文章目錄
- 1、環境變量
- 基本概念
- 常見環境變量
- 查看環境變量方法
- 測試 PATH
- 測試 HOME
- 和環境變量相關的命令
- 環境變量的組織方式<p align="center">
- main 函數的三個參數
- 通過代碼獲得環境變量
- 通過系統調用獲取環境變量
- 環境變量通常是具有全局屬性的
- 2、程序地址空間
- 2.1 驗證程序地址空間的排布
- 2.2 驗證堆和棧增長方向的問題
- 2.3 如何理解 static 變量<p align="center">
- 2.4 感知虛擬地址空間的存在
- 3、進程地址空間
- 分頁 & 虛擬地址空間
- 4、Linux2.6 內核進程調度隊列 - (理解即可)<p align="center">
- 一個 CPU 擁有一個 runqueue
- 優先級
- 活動隊列
- 過期隊列
- active 指針和 expired 指針
1、環境變量
??我們都清楚自己寫的一串代碼,經過編譯后生成可執行程序,我們用./即可運行,但是系統里有些命令也是64位的可執行程序:

- 既然都是程序,那就可以把你自己的寫的程序叫做指令,把系統的指令叫做命令程序 or 二進制文件。所以
自己寫的程序和系統中的指令沒區別,均可以稱為指令、工具、可執行程序。
??但是系統里的命令(ls、pwd……)可以直接用,既然你自己寫的可執行程序myproc也是命令,那為什么不能像系統中的那樣直接使用呢?反而要加上./才能運行。
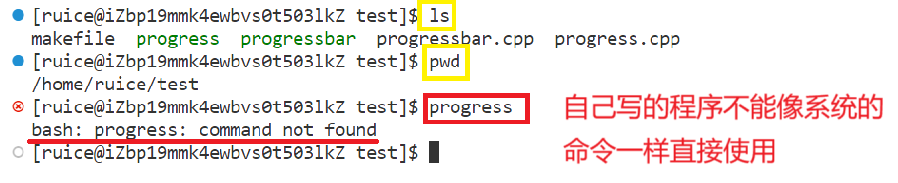
- 注意看這里的報錯:command not found,就是說執行一個可執行程序,前提是要先找到它,這也就說明了系統的命令能找到它,自己寫的程序卻找不到它。
??原因:linux系統中存在相關的環境變量,保留了程序的搜索路徑的! 所以出現上面的情況。下面就來具體講解環境變量。
基本概念
??環境變量 (environment variables) 一般是指在操作系統中用來指定操作系統運行環境的一些參數。
- 如在編寫 C/C++ 代碼鏈接時,雖不知動態靜態庫位置,但能鏈接成功生成可執行程序,就是因為有相關環境變量幫助編譯器查找。
??環境變量通常具有某些特殊用途,且在系統當中通常具有全局特性。
常見環境變量
輸入指令env能夠查看所有環境變量,常見的環境變量如下:
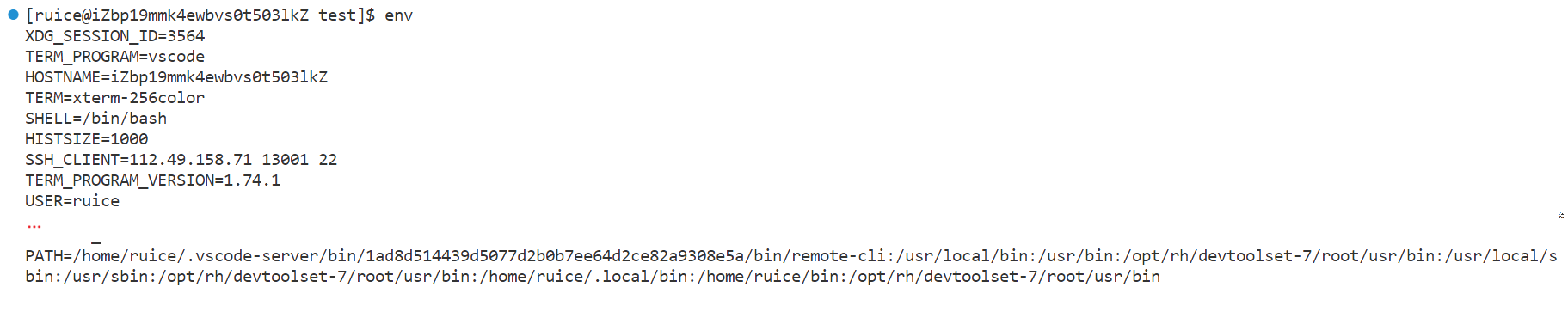
不過常見的如下:
- PATH:系統中搜索可執行程序(命令)的環境變量
- HOME:指定用戶的家目錄 (即用戶登陸到 Linux 系統中時,默認的目錄)
- SHELL:當前 Shell, 它的值通常是 /bin/bash。
如下查看系統中的PATH命令:

查看環境變量方法
??通過echo命令來查看環境變量,指令格式為:
echo $NAME //NAME:你的環境變量名稱
??以查看具體的PATH環境變量為例:

??注意這里的路徑分隔符是用:間隔的,當輸入ls指令時,系統會在這些路徑里面逐個尋找,找到后就執行特定路徑下的ls 。這也就解釋了自己寫的myproc程序不在此路徑中,所以不能直接使用的原因。
測試 PATH
??以mypro文件為例,自己寫的可執行程序myproc不能像系統的命令一樣直接使用,如果想要讓myproc像系統中的命令一樣使用,有如下兩種方法:

