目錄
前言
一、聚合函數
1.1日期函數
1.2字符串函數
?1.3數學函數
1.4其它函數
二、關鍵字周邊
2.1關鍵字的生效順序
?2.2數據源
2.3可以使用聚合函數的關鍵字
前言
在前面幾篇文章中,講解了有關MySQL數據庫、數據庫表的創建、數據庫表的數據操作等等。本文我們主要講解MySQL中給我們內置好的,可以幫助我們完成一定功能的函數,以及一些復雜場景下的查詢操作。這里不建議沒有基礎的同學進行閱讀。
一、內置函數函數
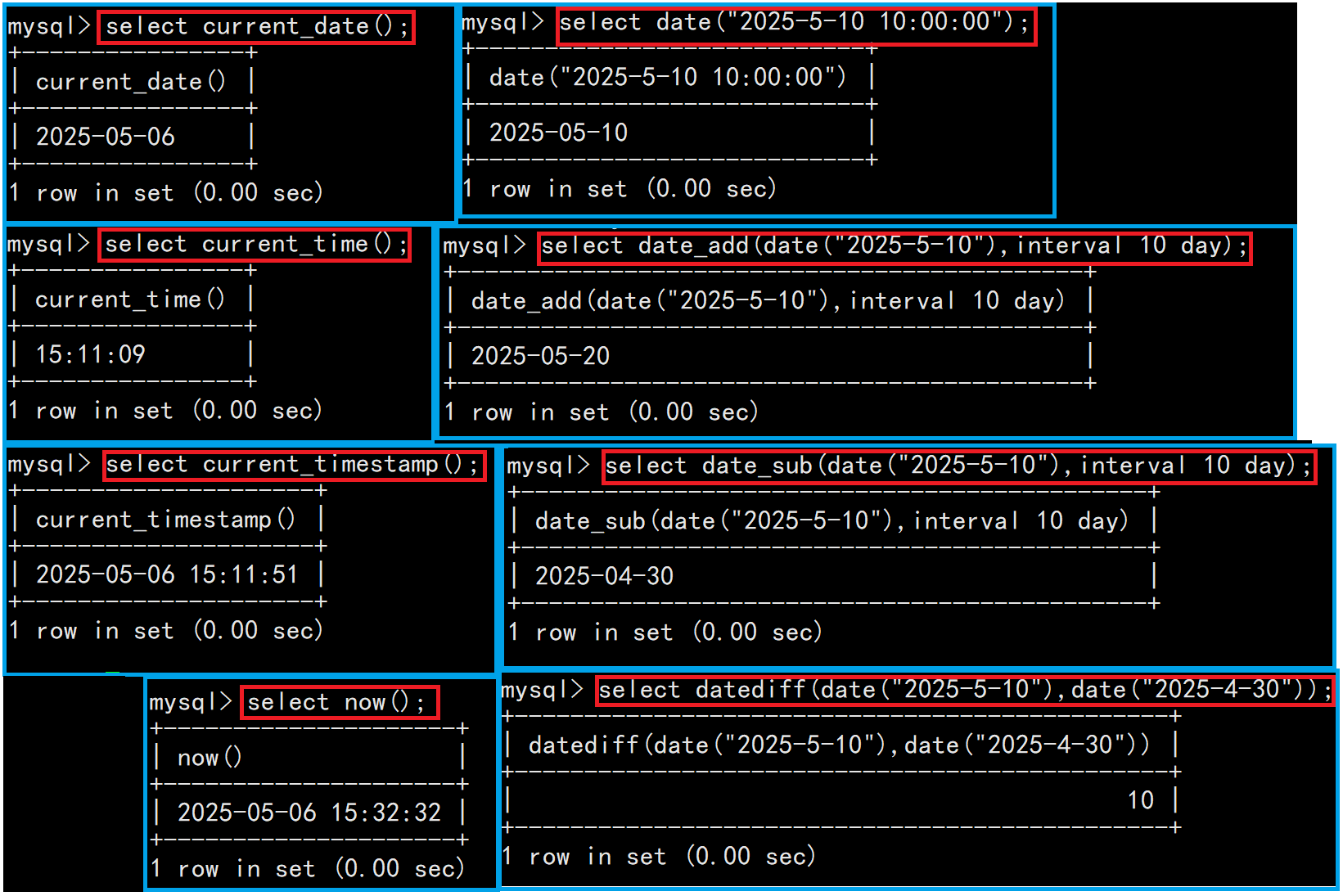
1.1日期函數
| 函數名稱 | 描述 |
|---|---|
| current_date() | 當前日期 |
| current_time() | 當前時間 |
| current_timestamp() | 當前時間戳 |
| date(datetime) | 按照datetime格式返回時間 |
| date_add(date, interval d_value_type) | 在date的基礎上添加時間。 d_value_type可以是year、day、minute、second其中之一 |
