為了增強代碼可讀性,代碼均使用Chatgpt給每一行代碼都加入了注釋,方便大家在本文代碼的基礎上進行改進優化。
本文是搭建了一個稍微優化了一下的模型,訓練200個epoch,準確率達到了99.74%,簡單完成了一下CIFAR-10數據集的實驗,再調調參可能就到100%了吧,算是一個入門學習吧 ~
完整代碼鏈接: MachineLearningCourseWork
數據: data5 - CIFAR10
完整代碼ipynb格式文件: work5-CIFAR10.ipynb
【本文參考資料】
- CIFAR-10 官方網站:由數據集創建者 Alex Krizhevsky 維護,提供了數據集的下載鏈接、格式說明等詳細信息。
- Deep Learning with Python:由 Francois Chollet 撰寫的深度學習書籍,其中使用 CIFAR-10 數據集作為案例講解圖像分類模型的構建和訓練方法。
- CS231n: Convolutional Neural Networks for Visual Recognition:斯坦福大學的CV課。
文章目錄
- 1. 數據集介紹
- 1.1 數據集概述
- 1.2 數據集結構
- 1.3 數據集格式
- 1.4 數據集應用場景
- 1.5 數據集特點
- 2. 實驗流程
- 2.1 導包
- 2.2 數據獲取與加載
- 2.3 定義網絡
- 2.4 增強的數據預處理
- 2.5 模型訓練
- 2.6 測試準確率
- 2.7 收集所有樣本的預測概率
- 2.8 評價一下
- 2.8.1 混淆矩陣
- 2.8.2 精確 - 召回
- 2.8.3 ROC曲線
1. 數據集介紹
1.1 數據集概述
數據集名稱:CIFAR-10
官方鏈接:https://www.cs.toronto.edu/~kriz/cifar.html
數據集簡介:
CIFAR-10 數據集是一個廣泛用于圖像分類任務的基準數據集,由 Alex Krizhevsky 在 2009 年創建,是計算機視覺領域最常用的數據集之一。它包含 60000 張 32x32 彩色圖像,分為 10 個不同的類別,每個類別有 6000 張圖片,其中 50000 張用于訓練模型,10000 張用于測試模型性能。
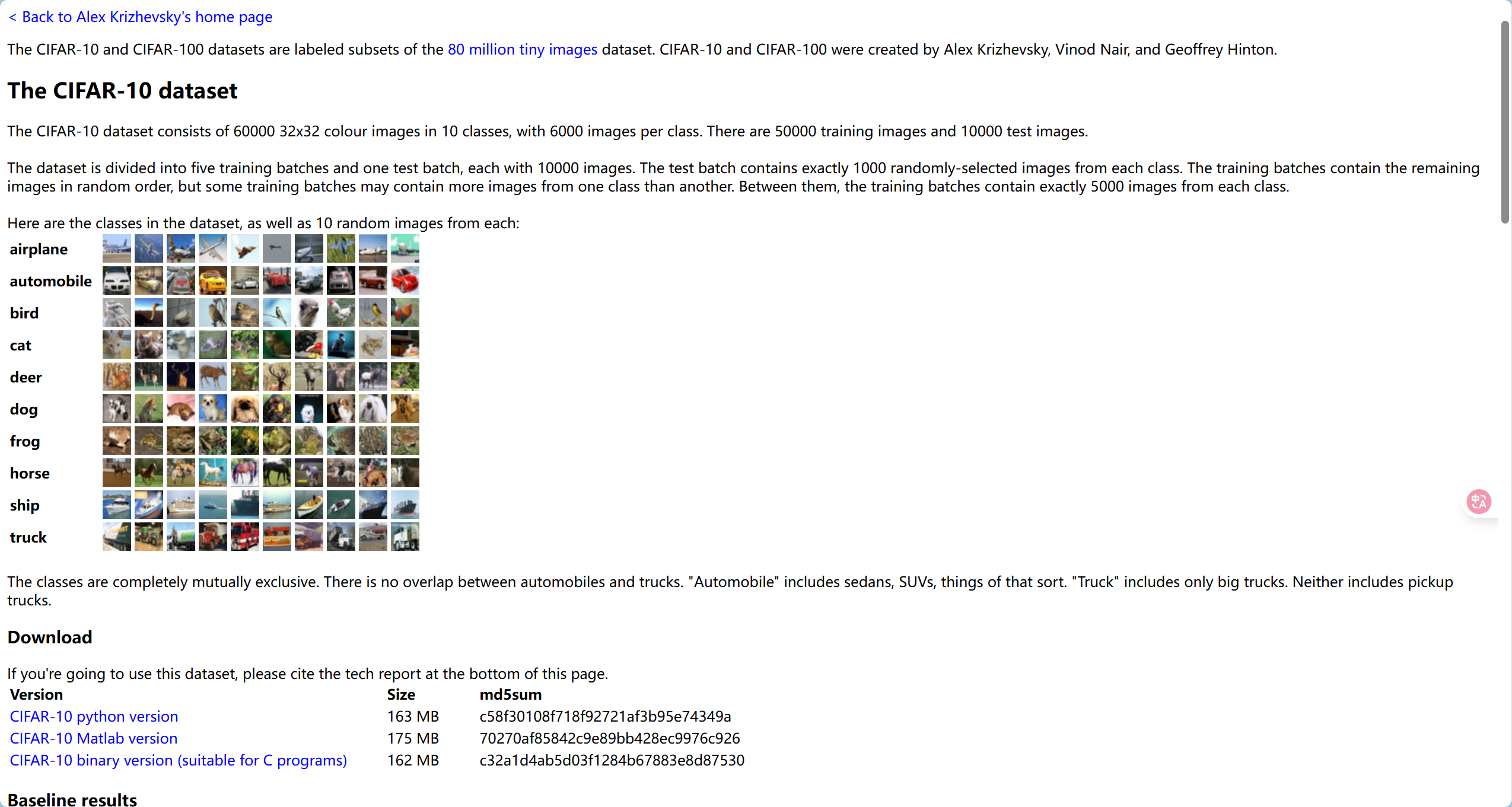
1.2 數據集結構
- 訓練集:包含 5 個批次,每個批次有 10000 張圖像。雖然訓練批次內圖像順序是隨機的,但各批次間圖像分布可能存在不均衡,即某些批次可能包含某一類別更多的圖片,但總體來說所有訓練批次合起來每個類別有 5000 張圖片。
- 測試集:包含 1 個批次,有 10000 張圖像,每個類別在測試集中正好有 1000 張隨機選擇的圖片。
數據集示例:
CIFAR-10 的圖像涵蓋了多種常見的物體類別,具體類別包括: - plane(飛機):例如各種型號的飛機在不同場景下的圖片,如在天空飛行、停在機場等。
- car(汽車):涵蓋不同品牌、款式和顏色的汽車,可能在道路上行駛或停在停車場。
- bird(鳥):包含多種鳥類的圖片,如麻雀、鴿子等,可能處在飛翔或棲息狀態。
- cat(貓):有不同品種、毛色和姿態的貓的圖像,比如家貓、波斯貓等。
- deer(鹿):展示在野外環境中的鹿,如梅花鹿等。
- dog(狗):包含各種品種的狗,如金毛犬、哈士奇等在不同場景下的圖片。
- frog(蛙類):有不同種類青蛙的圖片,可能在水中、岸邊等環境。
- horse(馬):展示不同品種馬的圖片,如在草原上奔跑或被飼養的場景。
- ship(船):包含各種船只,如貨船、游輪等在水中的圖片。