??根據我們前面的分析得知,我們不能讓自己寫的可執行程序myproc像系統的命令一樣直接使用:
??如果要讓自己寫的myproc像系統中的命令樣使用,有如下兩種方法:
- 1、手動添加到系統路徑/usr/bin/里頭
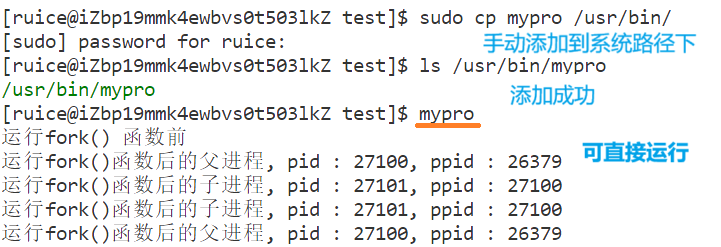
??但是并不建議把你自己寫的可執行程序隨意添加到系統里頭(會污染),所以執行下面的命令刪除即可:
sudo rm /usr/bin/mypro
2、使用export命令把myproc當前所處的路徑也添加到PATH環境變量里,Linux命令行也是可以定義變量的,分為兩種:
??1.本地變量 (不加export定義的就是本地變量,可以通過set命令查看本地變量,也可以查看環境變量:)
??2.環境變量(全局屬性,我們使用export可以導出環境變量,使用env顯示環境變量:)
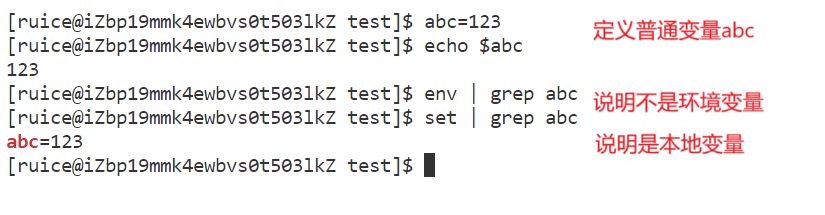
??如果我們在變量前面加上export,這就是導出環境變量:

下面演示把myproc的路徑導入PATH里頭,輸入下面的命令:
PATH=$PATH:/home/ruice/test

該命令是把所有的PATH環境變量內容提取出來放到PATH里,并在后面追加mypro的當前路徑。添加后就可以像命令一樣直接使用myproc,
若想刪除該環境變量,執行unset命令。

測試 HOME
任何一個用戶在運行系統登錄時都有自己的主工作目錄(家目錄),環境變量HOME保存的就是該用戶的主工作目錄。
普通用戶示例:

root超級用戶示例:

和環境變量相關的命令
- 1、echo:顯示某個環境變量值
- 2、export:設置一個新的環境變量
- 3、env:顯示所有環境變量
- 4、unset:清除環境變量
- 5、set:顯示本地定義的 shell 變量和環境變量
環境變量的組織方式
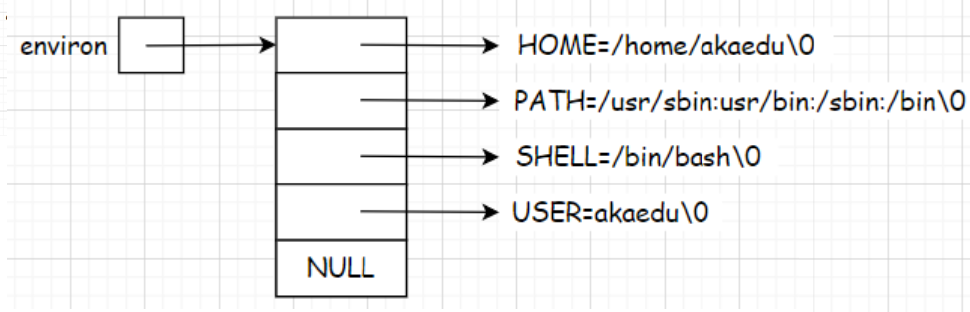
??每個程序都會收到一張環境表,環境表是一個字符指針數組,每個指針指向一個以’\0’結尾的環境字符串。
main 函數的三個參數
??main函數可以帶 3 個參數,其形式為:int main(int argc, char* argv[], char* envp[]) ,其中:
int main(int argc, char* argv[], char* envp[])
{return 0;
}
int argc : 指針數組中元素的個數,代表命令行參數的數量(包含可執行程序名)。
char* argv[]:指針數組
int argc:數組里的元素個數
通過以下代碼測試前兩個參數:
#include<stdio.h>
#include<unistd.h>int main(int argc, char* argv[])
{for (int i = 0; i < argc; i++){printf("argv[%d]: %s\n", i , argv[i]);}return 0;
}
??運行結果如下:
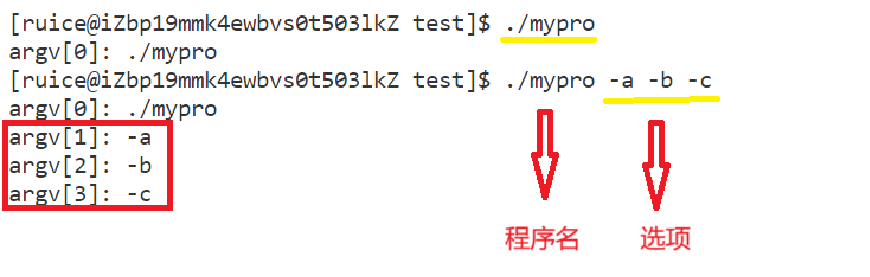
??main函數的第二個參數一個字符指針數組,此時argv數組下標 0 存儲的是命令行的第一個位置(可執行程序),其余字符指針存儲的是命令行對應的選項,main函數的第一個參數argc存儲的是數組元素個數。
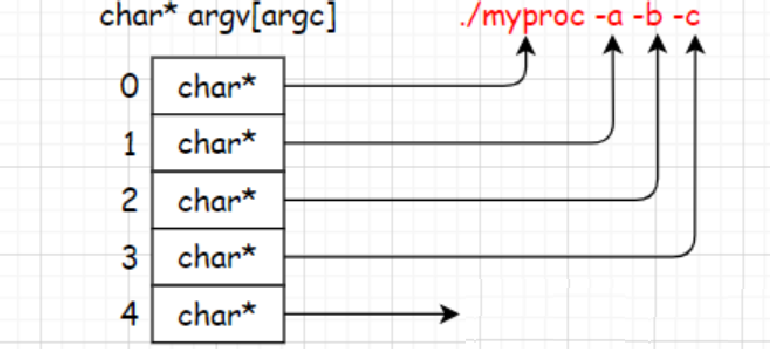
??總結:我們給main函數傳遞的argc,char* argv[ ]是命令行參數,傳遞的內容是命令行中輸入的程序名和選項,并且結尾以NULL結束!!!
問:main函數傳這些參數的意義是什么?
??假設我們現在要實現一個命令行計算器,如果輸出./myproc -a 10 20,那么就是加法10+20=30,如果輸出./myproc -s 10 20,那么就是減法10-20=-10……。代碼如下
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<stdlib.h>int main(int argc, char* argv[])
{if (argc != 4) {printf("Usage: %s [-a|-s|-m|-d first_num second_num",argv[0]);return 0;}int x = atoi(argv[2]);int y = atoi(argv[3]);if (strcmp("-a", argv[1]) == 0){printf ("%d + %d = %d\n", x, y, x + y);}else if (strcmp("-s", argv[1]) == 0){printf ("%d - %d = %d\n", x, y, x - y);}else if (strcmp("-m", argv[1]) == 0){printf ("%d * %d = %d\n", x, y, x * y);}else if (strcmp("-d", argv[1]) == 0){printf ("%d / %d = %d\n", x, y, x / y);}else {printf("Usage: %s [-a|-s|-m|-d first_num second_num",argv[0]);}return 0;
}
此時我們就可以運行此程序并通過命令行參數來實現我們想要的計算方式:
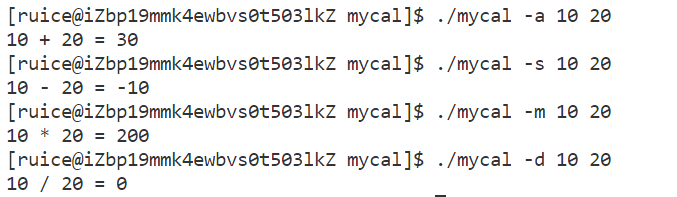
總結:
同一個程序,通過傳遞不同的參數,讓同一個程序有不同的執行邏輯,執行結果。Linux系統中,會根據不同的選項,讓不同的命令,可以有不同的表現,這就是指令中各個選項的由來和起作用的方式!!! 這也就是命令行參數的意義,同樣也就是main函數參數的意義。
下面來談下main函數的第三個參數:
int main(int argc, char* argv[], char* envp[])
{return 0;
}
??char*envp就是環境變量,也是一個字符指針數組,argv指向命令行參數字符串,envp指向一個一個環境變量字符串,最后以NULL結尾。
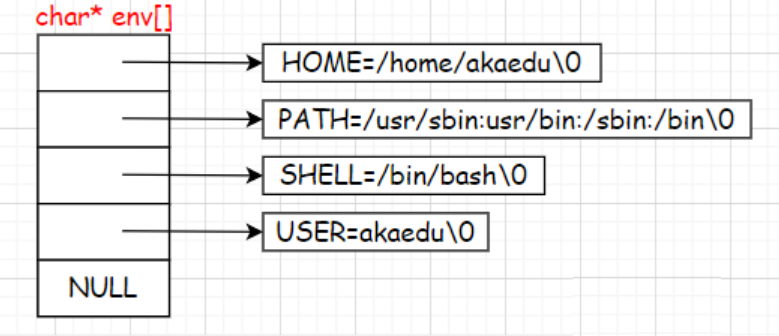
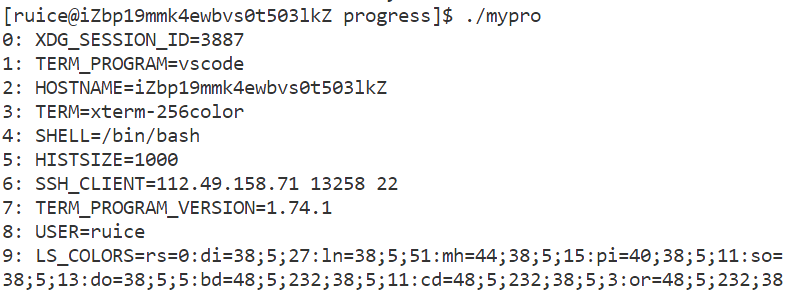
通過以下代碼測試第三個參數:
int main(int argc, char* argv[], char* env[])
{for (int i = 0; env[i]; i++){printf("env[%d]: %s\n", i, env[i]);}return 0;
}
??總結:一個進程是會被傳入環境變量參數的。
補充:一個函數在聲明和定義時無參數,實際傳參時也可以傳參。
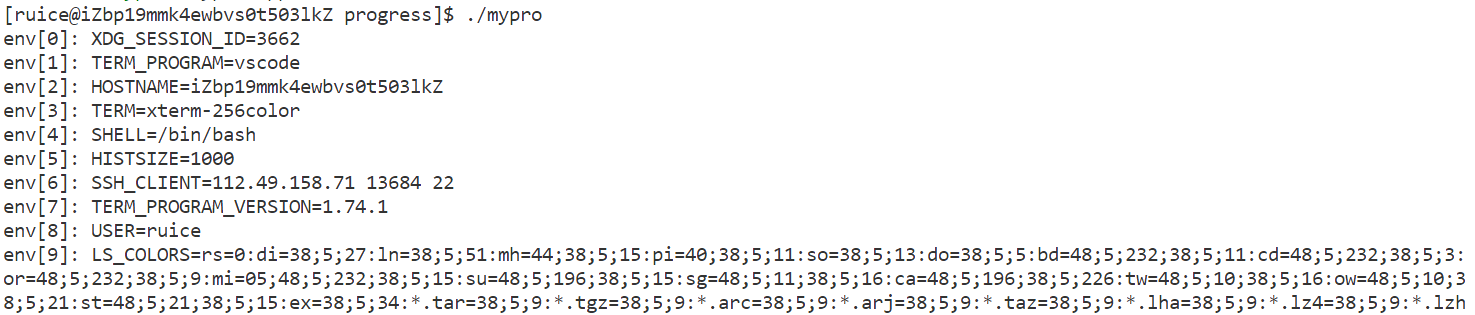
通過代碼獲得環境變量
??可以通過main函數的第三個參數獲得環境變量,也可以通過第三方變量environ獲取。
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<stdlib.h>int main()
{extern char** environ;for (int i = 0; environ[i]; i++) {printf("%d: %s\n", i, environ[i]);}return 0;
}
通過系統調用獲取環境變量
??除了通過main函數的第三個參數和第三方變量environ外,還可通過系統調用getenv函數獲取環境變量,getenv能通過目標環境變量名查找,返回對應的字符指針,從而直接獲得環境變量內容。
#include <stdio.h>
#include <stdlib.h>
int main()
{char* val = getenv("PATH");printf("%s\n", val);return 0;
}

