目錄
1.ZipList
1.2.解析Entry:
1.3Encoding編碼
1.4.ZipList連鎖更新問題
2.QuickList
SkipList跳表
RedisObject
五種數據類型
1.ZipList
redis中的ZipList是一種緊湊的內存儲存結構,主要可以節省內存空間儲存小規模數據。是一種特殊的雙端鏈表,有一系列連續的內存組成,可以在任意一端進行壓入/彈出操作,而且操作的時間復雜度為O(1)
常見方法:
LPUSH mylist "value1" "value2" //左邊插入
RPUSH mylist "value3" "value4" //右邊插入LPOP mylist //從鏈表最左端彈出數據
RPOP mylist //從鏈表最右端彈出數據LRANGE mylist 0 2 //獲取左邊指定范圍的數據
LINDEX mylist 0 //獲取指定下標數據LLEN mylist //獲取列表長度| zlbytes | zltail | zllen | entry | ... | entry | entry | zlend |
| 屬性 | 類型 | 長度 | 用途 |
| zlbytes | uint32_t | 4字節 | 記錄整個壓縮鏈表占用的內存字節數 |
| zltail | uint32_t | 4字節 | 這個是偏移量,記錄壓縮列表尾節點到列表起始地址有多少字節,通過這個偏移量,可以確定尾節點地址 |
| zllen | uint16_t | 2字節 | 記錄列表包含的節點數量。最大65534,如果超出也只是65535 |
| entry | 列表節點 | 不定 | 各個節點的長度由節點保存的內容確定 |
| zlend | uint8_t | 1字節 | 特殊值0xFF(255),用于標記壓縮例表的末端 |
1.2.解析Entry:
ZipList的Entry不像普通鏈表那樣記錄前后節點的指針,因為記錄前后節點指針需要16字節,大大浪費了內存。所以采用下面的結構來保存。
| previous_entry_length | encoding | content |
