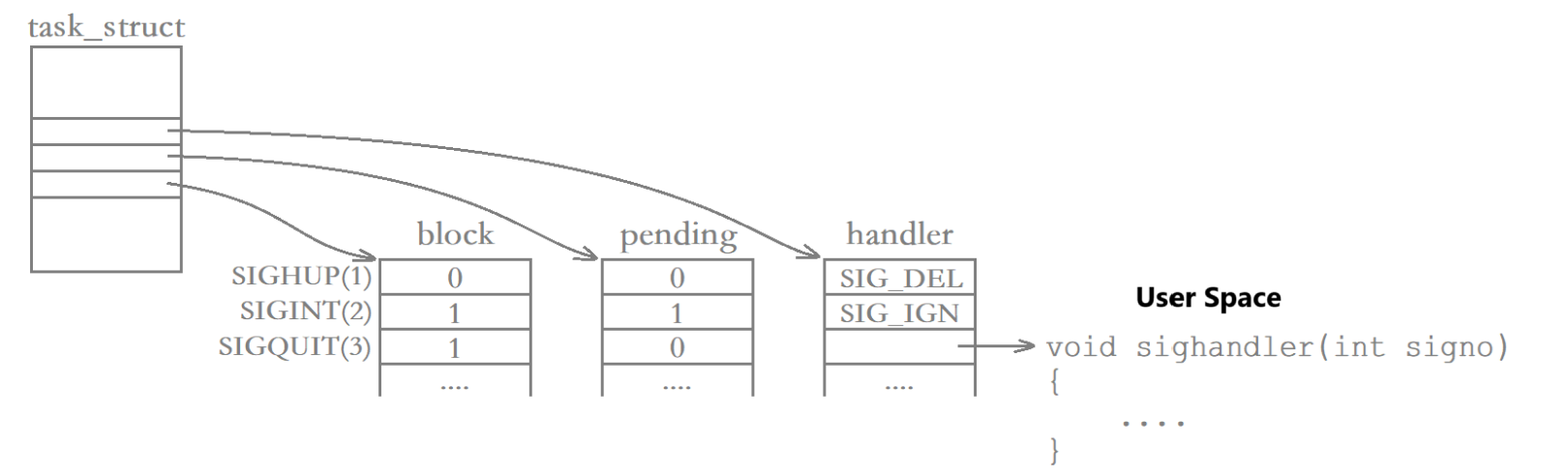
- 每個信號都有兩個標志位分別表示阻塞(block)和未決(pending),還有一個函數指針表示處理動作。信號產生時,內核在進程控制塊中設置該信號的未決標志,直到信號遞達才清除該標志。在上圖中,SIGHUP信號未阻塞也未產生過,當它遞達時執行默認處理動作。
- SIGINT信號產生過,但正在被阻塞,所以暫時不能遞達。雖然它的處理動作是忽略,但在沒有解除阻塞之前不能忽略這個信號,因為進程仍有機會在改變處理動作之后再接觸阻塞。
- SIGQUIT信號未產生過,但一旦產生SIGQUIT信號,該信號將被阻塞,它的處理動作是用戶自定義函數sighandler。如果在進程解除對某信號的阻塞之前,這種信號產生過多次,POSIX.1允許系統遞達該信號一次或多次。Linux是這樣實現的:普通信號在遞達之前產生多次只計一次,而實時信號在遞達之前產生多次可以依次放在一個隊列里,這里只討論普通信號。
?總結一下:
- 在block位圖中,比特位的每個位置都代表一個對某一信號的標記,比特位的內容代表該信號是否被阻塞,即0表示不屏蔽,1表示屏蔽。
- 在pending位圖中,比特位的位置代表對某一信號的一個標識,比特位的內容代表是否收到該信號,即0表示沒有收到,1表示收到。
- handler表本質上是一個函數指針數組,數組的下標代表某一個信號,數組的內容代表該信號遞達時的處理動作,處理動作包括默認、忽略以及自定義。
- block、pending和handler這三張表的每一個位置是一一對應的。
sigset_t
從上面的內核表示中的圖中可以看出,每個信號只有一個bit的未決標志,非0即1,不記錄該信號產生了多少次,阻塞標志也是這樣表示的。
因此未決和阻塞標志可以用相同的數據類型sigset_t來儲存,sigset_t稱為信號集,這個類型可以表示每個信號的有效或無效狀態,在阻塞信號集中有效和無效的含義是該信號是否被阻塞,而在未決信號集中有效和無效的含義是該信號是否處于未決狀態。
在Ubuntu的云服務中,sigset_t類型的定義如下:(不同操作系統實現sigset_t的方案可能不同)
#define _SIGSET_NWORDS (1024 / (8 * sizeof (unsigned long int)))
typedef struct {unsigned long int __val[_SIGSET_NWORDS]; // 通常是 64 位整數數組
} sigset_t;
信號集操作函數
sigset_t類型對于每種信號用一個bit表示“有效”或“無效”,至于這個類型內部如何存儲這些bit則依賴于系統的實現,從使用者的角度是不必關心的,使用者只能調用以下函數來操作sigset_t變量,而不應該對它內部數據做任何解釋,比如printf直接打印sigset_t變量是沒有意義的。
#include <signal.h>int sigemptyset(sigset_t *set);int sigfillset(sigset_t *set);int sigaddset(sigset_t *set, int signum);int sigdelset(sigset_t *set, int signum);int sigismember(const sigset_t *set, int signum);
函數解釋:
- sigemptyset函數:初始化set所指向的信號集,使其中所有信號的對應bit清零,表示該信號集不包含任何有效信號。
- sigfillset函數:初始化set所指向的信號集,使其中所有信號的對應bit置位,表示該信號集的有效信號包括系統支持的所有信號。
- sigaddset函數:在set所指向的信號集中添加某種有效信號。
- sigdelset函數:在set所指向的信號集中刪除某種有效信號。
- sigismember函數:判斷在set所指向的信號集中是否包含某種信號,若包含則返回1,不包含則返回0,調用失敗返回-1。
- 注意,在使用sigset_t類型的變量之前,一定要調用sigemptyset或sigfillset做初始化,使信號處于確定的狀態。
- 初始化siggset_t變量之后就可以再調用sigaddset和sigdelset在該信號集中添加或刪除某種有效信號
前四個函數都是調用成功返回0,出錯返回-1,只有最后一個函數包含是返回1,不包含返回0,出錯返回-1。
這幾個函數的作用是修改siggset_t類型,但是它并不能真正的修改block表于pending表。就好比只能修改草稿,但并不會真正影響進程。
sigprocmask 修改block表
調用函數sigprocmask可以讀取或更改進程的信號屏蔽字(阻塞信號集)。
其該函數的函數原型如下:
#include <signal.h>
int sigprocmask(int how, const sigset_t *set, sigset_t *oldset);
返回值:若成功則為0,出錯則為-1.參數說明:
- 如果oset是非空指針,則讀取進程當前的信號屏蔽字通過oset參數傳出。