問:我為什么要獲得環境變量?
??例如,假設當前用戶USER為ruice,只允許自己使用,不允許rc訪問,可通過獲取環境變量實現訪問控制。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{char* id = getenv("USER");if (strcmp(id, "ruice") != 0){printf("權限拒絕!\n");return 0;}printf("成功執行!\n");return 0;
}

綜上,環境變量一定在某些地方有特殊用途,上面粗略的展示了其中一個方面。
環境變量通常是具有全局屬性的
??回顧bash進程:
#include<stdio.h>
#include<unistd.h>
int main()
{while (1){printf("hello Linux!,pid: %d, ppid:%d\n", getpid(), getppid());sleep(1); }return 0;
}
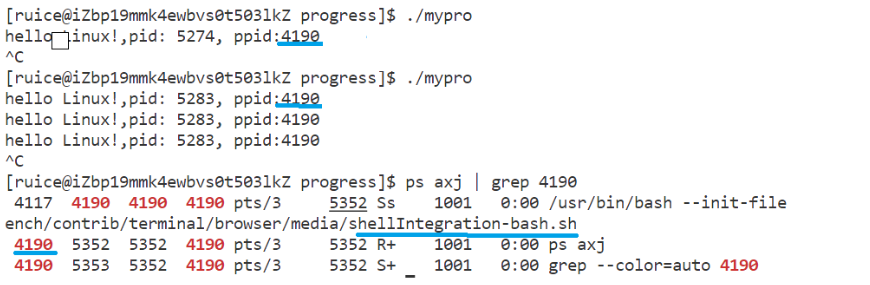
- 子進程pid每次運行結果不斷變化(因進程每次運行都在重啟),但父進程不變(父進程就是bash,是系統創建的命令行解釋器)。
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{while (1){printf("hello Linux!,pid: %d, ppid:%d, myenv=%s\n", getpid(), getppid(),getenv("key"));sleep(1); }return 0;
}
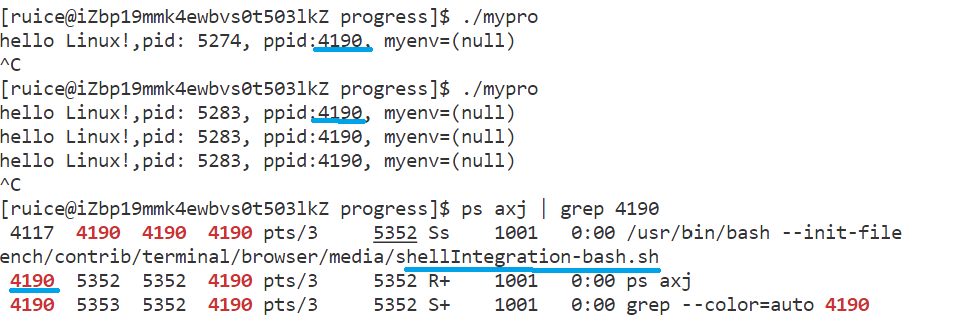
- 如果殺掉bash進程,輸入任何命令都無反應,命令行直接掛掉。正常使用命令行是因為命令本身由bash進程獲取,且命令行中啟動的進程,父進程全都是bash。
下面來理解環境變量具有全局屬性:
看如下代碼:(在原有的pid和ppid基礎上添加了獲取環境變量)
??通過代碼測試發現,進程剛開始不存在環境變量,若在bash進程中導出一個環境變量,子進程運行時就能獲取到該環境變量。

??總結:
- 環境變量會被子進程繼承,若在bash進程中創建export環境變量,該環境變量會從bash位置開始被所有子進程獲取,所以環境變量具有全局屬性;
- 而本地變量在bash內部定義,不會被子進程繼承。
??補充:

??local_val是本地變量,Linux下大部分命令通過子進程方式執行,但還有部分命令由bash自己執行(調用對應函數完成特定功能),這類命令叫內建命令。
2、程序地址空間
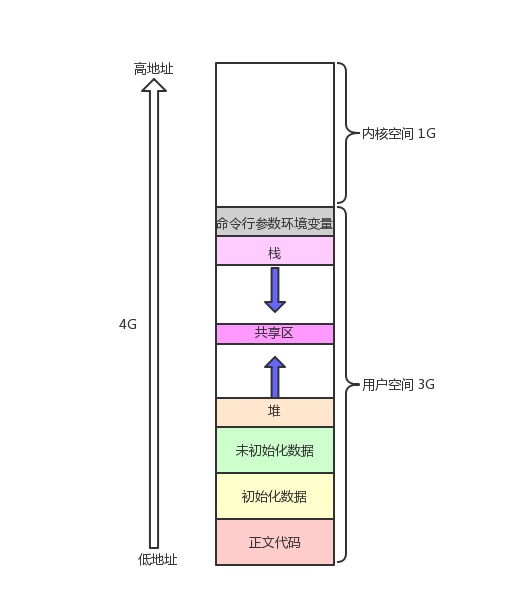
在學習 C 的過程中,常見如下程序地址空間布局圖:
2.1 驗證程序地址空間的排布
- 程序地址空間不是內存,通過以下代碼在linux操作系統中對該布局進行驗證:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int un_g_val;
int g_val = 100;
int main()
{printf("code addr : %p\n", main); //代碼區printf("init global addr : %p\n", &g_val);//已初始化全局數據區地址printf("uninit global addr: %p\n", &un_g_val);//未初始化全局數據區地址char* m1 = (char*)malloc(100);printf("heap addr : %p\n", m1);//堆區printf("stack addr : %p\n", &m1);//棧區for(int i = 0; environ[i]; i++){printf("env addr: %p\n", environ[i]);}return 0;
}
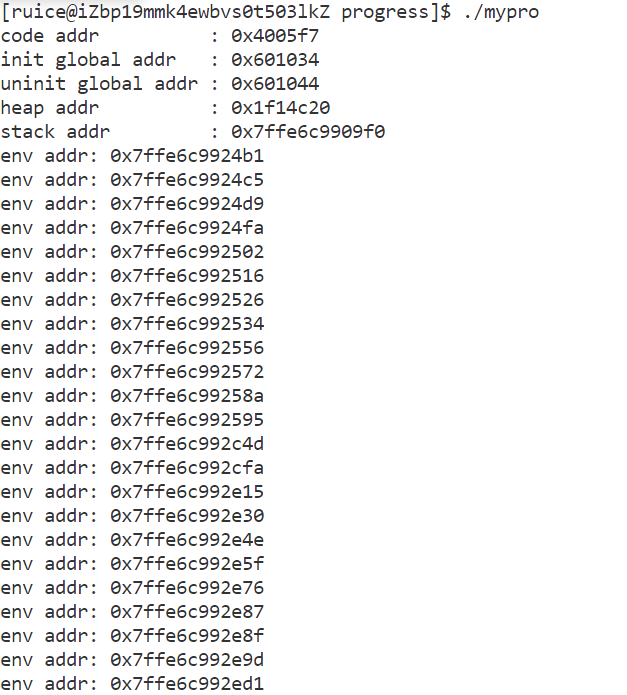
- 運行結果顯示,從上到下地址逐漸增大,且棧區和堆區之間有一塊非常大的鏤空,證實了程序地址空間的布局符合常見布局圖。
2.2 驗證堆和棧增長方向的問題
堆
通過代碼測試,結果表明堆區的確是向上增長。
char* m1 = (char*)malloc(100);char* m2 = (char*)malloc(100);char* m3 = (char*)malloc(100);char* m4 = (char*)malloc(100);printf("heap addr :%p\n", m1);// 堆區printf("heap addr :%p\n", m2);// 堆區printf("heap addr :%p\n", m3);// 堆區

棧
通過代碼測試,從結果可以看出棧區向上減少。
char* m1 = (char*)malloc(100);char* m2 = (char*)malloc(100);char* m3 = (char*)malloc(100);char* m4 = (char*)malloc(100);printf("stack addr :%p\n", &m1);//棧區printf("stack addr :%p\n", &m2);//棧區printf("stack addr :%p\n", &m3);//棧區printf("stack addr :%p\n", &m4);//棧區

總結:
- 堆區向地址增大方向增長(箭頭向上)
- 棧區向地址減少方向增長(箭頭向下)
- 堆,棧相對而生
- 在 C 函數中定義的變量,通常在棧上保存,先定義的變量地址比較高(先定義先入棧,后定義后入棧)。
2.3 如何理解 static 變量
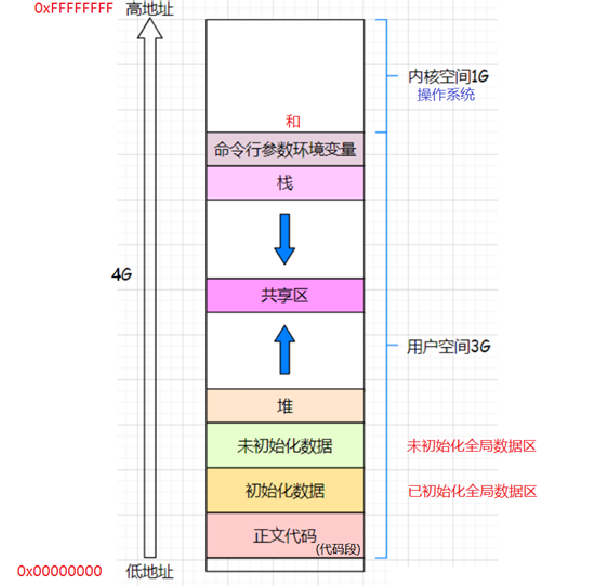
正常定義的變量符合棧的地址分布規則,后定義的變量在地址較低處。而被static修飾的變量,盡管在函數內定義,但已不在棧上,而是變為全局變量,存儲在全局數據區,這就是其生命周期會隨程序一直存在的原因。


總結:函數內定義的變量被static修飾,本質是編譯器會把該變量編譯進全局數據區內。
2.4 感知虛擬地址空間的存在
通過父子進程對全局數據操作的代碼示例:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/types.h>
int un_g_val;
int g_val = 100;
int main()
{pid_t id = fork();if (id == 0){// childwhile (1){printf("我是子進程:%d, ppid:%d, g_val:%d, &g_val:%p\n\n ",getpid(), getppid(), g_val, &g_val);sleep(1);}}else if (id > 0){// childwhile (1){printf("我是父進程:%d, ppid:%d, g_val:%d, &g_val:%p\n\n ",getpid(), getppid(), g_val, &g_val);sleep(1);}}return 0;
}
當父子進程都未修改全局數據時,共享該數據。

當有一方嘗試寫入修改時:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/types.h>
int un_g_val;
int g_val = 100;
int main()
{pid_t id = fork();if (id == 0){int flag = 0;// childwhile (1){printf("我是子進程:%d, ppid:%d, g_val:%d, &g_val:%p\n\n ",getpid(), getppid(), g_val, &g_val);sleep(1);flag++;if (flag == 3){g_val = 200;printf("我是子進程,全局數據我已經修改了,用戶注意參看!!!\n");}}}else if (id > 0){// childwhile (1){printf("我是父進程:%d, ppid:%d, g_val:%d, &g_val:%p\n\n ",getpid(), getppid(), g_val, &g_val);sleep(1);}}return 0;
}
會出現父子進程讀取同一個變量(地址相同),但讀取到的內容卻不一樣的情況。