- truck(卡車):有不同類型的卡車,如貨運卡車、油罐車等的圖片。
1.3 數據集格式
- 圖像像素:每個圖像都是 32x32 像素的彩色圖像,具有 RGB 三個通道(數據集中本身是 BGR 通道,但在使用時通常會轉換為 RGB 通道)。
- 存儲格式:數據以 Python 拾取(pickle)文件的形式存儲,包含字典對象,其中包含圖像數據和標簽等信息。在使用時,通常需要通過 Python 的 pickle 庫加載數據,并將其轉換為 NumPy 數組等常用數據格式以便進行處理和訓練模型。
1.4 數據集應用場景
- 圖像分類:CIFAR-10 最常見的應用場景是作為圖像分類任務的數據集,用于訓練和測試各種卷積神經網絡(CNN)模型,如 LeNet、AlexNet、ResNet 等,評估模型對不同類別圖像的識別準確率。
- 模型評估與比較:作為標準數據集,方便研究者和開發者對比不同模型的性能,推動圖像識別技術的發展。
- 遷移學習:可以作為預訓練模型的基礎數據集,通過在 CIFAR-10 上訓練得到的模型參數,遷移到其他類似的圖像分類任務中,減少新任務的數據量需求和計算資源消耗。
- 深度學習研究:為深度學習算法的研究提供實驗平臺,例如研究新的網絡架構、優化算法、正則化方法等在 CIFAR-10 數據集上的效果。
1.5 數據集特點
優勢:
- 典型性和代表性:涵蓋了多種常見的物體類別,能夠反映日常生活中的一些基本圖像分類場景,適用于研究和測試基礎的圖像識別模型。
- 規模適中:60000 張圖像的數量對于現代計算資源來說既足夠大以提供有代表性的數據集,又不至于過于龐大而難以處理,適合在個人計算機或小型服務器上進行實驗和研究。
- 數據多樣性:雖然圖像尺寸較小,但包含不同類別、顏色、姿態和背景的圖片,具有一定的數據多樣性,有助于模型學習到更通用的特征。
局限性:
- 圖像尺寸較小:32x32 像素的圖像尺寸可能限制了模型對圖像細節的捕捉能力,對于一些需要精細識別的任務來說,可能不夠精確,例如對于圖像中一些微小特征或復雜紋理的識別。
- 類別相對簡單:相較于一些更復雜的圖像數據集(如 ImageNet),CIFAR-10 的類別較為基礎,可能無法充分測試模型在面對高度復雜、多樣化的圖像內容時的性能。
- 背景簡單:圖像中的物體通常具有相對簡單的背景,這可能使模型在處理更復雜背景或具有遮擋的圖像時表現不佳。
2. 實驗流程
2.1 導包
import torch # 導入 PyTorch 框架,用于構建和訓練深度學習模型
import torch.nn as nn # 導入 PyTorch 的神經網絡模塊,用于定義神經網絡結構
import torch.optim as optim # 導入 PyTorch 的優化器模塊,用于定義優化算法(如 SGD、Adam 等)
import torchvision # 導入 torchvision 庫,提供圖像處理和預訓練模型等功能
import torchvision.transforms as transforms # 導入 torchvision 的數據預處理模塊,用于對圖像數據進行變換(如歸一化、裁剪等)
from torch.utils.data import DataLoader # 導入 PyTorch 的數據加載器模塊,用于批量加載和管理數據集
from datetime import datetime
import time
# 畫圖相關
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np # 數據計算