- 如果set是非空指針,則更改進程的信號屏蔽字,參數how指示如何更改。
- 如果oset和set都是非空指針,則先將原來的信號屏蔽字備份到oset里,然后根據set和how參數更改信號屏蔽字。
假設當前的信號屏蔽字為mask(屏蔽字),下表說明了how參數的可選值以及其各自含義
| 選項 | 含義 |
| SIG_BLOCK | set包含了我們希望添加到當前信號屏蔽字的信號,相當于mask=mask|set |
| SIG_UNBLOCK | set包含了我們希望從當前信號屏蔽字中解除阻塞的信號,相當于mask=mask|~set |
| SIG_SETMASK | 設置當前信號屏蔽字為set所指向的值,相當于mask=set |
如果調用了sigprocmask解除了對當前若干個未決信號的阻塞,則再sigprocmask返回前,至少將其中一個信號遞達。
sigpending 修改pending表
sigpending函數用于讀取當前進程的未決信息集,通過set參數傳出。
函數原型如下:
#include <signal.h>
int sigpending(sigset_t *set);
返回值:調用成功返回0,出錯返回-1。?下面我們來用剛學的幾個函數做一個簡單的實驗
實驗步驟如下:
- 先定義兩個siggset_t變量。然后進行初始化。
- 對將SIGINT信號添加為有效信號。
- 設置阻塞信號集,阻塞信號SIGINT信號。
- 使用kill命令或組合按鍵向進程發送2號信號。
- 此時2號信號會一直被阻塞,并一直處于pending(未決)狀態。
- 使用sigpending函數獲取當前進程的pending信號集進行驗證。
代碼如下:
#include <stdio.h>
#include <unistd.h>
#include <signal.h>void printPending(sigset_t *pending)
{int i = 1;for (i = 1; i <= 31; i++){if (sigismember(pending, i)){printf("1 ");}else{printf("0 ");}}printf("\n");
}
int main()
{sigset_t set, oset;sigemptyset(&set);sigemptyset(&oset);sigaddset(&set, 2); //SIGINTsigprocmask(SIG_SETMASK, &set, &oset); //阻塞2號信號sigset_t pending;sigemptyset(&pending);while (1){sigpending(&pending); //獲取pendingprintPending(&pending); //打印pending位圖(1表示未決)sleep(1);}return 0;
}可以看到,程序剛開始運行的時候因為沒有收到任何信號,所以此時的pending表一直全為0,我們使用kill命令向該進程發送2號信號后,由于2號信號是阻塞的,因此2號信號一直處于未決狀態,所以我們看到pending表中的第二個數字一直是1。
捕捉信號
想要深入了解信號的捕捉,那么就需要了解進程地址空間。進程地址空間是操作系統為每個運行中的進程分配的虛擬內存范圍,它是進程視角中的線性或結構化內存視圖。除此之外,最終要的是:進程地址空間由內核空間與用戶空間組成。
內核空間與用戶空間
- 用戶空間是供進程直接使用的內存區域,存放進程的代碼、數據、堆、棧等的空間。
- 內核空間是用于供操作系統內核運行,管理硬件、進程調度、內存映射等核心功能的空間。
說到此,就又回到我們的老圖了,就是如圖:
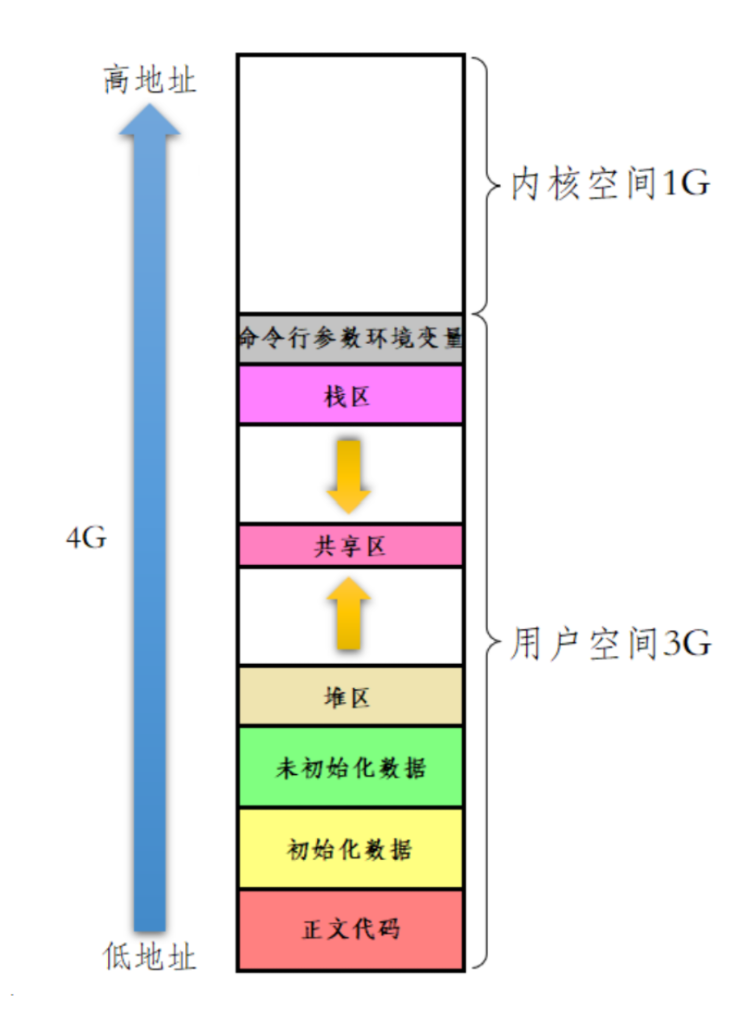
?如圖就是進程地址空間的分布圖(典型地址布局(以32位系統為例)
-
用戶空間:
0x00000000?~?0xBFFFFFFF(3GB)-
進程獨享,通過頁表映射到物理內存或交換區。
-
-
內核空間:
0xC0000000?~?0xFFFFFFFF(1GB)-
所有進程共享,直接映射物理內存。
-
在以前的學習中我們只是以用戶級頁表來學習的,但實際上,還存在內核級頁表。
內核級頁表是一個全局的頁表,它用來維護操作系統的代碼與進程之間的關系,因此在理論上,操作系統只需要維護一個內核級頁表就可以,對于不同的進程地址空間都可以共用這一張內核級頁表用于映射?內核空間。但在在每個進程的進程地址空間中,用戶空間是獨立屬于當前進程,每個進程看到的代碼和數據是完全不同的,所以對于每一個進程,操作系統需要對每一個進程都需要獨立維護一個用戶級頁表。
注意:雖然所有進程的地址空間中都有內核空間的映射(即能“看到”操作系統),但用戶態進程無法直接訪問或修改內核空間的內容,必須通過嚴格的權限控制機制(如系統調用)才能間接訪問。
?進程切換時
因為用戶級頁表(每個進程獨立),但內核級頁表(全局共享)?。
所以當CPU切換到另一個進程時,對于用戶級頁表,會加載該進程的頁表(通過CR3寄存器更新),從而切換用戶空間視圖。內核空間的頁表部分?保持不變(僅用戶空間頁表切換)。
為什么這樣設計?