| date_sub(date, interval d_value_type) | 在date的基礎上減去時間。 d_value_type可以是year、day、minute、second其中之一 |
| datediff(date1,date2) | 兩個日期之差,單位是天 |
| now() | 獲取當前時間 |
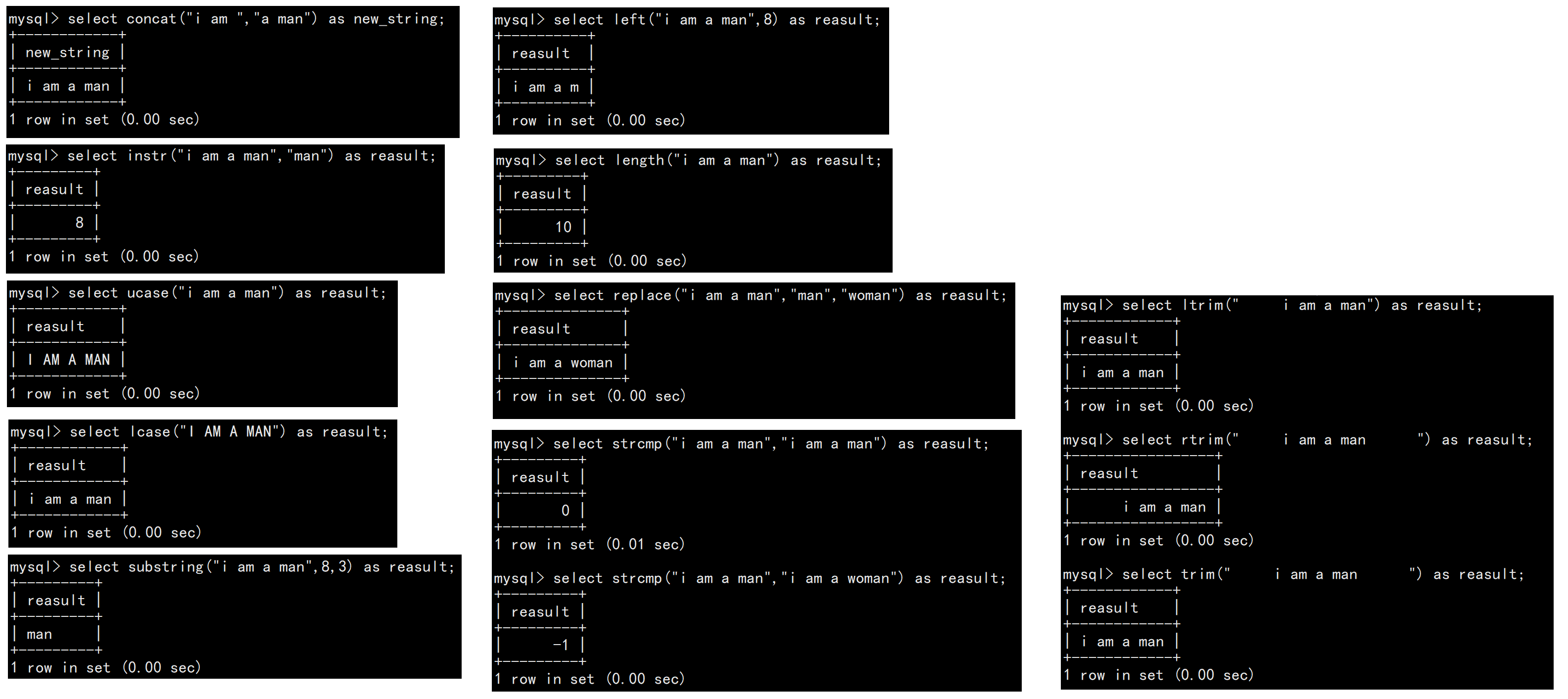
1.2字符串函數
| 函數 | 說明 |
|---|---|
| charset() | 返回字段的字符集 |
| concat(str1,str,...) | 連接字符串 |
| instr(stringA,stringB) | 在stringA中查找是否存在stringB,存在則返回其所在位置,不存在則返回0 |
| ucase(string) | 轉換為大寫 |
| lcase(string) | 轉換為小寫 |
| left(string,length) | 從string首部其去除length個字符 |
| length(string) | 返回string的長度 |