from torch.nn.functional import softmax #softmax函數
2.2 數據獲取與加載
# 定義一個數據預處理的組合操作
transform = transforms.Compose([transforms.ToTensor(), # 將圖像數據從 PIL 圖像格式轉換為 PyTorch 張量(Tensor),并將其值歸一化到 [0, 1] 范圍transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 對圖像的每個通道進行標準化處理,均值為 0.5,標準差為 0.5
])# 加載 CIFAR-10 訓練數據集
trainset = torchvision.datasets.CIFAR10(root='./data4', # 數據集存儲的根目錄路徑train=True, # 指定加載訓練集download=False, # 不從網絡下載數據集(假設數據已經下載到本地)transform=transform # 應用上面定義的預處理操作
)# 加載 CIFAR-10 測試數據集
testset = torchvision.datasets.CIFAR10(root='./data4', # 數據集存儲的根目錄路徑train=False, # 指定加載測試集download=False, # 不從網絡下載數據集(假設數據已經下載到本地)transform=transform # 應用上面定義的預處理操作
)
# 定義每個批次的大小
batch_size = 64 # 每個批次包含 64 張圖像# 創建訓練數據的 DataLoader
trainloader = DataLoader(trainset, # 指定加載的訓練數據集batch_size=batch_size, # 每個批次的大小shuffle=True, # 在每個 epoch 開始時隨機打亂數據順序num_workers=2 # 使用 2 個子進程加載數據,加速數據讀取
)# 創建測試數據的 DataLoader
testloader = DataLoader(testset, # 指定加載的測試數據集batch_size=batch_size, # 每個批次的大小shuffle=False, # 測試時不需要打亂數據順序num_workers=2 # 使用 2 個子進程加載數據,加速數據讀取
)
2.3 定義網絡
這里我定義的是一個比較簡單的卷積神經網絡模型,包含特征提取層和分類器層,但是整體的效果也還行了,可以改成ResNet18或ResNet34
# 定義一個簡單的卷積神經網絡模型
class TestNet(nn.Module):def __init__(self, dropout_rate=0.5):super(TestNet, self).__init__() # 調用父類的初始化方法# 特征提取部分self.features = nn.Sequential( # 定義特征提取層的序列nn.Conv2d(3, 64, kernel_size=3, padding=1), # 第一層卷積,輸入通道數為3,輸出通道數為64,卷積核大小為3x3,邊緣填充為1nn.BatchNorm2d(64), # 對64個通道進行批量歸一化nn.ReLU(inplace=True), # ReLU激活函數,inplace=True表示直接在原變量上操作,節省內存nn.Conv2d(64, 64, kernel_size=3, padding=1), # 第二層卷積,輸入輸出通道數均為64nn.BatchNorm2d(64), # 