-
效率:內核代碼只需加載到物理內存一次,所有進程共享,避免重復映射。
-
安全性:用戶進程無法直接修改內核頁表或訪問其他進程的用戶空間。
-
一致性:內核管理的全局資源(如進程列表、文件系統緩存)對所有進程可見。
這里簡單補充一下,以為下面提出用戶態,內核態做一下引子。
注意:?當你訪問用戶空間時你必須處于用戶態,當你訪問內核空間時你必須處于內核態。
?內核態與用戶態
一句話總結:
-
用戶態(User Mode):普通程序運行的狀態,權限低,不能直接訪問硬件或內核內存。
-
內核態(Kernel Mode):操作系統內核運行的狀態,權限高,可以執行任何操作(管理硬件、修改內存等)。
通俗類比:
-
用戶態?→ 像普通游客在動物園:
-
只能看動物(用API),不能摸(不能直接操作硬件)。
-
需要喂食?得找管理員(系統調用)。
-
-
內核態?→ 像動物園管理員:
-
能打開籠子(操作硬件)、調配資源(管理內存)。
-
對操作系統來說,當操作系統接受到信號的時候,并不是立刻處理信號的,而是在其適合的時候,適合的時候是指內核態與用戶態的切換。
內核態和用戶態之間是進行如何切換的?
?操作系統在?用戶態(User Mode)?和?內核態(Kernel Mode)?之間的切換是通過?硬件機制(CPU指令)?和?操作系統協作?完成的。
| 切換方向 | 觸發方式 | CPU 行為 | 關鍵指令 |
|---|---|---|---|
| 用戶態 → 內核態 | 系統調用 / 中斷 / 異常 | 保存上下文 → 提權 → 跳轉內核代碼 | syscall?/?int 0x80 |
| 內核態 → 用戶態 | 系統調用返回 / 中斷返回 | 恢復上下文 → 降權 → 返回用戶代碼 | iret?/?sysexit |
由用戶態轉為內核態的過程稱為‘陷入內核’(Trap)。其本質就是:當用戶程序需要執行高特權操作(如硬件訪問或內存管理)時,由于用戶態權限不足,必須通過‘陷入內核’機制,讓操作系統內核代為完成。
例如,用戶程序調用?open()?或?write()?等函數時,表面上使用的是封裝好的接口,但實際執行的是內核中的?sys_open()?和?sys_write()。用戶程序在理論上是無法直接調用這些內核函數,必須通過系統調用觸發陷入內核,由內核完成實際操作后,再將結果返回用戶態。