1.previous_entry_length:前一節點的長度,占1字節 或 5字節
當前一節點長度 < 254字節,采用 1字節保存這個長度值
當前一節點的長度 > 254字節,采用5字節保存這個長度值
2.encoding:編碼屬性,記錄content的數據類型(數字/字符串)及長度,占用1,2,5字節。
3.contents:負責保存具體的內容,可以是數字可以是字符串
注意:ZipList中所有儲存長度的數值均采用小端字節序儲存,低位在前,高位字節在后。
列如:0x1234,采用小端字節序后就是 0x3412
1.3Encoding編碼
encoding編碼分為兩種:字符串和數字
字符串:encoding以00,01,10開頭標識儲存的是字符串。
下面長度不同的字符串對應encoding編碼格式

舉例:儲存字符串ab,bc
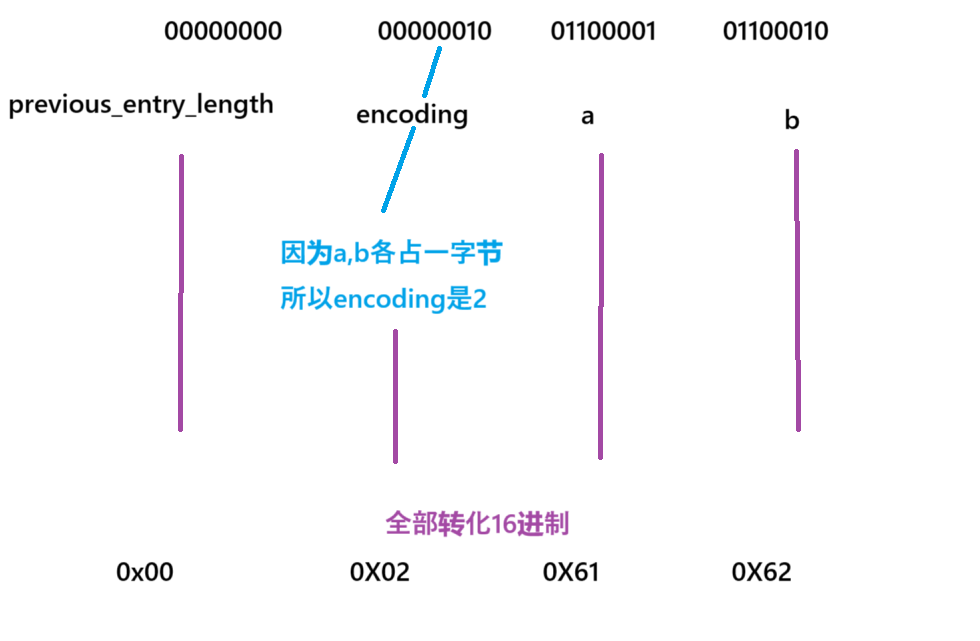

1.4.ZipList連鎖更新問題
ZipList的每個Entry都包含previous_entry_length來記錄上一節點大小,長度為1個或5字節。
>>如果前一節點長度 < 254,那么采用1字節保存這個長度值。
>>如果前一節點 >= 254,則采用5字節保存這個長度值。
如果有N個連續的長度為250~253之間的entry,如果不巧有一個擴展那么又可能發生連鎖反應,又可能所有都發生連鎖更新,新增,刪除都可能導致連鎖更新發生。
總結:
1.壓縮列表可以看作連續內存空間的“雙向鏈表“
2.列表的節點之間不是通過指針鏈接,而是上一節點和本節點長度來尋址,大大節省內存
3.如果數據過多,鏈表過長,可能影響查詢性能
4.增加刪除都可能發生連續更新問題
2.QuickList
ZIpList雖然節省內存,但是申請內存必須是連續空間,如果內存占用過多那么申請效率變低
數據量過大超出上限采用分片儲存數據,那么這些ZipList如何聯系?
Redis3.2版本引入QuickList,是一個雙端鏈表,只不過每個節點都是ZipList
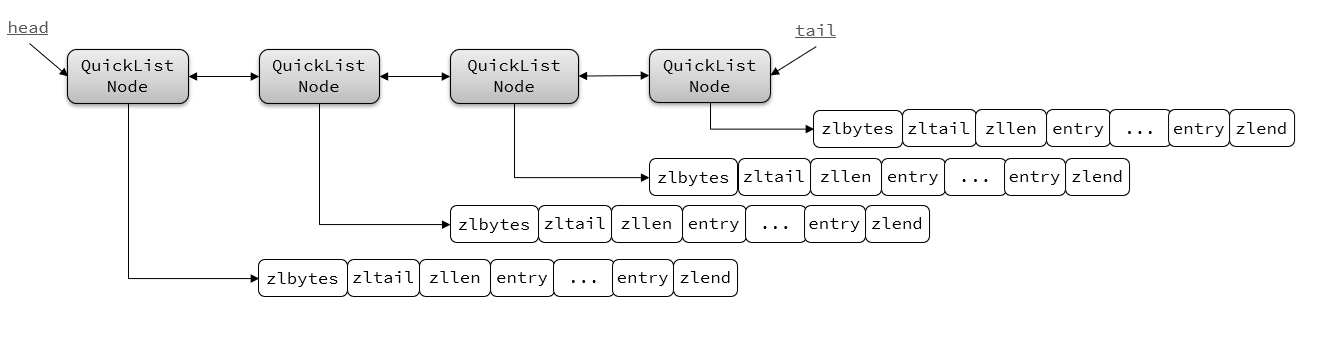
Redis提供配置:list-max-ziplist-size?