| replace(str,search_str,replace_str) | 在str中使用replace_str替換search_str |
| strcmp(stringA,stringB) | 逐字符比較stringA與stringB的大小 |
| substring(str,position,length) | 從str的position位置取出length個字符 |
| ltrim(string) rtrim(string) trim(string) | 去除string中的左空格、右空格、左右空格 |
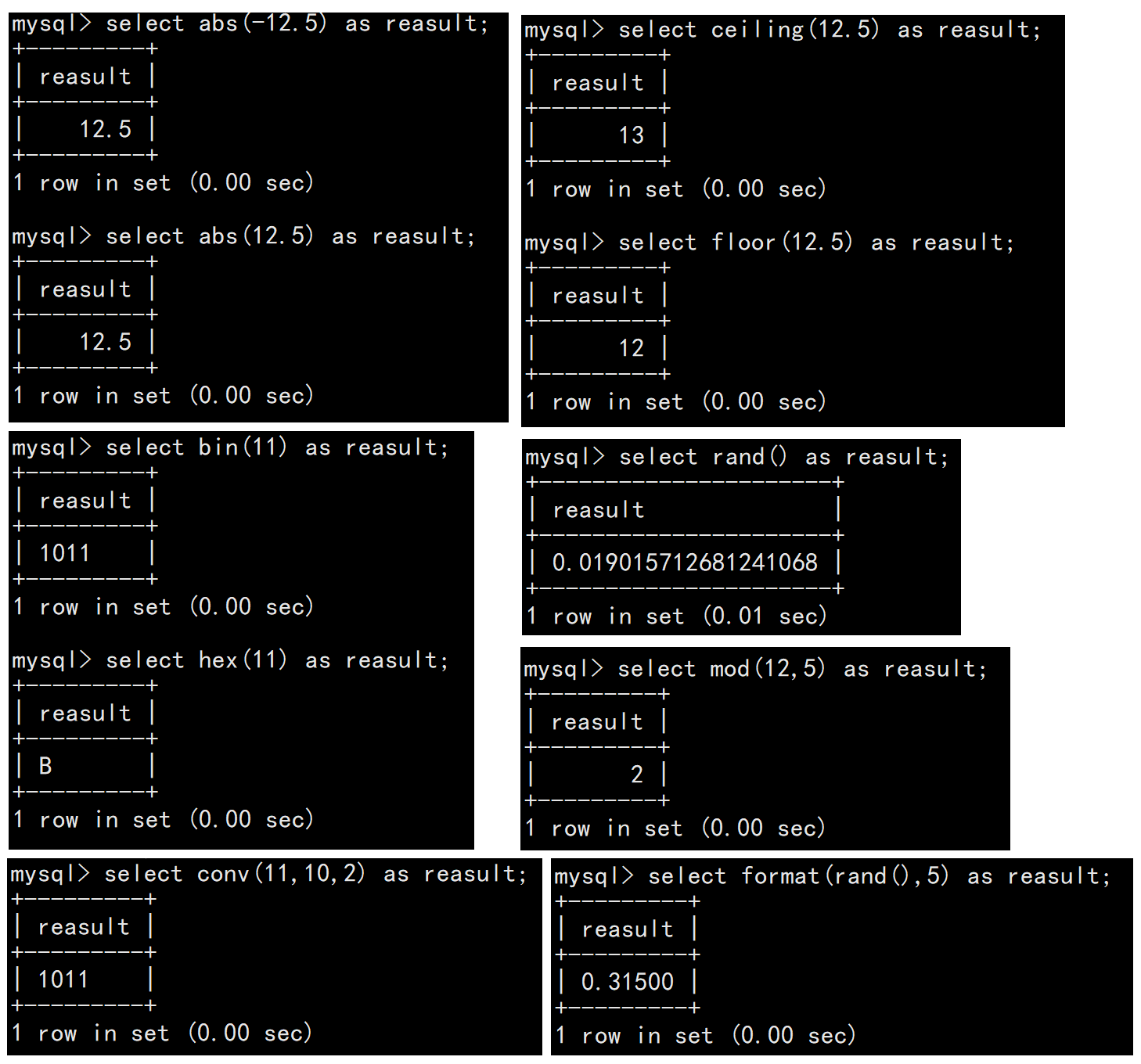
?1.3數學函數
| 函數名稱 | 說明 |
|---|---|
| abs(number) | 對number進行絕對值運算 |
| bin(decimal_number) | 十進制轉換為二進制 |
| hex(decimal_number) | 十進制轉換為十六進制 |
| conv(number,from_base,to_base) | 將number從from_base進制轉換為to_base進制 |