內核如何實現信號的捕捉
當我們在執行主控制流程的時候,可能因為某些情況而陷入內核,當內核處理完畢準備返回用戶態時,就需要進行信號pending的檢查。(此時仍處于內核態,有權力查看當前進程的pending位圖)。
在查看pending位圖時,如果發現有未決信號,并且該信號沒有被阻塞,那么此時就需要該信號進行處理。
如果待處理信號的處理動作是默認或者忽略,則執行該信號的處理動作后清除對應的pending標志位,如果沒有新的信號要遞達,就直接返回用戶態,從主控制流程中上次被中斷的地方繼續向下執行即可。
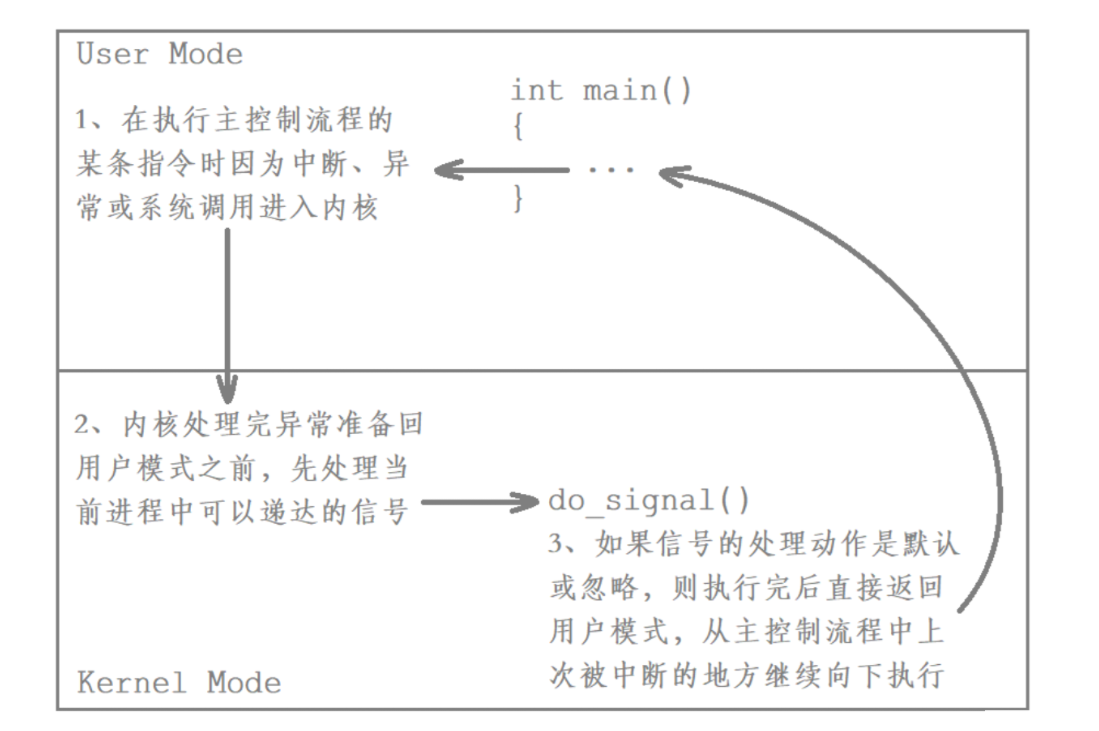
如果信號的處理動作是用戶自定義函數,在信號遞達時就調用這個函數,這稱為捕捉信號。即該信號的處理動作是由用戶提供的,那么處理該信號時就需要先返回用戶態執行對應的自定義處理動作,執行完后再通過特殊的系統調用sigreturn再次陷入內核并清除對應的pending標志位,如果沒有新的信號要遞達,就直接返回用戶態,繼續執行主控制流程的代碼。
舉例如下: 用戶程序注冊了SIGQUIT信號的處理函數sighandler。 當前正在執行 main函數,這時發生中斷或異常切換到內核態。 在中斷處理完畢后要返回用戶態的main函數之前檢查到有信號 SIGQUIT遞達。 內核決定返回用戶態后不是恢復main函數的上下文繼續執行,而是執行sighandler函 數,sighandler 和main函數使用不同的堆棧空間,它們之間不存在調用和被調用的關系,是 兩個獨立的控制流程。 sighandler函數返 回后自動執行特殊的系統調用sigreturn再次進入內核態。 如果沒有新的信號要遞達,這次再返回用戶態就是恢復 main函數的上下文繼續執行了。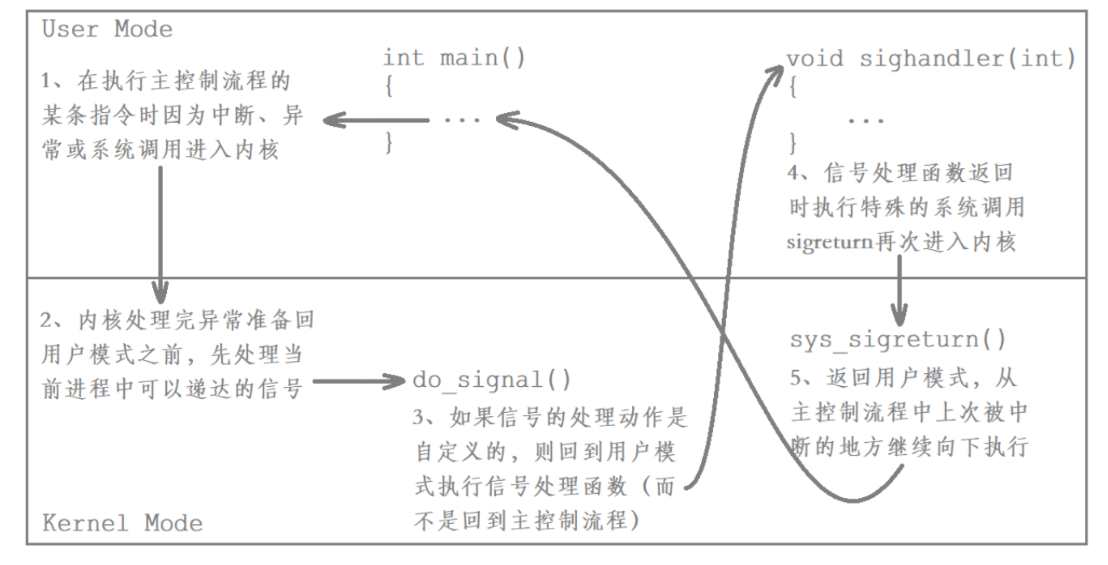
?那么這樣記憶還是太麻煩了,有沒有更簡單的記憶方法?
有的,有的。
巧記
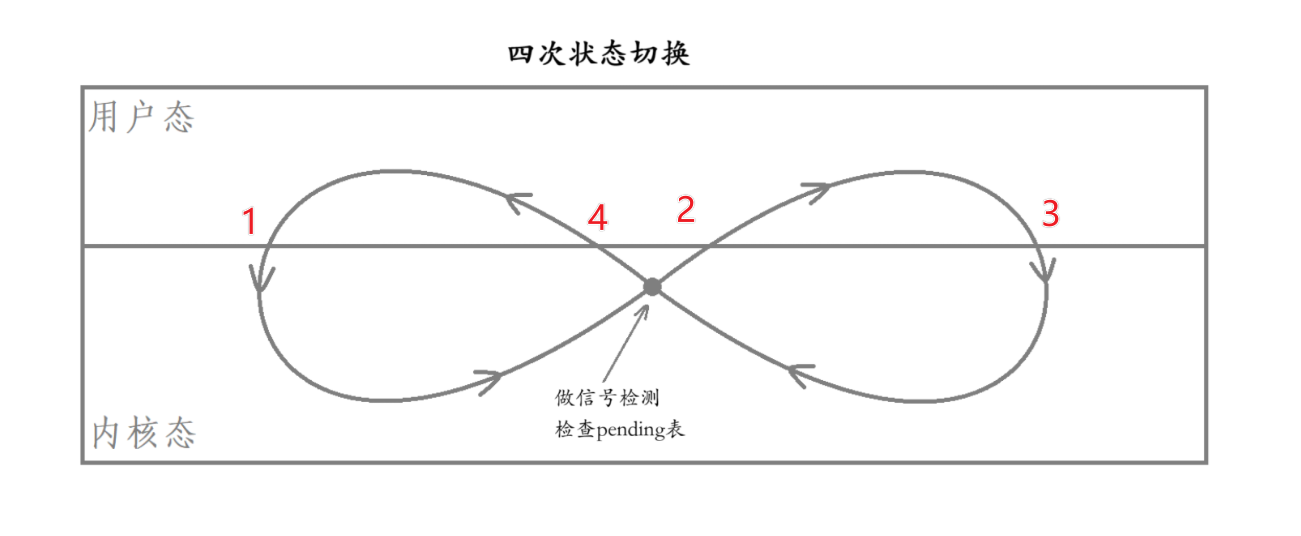
其中,改圖與中間的直線有幾個交線,那么就有幾次內核態與用戶態的切換次數。而箭頭就代表狀態切換的方向。園點就代表著信號檢測,注意此時還在內核態。?