如果值是正:代表ZipList允許的最大entry數。
如果值是負:代表每個ZipList的最大內存大小。
| -1 | -2 | -3 | -4 | -5 |
| 4kb | 8kb | 16kb | 32kb | 64kb |

QuickList可以控制首尾是否進行壓縮,通過配置項list-compress-depth來控制,這個參數是控制首尾不壓縮的節點個數。
| 0 | 1 | 2 |
| 代表首尾節點不壓縮 | 首尾各有一個1個不壓縮,中間全壓縮 | 首尾各有2節點不壓縮,中間全壓縮 |

QuickList 和 Quick List Node的結構源碼:
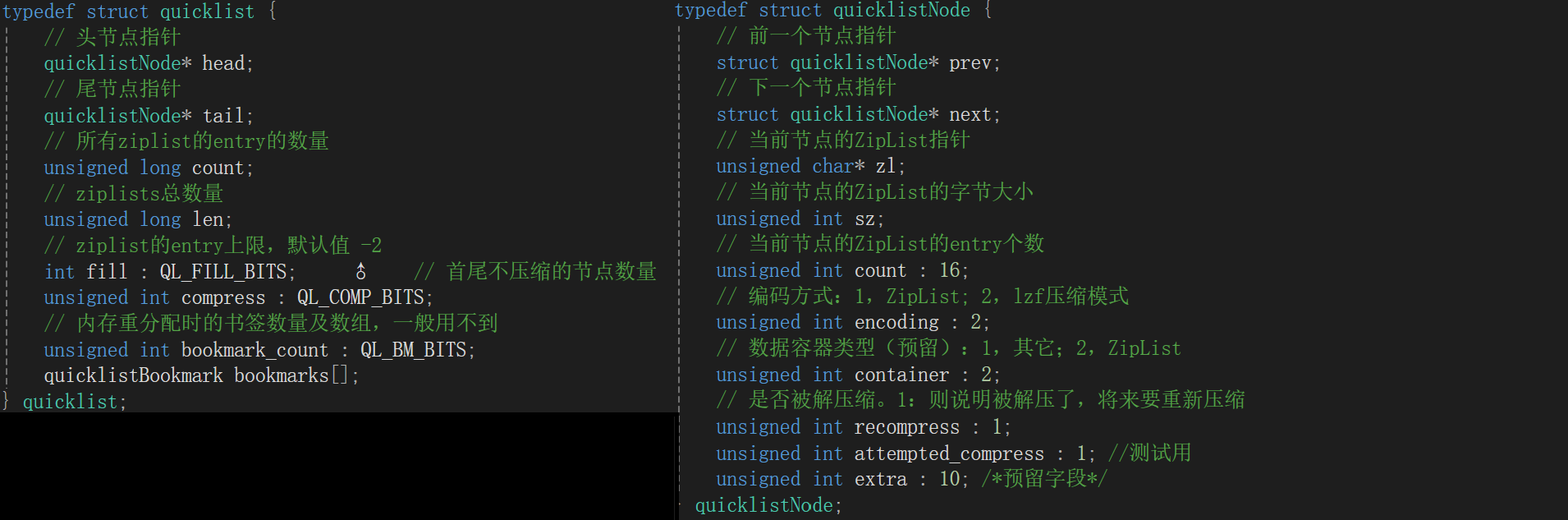
QuickList結構圖:
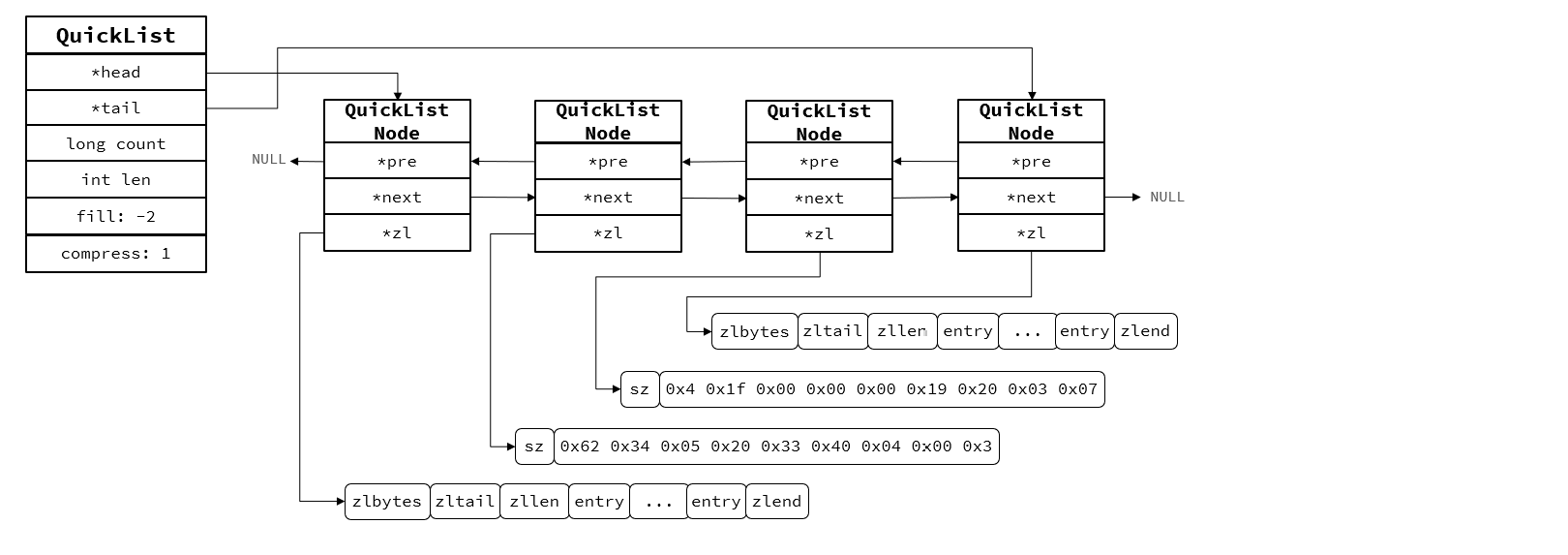
QuickList特性:
1.每個節點都是ZipList的雙端鏈表
2.節點采用ZipList,解決傳統鏈表的內存占用
3.控制ZipList大小,解決傳統連續內存空間申請問題
4.中間節點可壓縮,節省內存
SkipList跳表