批量歸一化nn.ReLU(inplace=True), # ReLU激活nn.MaxPool2d(2, 2), # 最大池化,池化窗口大小為2x2,步長為2nn.Dropout2d(p=dropout_rate/2), # 二維Dropout,隨機丟棄一半的特征圖,防止過擬合nn.Conv2d(64, 128, kernel_size=3, padding=1), # 第三層卷積,輸入通道數為64,輸出通道數為128nn.BatchNorm2d(128), # 批量歸一化nn.ReLU(inplace=True), # ReLU激活nn.Conv2d(128, 128, kernel_size=3, padding=1), # 第四層卷積,輸入輸出通道數均為128nn.BatchNorm2d(128), # 批量歸一化nn.ReLU(inplace=True), # ReLU激活nn.MaxPool2d(2, 2), # 最大池化nn.Dropout2d(p=dropout_rate), # Dropoutnn.Conv2d(128, 256, kernel_size=3, padding=1), # 第五層卷積,輸入通道數為128,輸出通道數為256nn.BatchNorm2d(256), # 批量歸一化nn.ReLU(inplace=True), # ReLU激活nn.Conv2d(256, 256, kernel_size=3, padding=1), # 第六層卷積,輸入輸出通道數均為256nn.BatchNorm2d(256), # 批量歸一化nn.ReLU(inplace=True), # ReLU激活nn.MaxPool2d(2, 2), # 最大池化)# 分類器部分self.classifier = nn.Sequential( # 定義分類器層的序列nn.Linear(256 * 4 * 4, 512), # 全連接層,輸入特征數為256*4*4,輸出特征數為512nn.BatchNorm1d(512), # 一維批量歸一化nn.ReLU(inplace=True), # ReLU激活nn.Dropout(p=dropout_rate), # Dropoutnn.Linear(512, 256), # 全連接層,輸入特征數為512,輸出特征數為256nn.BatchNorm1d(256), # 批量歸一化nn.ReLU(inplace=True), # ReLU激活nn.Dropout(p=dropout_rate/2), # Dropoutnn.Linear(256, 10) # 最后一層全連接層,輸出10個類別)def forward(self, x):x = self.features(x) # 將輸入數據通過特征提取層x = torch.flatten(x, 1) # 將特征圖展平為一維向量,從第1維開始展平x = self.classifier(x) # 將展平后的特征通過分類器層return x # 返回最終的輸出
2.4 增強的數據預處理
# 定義訓練集的數據預處理操作
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4), # 隨機裁剪,裁剪大小為32x32,邊緣填充為4transforms.RandomHorizontalFlip(), # 隨機水平翻轉transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2), # 隨機調整亮度、對比度和飽和度transforms.ToTensor(), # 將圖像轉換為張量transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), # 標準化,均值和標準差分別為CIFAR-10數據集的均值和標準差