這樣的設計,就保證了效率,安全性,一致性。
sigaction
該函數與我們一開始用到的signal函數都是用與信號的捕捉,但signal()?因為存在局限性,signal()?比如在信號處理函數執行時,會自動重置信號處理方式為默認行為(如?SIGINT?重置后再次觸發會直接終止進程)。后果:若信號頻繁觸發(如快速按下 Ctrl+C),可能導致信號丟失或進程意外終止。除此之外,不同的系統對于其是實現也有不同,所以可移植性也存在問題。
所以就有了更優的函數sigaction。
其函數原型如下:
#include <signal.h>
int sigaction(int signo, const struct sigaction *act, struct sigaction *oact);sigaction函數可以讀取和修改與指定信號相關聯的處理動作,該函數調用成功返回0,出錯返回-1。
參數說明:
- signo代表指定信號的編號。
- 若act指針非空,則根據act修改該信號的處理動作。其為輸入型參數。
- 若oact指針非空,則通過oact傳出該信號原來的處理動作。其為輸出型參數。
- act與oact都是指向sigaction結構體。
其結構體原型如下:
struct sigaction {void (*sa_handler)(int); // 簡單信號處理函數(類似 signal())1-31void (*sa_sigaction)(int, siginfo_t *, void *); // 實時信號處理函數 34-64sigset_t sa_mask; // 信號處理期間阻塞的信號集int sa_flags; // 控制信號行為的標志位void (*sa_restorer)(void); // 已廢棄,勿用
};- 其中結構體中sa_handler,將sa_handler賦值為常數SIG_IGN傳給sigaction表示忽略信號,賦值為常數SIG_DFL表示執行系統默認動 作,賦值為一個函數指針表示用自定義函數捕捉信號,或者說向內核注冊了一個信號處理函 數,該函數返回 值為void,可以帶一個int參數,通過參數可以得知當前信號的編號,這樣就可以用同一個函數處理多種信 號。顯然,這也是一個回調函數,不是被main函數調用,而是被系統所調用。?
- 當某個信號的處理函數被調用時,內核自動將當前信號加入進程的信號屏蔽字,當信號處理函數返回時自動恢復原來的信號屏蔽字,這樣就保證了在處理某個信號時,如果這種信號再次產生,那么 它會被阻塞到當前處理結束為止。這樣的目的是:防止同一信號嵌套觸發導致處理函數重入(即函數未執行完又被調用),引發競態條件或資源沖突。
- pending表是什么時候從1 --> 0呢?是在執行信號捕捉之前,就先清0,然后再調用方法信號被處理時,此時還會將對應就會內核自動將當前信號加入進程的信號屏蔽字。最后處理完后恢復。并不是處理完后才清0,而是先清0,再處理。
- 如果在調用信號處理函數時,除了當前信號被自動屏蔽之外,還希望自動屏蔽另外一些信號,則用sa_mask字段說明這些需 要額外屏蔽的信號,當信號處理函數返回時自動恢復原來的信號屏蔽字。這樣的含義是:防止其他信號干擾當前信號的處理過程。
sa_flags字段包含一些選項,大部分都是將sa_flags設為0,sa_sigaction是實時信號的處理函數。本篇文章不詳細解釋這兩個字段。
下面簡單給一個使用案例:
代碼實現了一個信號處理程序:主進程循環打印自身PID,當捕獲到信號2(SIGINT,通常是Ctrl+C)時,會觸發handler函數,持續打印當前未決信號狀態(1-31號信號的阻塞情況),直到手動終止進程。同時屏蔽了信號1、3、4的干擾。
#include <iostream>
#include <cstring>
#include <ctime>
#include <unistd.h>
#include <signal.h>
#include <sys/types.h>
#include <sys/wait.h>using namespace std;void PrintPending()
{sigset_t set;sigpending(&set);for (int signo = 1; signo <= 31; signo++){if (sigismember(&set, signo))cout << "1";elsecout << "0";}cout << "\n";
}void handler(int signo)
{cout << "catch a signal, signal number : " << signo << endl;while (true){PrintPending();sleep(1);}
}int main()
{// act: 用于設置新的信號處理動作。// oact: 用于保存原來的信號處理動作。struct sigaction act, oact;// 將 act 和 oact 的所有字段初始化為 0,以確保沒有意外的垃圾數據。memset(&act, 0, sizeof(act));memset(&oact, 0, sizeof(oact));// 初始化 act.sa_mask,表示在信號處理期間不屏蔽任何信號。sigemptyset(&act.sa_mask);// 將信號 1、3 和 4 添加到 act.sa_mask 中。// 這些信號在處理信號 2 的過程中會被阻塞,避免它們干擾當前信號的處理。sigaddset(&act.sa_mask, 1);// 設置block表sigaddset(&act.sa_mask, 3);sigaddset(&act.sa_mask, 4);// 指定處理信號 2 的動作。act.sa_handler = handler; // SIG_IGN SIG_DFL 設置捕捉動作函數sigaction(2, &act, &oact);while (true){cout << "I am a process: " << getpid() << endl;sleep(1);}return 0;
}效果運行如下:?