是個鏈表,但不是普通鏈表,不同節點之間跨度不一樣。
1.元素按照升序排列儲存
2.節點可能包含多個指針,指針跨度不同
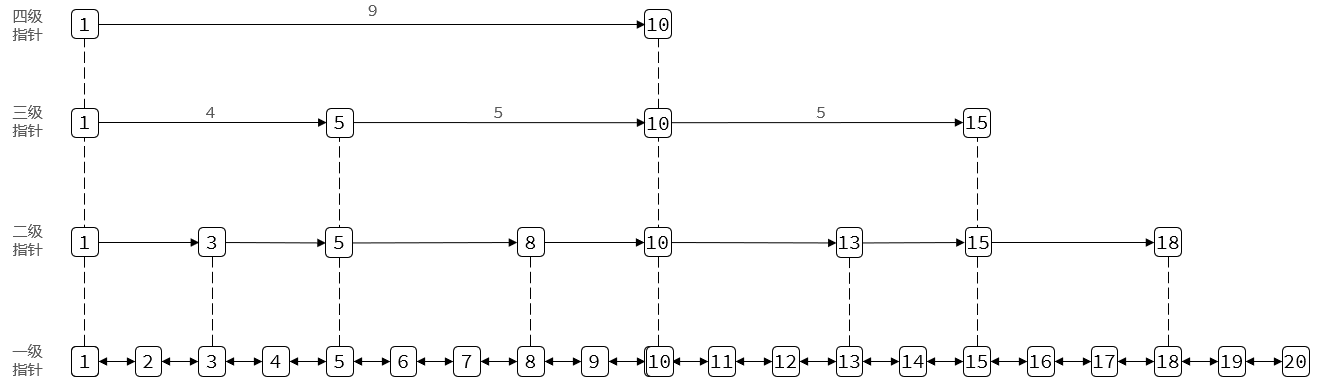
為了更快的找到所需要的元素,SkipList采用這種結構類似于二分查找。
以下是結構源碼:
// t_zset.c
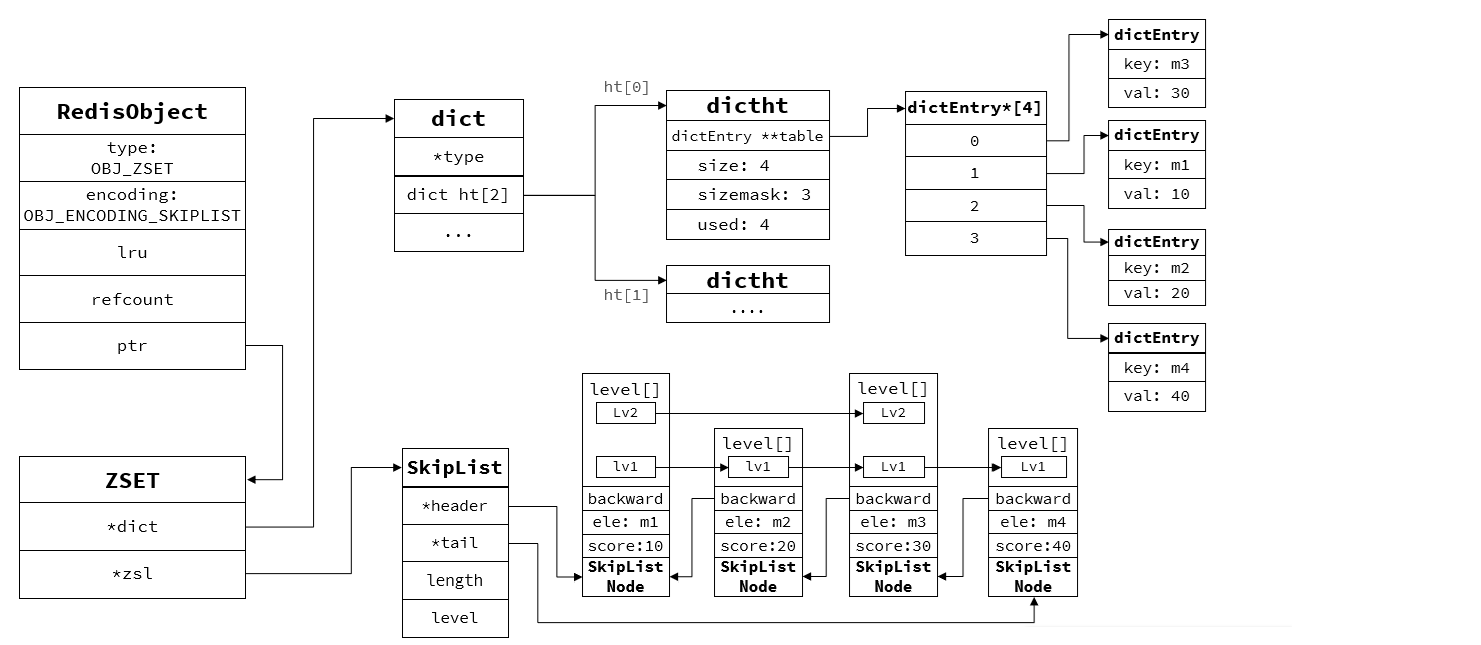
typedef struct zskiplist {// 頭尾節點指針struct zskiplistNode* header, * tail;// 節點數量unsigned long length;// 最大的索引層級,默認是1int level;
} zskiplist;// t_zset.c
typedef struct zskiplistNode {sds ele; // 節點存儲的值double score;// 節點分數,排序、查找用struct zskiplistNode* backward; // 前一個節點指針struct zskiplistLevel {struct zskiplistNode* forward; // 下一個節點指針unsigned long span; // 索引跨度} level[]; // 多級索引數組
} zskiplistNode;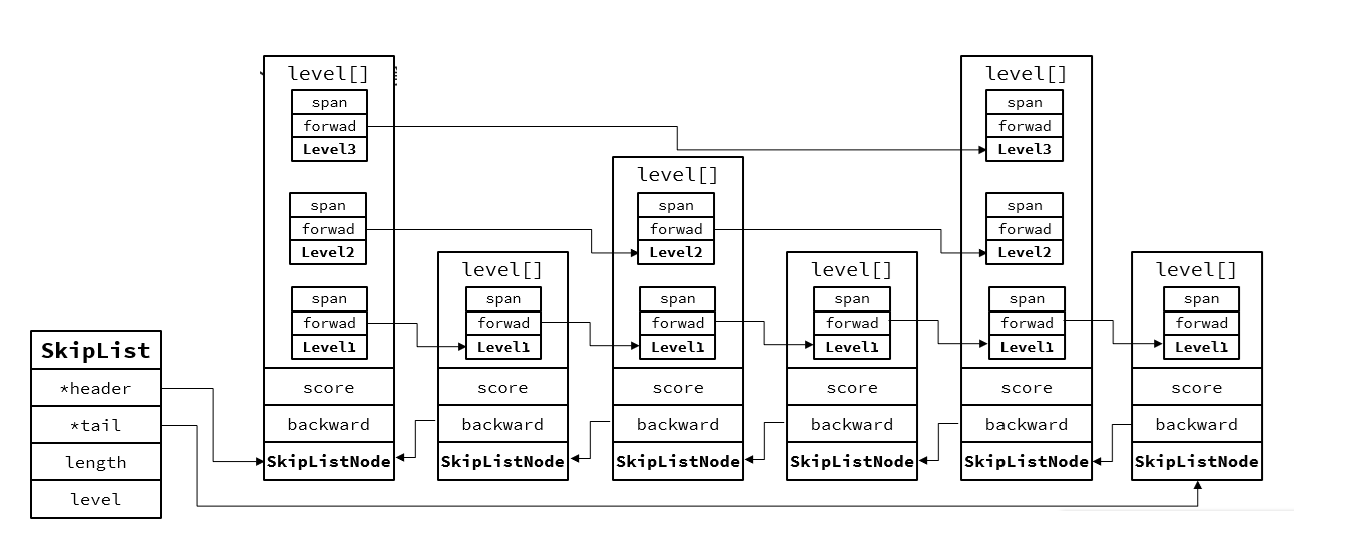
特性:
1.跳表是一個雙向鏈表,每個節點包含存儲的值和排序用的socre,用來保存別的節點的ele數組
2.節點按照score值排序,score值一樣按照ele字典排序
3.每層指針到下一節點跨度不同,層級越高跨度越大
4.增刪改查的效率與紅黑樹基本一致
RedisObject
在Redis中任意數據類型的鍵和值都會被封裝在一個RedisObject中,也叫做Redis對象。
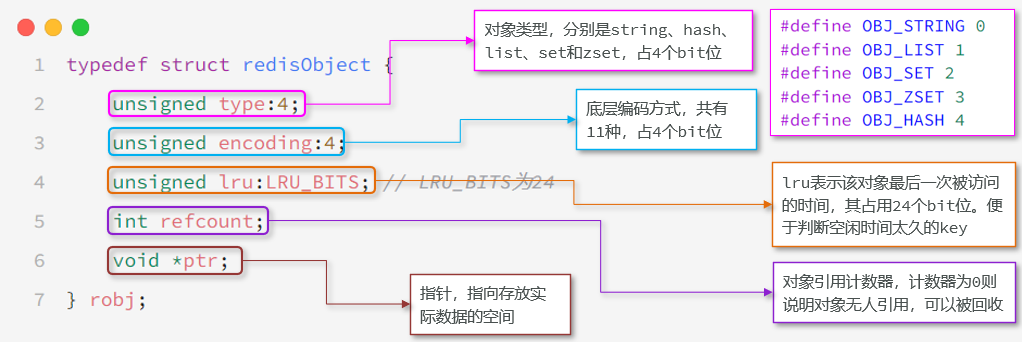
Redis會根據儲存不同的數據類型選擇不同的編碼格式,共包含11種不同類型。
| 編號 | 編碼方式 | 說明 |
|---|---|---|
| 0 | OBJ_ENCODING_RAW | 動態字符串(動態長度,非預分配) |