- 這里父子進程讀取同一個變量(因為地址一樣),但是后續在沒有人修改的情況下,父子進程讀取到的內容卻不一樣!!!怎么會出現子進程和父進程對全局變量的地址是一樣的,但是輸出的內容確是不一樣的呢?
結論:我們在C、C++中使用的地址,絕對不是物理地址。 因為如果是物理地址,上述現象是不可能產生的!!!這種地址我們稱之為虛擬地址、線性地址、邏輯地址!!!
補充:為什么我的操作系統不讓我直接看到物理內存呢?
- 因為不安全,內存就是一個硬件,不能阻攔你訪問!只能被動的進行讀取和寫入。不能直接訪問。
3、進程地址空間
之前所說的‘程序的地址空間’并不準確,準確的說法是進程地址空間。
-
每一個進程在啟動時,操作系統會為其創建一個地址空間,即進程地址空間,
每個進程都有屬于自己的進程地址空間。操作系統管理這些進程地址空間的方式是先描述,再組織,進程地址空間實際上是內核的一個數據結構(struct mm_struct )。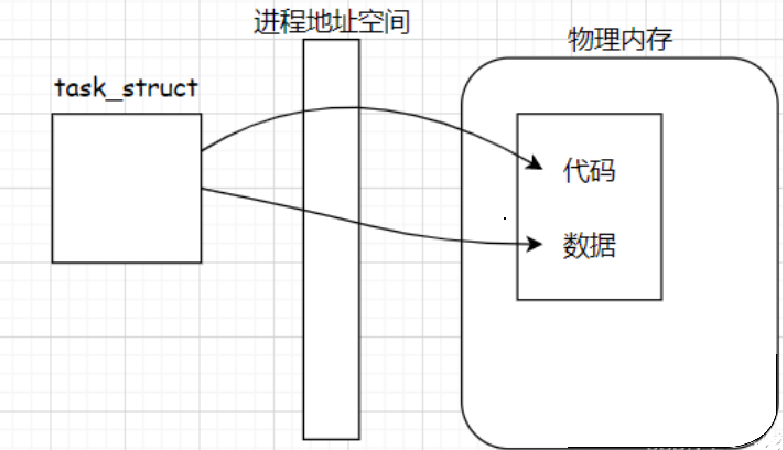
-
進程具有獨立性,體現在相關的數據結構獨立,進程的代碼和數據獨立等方面。可以類比為一位圖書館管理員(相當于操作系統)同時管理三個獨立的書屋(相當于進程)。每個書屋都有自己的書籍(相當于進程的數據和代碼)和管理規則。管理員確保每個書屋獨立運營,每個書屋的書籍和其他資源都只供該書屋使用,不會與其他書屋混用。這樣可以避免書籍混亂,保證每個書屋的獨立性和秩序。
綜上:進程地址空間是OS通過軟件方式,為進程提供一個軟件視角,讓進程認為自己會獨占系統的所有資源(內存)。
分頁 & 虛擬地址空間
在 Linux 內核中,每個進程都有task_struct結構體,該結構體中有個指針指向mm_struct(程序地址空間)。當磁盤上的程序被加載到物理內存時,需要在虛擬地址空間和物理內存之間建立映射關系,這種映射關系由頁表(映射表)完成(操作系統會為每個進程構建一個頁表結構)。
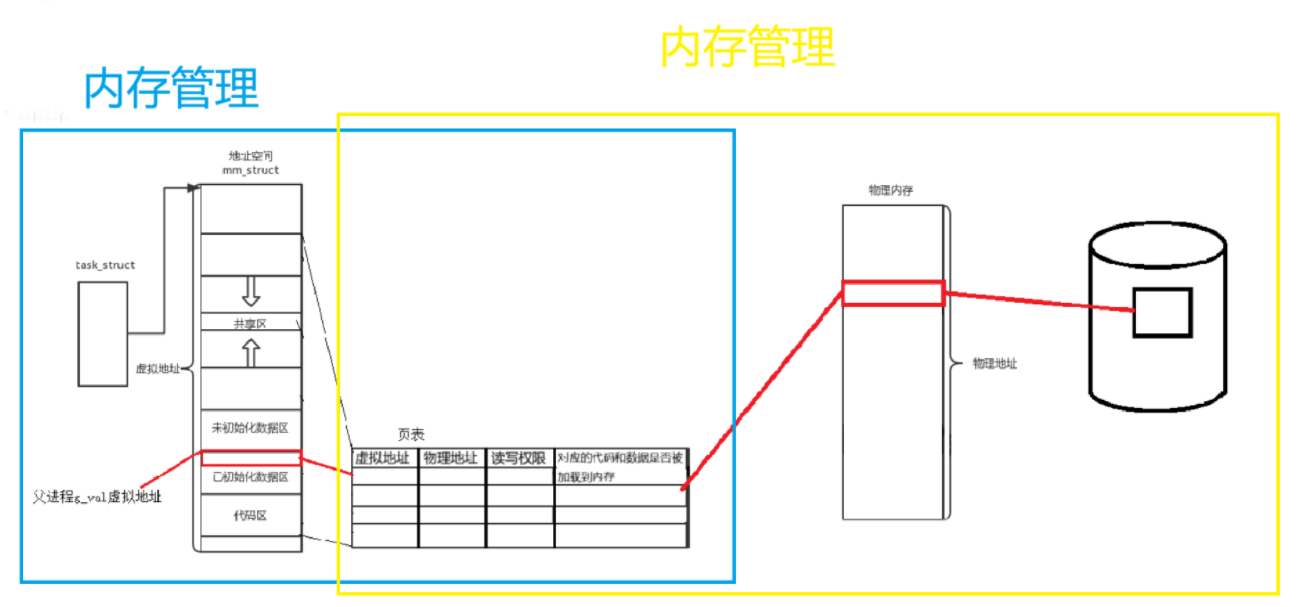
問 1:什么叫做區域(代碼區……)?
- 區域類似于桌子上劃分的三八線,將空間一分為二,每一半又可進一步細分,比如這塊放書,這塊放筆盒,這塊放水杯等。mm_struct結構體也是按照類似方式進行區域劃分和限制的,如下代碼所示:
struct mm_struct