可重入函數
這一部分內容,我們還是要從鏈表部分來解釋,下面給出一個代碼。
我么做的操作上是在主函數上調用insert函數向鏈表中插入節點node1,然后設計一個信號處理函數sighandler,然后該函數內調用insert。代碼如圖表示,乍一看完全沒有問題。

但這實際上是存在隱藏問題的,下面給大家分析一下這個鏈表
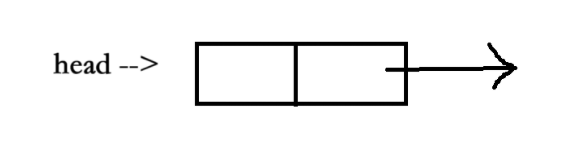
1、首先,main函數中調用了insert函數,想要將node1結點插入鏈表,但其插入分兩步,但剛做完第一步的時候,因為某種原因,發生了硬件中斷使進程切換到內核,再次回到用戶態之前檢查到有信號待處理,于是切換到sighandler函數。
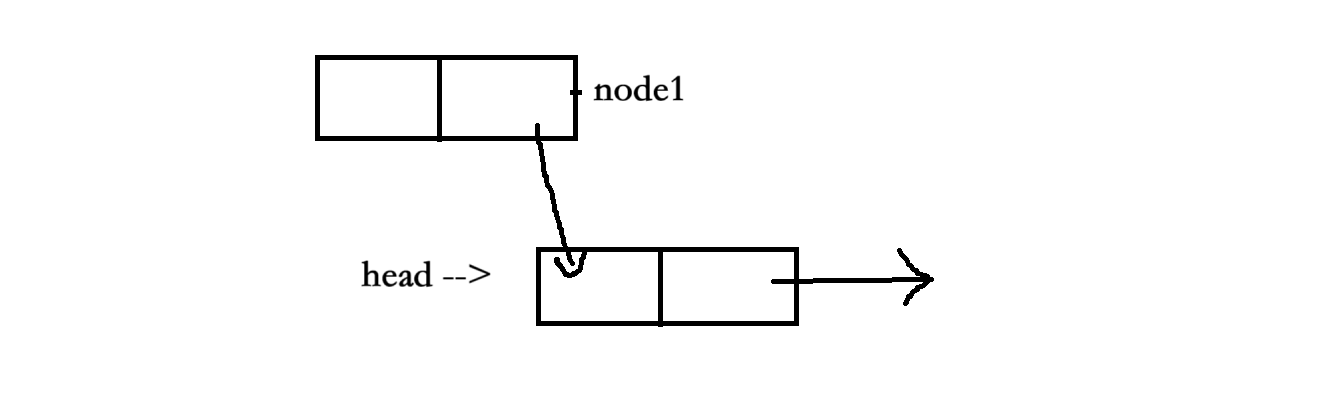
2、而對于?sighandler 也調用了insert函數,將結點node2插入到了鏈表中,插入操作完成第一步后的情況如下:
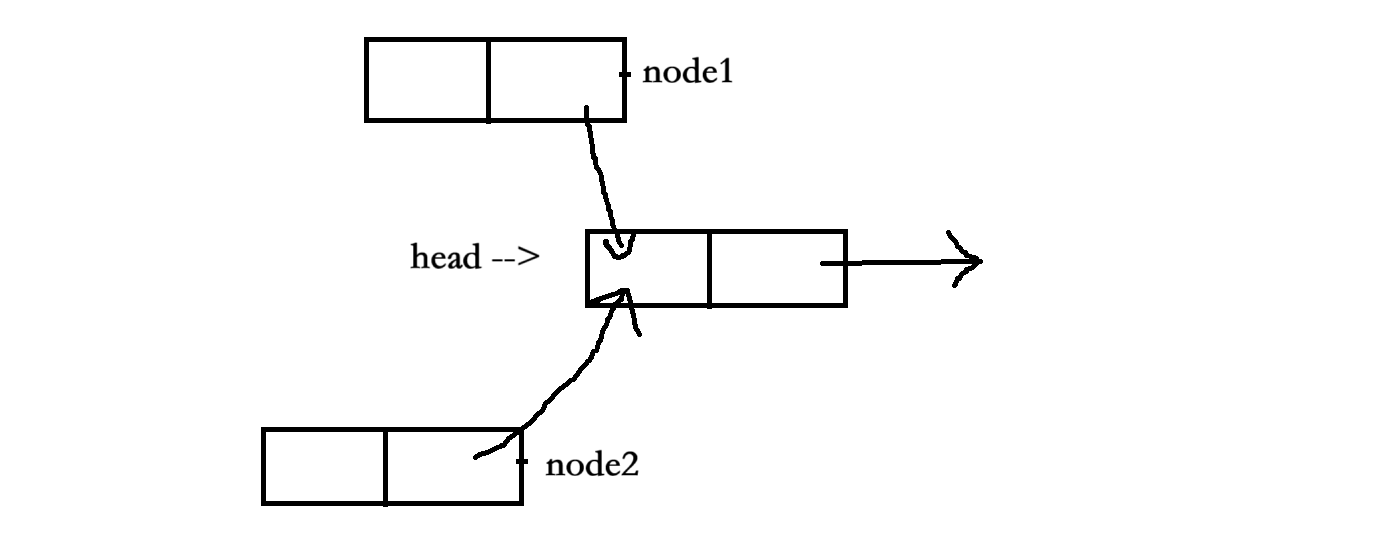
3、當結點node2插入的兩步操作完成后,操作系統就會返回內核態,此時鏈表的布局如下:?