| 1 | OBJ_ENCODING_INT | 長整型(用?long?類型存儲) |
| 2 | OBJ_ENCODING_HT | 哈希表(字典,基于?dict?實現) |
| 3 | OBJ_ENCODING_ZIPMAP | 已廢棄的哈希壓縮結構 |
| 4 | OBJ_ENCODING_LINKEDLIST | 雙端鏈表(舊版 List 實現) |
| 5 | OBJ_ENCODING_ZIPLIST | 壓縮列表(緊湊的二進制結構) |
| 6 | OBJ_ENCODING_INTSET | 整數集合(僅存儲整數的有序集合) |
| 7 | OBJ_ENCODING_SKIPLIST | 跳表(有序集合的底層實現之一) |
| 8 | OBJ_ENCODING_EMBSTR | 短字符串(固定長度,預分配內存) |
| 9 | OBJ_ENCODING_QUICKLIST | 快速列表(雙向鏈表 + 壓縮列表) |
| 10 | OBJ_ENCODING_STREAM | Stream 流(消息隊列結構) |
五種數據類型
String基于簡單動態字符串SDS實現,存儲上限為512mb,基本編碼方式是RAM
List可以從首尾操作列表中的元素,3.2版本后統一采用QuickList來實現List
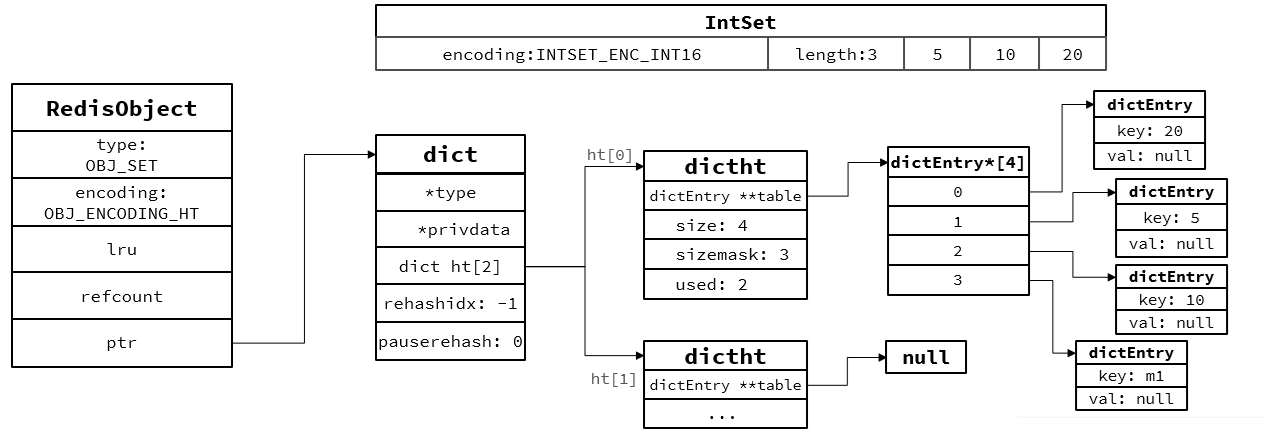
Set:
1.為了查詢效率和唯一性,采用Dict編碼,key為存儲元素,value統一為null
2.所有數據都是整數,且元素數量不超過set-max-intset-entries,Set會采用IntSet編碼
ZSet:
ZSet就是SortedSet,其中每個元素都需指定一個score 和 member值
可以根據score排序,且member必須唯一,可以根據member查詢分數
當元素數數量小時,采用ZipList來節省內存,但是需要滿足兩個條件:
1.元素數量小于 zset_max_ziplist_entries (128)
2.每個元素都小于zset_max_ziplist_value(64)
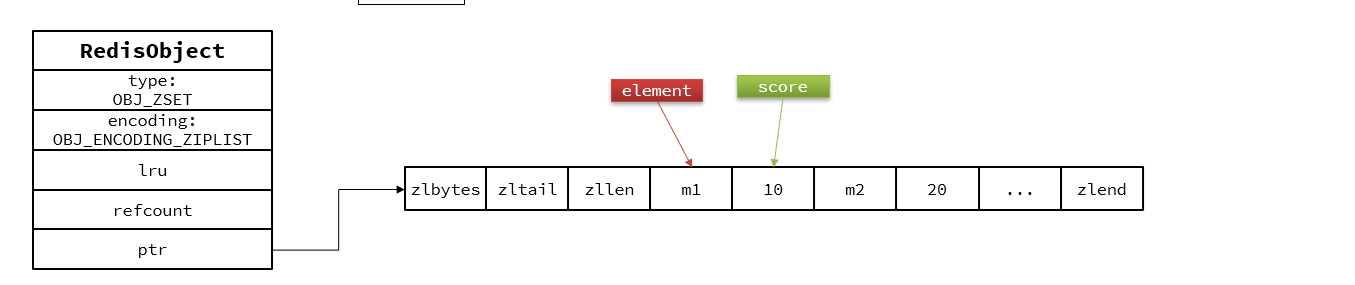
當數據量大時采用SkipList和HT結構
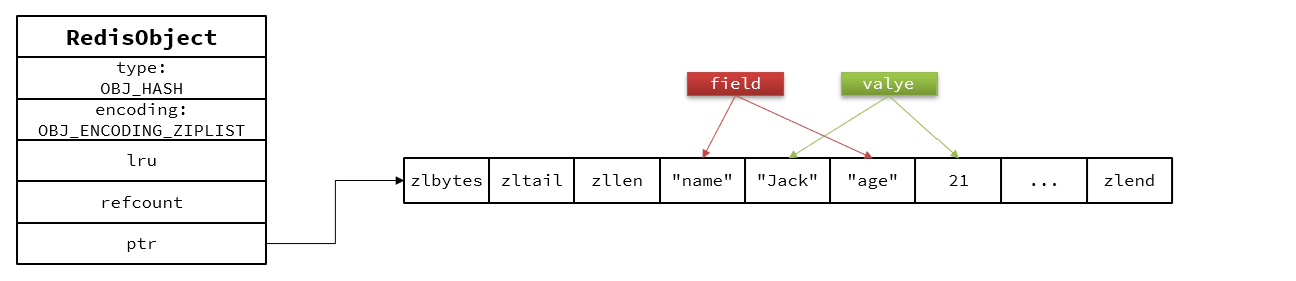