| ceiling(number) | 向上取整 |
| floor(number) | 向下取整 |
| format(number,decimal_places) | 格式化,保留小數位 |
| rand() | 返回[0,1)之間的隨機浮點數 |
| mod(number,denominator) | 取模,求余 |
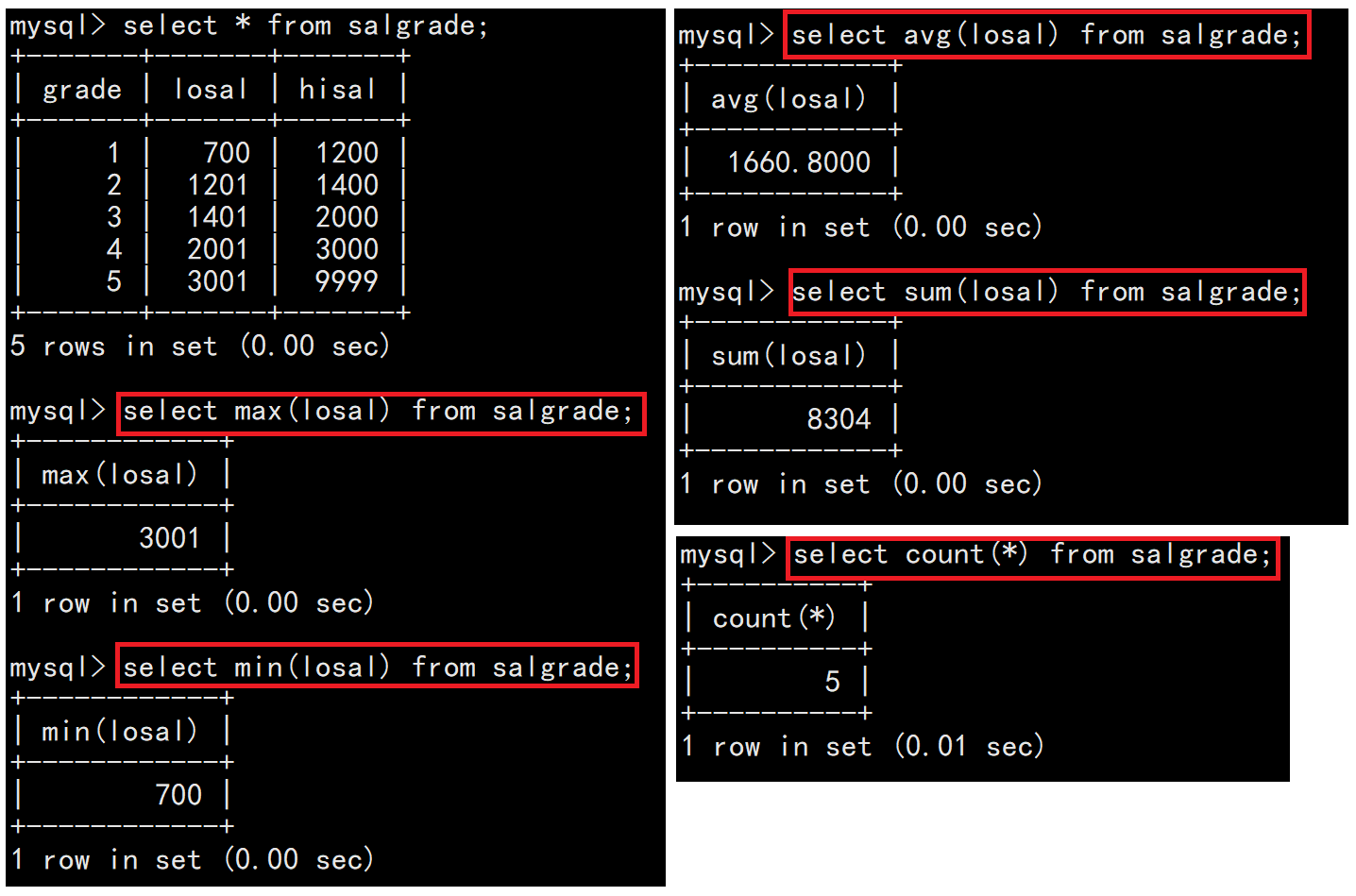
1.4聚合函數
| 函數名稱 | 說明 |
|---|---|
| count() | 用來統計表中行的個數,使用count(*)可以統計所有行(包括值為null的列的行)的數量。 |
| sum() | 用來統計數值列的總和,只能用于數值列。 |
| avg() | 用來統計數值列的平均值,只能用于數值列。 |
| max() | 用于獲取指定列的最大值。可以用于數值、日期、字符串等類型的列。 |
| min() | 用于獲取指定列的最小值。與 MAX()類似,可以用于多種數據類型。 |
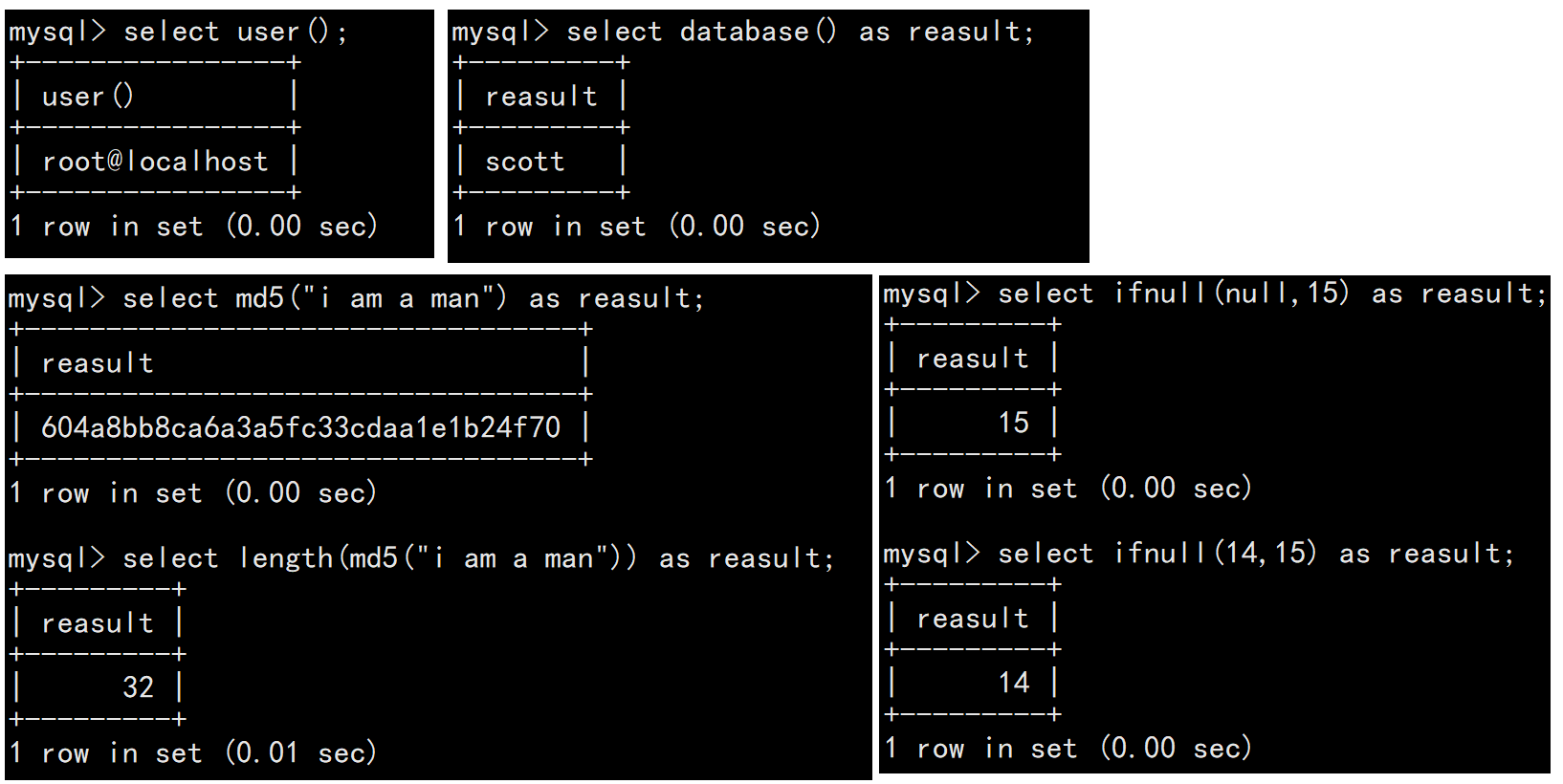
1.5其它函數
| 函數名稱 | 說明 |