])# 定義測試集的數據預處理操作
transform_test = transforms.Compose([transforms.ToTensor(), # 將圖像轉換為張量transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), # 標準化
])
net = TestNet() # 初始化
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # GPU
net.to(device)
2.5 模型訓練
# 開始訓練模型
start_time = time.time() # 記錄訓練開始時間
for epoch in range(10): # 訓練 10 個 epochrunning_loss = 0.0 # 初始化每輪的累計損失for i, data in enumerate(trainloader, 0): # 遍歷訓練數據加載器inputs, labels = data[0].to(device), data[1].to(device) # 將輸入數據和標簽移動到指定設備(如 GPU)optimizer.zero_grad() # 清零梯度,避免梯度累積outputs = net(inputs) # 前向傳播,計算模型輸出loss = criterion(outputs, labels) # 計算損失值loss.backward() # 反向傳播,計算梯度optimizer.step() # 更新模型參數running_loss += loss.item() # 累加損失值# 每 100 批次打印一次詳細信息if i % 100 == 99: avg_loss = running_loss / 100 # 計算平均損失print(f'[Epoch {epoch + 1}/{10}, Batch {i + 1}/{len(trainloader)}] 'f'Average Loss: {avg_loss:.4f} | 'f'Current Batch Loss: {loss.item():.4f} | 'f'Running Loss: {running_loss:.4f}')running_loss = 0.0 # 重置累計損失scheduler.step() # 更新學習率end_time = time.time() # 記錄訓練結束時間
elapsed_time = end_time - start_time # 計算總耗時
print(f'Finished Training. Total time taken: {elapsed_time:.2f} seconds')# 保存模型
timestamp = datetime.now().strftime("%y-%m-%d-%H-%M-%S") # 獲取當前時間戳
model_name = f"CIFAR10Net-{timestamp}.pth"
torch.save(net.state_dict(), model_name)
print(f"Model saved successfully as {model_name}")
2.6 測試準確率
# 初始化正確預測的數量和測試數據的總數
correct_predictions = 0