{long code_start;long code_end;long init_start;long init_end;long uninit_start;long uninit_end;//……
}
問 2:程序是如何變成進程的?
- 程序編譯后未加載時,程序內部有地址和區域,此時地址采用相對地址形式,區域在磁盤上已劃分好。程序加載就是按區域將其加載到內存的過程。
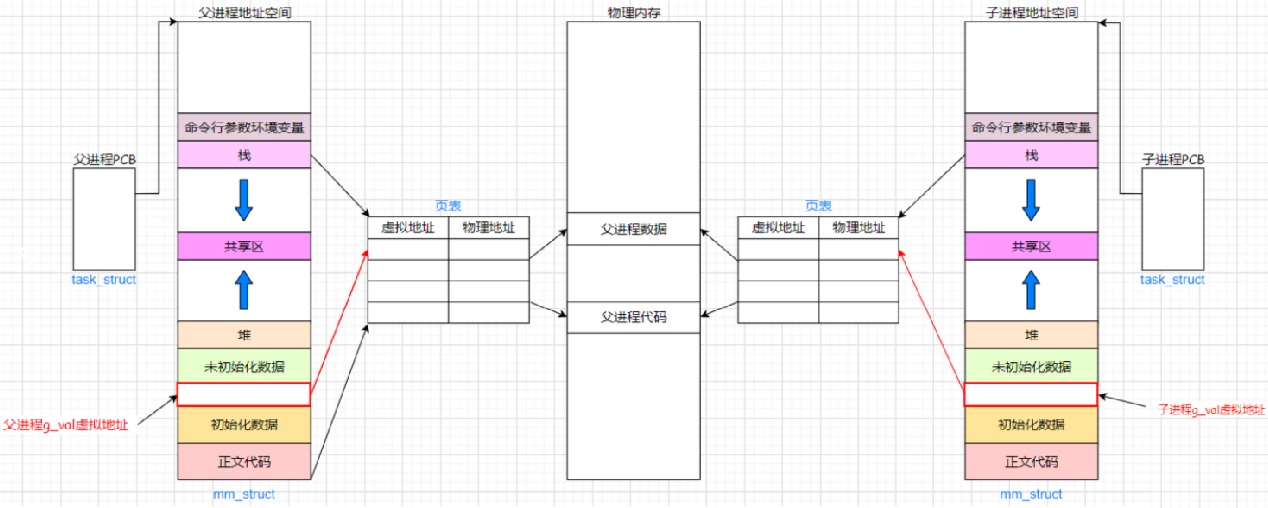
問 3:為什么先前修改一個進程時,地址是一樣的,但是父子進程訪問的內容卻是不一樣的?
-
父進程創建時,有自己的task_struct和地址空間mm_struct,地址空間通過頁表映射到物理內存。使用fork創建子進程時,子進程也有自己的task_struct、地址空間mm_struct和頁表 。如下:
-
子進程剛創建時,和父進程的數據、代碼是共享的,即父子進程的代碼和數據通過頁表映射到物理內存的同一塊空間,所以此時打印g_val的值和內容是一樣的。
-
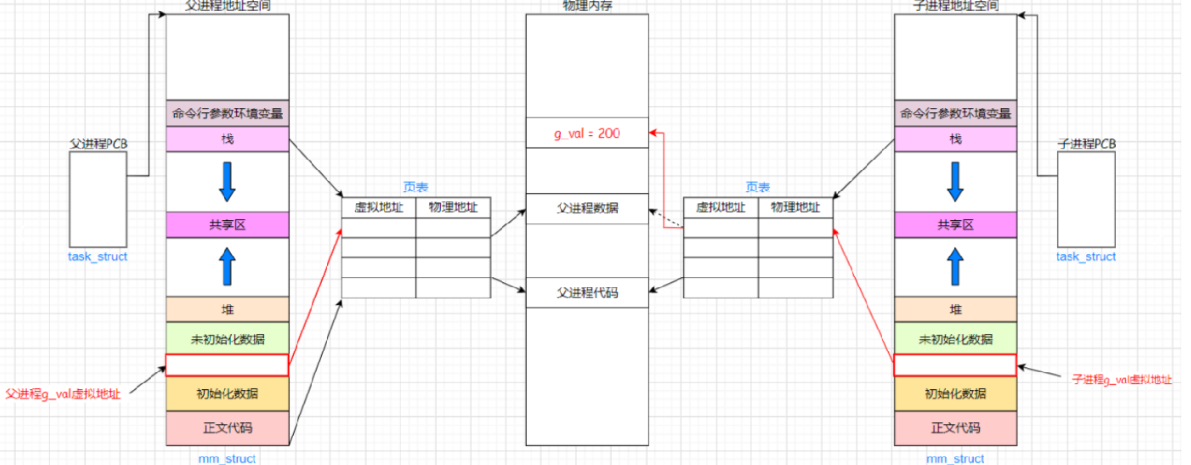
當子進程需要修改數據g_val時,結果就變了,如下圖:
-
無論父進程還是子進程,因為進程具有獨立性,如果子進程把變量g_val修改了,那么就會導致父進程識別此變量的時候出現問題,但是獨立性的要求是互不影響,所以此時操作系統會給你子進程重新開辟一塊空間,把先前g_val的值100 拷貝下來,重新給此進程建立映射關系,所以子進程的頁表就不再指向父進程的數據100了,而是指向新的100,此時把100修改為200,無論怎么修改,變動的永遠都是右側,左側頁表間的關系不變, 所以最終讀到的結果為子進程是200,父進程是100.
-
總結:當父子進程中有一方修改數據時,操作系統會為修改方重新開辟空間,拷貝原始數據到新空間,這種行為稱為寫時拷貝。通過頁表,利用寫時拷貝實現父子進程數據的分離,保證父子進程的獨立性。
問 4:fork 有兩個返回值,pid_t id,同一個變量,怎么會有不同的值?
- 一般情況下,pid_t id是父進程棧空間中定義的變量,fork內部return會被執行兩次,return本質是通過寄存器將返回值寫入接收返回值的變量。 當執行id = fork()時,先返回的一方會發生寫時拷貝,所以同一個變量虛擬地址相同,但物理地址不同,從而有不同的內容值。
問 5:為什么要有虛擬地址空間?