|---|---|
| user() | 查看當前登錄用戶的用戶名 |
| md5(str) | 對str生成一個32位的md5摘要 |
| database() | 顯示當前正在使用的數據庫 |
| ifnull(val1,val2) | 如果val1為null,返回val2,否則返回val1 |
二、關鍵字周邊
2.1關鍵字的生效順序
- FROM:該關鍵字表示我們將從哪一個數據的表中獲取數據,這也是最先生效的關鍵字。
- WHERE:該關鍵字表示我們將按照一定的規則篩選表中的數據,將不滿足條件的數據篩選掉。
- GROUP BY:該關鍵字會將where條件篩選后的數據按照一定的規則進行分組。
- HAVING:該關鍵字會對分組后的數據按照一定的規則進行篩選,篩選掉不符合的數據。
- SELECT:講過分組后篩選的數據就會被select挑選原則進行挑選,因為每一行數據可能有很多的字段并不是每一個字段都會被使用到。
- ORDER BY:在選擇好對應的數據后,將符合條件的數據按照一定的規則進行排序。
- LIMIT/OFFSET:LIMIT用于限制返回結果的行數,OFFSET表示從第幾行開始返回。這兩個子句通常是一次查詢最后執行的部分。
- UNION:將多個包含相同列數的、SELECT的結果集進行去重后合并,UNION ALL與UNION類似,但是UNION ALL不會對進行去重操作。
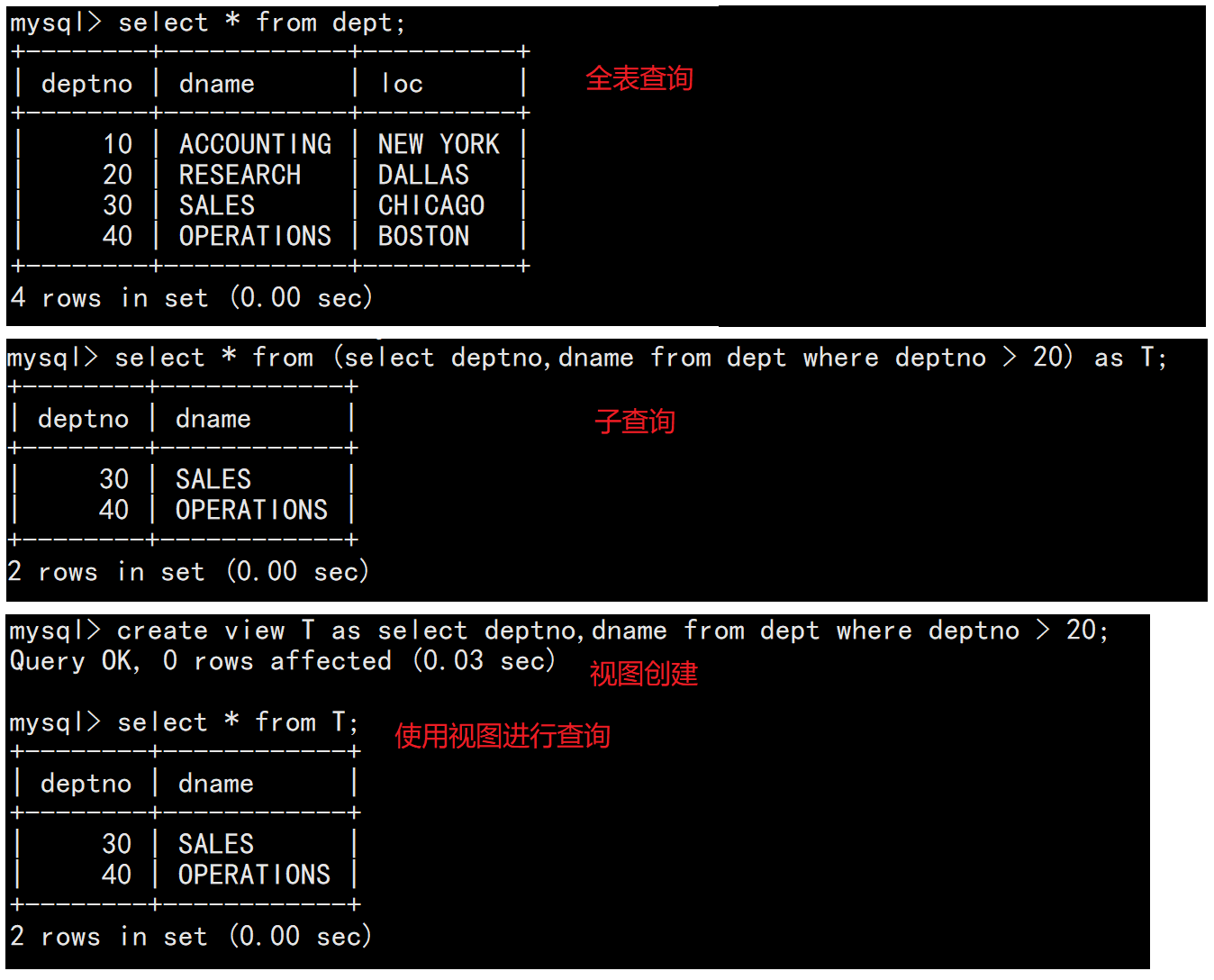
?2.2數據源
? ? ? ? 我們的from對數據的獲取不僅可以從數據庫表中獲取,也可以從視圖和子查詢的結果中獲取。
? ? ? ? 實際上所謂的視圖你可以理解為是一個子查詢以視圖的形式進行了保存,這意味著如果某個查詢事務常常被執行,那么我們就可以創建一個視圖,然后從這個視圖里獲取數據而不是從數據庫中重新篩選獲取。需要說明的是——視圖不會掉電丟失。
2.3可以使用聚合函數的關鍵字
? ? ? ? 關于這個問題,我們首先要了解聚合函數存在的意義是什么,聚合中的“聚”字代表有很多的數據,“合”字代表要將這些數據整合為一個值用來表示這些數據的一個整體的指標。
????????例如,COUNT?函數用于統計行數,它會對表中的一組行進行計數,將這組行的數量聚合成一個數字;SUM?函數用于計算某一列數值的總和,是將該列的多個值聚合為一個總和值;AVG?函數計算平均值,是先將一組數值進行求和聚合,再除以數量得到一個平均值;MAX?和?MIN?函數則是從一組數據中找出最大值或最小值,也是一種聚合操作,將一組數據聚合成一個代表最大或最小的值。
? ? ? ? 所以在where和group by階段直接使用聚合函數是沒有意義的,因為在where階段我們往往是要確定篩選的條件,而不是使用聚合函數去得出一個能夠描述全表數據特征的一個值,對于group by來說也是如此,但是對于select和having階段就有所不同了,select關鍵字的意思很明顯就是想查看值,如果我們想查看一個表的特征值這顯然是合理的,having則是對經過分組后的數據添加約束條件,這就意味著如果我們此時使用聚合函數描述的是分組后的數據的特征值,顯然我們可以根據分組特征值篩去一些不合理的分組。





)
)




——RAG高級之跳過檢索)







![[Linux_69] 數據鏈路層 | Mac幀格式 | 局域網轉發 | MTU MSS](http://pic.xiahunao.cn/[Linux_69] 數據鏈路層 | Mac幀格式 | 局域網轉發 | MTU MSS)