total_samples = 0# 禁用梯度計算,節省內存和計算資源
with torch.no_grad():for data in testloader: # 遍歷測試數據加載器images, labels = data[0].to(device), data[1].to(device) # 將圖像和標簽移動到指定設備outputs = net(images) # 前向傳播,獲取模型的輸出_, predicted_labels = torch.max(outputs.data, 1) # 獲取預測的類別(概率最高的類別)total_samples += labels.size(0) # 累加測試數據的總數correct_predictions += (predicted_labels == labels).sum().item() # 累加正確預測的數量# 計算準確率
accuracy = 100 * correct_predictions / total_samples
print(f'Accuracy: {accuracy:.2f}%') # 打印準確率
2.7 收集所有樣本的預測概率
import numpy as np
from torch.nn.functional import softmax# 初始化兩個列表,用于保存所有樣本的預測概率和真實標簽
all_preds = [] # 保存所有樣本的預測概率
all_labels = [] # 保存所有真實標簽# 使用torch.no_grad()上下文管理器,這可以暫時禁用計算圖中的梯度計算,節省內存和計算資源
with torch.no_grad():for data in testloader: # 遍歷測試數據加載器testloaderimages, labels = data[0].to(device), data[1].to(device) # 將圖像和標簽數據移動到指定的設備(如GPU)outputs = net(images) # 通過神經網絡模型net獲取預測輸出probabilities = softmax(outputs, dim=1) # 將輸出轉換為概率分布,dim=1表示在類別維度上進行softmax操作all_preds.append(probabilities.cpu().numpy()) # 將概率分布轉移到CPU并轉換為numpy數組,然后添加到all_preds列表中all_labels.append(labels.cpu().numpy()) # 將標簽數據轉移到CPU并轉換為numpy數組,然后添加到all_labels列表中# 合并所有批次的結果,使用numpy的concatenate函數沿著第一個軸(axis=0)合并數組
all_preds = np.concatenate(all_preds, axis=0) # 形狀 [N, 10],其中N是樣本總數,10是類別數
all_labels = np.concatenate(all_labels, axis=0) # 形狀 [N, ],其中N是樣本總數
2.8 評價一下
2.8.1 混淆矩陣
from sklearn.metrics import confusion_matrix # 導入混淆矩陣計算函數
import seaborn as sns # 導入seaborn庫,用于繪制熱圖
import matplotlib.pyplot as plt # 導入matplotlib庫,用于繪圖# 初始化兩個列表,用于存儲模型預測的標簽和真實標簽
all_preds, all_labels = [], []# 使用torch.no_grad()來禁用梯度計算,因為在測試階段不需要計算梯度