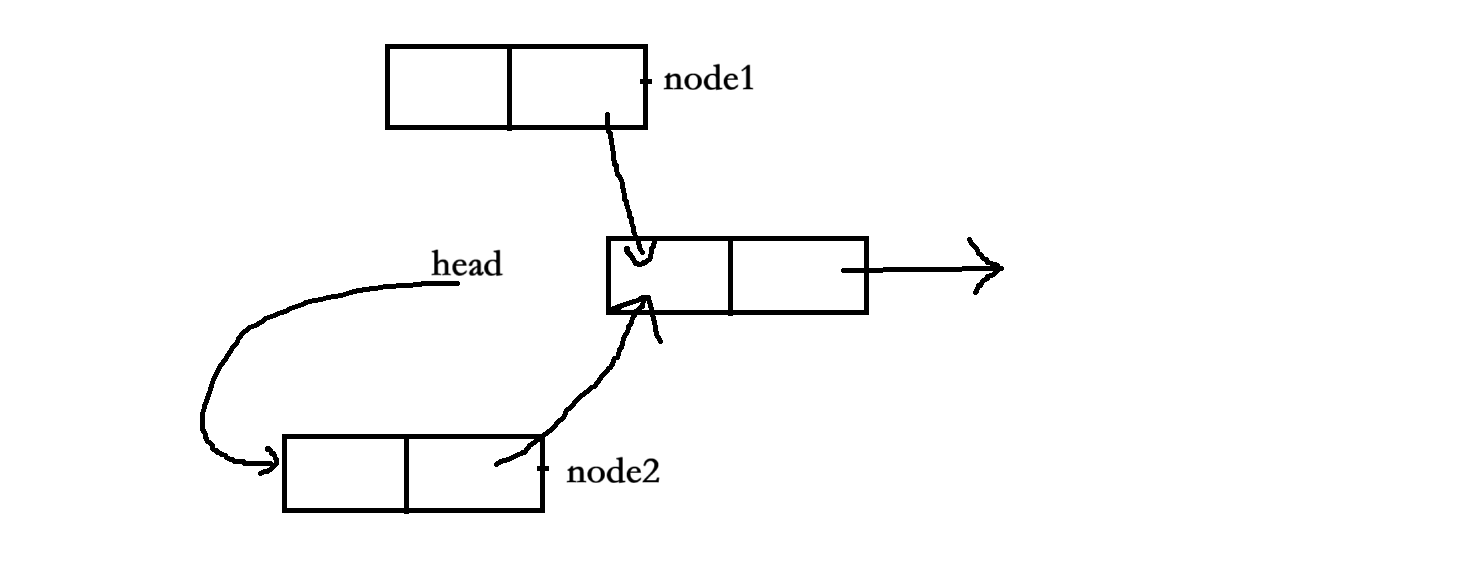
?4、再次回到用戶態就從main函數調用的insert函數中繼續往下執行,即繼續進行結點node1的插入操作。此時鏈表就變為了:
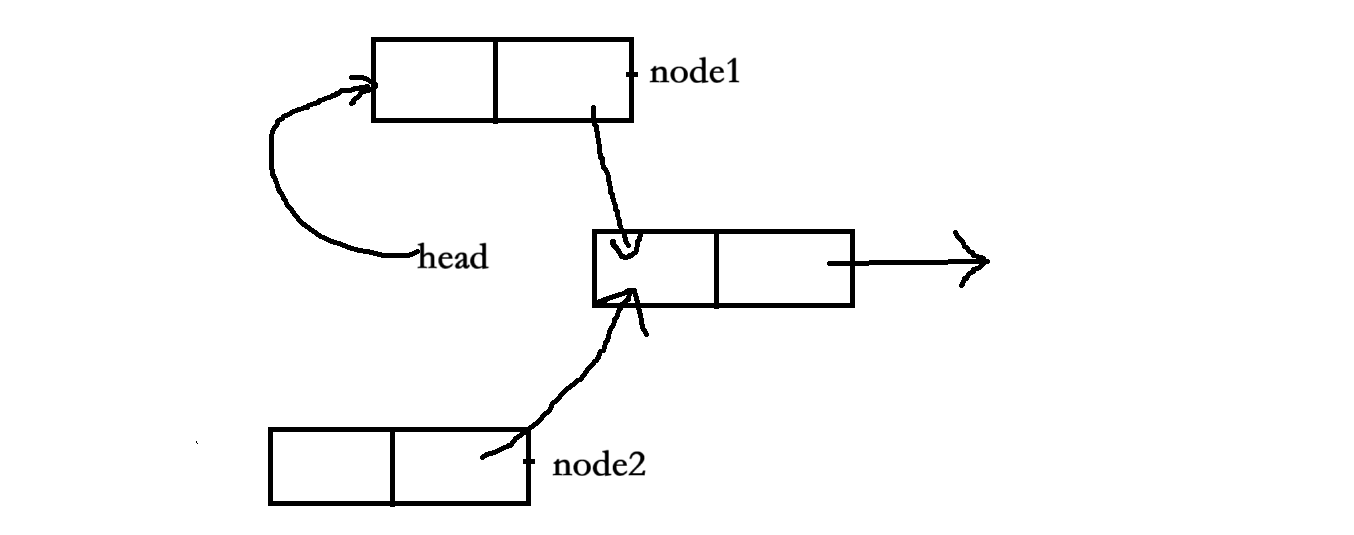
最終結果是,main函數和sighandler函數先后向鏈表中插入了兩個結點,但最后只有node1結點真正插入到了鏈表中,而node2結點就再也找不到了,造成了內存泄漏。
上述例子中,各函數執行的先后順序如下: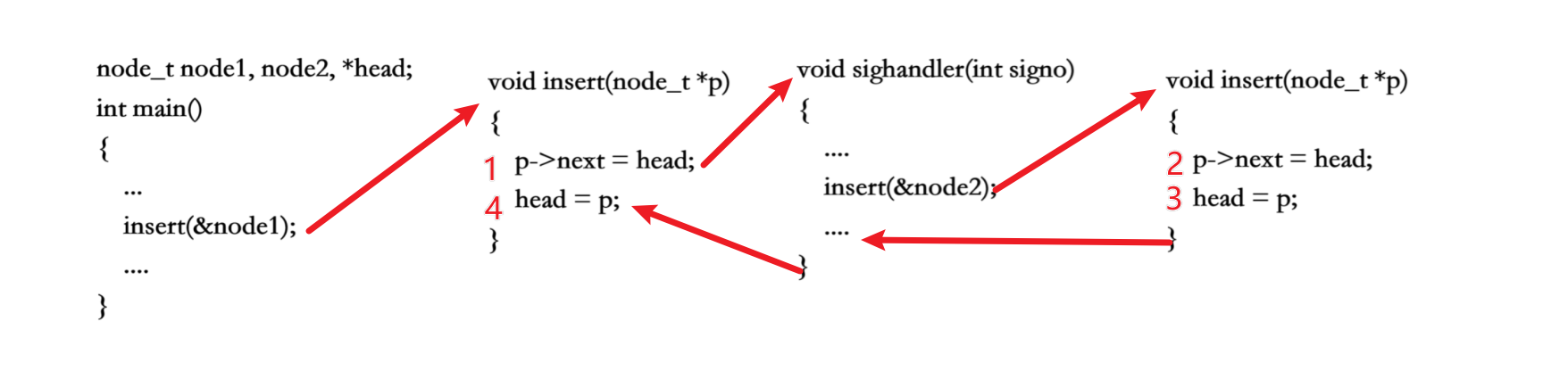 ?像上例這樣,insert函數被不同的控制流程調用,有可能在第一次調用還沒返回時就再次進入該函數,這稱 為重入,insert函數訪問一個全局鏈表,有可能因為重入而造成錯亂,像這樣的函數稱為 不可重入函數,反之, 如果一個函數只訪問自己的局部變量或參數,則稱為可重入(Reentrant) 函數。
?像上例這樣,insert函數被不同的控制流程調用,有可能在第一次調用還沒返回時就再次進入該函數,這稱 為重入,insert函數訪問一個全局鏈表,有可能因為重入而造成錯亂,像這樣的函數稱為 不可重入函數,反之, 如果一個函數只訪問自己的局部變量或參數,則稱為可重入(Reentrant) 函數。
想一下,為什么兩個不同的控制流程調用同一個函數,訪問它的同一個局部變量或參數就不會造成錯亂
?這是因為每次函數調用時,系統會為其分配獨立的棧幀(Stack Frame),局部變量和參數存儲在該棧幀中。
-
不同控制流程(如不同線程或嵌套調用)的棧幀彼此隔離,因此同名局部變量實際占用不同內存地址。
如果一個函數符合以下條件之一則是不可重入的:
- 調用了malloc或free,因為malloc也是用全局鏈表來管理堆的。
- 調用了標志I/O庫函數,因為標準I/O庫的很多實現都以不可重入的方式使用全局數據結構。
?volatile
該關鍵字在C語言當中我們已經有所學習,其作用為:是一個類型修飾符,用于告訴編譯器不要對該變量進行激進的優化(如緩存、重排序等),因為它可能被意外修改(例如由硬件、中斷或另一個線程修改)。
編譯器通常會優化代碼,將頻繁讀取的變量緩存到寄存器中。volatile?強制每次訪問變量時都從內存中重新讀取或寫入,確保數據的實時性。
比如:
volatile int flag = 0;
while (flag == 0); // 編譯器不會優化掉循環,每次都會檢查內存中的 flag今天我們就站在信號的角度來理解一下。
在下面的代碼中,我們對2號信號進行了捕捉,當該進程收到2號信號時會將全局變量flag由0置1。也就是說,在進程收到2號信號之前,該進程會一直處于死循環狀態,直到收到2號信號時將flag置1才能夠正常退出。
#include <stdio.h>
#include <signal.h>int flag = 0;void handler(int signo)
{printf("get a signal:%d\n", signo);flag = 1;