Hash:
hash底層的編碼和ZSet基本一致,只需要把排序有關的SkipList去掉就行。
1.數據量小時,采用ZipList編碼節省內存,ZipList中相鄰的兩個entry保存field和value
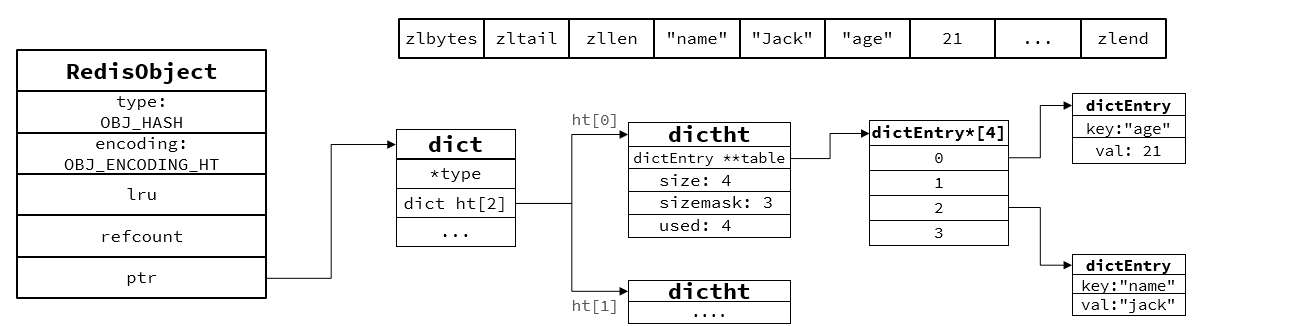
2.數據量大時,采用HT編碼,就是Dict,觸發條件是:元素數量超過512,每個entry超過64字節



——RAG高級之跳過檢索)







![[Linux_69] 數據鏈路層 | Mac幀格式 | 局域網轉發 | MTU MSS](http://pic.xiahunao.cn/[Linux_69] 數據鏈路層 | Mac幀格式 | 局域網轉發 | MTU MSS)


開發與綜合案例)


![[250506] Auto-cpufreq 2.6 版本發布:帶來增強的 TUI 監控及多項改進](http://pic.xiahunao.cn/[250506] Auto-cpufreq 2.6 版本發布:帶來增強的 TUI 監控及多項改進)