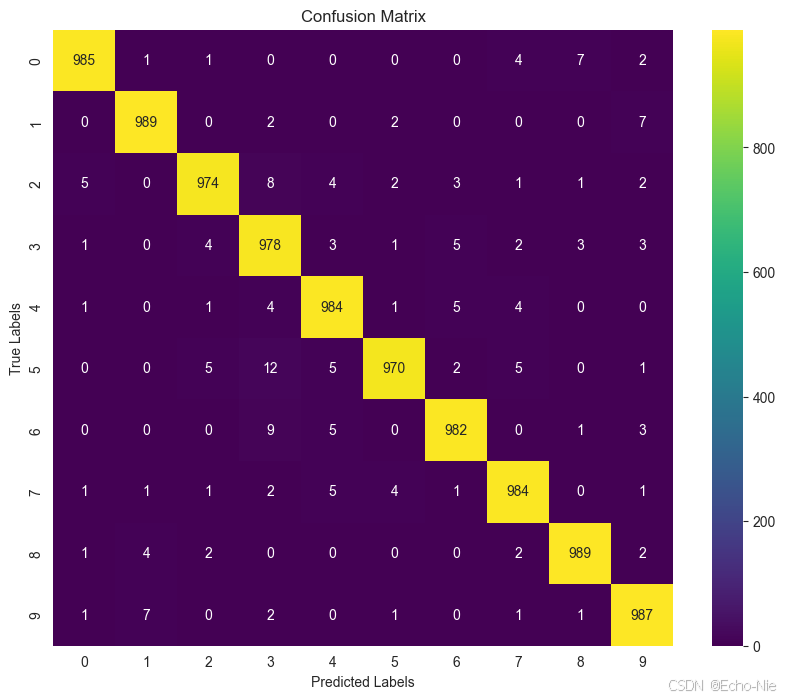
with torch.no_grad():# 遍歷測試數據加載器for data in testloader:# 將圖像數據和標簽數據移動到設備上(如GPU)images, labels = data[0].to(device), data[1].to(device)# 將圖像數據輸入模型進行預測outputs = net(images)# 獲取模型輸出中概率最大的索引,即預測的類別_, predicted = torch.max(outputs, 1)# 將預測的類別和真實類別添加到列表中all_preds.extend(predicted.cpu().numpy())all_labels.extend(labels.cpu().numpy())# 計算混淆矩陣
cm = confusion_matrix(all_labels, all_preds)# 設置圖形的大小
plt.figure(figsize=(10, 8))
# 使用seaborn庫繪制熱圖,顯示混淆矩陣
# annot=True表示在每個單元格中顯示數值,fmt='d'表示數值格式為整數
# cmap='viridis'指定使用viridis配色方案
sns.heatmap(cm, annot=True, fmt='d', cmap='viridis')
plt.title('Confusion Matrix')
plt.xlabel('Predicted Labels')
plt.ylabel('True Labels')
plt.show()
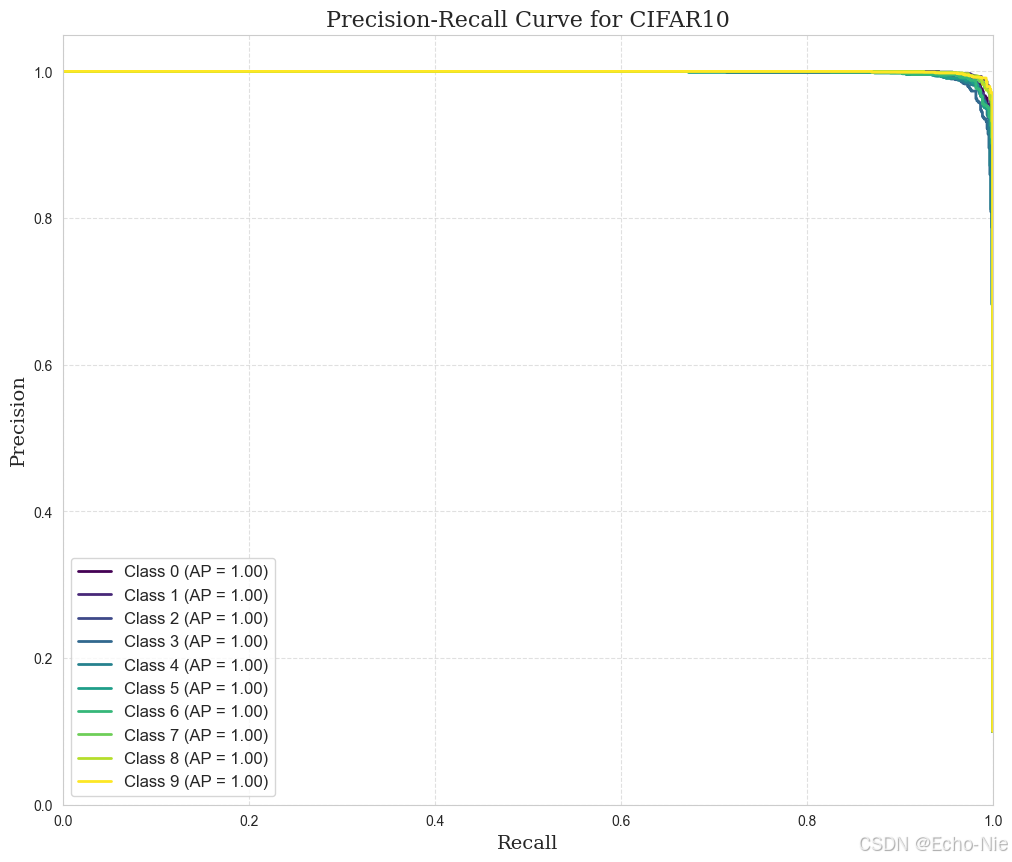
2.8.2 精確 - 召回
from sklearn.metrics import precision_recall_curve, auc
import matplotlib.pyplot as plt
import numpy as npn_classes = 10 # CIFAR10數據集有10個類別# 初始化字典來存儲每個類別的精確度、召回率和平均精確度
precision = dict()
recall = dict()
average_precision = dict()# 遍歷所有類別
for i in range(n_classes):# 提取第i類的概率作為預測分數,并生成對應的二分類標簽precision[i], recall[i], _ = precision_recall_curve((all_labels == i).astype(int), all_preds[:, i])average_precision[i] = auc(recall[i], precision[i])plt.figure(figsize=(12, 10), dpi=100)
colors = plt.cm.viridis(np.linspace(0, 1, n_classes))for i in range(n_classes):plt.plot(recall[i], precision[i], color=colors[i], lw=2, label=f'Class {i} (AP = {average_precision[i]:.2f})')
plt.xlabel('Recall', fontsize=14, fontfamily='serif')
plt.ylabel('Precision', fontsize=14, fontfamily='serif')