}
int main()
{signal(2, handler);while (!flag);printf("process quit normal!\n");return 0;
}
標準情況下,鍵入Ctrl + C ,2號信號被捕捉,執行自定義動作,修改flag=1,while條件不滿足,退出循環,進程退出。
 ?該程序的運行過程好像都在我們的意料之中,但事實并非如此。可能會想到,代碼中的main函數和handler函數是兩個獨立的執行流,而while循環是在main函數當中的,在編譯器編譯時只能檢測到在main函數中對flag變量的使用。
?該程序的運行過程好像都在我們的意料之中,但事實并非如此。可能會想到,代碼中的main函數和handler函數是兩個獨立的執行流,而while循環是在main函數當中的,在編譯器編譯時只能檢測到在main函數中對flag變量的使用。
此時編譯器檢測到在main函數中并沒有對flag變量做修改操作,在編譯器優化級別較高的時候。
此優化情況下,鍵入CTRL-C ,2號信號被捕捉,執行自定義動作,修改flag=1,但是while條件依舊滿足,進 程繼續運行!但是很明顯flag肯定已經被修改了,但是為何循環依舊執行?很明顯,while循環檢查的flag, 并不是內存中最新的flag,這就存在了數據二異性的問題。while檢測的flag其實已經因為優化,被放在了 CPU寄存器當中。
在編譯代碼時攜帶-O3選項使得編譯器的優化級別最高,此時再運行該代碼,就算向進程發生2號信號,該進程也不會終止。
g++ -03 -o proc proc.cc // 注意是數字03,不要搞為字母O + 3
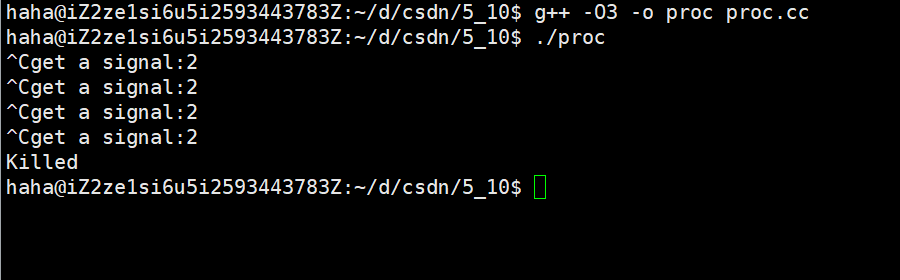
這里我在測試的時候遇見了一個小問題,按道理效果應該如上如,但是第一次學習的時候用的別的環境測試的Centos7,第二次用的是Ubuntu,第三次是換了個Ubuntu。同樣的代碼,前兩次沒問題,但第三次出現了小問題,并不是正確的運行結果,是直接打印process quit normal,然后我就猜測與實驗,然后發現在while后面添加一個調用cout就可以了,目前也不知道為什么。應該是有什么bug之類的。?
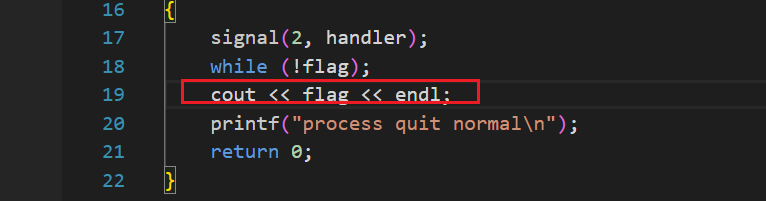
面對這種情況,我們就可以使用volatile關鍵字對flag變量進行修飾,告知編譯器,對flag變量的任何操作都必須真實的在內存中進行,即保持了內存的可見性。
volatile int flag = 0;
此時就算我們編譯代碼時攜帶-O3選項,當進程收到2號信號將內存中的flag變量置1時,main函數執行流也能夠檢測到內存中flag變量的變化,進而跳出死循環正常退出。

總結:
volatile作用:保持內存的可見性,告知編譯器,被該關鍵字修飾的變量,不允許被優化,對該變量 的任何操作,都必須在真實的內存中進行操作


 查詢優化詳解!)
