- 保護內存:假設存在非法訪問野指針(*p = 110),若該野指針指向其他進程甚至操作系統,直接訪問物理內存會修改其他進程數據,存在安全風險。而有了虛擬地址空間,當遇到野指針時,頁表不會建立映射關系,無法訪問物理內存,相當于在內存訪問時增加了一層軟硬件審核機制,可攔截非法請求。
- 解耦功能模塊:可以將 Linux 內存管理和進程管理通過地址空間進行功能模塊的解耦。
- 統一視角與簡化實現:讓進程或程序以統一視角看待內存,便于以統一方式編譯和加載所有可執行程序,簡化進程本身的設計與實現。
4、Linux2.6 內核進程調度隊列 - (理解即可)
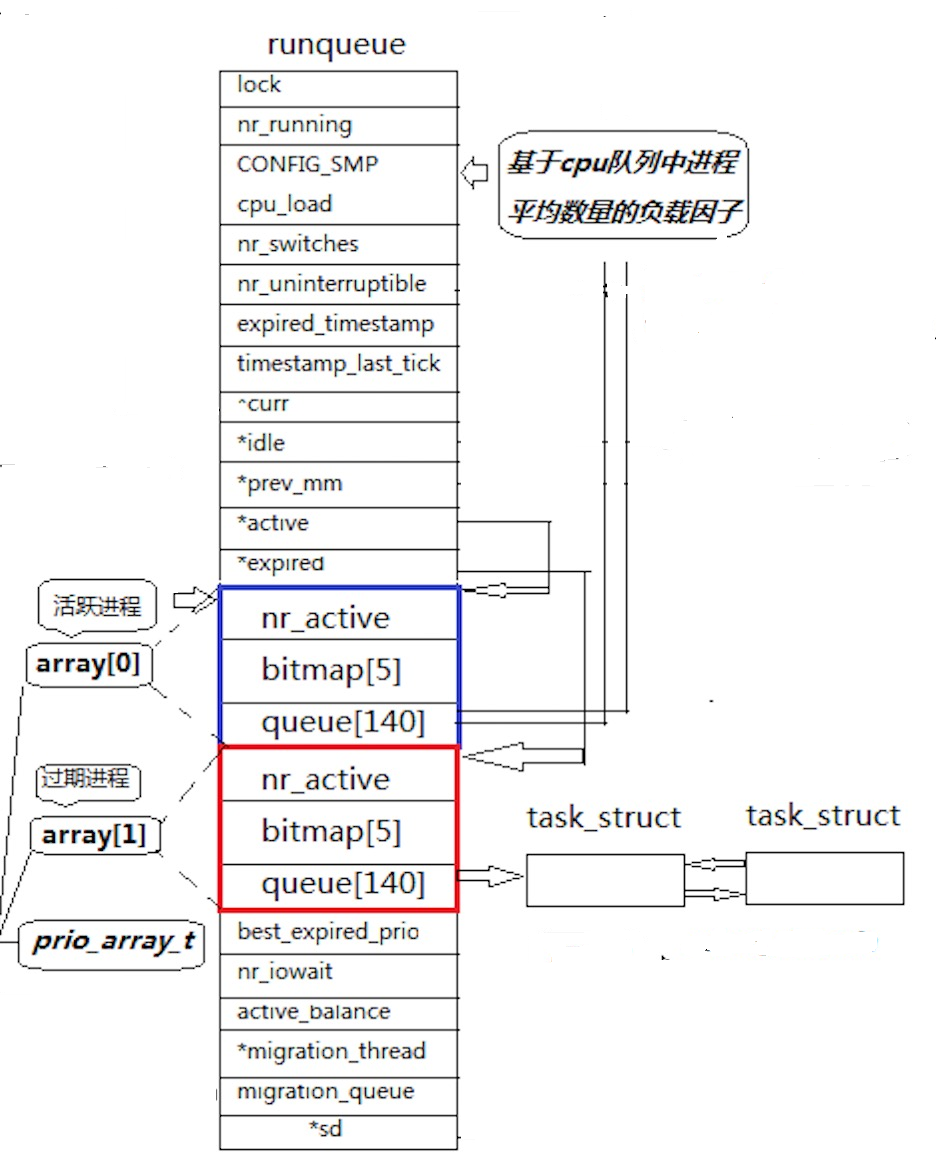
一個 CPU 擁有一個 runqueue
若存在多個 CPU,就需要考慮進程個數的負載均衡問題。
優先級
- 普通優先級:100~139(與nice值取值范圍對應)
- 實時優先級:0~99(不重點關注)
活動隊列
??時間片還沒有結束的所有進程都按照優先級放在該隊列。 nr_active:表示總共有多少個運行狀態的進程。
??queue[140]:一個元素就是一個進程隊列,相同優先級的進程按照 FIFO(先進先出)規則進行排隊調度,數組下標即優先級。??從該結構中選擇一個最合適的進程的過程如下:
- 1、從 0 下標開始遍歷queue[140]
- 2、找到第一個非空隊列(該隊列優先級最高)
- 3、拿到選中隊列的第一個進程開始運行,完成調度。
- 4、遍歷queue[140]的時間復雜度是常數,但效率仍較低。
??為提高查找非空隊列的效率,使用bitmap[5],用 5*32 個比特位表示隊列是否為空,可大大提升查找效率。
過期隊列
- 過期隊列和活動隊列結構一模一樣,放置的是時間片耗盡的進程。
- 當活動隊列上的進程都被處理完畢后,會對過期隊列的進程重新計算時間片。
active 指針和 expired 指針
- active指針永遠指向活動隊列。
- expired指針永遠指向過期隊列。
- 隨著進程運行,活動隊列上的進程會越來越少,過期隊列上的進程會越來越多。
- 在合適的時候,交換active指針和expired指針的內容,就相當于獲得了一批新的活動進程。
總結
在系統中查找一個最合適調度的進程的時間復雜度是常數,不會隨著進程數量增多而增加時間成本,這種進程調度方式稱為進程調度 O (1)算法。







 - @dataclass)


)

)


)


)