plt.title('Precision-Recall Curve for CIFAR10', fontsize=16, fontfamily='serif')
plt.legend(loc='best', fontsize=12, frameon=True)
plt.grid(True, linestyle='--', alpha=0.6)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.savefig('precision_recall_curve.png', bbox_inches='tight')
plt.show()
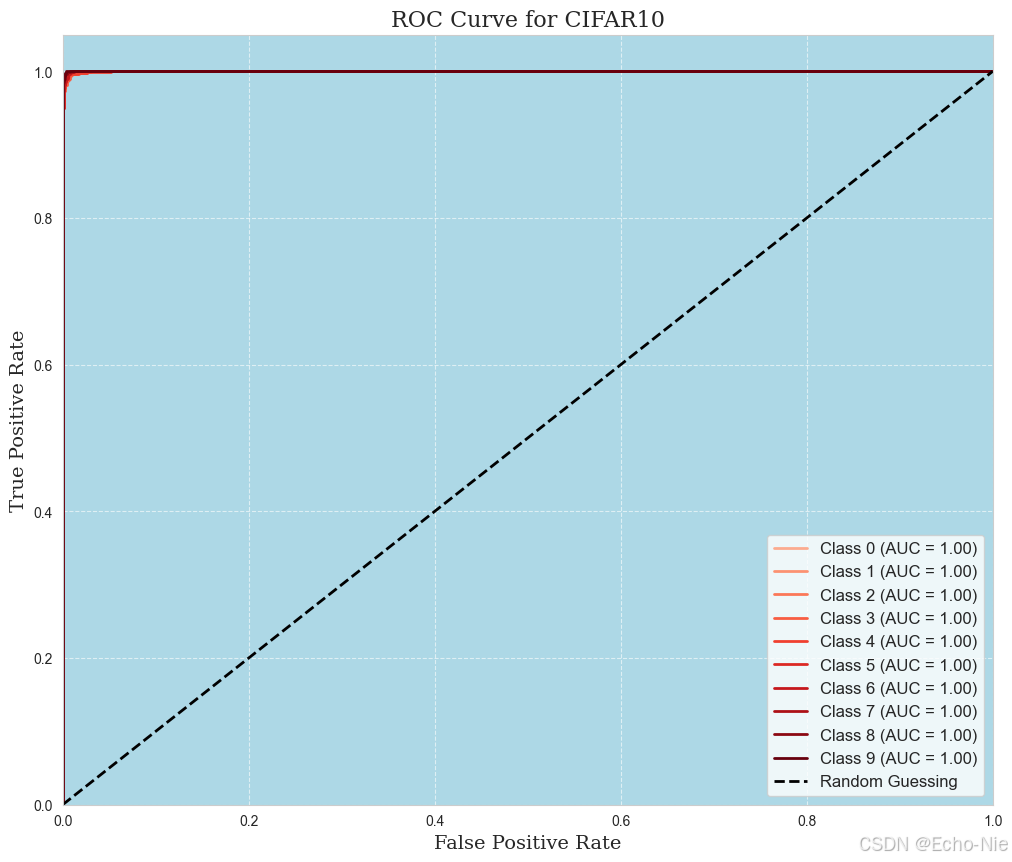
2.8.3 ROC曲線
from sklearn.preprocessing import label_binarize
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
import numpy as np# ROC曲線
all_labels_binarized = label_binarize(all_labels, classes=np.arange(n_classes))
all_preds_binarized = all_preds
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):fpr[i], tpr[i], _ = roc_curve(all_labels_binarized[:, i], all_preds_binarized[:, i])roc_auc[i] = auc(fpr[i], tpr[i])plt.figure(figsize=(12, 10), dpi=100)plt.gca().set_facecolor('#ADD8E6')
colors = plt.cm.Reds(np.linspace(0.3, 1, n_classes))for i in range(n_classes):plt.plot(fpr[i], tpr[i], color=colors[i], lw=2, label=f'Class {i} (AUC = {roc_auc[i]:.2f})')plt.plot([0, 1], [0, 1], 'k--', lw=2, label='Random Guessing')plt.xlabel('False Positive Rate', fontsize=14, fontfamily='serif')
plt.ylabel('True Positive Rate', fontsize=14, fontfamily='serif')plt.title('ROC Curve for CIFAR10', fontsize=16, fontfamily='serif')plt.legend(loc='best', fontsize=12, frameon=True)plt.grid(True, linestyle='--', alpha=0.6, color='white')plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])plt.savefig('roc_curve_red.png', bbox_inches='tight')plt.show()



 - @dataclass)


)

)


)


)





)